ナレッジ登録の自動化
前回の記事ではLLMを活用したJira自動返信ワークフローを紹介しました。今回の記事ではPineconeにナレッジを自動登録する方法を紹介します。
テンプレートは以下のGithubで公開しています。
公式n8nテンプレートサイトにも公開しています。
各ノードの詳細を確認したい方はn8nテンプレートサイトを参照してください。
ワークフロー全体
Jira自動返信のワークフローと似ていますが、後半部分を「完了済みチケットをPineconeへ登録する処理」に置き換えてます。
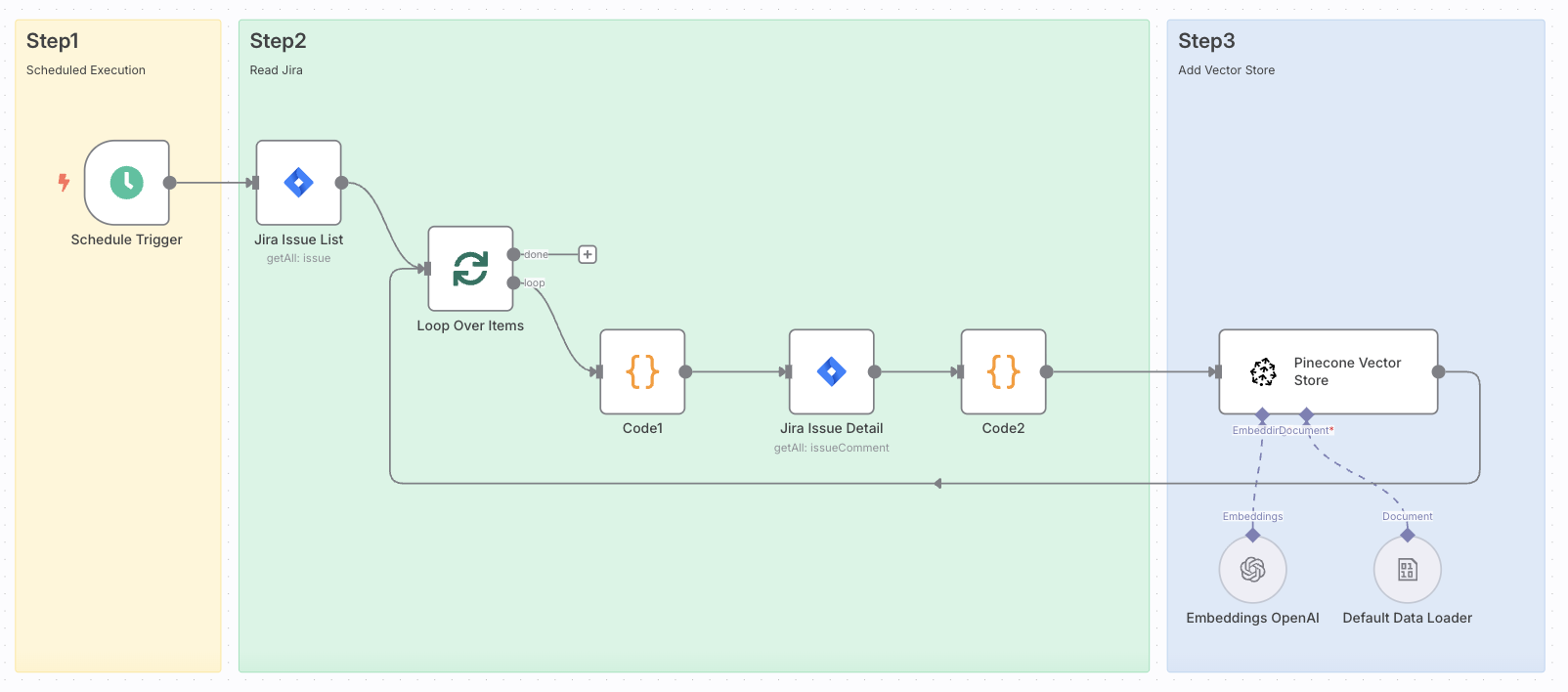
処理の流れ
以下が処理の流れです。1日毎に当日「完了済み」になったチケットを対象にデータ収集してPineconeに登録しています。
- 1日毎にワークフローが実行される
- Jiraから以下の条件でチケット一覧を読み込む
- 完了済み
- 1日前までに更新あり
- それぞれのチケット毎に以下の処理を実行
- Jiraの本文や、コメントの読み込み
- Pineconeに登録
登録データについて
Code2ノードで登録するデータを収集します。収集するデータは以下となります。
- JiraチケットのID
- Jiraチケットの説明
- Jiraチケットのコメント
データを収集するためのコードは以下です。基本的にはJiraノードから出力されるデータを使っているのですが、コメントが配列となっているため読みやすい形式に変換を行ってます。
let comments = '';
for (const item of $input.all()) {
comments += '## ' + item.json.updated
comments += '\n'
comments += item.json.body.content[0].content[0].text
comments += '\n'
comments += '\n'
}
return {
'id': $('Code1').first().json.id,
'summary': $('Code1').first().json.summary,
'description': $('Code1').first().json.description,
'comments': comments,
};
Pinecone登録処理
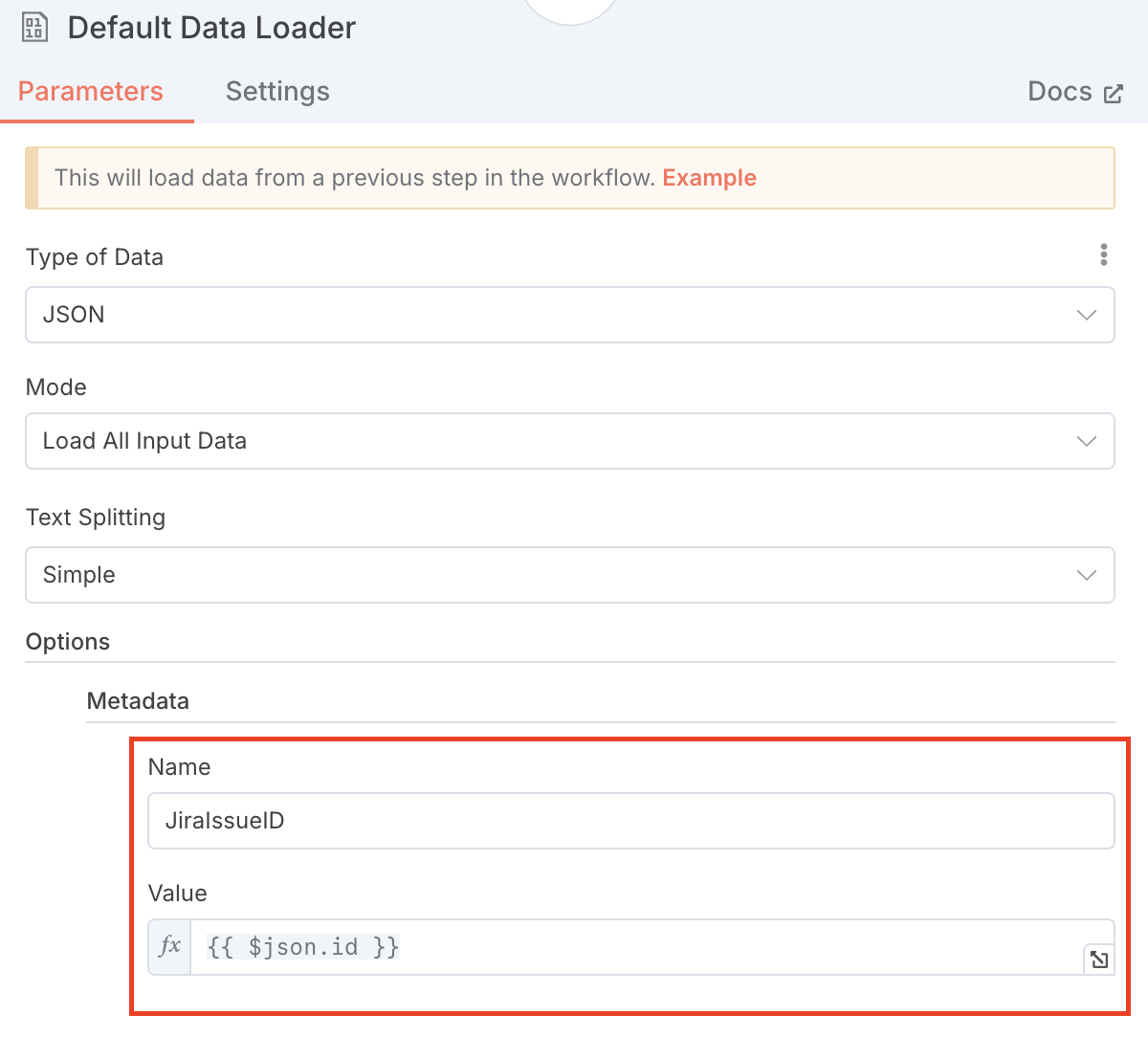
Code2ノードで処理したデータをDefault Data Loaderノードで整形してPineconeに登録しています。
基本的にはそのまま登録しているのですが、JiraチケットIDだけはMetadata登録しています。こうすることでLLMが参照しやすいようになります。
最後に
今回はPineconeへ完了済みJiraチケットデータ登録をやってみました。本ワークフローを定期的に動かすことでLLMの回答精度向上が見込めます。また、ドキュメントやWikiなど他の情報源も追加し、より精度の高いナレッジベースを構築することも可能です。
質問・フィードバック
Github Issues or X(旧twitter) or コメント欄 からお願いします。