更新記録
2015/9/30: select方式を追加した結果、結論が大きく変わりました
2015/10/1: @nmby さんの助言を受けて、selectの正式名「Fisher-Yates法」を追記し、unordered_mapを併用した方法もさらに比較しました。
2015/10/3: より細かい区切りで所要時間を計算したところ、shuffleが速くなる場合が出てきたため、一部記述を修正しました。
概要
C++で重複のない乱数列(整数)を生成する方法を、いくつか比較してみました。結果、
- 必要な乱数の数が、乱数範囲に比べて比較的少ない場合、
std::vectorに乱数を生成し、std::sortとstd::uniqueを適用するのが、重複しない乱数列を最も速く生成できる。 - 必要な乱数の数が、乱数範囲に比べて比較的多い場合(手元の環境だと、生成したい乱数範囲中の整数のおおよそ10%以上)、範囲に含まれる整数を全て
std::vectorにいれてからランダムに必要な数だけ抜き出す、Fisher-Yates法が速い。 - アルゴリズムの使い分けをせずに幅広い条件で利用したい場合には、
std::unordered_mapを利用したFisher-Yates法が安定した速度で生成できる。 - 必要な乱数の数が、乱数範囲に比べてかなり多い場合を除いて、範囲に含まれる整数を全て
std::vectorにいれてから、std::shuffleする方法は非常に遅い。速度を重視するなら避けるべきである。
乱数の数に応じて、常により速度の速いと思われるアルゴリズムを自動的に使いわける関数を、@yumetodo さんが書いてくださいました。多少手を加えたものをGit Hubにて公開中です。
nonrepeat_random_integrals.hpp
sample_nonrepeat_random_integrals.cpp
発端
こんな記事を見つけました。
配列を重複なく乱数で埋めるには @yumetodo
内容は、C++で (i)ランダムな順に並んでいる (ii)重複のない乱数配列 を生成したい、という記事です。要は、どうやって重複を取り除きつつ乱数列を生成すればよいか、というお話です。
いつか自分でも使いそうなケースです。
@yumetodo さんの報告では、
-
std::unordered_mapでインデックスを作って重複チェックする -
std::vectorに対する線形探索 -
std::unordered_setを使う
の3つの方法を比較し、std::unordered_setに乱数を必要数となるまで詰めていくのが一番速い、とのことです。
そこで、今回はstd::unordered_setを使う方法(以下、hashと呼びます)に加えて、新たに四つの方法を考えて、速度比較をしてみました。
1. sort & unique
一つ目は、std::vectorに乱数を生成し、std::sortとstd::uniqueで重複を取り除く方法です。以下、この方法をsort & uniqueと呼びます。なお、コードの一部は@yumetodo さんの上記記事 から引用しています。
std::vector<int> make_rand_array_unique(const size_t size, int rand_min, int rand_max){
if(rand_min > rand_max) std::swap(rand_min, rand_max);
const size_t max_min_diff = static_cast<size_t>(rand_max - rand_min + 1);
if(max_min_diff < size) throw std::runtime_error("引数が異常です");
std::vector<int> tmp;
auto engine = create_rand_engine();
std::uniform_int_distribution<int> distribution(rand_min, rand_max);
const size_t make_size = static_cast<size_t>(size*1.2);
while(tmp.size() < size){
while(tmp.size() < make_size) tmp.push_back(distribution(engine));
std::sort(tmp.begin(), tmp.end());
auto unique_end = std::unique(tmp.begin(), tmp.end());
if(size < std::distance(tmp.begin(), unique_end)){
unique_end = std::next(tmp.begin(), size);
}
tmp.erase(unique_end, tmp.end());
}
std::shuffle(tmp.begin(), tmp.end(), engine);
return std::move(tmp);
}
あらかじめ要求する乱数の数より少し多め(上記コードでは要求数の1.2倍)に乱数生成し、ソートしてから、重複分を std::uniqueで特定し削除しています。これを、要求する乱数列長になるまで繰り返します。
2. 範囲中の数列をシャッフル
二つ目は、愚直に [rand_min, rand_max] となる数列を生成し、それをstd::shuffleにかけた後、必要な部分だけ取り出す方法です。以下、この方法をshuffleと呼びます。
std::vector<int> make_rand_array_shuffle(const size_t size, int rand_min, int rand_max){
if(rand_min > rand_max) std::swap(rand_min, rand_max);
const size_t max_min_diff = static_cast<size_t>(rand_max - rand_min + 1);
if(max_min_diff < size) throw std::runtime_error("引数が異常です");
std::vector<int> tmp;
tmp.reserve(max_min_diff);
for(int i = rand_min; i <= rand_max; ++i)tmp.push_back(i);
auto engine = create_rand_engine();
std::shuffle(tmp.begin(), tmp.end(), engine);
tmp.erase(std::next(tmp.begin(), size), tmp.end());
return std::move(tmp);
}
見てのとおり、考えている範囲の全ての数字を用意してシャッフルする、という非常に乱暴なことをやっています。生成したい乱数の範囲が広いほど、パフォーマンスは落ちると思われます。
3 範囲中の数列から必要数のみ選択(vectorを使うFisher-Yates法)(9/30追加)
上記shuffleでは、数列全体をシャッフルしていますが、必要なのはsize個だけです。よって、最初のsize個だけ範囲中の数列からランダムに選べば、より効率よくsize個の乱数列を生成できることになります。以下、この方法をselectと呼びます。
(10/1追記)
Fisher-Yates法という名前が正式についているようです。@nmby さん、ありがとうございます。
std::vector<int> make_rand_array_select(const size_t size, int rand_min, int rand_max){
if(rand_min > rand_max) std::swap(rand_min, rand_max);
const size_t max_min_diff = static_cast<size_t>(rand_max - rand_min + 1);
if(max_min_diff < size) throw std::runtime_error("引数が異常です");
std::vector<int> tmp;
tmp.reserve(max_min_diff);
for(int i = rand_min; i <= rand_max; ++i)tmp.push_back(i);
auto engine = create_rand_engine();
std::uniform_int_distribution<int> distribution(rand_min, rand_max);
for(size_t cnt = 0; cnt < size; ++cnt){
size_t pos =std::uniform_int_distribution<size_t>(cnt, tmp.size()-1)(engine);
if(cnt != pos) std::swap(tmp[cnt], tmp[pos]);
}
tmp.erase(std::next(tmp.begin(), size), tmp.end());
return std::move(tmp);
}
shuffleとの違いは、後半部分でシャッフルせず、size個だけ前方にランダムに集めてきている点です。shuffleと同じく、生成したい乱数の範囲が広いほど、パフォーマンスは落ちると思われますが、乱数自体はsize個しか使用しない分高速になるはずです。
4 unordered_mapを使うFisher-Yates法(10/1 追加)
@nmby さんから有益な情報を頂きました。ありがとうございます!
select と仰っているのはいわゆるフツーの Fisher-Yates 法ですね。
やはり後半は乱数範囲に対してリニアになりますね。↓この部分が効いています。
for(int i = rand_min; i <= rand_max; ++i)tmp.push_back(i);もう一工夫加えることで、平らなグラフになりますよ。
なんと! ちゃんと名前のついた有名な方法だったばかりか、「もう一工夫」加えることで乱数範囲に対して速度が安定化するようです。やっぱり、ちゃんとアルゴリズムやデータ構造はきちんと勉強すべきですね。反省しきりです。
コメントのリンク先を読んでみたところ、どうも辞書型コンテナを使うことで、あらかじめ乱数範囲の数列を作ることなしに、selectと同様の処理が可能となるようです。となると、C++ではunorered_mapの出番でしょう。
自分のコードの理解が間違っていなければ、下記のようにかけるはずです。以降、この方法をselect with hashと呼びます。
std::vector<int> make_rand_array_select_with_hash(const size_t size, int rand_min, int rand_max){
if(rand_min > rand_max) std::swap(rand_min, rand_max);
const size_t max_min_diff = static_cast<size_t>(rand_max - rand_min + 1);
if(max_min_diff < size) throw std::runtime_error("引数が異常です");
using hash_map = std::unordered_map<type, type>;
std::vector<type> tmp;
tmp.reserve(size);
hash_map Map;
auto engine = create_rand_engine();
for(size_t cnt = 0; cnt < size; ++cnt){
type val = std::uniform_int_distribution<type>(rand_min, rand_max)(engine);
hash_map::iterator itr = Map.find(val);
type replaced_val;
hash_map::iterator replaced_itr = Map.find(rand_max);
if(replaced_itr !=Map.end()) replaced_val = replaced_itr->second;
else replaced_val = rand_max;
if(itr == Map.end()){
tmp.push_back(val);
if(val!=rand_max)Map.insert(std::make_pair(val, replaced_val));
} else{
tmp.push_back(itr->second);
itr->second = replaced_val;
}
//Map.erase(replaced_val);
--rand_max;
}
return tmp;
}
イメージとしては、hashやsort & unique のほうが近いかもしれません。乱数を生成してそれをコンテナ(vector)に入れていくのですが、一度出た乱数はそれ以降は不要です。そこで、次回以降その数字が出た際は、別の数字(上のコードではその時生成される乱数の最大値)として解釈し、その代りに以降その別の数字は乱数として出ないようにします(コードでは、乱数の最大値を毎回下げています)。
例えば、乱数の生成範囲が[0,5]の場合を考えます。
{0,1,2,3,4,5}
[0,5]で乱数を生成して、2が出たとします。2を戻り値用のコンテナに登録します。次回以降は2を今回の最大値である5と解釈し、代わりに乱数の最大値を4に変えます。
{0,1,2(5),3,4} ans:{2}
[0,4]で乱数を生成して、また2が出たとします。先ほどの結果から、2は5が出たとして解釈する必要があるので、5を戻り値用のコンテナに登録します。次回以降は2を今回の最大値である4と解釈しますし、代わりに乱数の最大値を3に変えます。
{0,1,2(4),3} ans:{2,5}
以降、同様に繰り返していくことで、重複のない乱数配列を、最少の乱数生成回数で作ることができます。
上記の例の2(5)や2(4)に当たる部分を覚えておくのが、unordered_mapの役割です。
結果
ベンチマークに使用したソースコードはgithubにあります。
nonrepeat_rand_array.hpp
use_nonrepeat_rand_array.cpp
コンパイラは、Visual Studio 2015 Communityです。
注:環境によって以下の結果は大きく左右されるようです。十分な繰り返しもしていない、ゆるゆるな検証実験なので、それを踏まえてご覧ください。
生成したい乱数の範囲(rand_minとrand_max)を変えながら、1万個の乱数を1000回ずつ生成させてみた時の所要時間が以下のグラフです。縦軸が生成に要した所要時間、横軸が、指定した乱数生成範囲中に含まれる整数の個数が、生成する乱数の何倍存在するか、です。左端が1倍、つまり1万個すべて必要な場合で、以降10倍(10万個の中から1万個)、100倍(100万個の中から1万個)・・・と続きます。
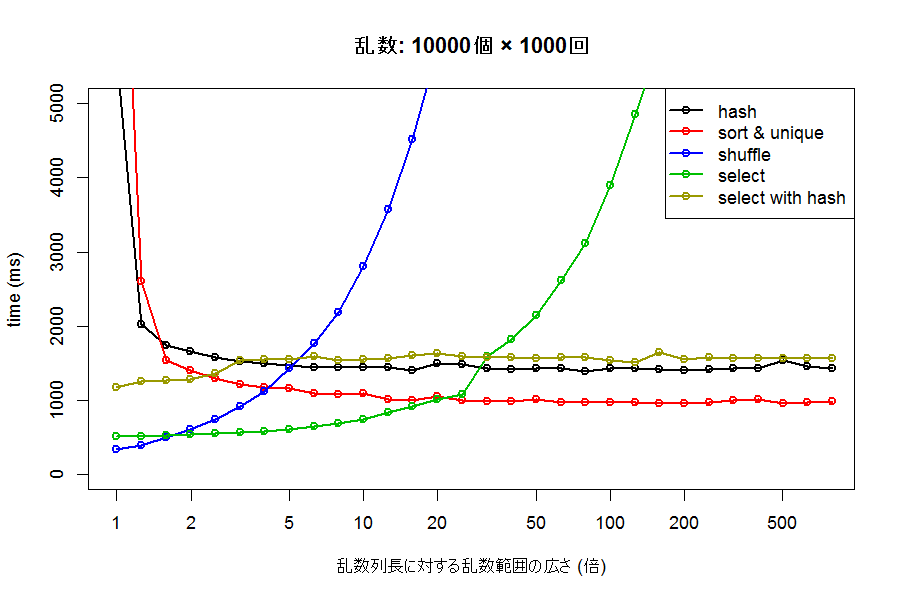
グラフを見ると、hash や sort & unique は、乱数範囲が狭い場合の性能は最悪ですが、ある程度広い乱数範囲を持つ場合は比較的安定した速度を出しています。性能としては、std::unordered_setを使ったhashよりも、std::vectorから重複を消したsort & uniqueのほうが多くの場合高速なことが分かります。これはおそらく、std::unordered_setへの要素追加に、それなりにコストがかかっているためと思われます。単純構造のstd::vector恐るべし。
一方、shuffle や select (vectorを使うFisher-Yates法) は、乱数範囲が狭いときには非常に高速ですが、乱数範囲が広くなるにつれ、急速にパフォーマンスが悪化しています。特に、shuffleは速度の低下が顕著です。乱数範囲が特に狭い場合にはshuffleのほうが、それより広い場合はselectのほうが性能がよさそうです。
select with hash(std::unordered_mapを使うFisher-Yates法)は、乱数範囲に関わらず非常に安定した速度で生成できています。しかし、sort & uniqueやselect、shuffleなどと比べて速いわけでないようです。これも、hashと同じく、unordered_mapへの要素追加に、それなりにコストがかかってしまっているためではないかと思われます。
次に、生成する乱数の数を変えてみましょう。100個の乱数を100000回、100万個の乱数を10回生成した場合の結果が、それぞれ下のグラフです。
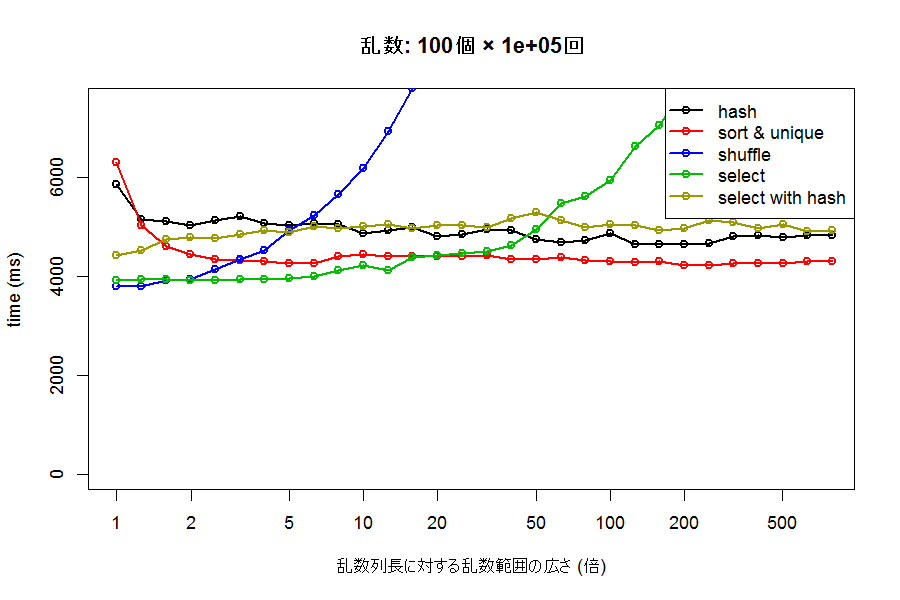
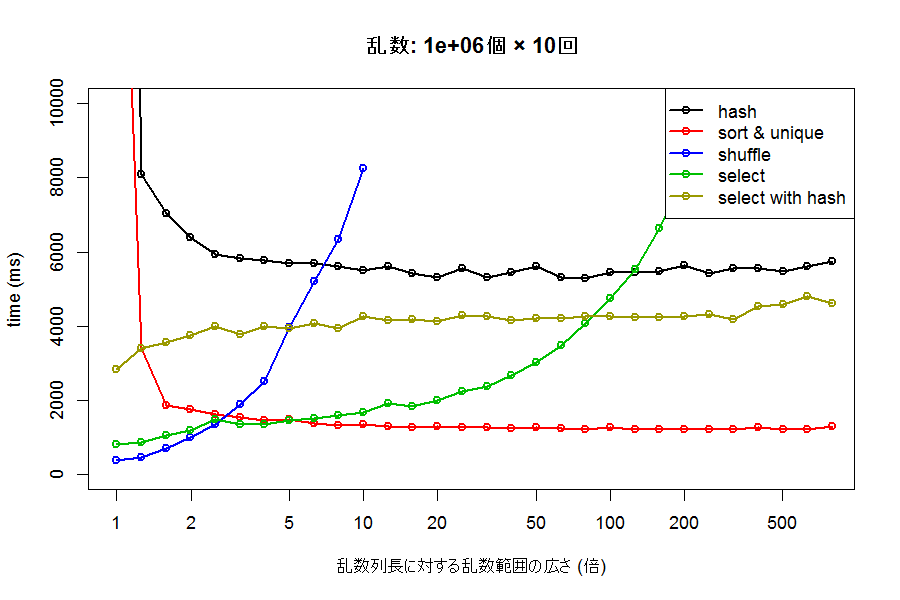
一度に生成する乱数列の長さが長いほど、各手法の速度差が大きく出るようですが、それでも全体としての傾向は大きく変わらないようです。乱数範囲が必要数に対して広いときには、sort & uniqueが、狭いときにはselectが、極端に狭いとshuffleがもっとも高速なアプローチとなるようです。
select が sort & unique の速度を上回るのは、生成する乱数の数に関わらず、おおよそ乱数生成範囲に含まれる整数が、必要な乱数の数の5倍~20倍程度以下の時のようです。目安としては、おおよそ乱数生成範囲中の整数の10%以上を必要とする場合に当たるでしょうか。同じく、shuffle が select を上回るのは、2倍程度以下、つまり、おおよそ乱数生成範囲中の整数の半分以上を必要とする場合といえそうです。例えば、0~1000 の整数を、重複なくランダムにほしい場合、必要な数が約100個以下であれば sort & uniqueを、500個以下であればselect(vectorを使うFisher-Yates法)を、それ以上必要な場合にはshuffleを使うのが最もパフォーマンスが良くなりそうです。ただし、これらの数字がどのコンパイラ/実行環境によっても非常に左右されそうです。
結論・考察
- 必要な乱数の数に対して比較的広い乱数生成範囲の中から乱数列を生成する場合、
std::vectorに対してstd::sortとstd::uniqueを適用する方法が、重複のない乱数生成は最も早くなるようです。 - 一方で、少なくとも手元の環境では、必要な乱数の数が乱数生成範囲中の整数の約10%程度より多ければ、(メモリを気にしなければ)生成したい範囲中の全ての整数列を
std::vectorに生成後、ランダムに選びだす、std::vectorを使ったFisher-Yates法が速いようです。 - 乱数生成範囲や生成数に関わらず、安定した速度を出していたのは
std::unordered_mapを使ったFisher-Yates法でした。状況に応じたアルゴリズムの使い分けをしない場合には、std::unordered_mapを使ったFisher-Yates法が平均的に見れば最も優秀かもしれません。 - 特に乱数生成範囲が広い場合、ハッシュテーブルを使う方法、つまり**
std::unordered_setを使って重複を取り除く方法やstd::unordered_mapを使ったFisher-Yates法**は、std::vectorに対してstd::sort&std::uniqueを適用する方法に対して、**速度面で劣っていました。**これは、std::unordered_setやstd::unordered_mapに対する要素の挿入コストが、意外と大きいためだと思われます。一般にハッシュテーブルは検索が高速な非常に優秀なコンテナですが、検索頻度が要素の追加頻度に比べて低い場合には、std::vectorなどの要素追加が高速なコンテナにstd::sortを併用した方がよいのかもしれません。 -
std::vectorに乱数生成範囲中の整数を全て入れてstd::shuffleする方法は、乱数生成範囲が広くなると急速にパフォーマンスが悪化します。乱数範囲中のほとんどを取得する場合を除き、速度面を重視する場合は避けるべき方法でしょう。 - 今回のsort & uniqueでは、何の根拠もなく、要求された乱数の1.2倍だけ、乱数をあらかじめ生成していますが、この倍率はより最適化できる可能性があります。おそらく、必要な乱数の数が、乱数生成範囲中の整数の数に比べて少ないほど、この倍率も低くてよいでしょう。
謝辞
この記事の元ネタである「配列を重複なく乱数で埋めるには」を執筆された @yumetodo さんと、その記事内でstd::vectorへの線形探索用のコードを書かれた @AinoMegumi さんに、コードの流用をお詫びするとともに、興味深い問題提起をして頂いたことに感謝いたします。
また、Fisher-Yates法というselectの正式なアルゴリズム名とともに、4つ目の方法をご教示頂いた@nmby さんに、深く感謝します。