概要
Databricks では、最近のアップデートにより Python UDF で外部ライブラリが利用できるようになりました。
https://docs.databricks.com/aws/ja/udf/unity-catalog
これにより、SQL Warehouse 上でもより柔軟かつ高度な処理が可能になっています。
従来は「Databricks SQL での RAG の構築」で紹介されているように、Vector Search を活用することで SQL Warehouse 上で RAG を実現することができました。
本記事では、Databricks が提供する Vector Search を利用せず、Python UDF を用いて独自にベクトル検索を実装し、SQL Warehouse と Databricks のホスト型 LLM のみで RAG を実現する方法を解説します。
なお、本記事で紹介する手法は、Python UDF の機能検証を目的とした実験的なものです。
計算効率やスケーラビリティ、運用・監査性などの観点から、実運用での利用は推奨されません。
プロダクション用途では、以下の公式機能の活用を検討してください。
- ベクトル検索: Mosaic AI Vector Search
- モデルのデプロイ: Mosaic AI Model Serving
- 評価・デバッグ: MLflow
- UI: Databricks Apps
実装
ライブラリのインストール
まず、必要なライブラリをインストールします。今回は langchain でテキスト分割を行い、scikit-learn で最近傍検索を実装します。
%pip install langchain==0.3.27 scikit-learn==1.7.1
%restart_python
データの準備
検索対象のデータを chunks 変数に List[str] 型で格納します。
今回は databricks-sdk-py のドキュメントを使います。まず GitHub からリポジトリをクローンし、Markdown ファイルを抽出します。
%sh
git clone https://github.com/databricks/databricks-sdk-py /tmp/databricks-sdk-py
from langchain.text_splitter import RecursiveCharacterTextSplitter
import os
md_files = []
for root, dirs, files in os.walk('/tmp/databricks-sdk-py'):
for file in files:
if file.endswith('.md'):
md_files.append(os.path.join(root, file))
display(md_files)
chunks = []
splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=200)
for file_path in md_files:
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
file_chunks = splitter.split_text(text)
chunks.extend(file_chunks)
df_chunks = spark.createDataFrame([(c,) for c in chunks], ["chunk"])
df_chunks.createOrReplaceTempView("chunks_view")
display(df_chunks)
ここでは、以下の処理を行っています:
- GitHub から databricks-sdk-py リポジトリをクローン
- リポジトリ内の Markdown ファイルを検索
- LangChain の RecursiveCharacterTextSplitter を使って、各ファイルをチャンクに分割
- 分割したテキストを Spark DataFrame に変換し、一時ビューを作成
特徴量の抽出
次に、各チャンクからベクトル埋め込みを抽出します。Databricks の ai_query 関数を使って、databricks-bge-large-en モデルで埋め込みを生成します。
embs_df = spark.sql(f"""
SELECT chunk, ai_query("databricks-bge-large-en", chunk) as emb FROM chunks_view
""").toPandas()
ai_query 関数は Databricks の Foundation Model API を呼び出し、テキストの埋め込みベクトルを生成します。
結果は Pandas DataFrame に変換しておきます。
ベクトル検索用インデックスの構築
抽出した埋め込みベクトルを使って、scikit-learn の NearestNeighbors を使った検索インデックスを構築します。
import numpy as np
import pickle
from sklearn.neighbors import NearestNeighbors
# ベクトルを numpy 配列に変換
embeddings = np.vstack(embs_df['emb'].values).astype('float32')
chunks_df = embs_df[['chunk']]
# kNN インデックスの構築
index = NearestNeighbors(n_neighbors=5, metric='euclidean') # L2距離
index.fit(embeddings)
# モデルとchunks_dfをシリアライズ
index_bytes = pickle.dumps(index)
chunks_df_bytes = pickle.dumps(chunks_df)
def search_top_k(query_vec, index_bytes, chunks_df_bytes, k=5):
index = pickle.loads(index_bytes)
chunks_df = pickle.loads(chunks_df_bytes)
D, I = index.kneighbors([query_vec], n_neighbors=k, return_distance=True)
results = chunks_df.iloc[I[0]][['chunk']]
return results["chunk"].to_list()
display(search_top_k(embeddings[0], index_bytes, chunks_df_bytes))
ここでは以下の処理を行っています:
- 埋め込みベクトルを numpy 配列に変換
- scikit-learn の NearestNeighbors を使って検索インデックスを構築
- インデックスと元のテキストデータをシリアライズ(バイナリ形式に変換)
- 検索用の関数
search_top_kを定義し、テスト実行
次に、シリアライズしたインデックスとテキストデータをテーブルに保存します。
UDF 内でインデックスデータを直接保持することは難しいため、事前にテーブルへ格納しておきます。
import pyspark.sql.types as T
# データフレーム作成
save_df = spark.createDataFrame(
[(index_bytes, chunks_df_bytes)],
schema=T.StructType([
T.StructField("index_bytes", T.BinaryType(), False),
T.StructField("chunks_df_bytes", T.BinaryType(), False)
])
)
# テーブルに保存
save_df.write.mode("overwrite").option("overwriteSchema", "true").saveAsTable("index")
Python UDF の実装
これまで Python で定義・テストしてきた検索処理を、SQL から呼び出せる Python UDF として実装します。
この UDF は、クエリベクトルとシリアライズされたインデックスを受け取り、最も類似度の高いテキストチャンクを返します。
これにより、SQL Warehouse 上でも同様のベクトル検索処理を簡単に利用できるようになります。
%sql
CREATE OR REPLACE FUNCTION search_top_k(
embs ARRAY<FLOAT>,
index_bytes BINARY,
chunks_df_bytes BINARY
)
RETURNS ARRAY<STRING>
LANGUAGE PYTHON
ENVIRONMENT (
dependencies = '["scikit-learn==1.7.1"]',
environment_version = 'None'
)
AS $$
import numpy as np
import pickle
def search_top_k(query_vec, index_bytes, chunks_df_bytes, k=5):
index = pickle.loads(index_bytes)
chunks_df = pickle.loads(chunks_df_bytes)
D, I = index.kneighbors([query_vec], n_neighbors=k, return_distance=True)
results = chunks_df.iloc[I[0]][['chunk']]
return results["chunk"].to_list()
return search_top_k(embs, index_bytes, chunks_df_bytes)
$$
;
この UDF の特徴は以下の通りです:
-
ENVIRONMENT句でカスタムの依存ライブラリ(scikit-learn)を指定 - 入力として埋め込みベクトル(
ARRAY<FLOAT>)とシリアライズされたインデックスデータ(BINARY)を受け取る - Python の pickle モジュールを使ってインデックスをデシリアライズし、最近傍検索を実行
- 検索結果のテキストチャンクを配列として返す
SQL Warehouse での実行
作成した UDF を使って、SQL Warehouse から RAG を実行できます。以下は日本語のクエリを英語に翻訳し、関連するコンテキストを検索して回答を生成する例です。
USE CATALOG your_catalog;
USE SCHEMA your_schema;
WITH translation AS (
SELECT
ai_query(
"databricks-llama-4-maverick",
concat(
"- 以下のテキストを英語に翻訳してください。\n- 翻訳結果以外は出力しないでください:\n",
:query
)
) as translated_query
),
context AS (
SELECT
translated_query,
concat(
"<context>\n",
concat_ws(
'\n---\n',
search_top_k(
ai_query("databricks-bge-large-en", translated_query), index_bytes, chunks_df_bytes
)
),
"\n</context>"
) as context
FROM
translation,
index
),
result AS (
SELECT
'answer' as result_type,
ai_query(
'databricks-claude-3-7-sonnet',
concat(
'あなたは、databricks-sdk-py のプロです。ユーザーの質問に対してcontextを用いて回答してください。回答は日本語かつHTML形式でお願いします。\nquestion:\n',
translated_query,
'\n\ncontext:\n',
context
)
) as value
FROM
context
UNION ALL
SELECT
'translated_query' as result_type,
translated_query as value
FROM
context
UNION ALL
SELECT
'context' as result_type,
context as value
FROM
context
)
SELECT
*
FROM
result
このクエリは以下のステップで処理されます:
- 日本語のクエリを
databricks-llama-4-maverickモデルで英語に翻訳
(埋め込みモデルが英語対応のため、事前に翻訳を実施) - 翻訳後のクエリを
databricks-bge-large-enモデルでベクトル化 -
search_top_kUDF を用いて、関連性の高いテキストチャンクを検索 - 検索したチャンクをコンテキストとして
databricks-claude-3-7-sonnetモデルに渡し、回答を生成
(ダッシュボード表示用に HTML 形式で出力)
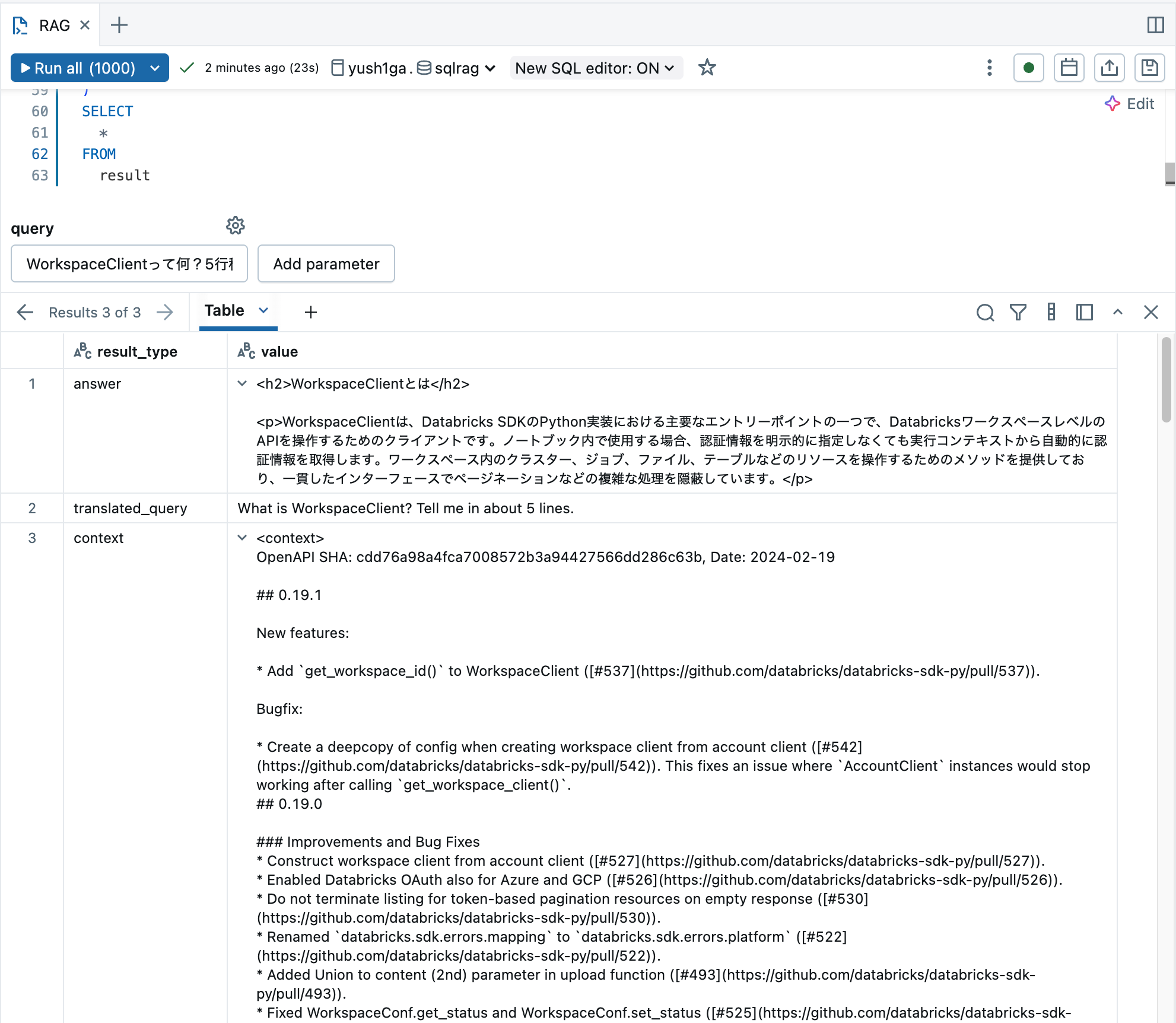
実行結果の例を以下に示します。
途中経過として翻訳テキストや検索されたコンテキストも出力しており、MLflow Tracing のようなプロンプトの流れの可視化を簡易的に再現しようとしています。
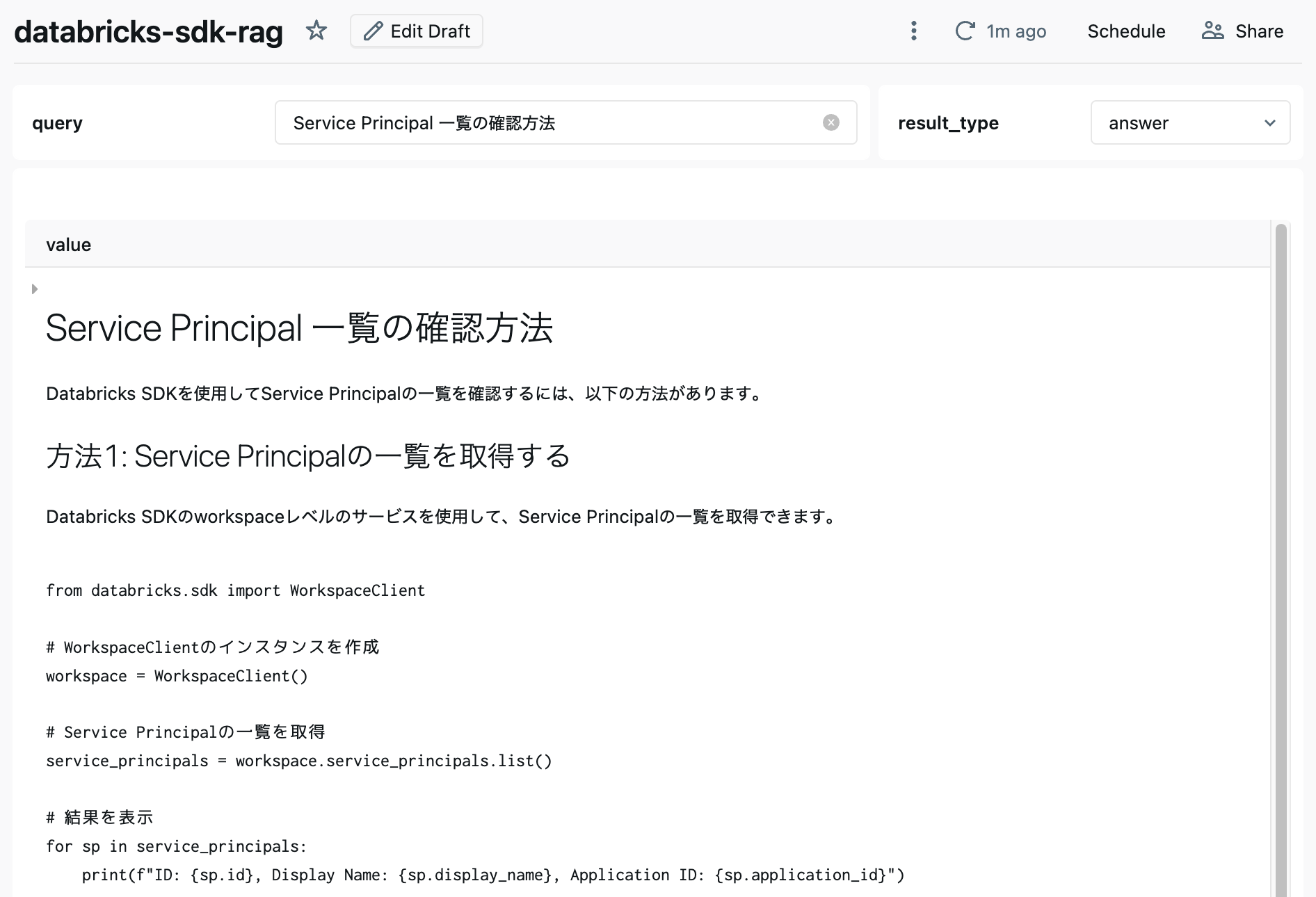
AI/BI ダッシュボードで簡易 Chatbot 化
「Databricks SQL での RAG の構築」と同様に、Databricks のダッシュボード機能を活用して簡易的な Chatbot を作成できます。
まとめ
本記事では、Databricks の Python UDF 機能を使って、SQL Warehouse 内でベクトル検索を実装し、RAG システムを構築する方法を紹介しました。
主なポイントは以下の通りです:
- 依存ライブラリを指定した を Python UDF によるベクトル検索の実装
- Python UDF と ai_query を用いたクエリによる RAG パイプラインの実行
冒頭でも述べたように、この実装は Python UDF の機能検証を目的とした実験的なものです。
プロダクション環境では、冒頭で紹介した RAG 向けの機能(Vector Search、Model Serving、MLflow、Databricks Apps)の活用を検討してください。
しかし、Python UDF の柔軟性を理解し、様々な可能性を探るための一例として参考にしていただければ幸いです。