はじめに
今回はGatsbyで作ったWebサイトに適切に検索クローラをコントロールする方法から検証まで記載しました。
ページの品質が低い、問い合わせ用のページなど、特定のページをGoogle検索に出したくない。また想定外のページが結果上位に出てきてしまうことがありえます。。。
あらかじめ、クローラーに対して命令することで上記のようなことを回避して、検索からのより良いファーストビューを提供しましょう。
ちなみにGatsbyスターターのadminはnoindexタグによってインデックスを拒否しているので、今回設定する必要はありません。※設定されていないスターターもあるかも。。。
robots.txtを生成するプラグインを導入する
robots.txtファイルを生成するプラグインを使用します。一緒にsitemapを生成するプラグインも追加します。
これでrobots.txtとsitemapがルート直下に作成されます。
// プラグインをライブラリに追加
$ yarn add gatsby-plugin-robots-txt
// sitemapがない場合は同時に追加しておく
$ yarn add gatsby-plugin-sitemap
gatsby-config.jsに追加したプラグインの記述を追加します。
複数のパスを登録する際は、配列で指定します。詳しい生成ルールについてはプラグインのGitHubページを参照してください。
plugins: [
{
resolve: 'gatsby-plugin-robots-txt',
options: {
host: 'https://www.example.com',
sitemap: 'https://www.example.com/sitemap.xml',
policy: [
{
userAgent: '*',
disallow: ['/blog', '/contact', '/tag', ] // クロール禁止のパスを配列で指定
}
]
}
},
'gatsby-plugin-sitemap',
]
上記の後、gatsby buildすると、public配下にrobots.txtとsitemap.xmlが生成されます。
生成したrobots.txtの中身はこちら。disallowに指定したパスが追記されていることがわかります。
User-agent: *
Disallow: /blog
Disallow: /contact
Disallow: /tag
Sitemap: https://www.example.com/sitemap.xml
Host: https://www.example.com
検証
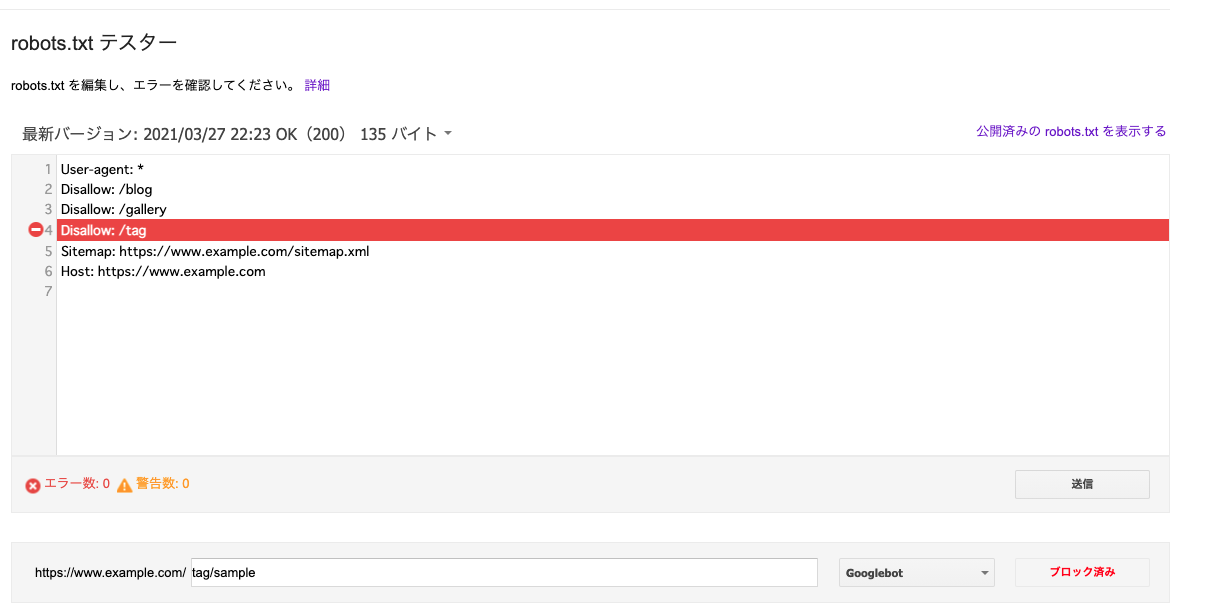
想定通りにrobots.txtが記載できているかはGoogle Search Consoleを使います。
こちらからrobots.txtのテスト画面に飛びます。サイトの登録がまだの方は登録が必要です。
robots.txt テスターで robots.txt をテストする
テスト対象のURLで検証を実行します。
結果がブロック済みであれば、クローラー対象外となっていることが確認できます。
あとはしばらく待って自分のサイトがクローリングされるのを待ちます。
しばらくするとGoogle Search Consoleのカバレッジから、robots.txt によってブロックされていると結果が表示されます。