C++Advent Calendar 2016
この記事はC++Advent Calendar 2016 8日目の記事です
[<< 7日目 | C++形式の共有ライブラリの書き方(gcc編)](http://qiita.com/Chironian/items/3fb61cffa2a20dbee5c2) || 9日目 | [最近書いたマクロ(構造体をtupleに変換したい) - TXT.TXT](http://txt-txt.hateblo.jp/entry/2016/12/09/225148)/[それでも構造体をtupleに変換したい - TXT.TXT](http://txt-txt.hateblo.jp/entry/2016/12/09/225641) >>
今年は3日目にしてコンパイル時CコンパイラとかいうC++の作者であるBjarne Stroustrupにまで言及されるに至った、頭のおかしい記事が出て、強さしか無いですね!
はじめに
皆様、ナマステ。
世の中では、Visual Studio2017 RCがでて、MSが来年にはtwo-phase lookupを実装するというニュースが駆け巡ったり、C++ Builder 10.1 BerlinがでてClangが使えるようになったり(ただし古い)、C++17の内容がいろいろ見えてきたり、またしてもchar8_t型がrejectされたりしましたが、
それについては誰かが書いてくれる気がするので私はスルーして、もう少し小さなネタを書いていこうと思います。なんかC++Advent Calendarのレベルがやたらと高いので皆さんには常識なのかもしれませんがそれを言ったらネタがない
多分読者の方は「艦これ」について名前くらいは聞いたことがあると思います。
http://www.dmm.com/netgame/feature/kancolle.html
艦隊これくしょん -艦これ- - Wikipedia
『艦隊これくしょん -艦これ-』(かんたいこれくしょん かんこれ)は、角川ゲームスが開発しDMM.comがブラウザゲームとして配信している育成シミュレーションゲームおよび、そのメディアミックス作品群。ゲーム内容は、第二次世界大戦時の大日本帝国海軍の軍艦を中心とした艦艇を女性キャラクターに擬人化した「艦娘(かんむす)」をゲーム中で集め、強化しながら敵と戦闘し勝利を目指すというものである。2013年4月23日にブラウザ版のサービスを開始した
で、@YSRKEN さんをメイン開発者、 @sayurinさんと私がリファクタリング&高速化担当をして、艦これの戦闘をシミュレーションするソフトを作っています。
https://github.com/YSRKEN/KanColleSimulator_KAI
以下KCS_KAIと略します。
それからもう一つ、SigContrastFastAviUtlという
https://github.com/yumetodo/SigContrastFastAviUtl
コントラストをSigmoid関数にもとづいて変更する(マネー)フリーな動画編集ソフトAviUtlのプラグイン
https://github.com/MaverickTse/SigColorAviutl
を高速化したプラグインを開発したのですが、@MaverickTseさんのコードをベースに大規模なリファクタリングと高速化をしました。
このKCS_KAIとSigContrastFastAviUtlで多数の高速化をやった経験などをベースに、今日一般的なPCにおける高速化の技法を書いていこうと思います。
・・・前置き長いな。
まずはリファクタリングして可読性を上げる
省略します。やったことが多すぎるので詳細はcommit logでも眺めてください。
きちんと時間計測をして高速化の戦略を練る
想像と推測で高速化を始めてはいけません。どこがネックなのかを認識してから取り組みましょう。
計測はIDEやgprofのプロファイリング機能を使ってもいいですし、自力で時間計測コードを埋め込んでもいいと思います。
プロファイリングをするときは、ホットスポットでないルーチンの最適化は行わないようにしましょう。労力に見合わないですし、プログラミング基本原則である(でっち上げ)
プログラム 書かなければ バグらない
に反します。
ホットスポットの最適化をするときに、Functions With Most Indivisual Workの解析が役に立ったりします(後述するstd::vector::push_backのVSのおバカ実装はコレのお陰で見つかった)。
自力で時間計測コードを埋め込んでやるときは、計測は複数回行って、処理時間の95%信頼区間を求めてそれがコード変更の前後で重ならなくなるか明らかに重なることがわかるまで(10回以上は計測したい)計測しましょう。
Excelとかで数式うつの面倒だからC++で計算する!という人は
https://github.com/yumetodo/SigContrastFastAviUtl/blob/master/SigColorFastAviUtl/time_logger.hpp
こんな感じのコードで求められます。
_mm_div_psは遅いから_mm_rcp_psをニュートン-ラフソン法で高精度化して使おうみたいな記事を見かけて
楓 software: 逆数の高精度化
実装して計測したら
https://github.com/yumetodo/SigContrastFastAviUtl/pull/9/commits/50fba5aa61324c2c6eb6e4b44ff815179ed26042
1%(+-2.4% N=19)遅くなってたなんてこともありました。
注意点として、小さすぎる粒度での時間計測はあまり意味がありません。最近のCPUはパイプラインと言って、1clockに1命令なんてのんびりしたことはしないで、開いている演算機を稼働させて1clock1命令以上実行している。処理に依存性が少ないとこのパイプラインがうまく動く。というわけである程度大きめの粒度で計測しましょう。
メモリ律速なものはどうしようもない
特に映像処理の分野では、メモリ律速に悩まされることが多いです。メモリ律速なものは多くの場合高速化できないので、DDR4積んでるメモリーを使うとか、メモリー転送帯域の大きいハードウェアをつかうとかそういう話になります。
それでもどうにかこうにか高速化しようと奮闘している方もいるのですが。
rigayaの日記兼メモ帳 2015年を振り返る (エンコ編)
http://rigaya34589.blog135.fc2.com/blog-entry-715.html
自動フィールドシフト (afs)
今年は自動フィールドシフトを速くするネタを思いつけなかった。誠に遺憾である。
まあこれまでも結構速くしたのだけど、24pへのインタレ解除はこれしか使わないので、もっと速くしていきたい。とはいっても演算律速というわけではなくメモリ律速なので、できることが限られているのが辛い。
QSVEnc
QSVはハードウェアエンコーダの中でも高速で、画質もまあ、比較的よいほう。
今年の大半はQSVEncCのavqsv周りをやっていた気がする。QSVでデコード→Vpp→エンコードまでを一貫して行うavqsvモードは、QSV高速化のためには必須であり、やっとQSVEncCが他のQSVエンコーダと比べて遅いという嘆かわしい状態を解決できたと思う。高速化とは良いものだ。まあ、最終的にはメモリ速度律速なのだけど…。
映像処理はQSVとかNVEncみたいなハードウェアエンコーダー/デコーダーの登場でだいぶ前進した感あるけど結局はメモリ律速に悩まされるという。
昨年(2015年)バズったwaifu2xなんかはメモリー律速の最たる例で、それでもメモリー配置を予測して頑張ったりと奮闘している方をたくさん見かけましたね。
最内ループからはじめる深層学習(waifu2xの高速化)
http://int.main.jp/txt/waifu2x.html
私の脳みそでは上記リンク先はちょっと理解しきれないわけですが。
依存ライブラリが適切か調べる
https://github.com/MaverickTse/SigColorAviutl
と
https://github.com/yumetodo/SigContrastFastAviUtl
の最も大きい違いは、ImageMagickに依存しているか否かです。
ImageMagickは内部で関数呼出しを一度内部でコマンド文字列に変換してそれを再度パースして関数ポインタを介して処理をするとかいう、頭のおかしいことをやっていて、その結果
ImageMagickを使う=遅くなる=ImageMagickを使う者はC++erにあらず
という等式が成立するレベルで遅いです。
逆に適切なライブラリを選択すれば、下手に自分で書くより高速化できます。例えばOpenCVだとちゃんと掛けば自動で並列化したりGPU使ったりできますね。
アルゴリズムの見直し
当たり前といえば当たり前ですが、いくつか。
テーブル引き
SigContrastFastAviUtlの場合、Sigmoid関数という処理の肝があります。
f(u)=\frac{\frac{1}{exp(s(m - u)) + 1} - \frac{1}{exp(sm) + 1}}{\frac{1}{exp(s(m - 1)) + 1} - \frac{1}{exp(sm) + 1}}
s:strength m:midtone u:input
見るからに重そうな数式ですが、これを画像の画素数×映像のframe数回呼び出すことになるのでえげつない計算量が必要です。
しかしSigContrastFastAviUtlの場合、sとmは定数扱いでき、uは0-4096の計4097通りしか無いので事前にキャッシュしてあとでそれを参照するtable引きが有効です。
int *pDst, *pTable, *pIndex;
for (int i = 0; i < 8; i++) {
pDst[i] = pTable[pIndex[i]];
}
のような二重テーブル引きをやってくれるvpgatherdd命令なんてものがAVX2にはあって、Intel Haswellで導入され、Intel Broadwell以降(Skylake含む)では高速に動作するそうです。
int *pTable;
__m256i yDst, yIndex;
yDst = _mm256_i32gather_epi32(pTable, yIndex, 4);
詳細は
rigayaの日記兼メモ帳 PMD_MT 高速化版+5 gatherの速度とか
http://rigaya34589.blog135.fc2.com/blog-entry-849.html
へ。
ただし、SIMD化するときにtable引きするより愚直にSIMDの馬力を活かしてひたすら計算したほうが速いこともあるようなので都度どちらが速いか考える必要があります。
rigayaの日記兼メモ帳 PMD_MT 高速化版
http://rigaya34589.blog135.fc2.com/blog-entry-483.html
ところが、高速化にあたって導入したいSIMD演算はテーブル参照とはあまり相性が良くない。そこで今回のSIMD化による高速化では、「useExp」オプションがオフの時には、テーブル参照をやめて、愚直に浮動小数点演算によって行うようにした。テーブル参照をして演算量を減らすよりも、SIMDの馬力を活かしてひたすら計算したほうが速いみたい。(というより、AVXを使うと浮動小数点演算を一度に8演算、FMA3を使えば一度に16演算できるので、どちらかというとFMA3でゴリ押しできることを前提に作ってる…)
注意点ですが、テーブル引きするときは、テーブルの参照コストはO(1)にしましょう。
もっというと、テーブル引きにstd::map/std::unorderd_mapを使ってはいけません
逆関数かくの面倒だからといって元の関数を流用してstd::lower_boundで誤魔化そうとか思わずに頑張ってはO(1)にしましょう。
https://github.com/yumetodo/SigContrastFastAviUtl/pull/9
計算オーダーが全てではない
後述するメモリーアクセスパターンやメモリー確保のコストなどが原因で、計算オーダーが良くても最速ではないことがあります。
そのいい例が
C++で効率よく重複のない乱数列を生成する#結果
これでしょうか。
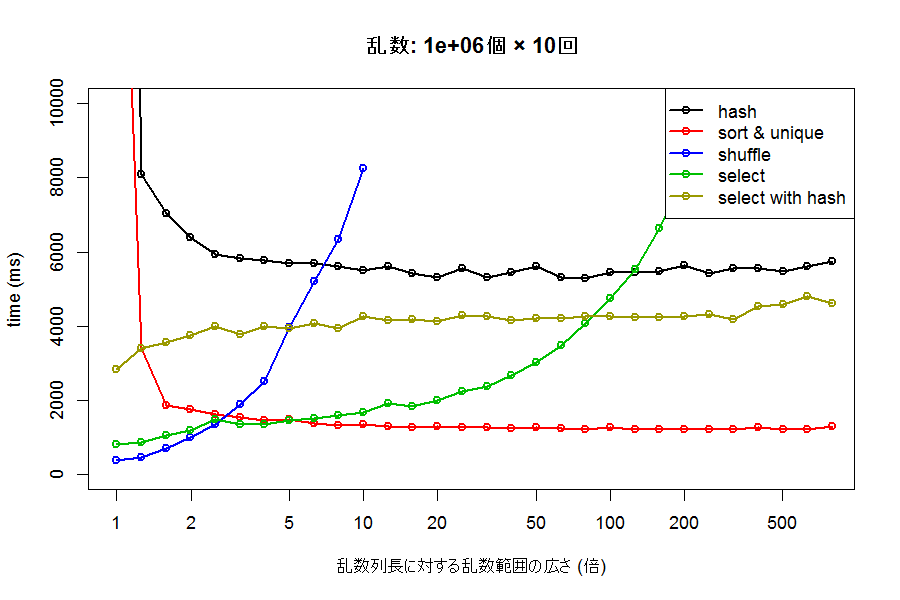
平らなグラフは計算オーダー的に優れていることを示しますが、最速ではないことが分かります。
メモリーアクセスパターンの改善
映像処理なんか書いていると、この辺が大事になってきます。
まず
CPUの気持ちになれるツール作った - ( ꒪⌓꒪) ゆるよろ日記
http://yuroyoro.hatenablog.com/entry/2014/10/20/102416
Remix: Latency Numbers Every Programmer Should Know(2014)
http://yuroyoro.net/latency.html
を見てみましょう。CPUの歓声CPUから見たアクセス速度が実感できます。
メモリー以外にCPUにはキャッシュがあります。このキャッシュにデータが乗っかりやすいようにメモリーアクセスをすることが大事です。
つまりシーケンシャルに(連続的に)メモリーアクセスしろということです。
また、SIMD化によってメモリーアクセス回数を減らすことも効果的です。
rigayaの日記兼メモ帳 自動フィールドシフト 高速化版+8
http://rigaya34589.blog135.fc2.com/blog-entry-360.html
afsには、メモリ空間に対し飛び飛びにアクセスする部分がある。こういった飛び飛びのアクセスは、非常に時間が掛かってしまう。
そもそも、(キャッシュに入っていない)メモリアクセスというのはとんでもなく遅い。メモリ上を飛び飛びにアクセスしていると特にひどい。
これに対し、オリジナルのafsでは、
- MMXの使用により、64bitまとめて処理
→64bitずつのアクセスになり、メモリアクセスの回数自体が減る。
により高速化していたし、さらにこれまでの高速化版では、
- SSEの使用により、128bitずつ処理
- prefetch命令の挿入により、必要になる飛び飛びのメモリの断片を明示的に先読み
して高速化していた。prefetch命令の挿入は非常に効果が大きかった(高速化の1/3ぐらいはprefetch命令のおかげだった)。
しかし、いくら先読みしているとはいっても、煩雑な飛び飛びのアクセスをしていることには変わりなく、根本的な解決にはなっていない。
今回の高速化版では、なるべく連続的なメモリアクセスをするようにプログラムを変更した。こうすることで、
- prefetch命令不要
- 効率的なメモリアクセス
となり、さらに高速化できた。
メモリーアクセスパターンといえばC++標準化委員会にflat_mapが提案されていましたね
本の虫: C++標準化委員会の文書: P0421R0-P0429R0
https://cpplover.blogspot.jp/2016/11/c-p0421r0-p0429r0.html
flat_mapと従来のmapのベンチマーク結果があるが、要素の挿入と削除はとても遅く、イテレートはとても速く、検索はmapより速いがunordered_mapよりは遅い結果となっている。そのデータ構造から考えて予想通りの特性だ。
また、メモリ使用量が少ない。これは当然の話で、mapを素直に実装するには左右の葉ノードと親ノードへの3個のポインターを持つノードによるバイナリツリーになる上に、メモリ確保をノード単位で行うためにメモリ管理のためのメモリも必要になる。また、連続したストレージ上に確保されるためキャッシュの局所性が最高だ。
シーケンシャルアクセスといえば今年のNHK技研の公開でシーケンシャルアクセスしかできない超高速にRead/Writeできる記憶媒体が紹介されていたなぁ・・・。詳細が思い出せないけど、映像の高精細化に伴うメモリー速度要求に対する一次バッファとしての利用を提案していたっけか。
さらに詳しいメモリーアクセスパターンの話は
[PDF注意]第9回 高速化チューニングとその関連技術2 | 渡辺宙志
に詳しく書かれているので参照してみてください。
OpenMPじゃなくてC++11のThreadを
つまりマルチスレッド化ですね。ループ間の作業に依存性が無いときはとりあえずマルチスレッド化するのが常道だと思います。
KCS_KAIでは最初に数個のスレッドを作るだけなのであまり関係ありませんが、SigContrastFastAviUtlのように映像処理なんかで画像一枚一枚単位でマルチスレッド化する場合はスレッド生成のコストが無視できないので、OpenMPは避けたほうが良いです。オーバーヘッドが大きいので。OpenMPはランタイムをstatic linkできないという問題もあります。
他のマルチスレッド化の選択肢としては
- VSのAuto-Parallelizer→自動変数領域の確保が信じられないほど遅い
- pthread→自力で叩きたくない
- Win32API→自力で叩きたくない
- Intel TBB
- Visual C++に付属するPPL
がありますが、せっかくC++11でstd::thread入ったので使いましょう。スレッド生成コストはVSのAuto-Parallelizerと同じか誤差レベルでstd::threadが速かったです。
とはいえスレッド生成とかタスク分割とかを自分で書かないといけないので
https://github.com/yumetodo/SigContrastFastAviUtl/blob/master/SigColorFastAviUtl/thread.hpp
こんな風に適当にラップしました。
C++17ではalgorithmヘッダーとかにある関数が引数一つ増やすだけで並列実行してくれるらしいので早く使いたいですね。例外周りもexception_listがあるのでより気軽に使えそうです。
追記:exception_listは死んだそうです。そういや本の虫にそんな話が出てたな、忘れてた。
本の虫: C++標準化委員会の文書: P0390R0-P0399R0
https://cpplover.blogspot.jp/2016/09/c-p0390r0-p0399r0.html
P0394R4: Hotel Parallelifornia: terminate() for Parallel Algorithms Exception Handling
並列アルゴリズムに渡した要素アクセス関数が例外を投げた時は、投げられた複数の例外がstd::exception_listに格納されて返されるという仕様になっている。しかし、実行ポリシーがpar_unseqの時だけはstd::terminate()を呼び出すとなっており、一貫性がない。
これを考えるに、一律std::terminate()を呼び出すことで統一したほうがよい。そのほうが生成されるコードも簡単になるし、exception_listに持ち上がっている数々の問題への対処も不要になる。
という変更をする提案。
std::vectorはreserveして使う
特にVisual Studioの付録のstd::vector::push_backの実装は腐っていて、std::vector::push_backを呼び出すたびに、現在の領域の大きさ+1のメモリーを確保して要素をすべてcopy/moveする、というのに近い状況が発生します。
https://t.co/lJApJ6CFOL
— Az (@azaika_) 2016年12月11日
このツイートについて今更検証したところ、VSはDebug/Releaseにかかわらず基数1.5でcapacityを増やしていくので、1~4までは1づつ増加するというだけだった
1.5倍ゲームでの実装のようです。reserveして使うべし、という結論に変わりはありませんが。@azaika_ どうやら最初に8要素分確保しておくようなことはしていないらしい(画像参照) pic.twitter.com/JCL0KGLksd
— Az (@azaika_) 2016年12月11日
cf.) https://github.com/YSRKEN/KanColleSimulator_KAI/issues/64#issuecomment-196514956
今日の一般的なPCは潤沢にメモリーがあるので、どんぶり勘定で大きめの領域をreserveしておくか、push_backのときに
vector</* some type */> re;
# ifdef _MSC_VER
if (v.capacity() < v.size() + 1) v.reserve((std::numeric_limits<size_t>::max() / 2 < v.size()) ? std::numeric_limits<size_t>::max() : v.size() * 2);
# endif
v.push_back(/* someting */);
のように強制的に倍々ゲームをするコードを書きましょう。
ちなみにGCCやClangは倍々ゲームをしてくれます。
メモリー確保を減らす
みんなstd::vectorが便利すぎて使いすぎてませんか?
実際適当に書いても動くしそこそこ速いので私も使っていますが、高速化のときはそれを見直す必要があります。
そもそもメモリー確保自体が無茶苦茶重いので高速化の際はそれを減らすことが大事です
具体的には、要素数が固定か、可変だけども最大数が決まっているものはすべてstd::arrayで書き換えるべきです。
// 生存艦から艦娘をランダムに指定する(航空戦用)
tuple<bool, size_t> Fleet::RandomKammusu() const {
//生存艦をリストアップ
std::array<size_t, kMaxUnitSize> alived_list;
size_t alived_list_size = 0;
for (size_t ui = 0; ui < this->GetUnit().front().size(); ++ui) {
if (this->GetUnit().front()[ui].Status() != kStatusLost) {
alived_list[alived_list_size] = ui;
++alived_list_size;
}
}
if (alived_list_size == 0) return tuple<bool, size_t>(false, 0);
return tuple<bool, size_t>(true, SharedRand::select_random_in_range(alived_list, alived_list_size));
}
このようにstd::array::size()はcapacityとして扱い、別にsizeを管理する変数を作ります。
std::vectorからstd::arrayへの置き換えはかなり強力で、KCS_KAIに施した高速化の1/3くらいは占めていると思います。
ただ、別に変数作るのはつらみがあるので、@bolero_MURAKAMI氏に問い合わせたところ
http://ask.fm/bolero_MURAKAMI/answers/137022673016
sproutにcapacity固定、sizeが0からcapacityの間で可変の配列クラスはあるか
valarray と sub_array>
との回答が来ましたが、今のところ私にはこのクラスの使い方がわかっていません。
なにもメモリー確保はstd::vectorだけではないので、当然その他のメモリー確保も注意が必要です。
http://rigaya34589.blog135.fc2.com/blog-entry-483.html
ほかにも毎フレームメモリを確保して破棄していたのをやめ、一度確保したメモリを使いまわすことでちょっと高速化した。(メモリの確保はとにかく遅いため、毎フレームメモリを確保→開放したりすると重くなる)
一度確保した領域はなるべく使いまわしましょう(初期化バグに注意)。
std::basic_string::opeartor==に注意せよ
またしてもVisual Studioの話ですが、ちょっとここでVisual Studio 2017 RCのリリースノートを見てみましょう。
- パフォーマンスの向上: basic_string::operator== は、文字列の内容を比較する前に文字列のサイズをチェックするようになりました。
なんだって!?今まで文字列比較は長さを見ていなかったの!?
まあお馬鹿なVSの話はさておき、場合によっては文字列のハッシュを計算しておいてそれを比較したり、enum classに変換しておくほうが高速になることがあります。
constexprは市民の義務です
C++規格への準拠が遅いVisual StudioでもC++11constexprがVisual Studio 2015 Update 2 から使えるようになりました。これにより、C++ Builder(not clang_based version)とかいう糞を無視すれば、我々はconstexprを使えるという人権を得ました。
もちろんC++11constexprは相当制約がきつく、ひたすら3項演算子と再帰と戯れる世界ですが、それでもいろいろできることはあります。
プリプロセス時ファイル読み込み+コンパイル時処理→コンパイル時DB構築
https://github.com/YSRKEN/KanColleSimulator_KAI/pull/46
https://github.com/YSRKEN/KanColleSimulator_KAI/pull/57
https://github.com/YSRKEN/KanColleSimulator_KAI/pull/62
でそんなことをやるコードを@sayurin氏が実装したので要約して紹介します。
材料
- 細工したcsvファイル
#includeconstexprstd::integral_const- UDLs
- プリプロセッサマクロ関数少々
まず
艦船ID,艦名,艦種,耐久,装甲,火力,雷撃,対空,運,速力,射程,スロット数,搭載数,回避,対潜,索敵,初期装備,艦娘フラグ
1,睦月,2,13/24,5/18,6/29,18/59,7/29,12/49,10,1,2,0/0/0/0/0,37/79,16/39,4/17,1/37/-1/-1/-1,1
2,如月,2,13/24,5/18,6/29,18/49,7/29,10/49,10,1,2,0/0/0/0/0,37/69,16/39,4/17,1/-1/-1/-1/-1,1
6,長月,2,13/24,5/18,6/29,18/49,7/29,15/69,10,1,2,0/0/0/0/0,37/69,16/39,4/17,1/-1/-1/-1/-1,1
7,三日月,2,13/24,5/18,6/29,18/49,7/29,10/49,10,1,2,0/0/0/0/0,37/69,16/39,4/17,1/-1/-1/-1/-1,1
9,吹雪,2,15/29,5/19,10/29,27/79,10/39,17/49,10,1,2,0/0/0/0/0,40/89,20/49,5/19,2/13/-1/-1/-1,1
10,白雪,2,15/29,5/19,10/29,27/69,10/39,10/49,10,1,2,0/0/0/0/0,40/79,20/49,5/19,2/-1/-1/-1/-1,1
こんな感じのcsvがあります。これを
//PREFIX,艦船ID,艦名,艦種,耐久,装甲,火力,雷撃,対空,運,速力,射程,スロット数,搭載数,回避,対潜,索敵,初期装備,艦娘フラグ,POSTFIX
SHIP(,1,"睦月",2,13.24,5.18,6.29,18.59,7.29,12.49,10,1,2,0.0.0.0.0,37.79,16.39,4.17,1.37.-1.-1.-1,1,)
SHIP(,2,"如月",2,13.24,5.18,6.29,18.49,7.29,10.49,10,1,2,0.0.0.0.0,37.69,16.39,4.17,1.-1.-1.-1.-1,1,)
SHIP(,6,"長月",2,13.24,5.18,6.29,18.49,7.29,15.69,10,1,2,0.0.0.0.0,37.69,16.39,4.17,1.-1.-1.-1.-1,1,)
SHIP(,7,"三日月",2,13.24,5.18,6.29,18.49,7.29,10.49,10,1,2,0.0.0.0.0,37.69,16.39,4.17,1.-1.-1.-1.-1,1,)
SHIP(,9,"吹雪",2,15.29,5.19,10.29,27.79,10.39,17.49,10,1,2,0.0.0.0.0,40.89,20.49,5.19,2.13.-1.-1.-1,1,)
SHIP(,10,"白雪",2,15.29,5.19,10.29,27.69,10.39,10.49,10,1,2,0.0.0.0.0,40.79,20.49,5.19,2.-1.-1.-1.-1,1,)
こんな感じに細工します。
この変換はもちろん自動化できます。
(Feat)generate csv for cpp by yumetodo · Pull Request #174 · YSRKEN/KanColleSimulator_KAI
試しにpowershellとbash scriptで自動化しました
次に
enum class ShipId {
# define SHIP(PREFIX, ID, NAME, SHIPCLASS, MAX_HP, DEFENSE, ATTACK, TORPEDO, ANTI_AIR, LUCK, SPEED, RANGE, SLOTS, MAX_AIRS, EVADE, ANTI_SUB, SEARCH, FIRST_WEAPONS, KAMMUSU_FLG, POSTFIX) \
I ## D ## ID = ID,
# include "ships.csv"
# undef SHIP
};
SHIPという関数マクロを作って、変換しているんですね。同様にして
enum class ShipClass {
PT = 0x00000001, // 魚雷艇
DD = 0x00000002, // 駆逐艦
CL = 0x00000004, // 軽巡洋艦
CLT = 0x00000008, // 重雷装巡洋艦
CA = 0x00000010, // 重巡洋艦
CAV = 0x00000020, // 航空巡洋艦
CVL = 0x00000040, // 軽空母
CC = 0x00000080, // 巡洋戦艦
BB = 0x00000100, // 戦艦
BBV = 0x00000200, // 航空戦艦
CV = 0x00000400, // 正規空母
AF = 0x00000800, // 陸上型
SS = 0x00001000, // 潜水艦
SSV = 0x00002000, // 潜水空母
LST = 0x00004000, // 輸送艦
AV = 0x00008000, // 水上機母艦
LHA = 0x00010000, // 揚陸艦
ACV = 0x00020000, // 装甲空母
AR = 0x00040000, // 工作艦
AS = 0x00080000, // 潜水母艦
CP = 0x00100000, // 練習巡洋艦
AO = 0x00200000, // 給油艦
};
namespace detail {
constexpr std::pair<cstring<wchar_t>, ShipId> shipIdMap[] = {
# define SHIP(PREFIX, ID, NAME, SHIPCLASS, MAX_HP, DEFENSE, ATTACK, TORPEDO, ANTI_AIR, LUCK, SPEED, RANGE, SLOTS, MAX_AIRS, EVADE, ANTI_SUB, SEARCH, FIRST_WEAPONS, KAMMUSU_FLG, POSTFIX) \
{ L##NAME, ShipId::I##D##ID },
# include "ships.csv"
# undef SHIP
};
constexpr std::pair<cstring<wchar_t>, ShipClass> shipClassMap[] = {
{ L"魚雷艇", ShipClass::PT },
{ L"駆逐艦", ShipClass::DD },
{ L"軽巡洋艦", ShipClass::CL },
{ L"重雷装巡洋艦", ShipClass::CLT },
{ L"重巡洋艦", ShipClass::CA },
{ L"航空巡洋艦", ShipClass::CAV },
{ L"軽空母", ShipClass::CVL },
{ L"巡洋戦艦", ShipClass::CC },
{ L"戦艦", ShipClass::BB },
{ L"航空戦艦", ShipClass::BBV },
{ L"正規空母", ShipClass::CV },
{ L"陸上型", ShipClass::AF },
{ L"潜水艦", ShipClass::SS },
{ L"潜水空母", ShipClass::SSV },
{ L"輸送艦", ShipClass::LST },
{ L"水上機母艦", ShipClass::AV },
{ L"揚陸艦", ShipClass::LHA },
{ L"装甲空母",ShipClass::ACV },
{ L"工作艦", ShipClass::AR },
{ L"潜水母艦", ShipClass::AS },
{ L"練習巡洋艦", ShipClass::CP },
{ L"給油艦", ShipClass::AO },
};
}
cstringは変更操作ができないコンパイル文字列クラスと思ってください。
https://github.com/YSRKEN/KanColleSimulator_KAI/blob/master/KCS_CUI/source/cstring.hpp
そうしたら
// 文字列から艦船IDへ変換します。
# define SID(STR) (std::integral_constant<ShipId, Single(detail::shipIdMap, L##STR##_cs)>{}())
// 文字列から艦種へ変換します。
# define SC(STR) (std::integral_constant<ShipClass, Single(detail::shipClassMap, L##STR##_cs)>{}())
こんなマクロを追加します。_csはcstringを作るUDLsで、Singleは分割統治法を使って第1引数に与えられた配列から第2引数の文字列に対応する値を取ってくるconstexpr関数です。
std::integral_constantを噛ませている理由ですが、こうしないで例えばこれ自体もUDLsにすると、コンパイル時に評価してくれなかったので、強制的にコンパイル時にSingle関数を走らせるためにtemplate実引数で呼び出すためです。で、毎回std::integral_constantと書くのは辛いのでマクロを使っています。
こうすることで、例えばSID("五十鈴改二")とすることでenum classであるShipId型にコンパイル時に変換できたり、SC("戦艦")とすることでenum classであるShipClass型にコンパイル時に変換できたりします。
残念ながらKCS_KAIではコンパイル時にDB検索まではしていませんが、実装は可能だと思います(将来実装したい)。
コンパイル時にDB検索まではしていないものの、文字列でのstd::unorderd_map検索より遥かに高速化できています。また、ついでに動的確保を減らせているのでさらなる高速化に寄与しています。
cpp(≠c++)の勝利! https://t.co/4EBEkVZm6d
— はぇ~☆ (@haxe) 2016年12月8日
条件分岐予測を成功させる
御存知の通り、CPUは条件分岐予測を行っています。その詳しい仕組みはCPU屋の腕の見せ所ですしすでにたくさん解説があるのでばっさりカットして、問題は条件分岐予測に失敗したときのコストが大きいことです。
とはいえ普通はそんなコストは埋もれて見えないのですが、処理内容によっては重要な事があります。
条件分岐予測がうまくいくと、
曰記 | 12月14日(水) Hiroshi Watanabe Home Page
のように、SIMD化するより速くなることがあるようです(データの依存性が関係する)
コンパイラにヒントを与える
GCC/Clangには__builtin_expectがあります。これは
# define likely(x) __builtin_expect(!!(x), 1)
# define unlikely(x) __builtin_expect(!!(x), 0)
のようにして
if(unlikely(0 != errno)) goto fail;
みたいに使います。Linuxカーネルではよく使われているようで、これをC++のattributeとして
if([[unlikely]] 0 != errno) goto fail;
追加する提案がC++標準化委員会に上がっていました。
本の虫: C++標準化委員会の文書: P0471R0-P0479R0
https://cpplover.blogspot.jp/2016/11/c-p0471r0-p0479r0.html
P0479R0: Attributes for Likely and Unlikely Branches
条件分岐の分岐が実行される頻度をヒントとして与える属性、[[likely]]と[[unlikely]]の提案。
Profile Guided Optimization
コンパイル時に条件分岐を予測できないなら、一度実行してみてプロファイルをとればいいじゃない、というのがPGOビルドです。他にも関数をinline展開したりします。
GCCでは-fprofile-generateをつけてコンパイルして一度実行し、今度は-fprofile-useをつけてコンパイルすればいいようです。
Visual StudioでもCommunity版でPGOビルドできます。
まあそこまで手間もかからないのでやって損はしないかなぁ・・・。
条件分岐をbit演算にして消す
分岐予測を成功させる手段を書きましたが、分岐がほぼ同確率な時はどうにもなりません。
そこで活躍することがあるかもしれないのがbit演算です。bit演算はSIMDとの相性も良いので、条件分岐がネックな場合は切り札になるかもしれません。
ビット演算についてはガチ勢?の方たちが
ビット演算テクニック Advent Calendar 2016 - Adventar
http://www.adventar.org/calendars/1403
記事を書いています。
先程から何回か名前が出てきた @YSRKEN さんが開発中の連珠の解法探索ソフトShioiでは現在判定の多くをSIMD化したbit演算で行うという暴挙快挙に出ようとしています
YSRKEN/Shioi at add_iona
https://github.com/YSRKEN/Shioi/tree/add_iona
これの解説記事が
YSR研究所 |連珠をビットボードで表現してみる【ビット演算テクニック Advent Calendar 2016 6日目】
http://ysrken.blog.fc2.com/blog-entry-86.html
ビットボードの凄さをざっくりと解説してみる
http://qiita.com/YSRKEN/items/29829c7f5beae7900f36
本人が執筆していらっしゃるので読んでみると面白いと思います。
まとめ
- 気分で高速化しない、きちんと計測して戦略を練ってから
- アルゴリズムの選択は計算オーダーばっかりじゃなくて、メモリー確保回数やメモリーアクセスパターンのことも考えよう
- メモリー確保はとにかく重いから消し飛ばせ、
std::array強い - コンパイル時にできることはコンパイル時に
終わりに
ちょっと来週のAdCの準備に手間取ってたらこの記事書くの遅れましたすみません。もう少し絵をいれて説明したかったけど文字ばっかになってしまった。
C++Advent Calendar 2016
明日はFuyutsubakiさんがなんか書くそうです。~~何を書くんでしょうかねぇ・・・(震え)。~~マクロからのC++17で追加された構造化束縛の活用例でした。
[<< 7日目 | C++形式の共有ライブラリの書き方(gcc編)](http://qiita.com/Chironian/items/3fb61cffa2a20dbee5c2) || 9日目 | [最近書いたマクロ(構造体をtupleに変換したい) - TXT.TXT](http://txt-txt.hateblo.jp/entry/2016/12/09/225148)/[それでも構造体をtupleに変換したい - TXT.TXT](http://txt-txt.hateblo.jp/entry/2016/12/09/225641) >>