学習済みモデルを使って画像の判定を実施
と、その前に。
その2で表示させられなかったtensorboardが表示できました。
前回は、
tensorboard --logdir=./logs
とコマンド入力していましたが、そもそもTensorBoardデータの保存先が違ったので、そりゃ表示できないですわな。
前回のコードでの保存先はここ。
tensorboard --logdir=./test/test1/data
無事表示されました。
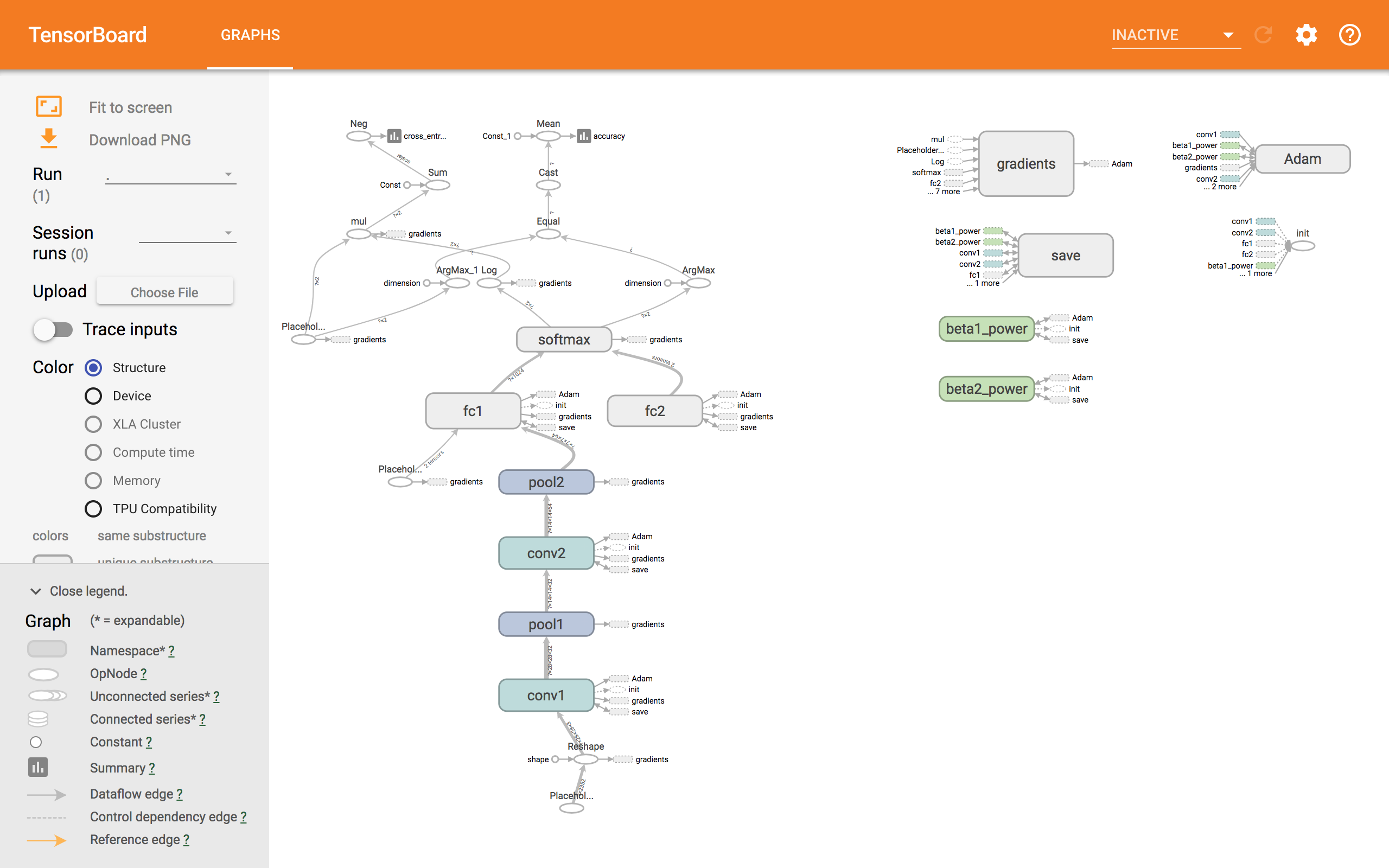
ん〜?
画像の判定
実行するとき、引数に画像を与えると、0/1で返してくれる。
0:西島秀俊
1:石原さとみ
FaceType.py
# !/usr/bin/env python
# ! -*- coding: utf-8 -*-
import sys
import numpy as np
import tensorflow as tf
import cv2
NUM_CLASSES = 2
IMAGE_SIZE = 28
IMAGE_PIXELS = IMAGE_SIZE*IMAGE_SIZE*3
def inference(images_placeholder, keep_prob):
""" モデルを作成する関数
引数:
images_placeholder: inputs()で作成した画像のplaceholder
keep_prob: dropout率のplace_holder
返り値:
cross_entropy: モデルの計算結果
"""
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
x_image = tf.reshape(images_placeholder, [-1, 28, 28, 3])
with tf.name_scope('conv1') as scope:
W_conv1 = weight_variable([5, 5, 3, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
with tf.name_scope('pool1') as scope:
h_pool1 = max_pool_2x2(h_conv1)
with tf.name_scope('conv2') as scope:
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
with tf.name_scope('pool2') as scope:
h_pool2 = max_pool_2x2(h_conv2)
with tf.name_scope('fc1') as scope:
W_fc1 = weight_variable([7*7*64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
with tf.name_scope('fc2') as scope:
W_fc2 = weight_variable([1024, NUM_CLASSES])
b_fc2 = bias_variable([NUM_CLASSES])
with tf.name_scope('softmax') as scope:
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
return y_conv
if __name__ == '__main__':
test_image = []
for i in range(1, len(sys.argv)):
img = cv2.imread(sys.argv[i])
img = cv2.resize(img, (28, 28))
test_image.append(img.flatten().astype(np.float32)/255.0)
test_image = np.asarray(test_image)
images_placeholder = tf.placeholder("float", shape=(None, IMAGE_PIXELS))
labels_placeholder = tf.placeholder("float", shape=(None, NUM_CLASSES))
keep_prob = tf.placeholder("float")
logits = inference(images_placeholder, keep_prob)
sess = tf.InteractiveSession()
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
saver.restore(sess, "model.ckpt")
for i in range(len(test_image)):
pred = np.argmax(logits.eval(feed_dict={
images_placeholder: [test_image[i]],
keep_prob: 1.0 })[0])
print (pred)
が、しかし。
顔を切り出した画像で学習させておりますので、顔の切り出し後の画像でしか正確な判定はできません。
結果
$ python3 FaceType.py ./fc0c597d5dad95acf207adff0b2f7c8a44f3383caf16f6b82a75ba8412459de0.jpg
0```
使った画像

fc0c597d5dad95acf207adff0b2f7c8a44f3383caf16f6b82a75ba8412459de0.jpg
しっかり西島秀俊が0と判定されました。
切り出し後の画像で、train/testどちらにも使ってない画像
西島秀俊:7枚
石原さとみ:9枚
を使って判定させてみたところ、全問正解でした。
いちいち顔を切り出した後に判定するのはだるいので、引数に与えた画像から顔検出して判定するやつはこちら。
引数で与えられた画像をopenCVで顔検出してから判定します。
```FaceType1.py
# !/usr/bin/env python
# ! -*- coding: utf-8 -*-
import sys
import numpy as np
import tensorflow as tf
import cv2
import os
NUM_CLASSES = 2
IMAGE_SIZE = 28
IMAGE_PIXELS = IMAGE_SIZE*IMAGE_SIZE*3
# カスケード分類器ロード
cascade_path = "/Users/yuni/anaconda/lib/python3.6/site-packages/cv2/data/haarcascade_frontalface_alt.xml"
def inference(images_placeholder, keep_prob):
""" モデルを作成する関数
引数:
images_placeholder: inputs()で作成した画像のplaceholder
keep_prob: dropout率のplace_holder
返り値:
cross_entropy: モデルの計算結果
"""
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
x_image = tf.reshape(images_placeholder, [-1, 28, 28, 3])
with tf.name_scope('conv1') as scope:
W_conv1 = weight_variable([5, 5, 3, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
with tf.name_scope('pool1') as scope:
h_pool1 = max_pool_2x2(h_conv1)
with tf.name_scope('conv2') as scope:
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
with tf.name_scope('pool2') as scope:
h_pool2 = max_pool_2x2(h_conv2)
with tf.name_scope('fc1') as scope:
W_fc1 = weight_variable([7*7*64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
with tf.name_scope('fc2') as scope:
W_fc2 = weight_variable([1024, NUM_CLASSES])
b_fc2 = bias_variable([NUM_CLASSES])
with tf.name_scope('softmax') as scope:
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
return y_conv
images_placeholder = tf.placeholder("float", shape=(None, IMAGE_PIXELS))
labels_placeholder = tf.placeholder("float", shape=(None, NUM_CLASSES))
keep_prob = tf.placeholder("float")
logits = inference(images_placeholder, keep_prob)
sess = tf.InteractiveSession()
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
saver.restore(sess, "model.ckpt")
if __name__ == '__main__':
test_image = []
for i in range(1, len(sys.argv)):
img = cv2.imread(sys.argv[i])
#グレースケール変換
image_gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
#カスケード分類器の特徴量を取得する
cascade = cv2.CascadeClassifier(cascade_path)
#物体認識(顔認識)の実行
facerect = cascade.detectMultiScale(image_gray, scaleFactor=1.1, minNeighbors=1, minSize=(1, 1))
if len(facerect) == 1:
print ("顔認識に成功しました。")
print (facerect)
#検出した顔の処理
for rect in facerect:
#顔だけ切り出して保存
x = rect[0]
y = rect[1]
width = rect[2]
height = rect[3]
dst = img[y:y+height, x:x+width]
new_image_path = "./result/" + sys.argv[1]
cv2.imwrite(new_image_path, dst)
elif len(facerect) > 1:
# 複数顔が検出された場合はスキップ
print ("顔が複数認識されました")
print (facerect)
if len(facerect) > 0:
color = (255, 255, 255) #白
for rect in facerect:
#検出した顔を囲む矩形の作成
cv2.rectangle(image, tuple(rect[0:2]),tuple(rect[0:2] + rect[2:4]), color, thickness=2) quit()
else:
# 顔検出に失敗した場合もスキップ
print ("顔が認識できません。")
quit()
#形式を変換
img = cv2.resize(img, (28, 28))
test_image.append(img.flatten().astype(np.float32)/255.0)
test_image = np.asarray(test_image)
for i in range(len(test_image)):
pred = np.argmax(logits.eval(feed_dict={
images_placeholder: [test_image[i]],
keep_prob: 1.0 })[0])
print (pred)
結果
$ python3 FaceType1.py ./fc0c597d5dad95acf207adff0b2f7c8a44f3383caf16f6b82a75ba8412459de0.jpg
[ INFO:0] Initialize OpenCL runtime...
顔認識に成功しました。
[[107 74 164 164]]
0```
使った画像

fc0c597d5dad95acf207adff0b2f7c8a44f3383caf16f6b82a75ba8412459de0.jpg
(さっきの切り出し後の画像と一緒です。)
ちゃんと西島秀俊(0)と判定されました。パチパチ
と思ったのは一瞬で...
### 他の画像でも検証
```$ python3 FaceType1.py ./f61a4affa931e919b890d752d858a12500d168780e3b74835779033e590e009a.jpg
[ INFO:0] Initialize OpenCL runtime...
顔認識に成功しました。
[[175 138 195 195]]
1

f61a4affa931e919b890d752d858a12500d168780e3b74835779033e590e009a.jpg
むむっ!
石原さとみ(1)判定されとる!
不正解。
$ python3 FaceType1.py ./f533ce4c731b97c8a76033137e58a53cf0787907f679739910d53f92359a8d53.jpeg
[ INFO:0] Initialize OpenCL runtime...
顔認識に成功しました。
[[188 4 108 108]]
0

f533ce4c731b97c8a76033137e58a53cf0787907f679739910d53f92359a8d53.jpeg
正解。
$ python3 FaceType1.py ./f91423f635a5cd00cbee3e155bf402bd117a7e906726b258c1f06217aa1a19ef.jpeg
[ INFO:0] Initialize OpenCL runtime...
顔認識に成功しました。
[[181 31 230 230]]
0```

f91423f635a5cd00cbee3e155bf402bd117a7e906726b258c1f06217aa1a19ef.jpeg
正解。
```$ python3 FaceType1.py ./fac5417282ce6273a670e1effcaa40f66befc890fd1fba5d5e77a36bf930b05f.jpg
[ INFO:0] Initialize OpenCL runtime...
顔認識に成功しました。
[[224 47 120 120]]
0```

fac5417282ce6273a670e1effcaa40f66befc890fd1fba5d5e77a36bf930b05f.jpg
正解。
```$ python3 FaceType1.py ./fb1bf6b612e02606be103e7dd6e9dffbcd34b237c39309baea1b8965c37bb82f.jpg
[ INFO:0] Initialize OpenCL runtime...
顔認識に成功しました。
[[109 46 180 180]]
0
```
fb1bf6b612e02606be103e7dd6e9dffbcd34b237c39309baea1b8965c37bb82f.jpg
正解。
```$ python3 FaceType1.py ./fe9872d55ad2c90fa366a6755fb24e8d5ddee6ab8e65ad796ec62ec4abe1dc39.jpg
[ INFO:0] Initialize OpenCL runtime...
顔認識に成功しました。
[[303 49 70 70]]
1```

fe9872d55ad2c90fa366a6755fb24e8d5ddee6ab8e65ad796ec62ec4abe1dc39.jpg
不正解。
顔認識はできているのに。

./result/fe9872d55ad2c90fa366a6755fb24e8d5ddee6ab8e65ad796ec62ec4abe1dc39.jpg
実行ファイルがある階層にresultフォルダがあって、そこに顔切り出し後の画像が保存される。
この顔切り出し後の画像で、FaceType.py(この記事で最初に記載したプログラム)で検証。
```$ python3 FaceType.py ./result/fe9872d55ad2c90fa366a6755fb24e8d5ddee6ab8e65ad796ec62ec4abe1dc39.jpg
0```
正解。
え、なんでなん?
### ちなみに
自分の顔でやってみた。

顔の切り出しはあらかじめやっておく。

全問正解中のFaceType.pyで実行。
```$ python3 FaceType.py ./IMG_6154.JPG
1```
石原さとみ(1)に判定された〜。
はあ〜っ、ドキドキした〜(汗)
女性に判定されてよかったw
疑問点は残るけど、安心したのでお疲れ様でした。
(2018.4.7追記)
FaceType1.pyのコード間違ってたので修正したものを[その5](https://qiita.com/yuni/items/2db984057095cfc59df8)に記載しました。