C++ Advent Calendar 2018
この記事はC++ Advent Calendar 2018 15日目の記事です。
- 14日目: VTKライブラリ
- 16日目: C++のエラー処理との付き合い方
当初見積もりよりも大幅に長い記事となり、投稿したのは12/22で1週間遅刻です。すみません。
お知らせ
cpprefjpにchar8_t型追加について解説を書きました。ぎゅぎゅっとコンパクトに、また査読を受けて中立的な表現で書いていますので、よければどうぞ。
UTF-8エンコーディングされた文字の型としてchar8_tを追加 - cpprefjp C++日本語リファレンス
追記
全ての開発者が知っておくべきUnicodeについての最低限の知識 - GIGAZINE
Unicodeについて簡潔にまとまってるいい記事を見つけました。
Caution
この文章には以下の要素が含まれます。苦手な方はご注意くださいね~。
- 西欧人への偏見
- C++の始祖への反論
- 日本語に偏った文章
- アジア圏に偏った文章
- 常体と敬体の入り乱れた文章
- 溢れ出た強烈な感情が
打ち消し線で表されている - 要出典
- 独自研究
- 不十分な/誤りのある英語→日本語翻訳
- Unicode策定に関わった人たちへのdisり
- 絵文字に関わった人たちへのdisり
- にこにこ(く)
- 江添亮氏のブログからの引用
- auに偏った絵文字観
- EUC軽視
- チベット語話者軽視
Unicodeとか
今回のchar8_t型を語る前にまずUnicodeについて話さねばならん。ここがすべての原点だからだ。
とはいえ探せば優れた記事が存在し、というか私は実のところさほど詳しくない。
でも書いちゃう。文字コードに散々苦しめられながら生活してきた人間として。
しかし感情が高ぶるあまり事実誤認している可能性が高い。このセクションはさーっと読み流しつつ詳しく知りたいなら参考資料のリンクを張っておくので通読されることを勧める。
そもそもUnicodeとはなにか
Unicode前夜、コンピュータで文字を扱うには各地域ごとの文字セットがあり、必要の応じてこれを切り替えて文字を扱っていた。
しかしソフトウェアを世界的に発売するようになるとローカライズの作業時にこれでは不都合があり、全部の文字を扱える文字セットが必要だろうという声が上がった。
そういった文字セットを作るべく、大きく2つの団体が舞台となりさながら戦争のような争いを経て現代に至る。ISOの文字コード規格委員会 (ISO/TC 97/SC2) とユニコードコンソーシアムである。
Unicodeにおけるエンコードとコードポイントとグリフとフォント
極めて混同しやすいので、きっちり分離して理解する必要がある。
まずグリフ(字体)がある。これは、ある文字がどういう特徴をもったものなのかを規定する。
フォント(書体)はグリフの要求を満たしつつ、デザイン性を加味したものだ。
コードポイントとはUnicodeで文字を扱うのに、グリフに背番号を付けたようなものだ。
そしてエンコードとはコードポイントをコンピューターで扱うに際してどのようなbinary列にするかを定めるものである。
追記:
グリフについては議論の余地があったようだ
char8_tによせて - なるせにっき
グリフ(glyph)という言葉の定義をめぐってでも触れられていますが、「グリフ」という言葉が「字体」を指すのか「字形」を指すのかってのは議論がありますね。文字コードの文脈では普通「字形」の意味だとして話を進めることが多いように思います。
火種は何処に
メモリー消費との戦い
そもそもコンピュータはプログラムの実行に必要なデータがメモリー上に展開されていなければ実行できない。
2018年の今だからこそ文字くらいでメモリー消費を気にすることなどないが、時代は1980年台である。メモリーとは命に等しいのであった[要出典]
したがって少しでもメモリー消費を減らすことがすべての場所で要求された。文字もその例外ではない。
メモリーの無駄遣いはそれだけで即刻Rejectされる世界だったのだろう。
ASCIIしか解さない愚か者たち
そもそもヨーロッパ圏においては中国や日本みたいに8bitには到底収まりきらない程の文字が日常にある世界など想像できないのである。[要出典]
というかASCII以外の文字は2級市民だという勢いの人すら存在する。例えば後述するBoost.Locale事件である。
すべての文字が16bitに収まると考える愚か者たち
ASCIIしか解さない愚か者たちの中にも流石にすべての文字が8bitに収まらないという現実は受け入れられ始めていた[要出典]
しかしやはり同じ理由からなのかメモリー消費との戦いからなのかはたまた宗教的な争いからか16bitで収まると考える愚か者が現れた。ユニコードコンソーシアムである。
MS さんは比較的初期から Unicode コンソーシアムにいて、 16bit のほうが都合がいいからと、半ば決まりかけていた DIS10646 の卓袱台返しに加担した側なので、同情の余地はないですね。 https://t.co/QpraL9VwfC
— AoiMoe a.k.aしお兄P (@AoiMoe) 2019年5月27日
CJKの漢字が同一であると考える愚か者たち
ちょっとでも詳しい人ならCJK統合漢字というものをご存知かもしれない。すべての文字が16bitに収まると考える愚か者たちにそそのかされた結果、中国(C)、日本(J)、韓国(K)、ついでにベトナム(V)の漢字を無理やり悪魔合体して同じ漢字だと自らを洗脳することで、漢字の統合を行ってしまった。
・・・ところでこれを主導したのが誰だったか追加調査すると
Early Years of Unicode
Our investigations, headed by Lee Collins, showed that we could get past these technical issues.As far as the text size, when we tested the percentage of memory or disk space actually occupied by character data in typical use, we found that it was rather small. Small not in absolute terms, but small compared to the amount of overhead in data structures and formatting information. Nowadays, of course, with video and sound data taking so much space, the percentage is even smaller.
Concerning unification, when we looked at the unification of CJK ideographs, we had the successful example of the Research Libraries Group's East Asian Character (EACC) bibliographic code to show the way. We could see that by using the very same unification rules that the Japanese used for JIS, we could unify characters across the three languages.
And, in terms of character count, when we counted up the upper bounds for the modern characters in common use, we came in well under 16 bits.
Lee Collinsという人だったと調べ直してわかったのですが、どっかでCJK統合できるか調べてShift-JISとかとか見たけど統合できそうやで!みたいな論文、それもスキャンされた画像だったと思うんですが、見た記憶があるんですが、一体どこにあったんだかさっぱり辿れない。
固定長に文字が収まるという夢を見た愚か者たち
プログラム的に、もし文字を固定長に表すことができれば非常に処理がやりやすい。その利便性から固定長に文字が収まるという幻想の郷に誘われてしまった愚か者たちがいた。当時の関係各位概ね全てである。[要出典]
追記:
と思いきや、そこまで愚かではなかった。むしろ現代の我々のほうが愚かである気がする。
まあこの辺については未だに理解が進んでおらず2017年の自作OS Advent Calendar 2017では@tenpoku1000さんが
UTF-32 でも固定長で処理出来るわけではない
を執筆されていたりしたようだ。
宗教・文化という普遍的な火種
人類の歴史を振り返るに、おおよそ戦争というものの多くは宗教・文化という普遍的な火種が関わっている。多様な価値観を認めるとかそういう行為はエントロピーが高かったりするんだろうか。
その他
まあ金とか名誉とかそのへんのありきたりな火種も当然ある。
結果
無視できない負債が現代もなおプログラマーを、ひいてはソフトウェアを利用する罪のない一般市民を巻き込んでいる。地雷原の撤去は終わっていないのだ。
無視できない負債たち
細かく上げれば鈍器になるレベルかも知れないので2つだけ。
UTF-16
Microsoftなどが国際化プログラミングとか称して時代はUnicodeだよねっ!と言い出した。まあそこまでは良かった。問題はそこからだ。
MicrosoftがUnicodeといえば、もれなくUTF-16を指す。
ワイド文字という概念が生産されたのだが、
追記:
char8_tによせて - なるせにっき
そもそもワイド文字という概念はUnicode以前からあって、元々はDEC漢字のような日本語UNIX環境の開発から生まれ、日本語UNIX環境がAT&Tの本家UNIXに取り込まれることで世界に紹介され、C89にwchar_tが取り込まれ、C++にも採用されるといった順序になっています。
Unicodeより前からあったのか・・・。
まあいずれにせよ、ユニコードコンソーシアム側の不用意な宣伝の結果誤用され、これはマルチバイト文字との対比の文脈で用いられた。言うまでもなく大問題で、なぜならUTF-16は文字を固定長で扱うことができないからである。サロゲートペアであるとか結合文字列なんかの問題がある。しかし多くのプログラマーはワイド文字なら固定長で扱えると考えてしまった。
日本人がまんまとユニコードコンソーシアム側の周回遅れの情報に騙されてしまった背景には2001年、Unicode 3.1で、ISO/IEC 10646-2として、拡張漢字B集合42,711字が、U+20000-U+2A6FFのブロックに追加されるまでサロゲートペアも結合文字列も扱う機会がなかったためと思われる。
結果膨大な数のバグを生み出す地雷として今なお猛威を振るっている。
じゃあUTF-16を使うのをやめればいいじゃないと思うかもしれないが、巨大なシェアを持つWindowsを始め、そこかしこで使われてしまったがために、バイナリ互換を捨てないために維持されている。
おい、だれか平行世界に転生してユニコードコンソーシアムの連中をひたすら論破し続ける小説を書いてくれないか。
CJK統合漢字
CJKの漢字が同一であると考える愚か者たちによって悪魔合体させられてしまった文字たちだが、当然問題になった。悪魔合体したとはいえ字形が同じであるはずもないし、用いられる文脈も違う別の文字だったはずのものである。
解決策として異体字セレクターというものができた。つまりCJK統合漢字を表す既存のCodepointの後ろに異体字セレクター用に割り当てられた別のcodepointを並べることで一つの文字として扱い、字形を区別できるようにするというものである。
追記:
( https://t.co/Vgyz7LH9Z1 ここでの異体字セレクターに関する下りは明らかな事実誤認かな。仮に CJKV でのソースの差を区別していたとしても、漢字の字体や文脈の問題は解決しなかったかより悪くなっていただろうし、IVS も(少なくとも現状)同一ソース内での形の差異を区別するものでしかない)
— MORIOKA Tomohiko (@CHISE_ja) 2018年12月24日
完璧に事実誤認だったようなので忘れてください。
ただ多くのソフトウェアでこれの対応を忘れてしまい、例えばvscodeなんかもその手の問題を当初抱えていた。
追記:
char8_tによせて - なるせにっき
だってさぁ、アルファベットは元から統合されてるんだし。まぁ、トルコ語のアルファベットは分離しておいた方がよかったと思います。
あーうん、確かにそう言われてみれば・・・。
絵文字
これもUnicodeを語るのに欠かせない要素なので触れておく。
世紀末の日本、1999年2月のこと、ドコモがi-モードを提供し始めた。このとき絵文字を収録した。21世紀に入る前に今のau、今のSoftbankも同様のサービスを提供し始めた。
ちなみにi-モードの絵文字をほぼ一人で作った人は今ニコニコ動画でおなじみドワンゴ取締役の(く)りたしげたか改・・・じゃなかった、栗田 穣崇さんだったりします。大炎上したにこにこ(く)の収拾にあたり陣頭にたった方ですね。
で、この絵文字、即座に問題になって、つまりキャリア間でメールを投げるときに絵文字を使うと化けるという問題でした。
元になっている文字コードはShift-JISというやつで2年前の1997年に正式に規定したときに禁止された範囲に絵文字を各社てんでんばらばらに割り当ててしまったもんだからさあ大変。
このとき3社の間で標準化する、もしくはデファクトスタンダードを作ってくれていればもうすこし現代社会をプログラマーは生きやすくなっただろうと思うのですが、それは後世からみた評価であって、致し方なかったのでしょうか。
2006年、3者はそれぞれ他の2社との相互運用性向上のために、E-mailに関して、メールの送信経路で中間者攻撃を仕掛け、送り先に合わせた絵文字に変換するサービスを開始しました。そう、最悪の結果となったのです。当時の関係各位は十分に反省して欲しい。
絵文字とGmailとiPhoneとUnicode
ASCIIしか解さない愚か者たちにぐーで殴りかかったものがある。絵文字だ。
最終的に絵文字が世界に流通するきっかけとなったのはiPhoneだと思われる。
しかし流通可能なまでに最悪の状態を整理した功績の多くはGoogleのGmail、その日本チームにある。
Gmailが絵文字に対応したのは2008年1月のことだが、2007年6月には概ね整理を終えていたらしい。
2009年の11月、iOS 2.2で日本語に設定したときのみ絵文字が使えるようになった。
Unicodeに絵文字を入れる議論が始まり、日本に偏っていたことやその他国際化にあたって多くの障害を乗り越え、本が何冊かないと書ききれない経緯を経て2010年、Unicode 6.0に絵文字が入った。
こうして世界に絵文字が広がった。その後も絵文字に改善が入っている。
結果ASCIIしか解さない愚か者たちに何が襲いかかったか。結合文字列である。ついに固定長に文字が収まるという幻想が破られるときが来てしまったのである。
と同時にそれはついに真面目にUnicodeに向き合わなければならない時代の到来を告げたのだった。
Unicodeにおける4つの文字の定義
にて4通りの定義が示されています。それに習ってU+0061, U+0928, U+093F, U+4E9C, U+10083(aनि亜𐂃)という文字列の長さを4通りで数えれば4つの定義がわかることでしょう。

byte
何byteか、という数え方です。Unicodeには今の所UTF-8/UTF-16/UTF-32というエンコード方式が存在するのでそれぞれ数えてみましょう。
| エンコード | byte数 | byte列 |
|---|---|---|
| UTF-8 | 14 | 61 E0 A4 A8 E0 A4 BF E4 BA 9C F0 90 82 83 |
| UTF-16BE | 12 | 00 61 09 28 09 3F 4E 9C D8 00 DC 83 |
| UTF-32BE | 20 | 00 00 00 61 00 00 09 28 00 00 09 3F 00 00 4E 9C 00 01 00 83 |
用途としては、メモリー確保するときの大きさとかそんなでしょうか。
code units
何単位か、という数え方です。やはりUTF-8/UTF-16/UTF-32についてどうなるか見てみましょう。
ところでcode unitsは一般に単位と訳されるのですが、Code Unit Sequenceはどう訳せばいいんでしょうか?単位列、だとなんか違和感があります。
| エンコード | Code Unit数 | Code Unit列 |
|---|---|---|
| UTF-8 | 14 | 61 E0 A4 A8 E0 A4 BF E4 BA 9C F0 90 82 83 |
| UTF-16 | 6 | 0061 0928 093F 4E9C D800 DC83 |
| UTF-32 | 5 | 00000061 00000928 0000093F 00004E9C 00010083 |
Javascriptとかいう変態は置いておいて少なくともC++でstringのlengthといったらこれですね。
code points
何コードポイントか、という数え方です。
U+0061, U+0928, U+093F, U+4E9C, U+10083
というのは5コードポイントですね。
ちなみにUTF-32のときのCode Unit数と同一です。
grapheme cluster
何書記素クラスタか、という数え方です。
(aनि亜𐂃)
人間が見たときに一文字と解釈するかという考え方です。
例えばनिはコードポイントで見るとU+0928(न), U+093F(ि)という2コードポイントで表されます。しかしこれを別々の文字とは人間は解釈せず、一文字と認識します。
他の例も見てみましょう。
प,ू,र,ी,त,ि

👩❤️💋👨
kiss: woman, manとして登録されているのですが、コードポイントで表すとU+1F469 U+200D U+2764 U+FE0F U+200D U+1F48B U+200D U+1F468となります。長い!
さらに見ていきましょう。
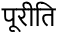 (पूरीति)
(पूरीति)
これはcodepintでいうとU+092A U+0942 U+0930 U+0940 U+0924 U+093Fという並びなのですが、見た目上の部品の並びとまったく一致しません。適当な文字入力手段がなかったのでWikipediaの
デーヴァナーガリー - Wikipedia
にある表から一つづつコピペして作りました。
-
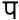 (प)
(प) -
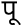 (पू)
(पू) -
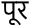 (पूर)
(पूर) -
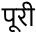 (पूरी)
(पूरी) -
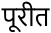 (पूरीत)
(पूरीत) -
(पूरीति)
いわゆる結合文字列の類はこのように認識上の一文字とコードポイント数が一致しません。
あゝ、世界の文字のなんと多様なることか!
そうです、コードポイントによって文字が固定長に表せるという考えすら幻想入りしたのです。
ここに文字を固定長で表そうとする試みは完全敗北したのでした。
本当に「人が見て認識する1文字」単位にするには、結合文字の扱いを考慮する必要があるわけです。なお、チベット文字の「1文字」がチベット語話者の立場から通常どのようにとらえられているのかは私には分かりません。
ちなみに、書記素の切れ目がどこに入るのか、は厳密に定義されているのでそこはご安心を。ただしUnicodeのバージョンが上がるごとに変わっていきます。うへぇ。
@ufcpp 氏によるC#で書かれたUnicode 10.0相当の判定コードがこちらです。
https://github.com/ufcpp/GraphemeSplitter/blob/master/GraphemeSplitter/Character.GetGraphemeBreakPropertyV10.cs
2920行あります。これでも前は2万行近い switch ステートメントだったんだから短くなったほう。
このようにcodepointごとに種類判定(CR LF Control Extend SpacingMark Regional_Indicator L V T LV LVT Any)を行い、さらにそれに基づいて結合するかの判定を行うことになるようです。
絶対自分で書きたくない。
なので普通はicuを使う(ところでWebassemblyで使おうと思ってコンパイルしようとしたらコンパイルできないの私だけ?)。
で、用途としてはマウスで選択するときとかbackspace/deleteキーで文字を消すときだとかにこれに基づいてやると最も自然だよね、ということになっています。
突っ込まれる前に補足
べつにCJKを始めとする多くの技術者たちがこの問題を放置してきたわけではなく、日本もUnicodeには多大なる貢献をしています。
ドコモをはじめ3社のことも悪く書いていますが彼らだって怠惰だったわけではない。とくにドコモについてはWebで見える範囲でも痕跡が見られます。auだってGoogleとの提携の中でなにかやっていたらしい話が聞こえている。SoftbankがAppleに乗り込んでいってiOSの絵文字の実装に関わったのも知ってる。
わかってる、わかってる。けどそれでもこの現状なんだよ、どうなっとるんじゃい、と思わずにはいられないんですよ。
UnicodeとUCS
Unicodeというのがもともと業界団体が作ったものだったのに対してUCSはISOという国際標準を取り扱うところに起源を持ちます。
なのでISO的にはISO/IEC 10646は、Information technology — Universal Coded Character Set (UCS)というのが正しいです。
しかし実質的にUnicodeとUCSは同一であり、Unicodeで決めたものを再度ISO側で段階を経てISOから発行するという手順を踏んでいたりします。
面倒なので以下Unicodeと呼ぶことにします。UCSって言われてもなにそれって感じですしお寿司。
参考資料
- 絵文字が開いてしまった「パンドラの箱」第1回--日本の携帯電話キャリアが選んだ道 - CNET Japan
- 絵文字が開いてしまった「パンドラの箱」第2回--Googleの開けてしまった箱の中味 - CNET Japan
- 絵文字が開いてしまった「パンドラの箱」第3回--Unicode提案の限界とメリット - CNET Japan
- 絵文字が開いてしまった「パンドラの箱」第4回--絵文字が引き起こしたUnicode-MLの“祭り” - CNET Japan
- 絵文字が開いてしまった「パンドラの箱」第5回--絵文字と日本マンガの親密な関係 - CNET Japan
- 絵文字が開いてしまった「パンドラの箱」第6回--Google・Apple提案とそのシナリオ - CNET Japan
- 絵文字が開いてしまった「パンドラの箱」第7回--そして舞台はダブリンから東京へ - CNET Japan
- 絵文字が開いてしまったパンドラの箱
- グーグルが絵文字を世界標準に提案した理由--国際化エンジニアに聞くプロジェクトの舞台裏(前編) - CNET Japan
- グーグルが絵文字を世界標準に提案した理由--国際化エンジニアに聞くプロジェクトの舞台裏(後編) - CNET Japan
- 安岡 孝一, ケータイの絵文字と文字コード, 情報管理, 2007, 50 巻, 2 号, p. 67-73, 公開日 2007/05/01, Online ISSN 1347-1597, Print ISSN 0021-7298
- Suggestions for text fallback · Issue #142 · googlei18n/emoji4unicode
- DOCOMO's comment - Google グループ
- Proposal for Encoding Emoji Symbols - Unicode Symbols
- 携帯電話の絵文字のUnicode登録をめぐる議論の動向 - moroshigeki's blog
- Emojiに対するアイルランド、ドイツからの修正案 - moroshigeki's blog
- 12. Unicode、絵文字、Androidのテキスト関連のハンドリング、無数の文字トリビア (のな)
- Unicodeのgrapheme cluster (書記素クラスタ) | hydroculのメモ
- 絵文字の連結と、書記素クラスター判定 | ++C++; // 未確認飛行 C ブログ
提案文章へのリンクは割愛しています。
参考資料2
この記事の執筆のさいに参照はしていませんが、昔見ていいなと思っていた解説のうちひろい出せたものだけと、はてぶで紹介いただいたものなど。
ほら貝:文字コード
- 文字コード問題早わかり 1 カタカナ篇
- 文字コード問題早わかり 2 漢字篇
- 文字コード問題早わかり 3 続・漢字篇
- 文字は無制限に増やすべきか?──棟上昭男情報規格調査会会長に聞く
- 小は大をかねるか?
- 文字コード案内──どこから読むか?
安岡 孝一, 日本における最新文字コード事情
- 2001-04-15: 安岡 孝一, 日本における最新文字コード事情(前編), システム/制御/情報, 2001, 45 巻, 9 号, p. 528-535, 公開日 2017/04/15, Online ISSN 2424-1806, Print ISSN 0916-1600
- 2001-12-15: 安岡 孝一, 日本における最新文字コード事情(後編), システム/制御/情報, 2001, 45 巻, 12 号, p. 687-694, 公開日 2017/04/15, Online ISSN 2424-1806, Print ISSN 0916-1600
【ネット時代の大きな課題、文字コード・進化の過程】シリーズ
- 2005-08-16: 「漢字の国」にみる、電子機器の文字問題(1)
- 2005-09-01: 「漢字の国」にみる、電子機器の文字問題(2)
- 2005-09-14: 「漢字の国」にみる、電子機器の文字問題(3)
PDF 千夜一夜 PDFなんでも情報ブログ by アンテナハウス株式会社 より
- 2005-12-12: PDFと文字(1) – 言語と文字
- 2005-12-13: PDFと文字(2) – 言語と文字 続き
- 2005-12-14: PDFと文字(3) – 言語と文字 その3
- 2005-12-15: PDFと文字(4) – 文字の取り扱い
- 2005-12-17: PDFと文字(5) – テキストを構成する文字
- 2005-12-18: PDFと文字(6) – 地域別文字規格
- 2005-12-20: PDFと文字(7) – JISの文字規格
- 2005-12-22: PDFと文字(8) – JIS X0212, X 0213
- 2005-12-23: PDFと文字(9) – 中国の文字規格
- 2005-12-24: PDFと文字(10) – Unicodeの誕生
- 2005-12-25: PDFと文字(11) – UnicodeとISO 10646
- 2005-12-26: PDFと文字(12) – Unicode仕様の文字
- 2006-01-02: PDFと文字(13) – Unicode文字の検討
- 2006-01-03: PDFと文字(14) – CJK漢字統合問題
- 2006-01-04: PDFと文字(15) – CJK統合漢字拡張
- 2006-01-05: PDFと文字(16) –漢字統合の破綻
- 2006-01-06: PDFと文字(17) – 統合漢字の理論
- 2006-01-07: 漢字統合の3次元モデルについてKen Lundeの誤り
- 2006-01-09: PDFと文字(18) –Unicodeの漢字関連ブロック
- 2006-01-10: PDFと文字(19) – 漢字統合問題再検討
- 2006-01-11: PDFと文字(20) – 字体と字形
- 2006-01-12: PDFと文字(21) – 大文字セット
- 2006-01-13: PDFと文字(22) – グリフとグリフセット
- 2006-01-15: PDFと文字 (23) – Adobe-Japan1
- 2006-01-16: PDFと文字 (24) – Adobe-GB1, Adobe-CNS1, Adobe-Korea1
- 2006-01-17: PDFと文字 (25) – CMapで文字コードからCIDへ変換
- 2006-01-18: PDFと文字(26) – ハングルの扱い
- 2006-01-19: PDFと文字 (27) – アラビア文字の扱い
- 2006-01-20: PDFと文字 (28) – アラビア文字のプログラム処理
- 2006-01-21: PDFと文字 (29) – アラビア文字表示形
- 2006-01-22: PDFと文字 (30) – アラビア文字Harakatの結合処理
- 2006-01-23: PDFと文字 (31) – リガチャ
- 2006-01-24: PDFと文字 (32) – 文字コードと情報交換を考える
- 2006-01-26: PDFと文字 (33) – ラテンアルファベット
- 2006-01-27: PDFと文字 (34) – Unicodeの結合文字
- 2006-01-28: PDFと文字 (35) – 文字の合成方法
- 2006-01-29: PDFと文字 (36) – 文字の合成方法(続き)
- 2006-01-30: PDFと文字 (37) – 結合文字列の正規合成
- 2006-02-01: PDFと文字 (38) – Unicode標準形NFCの実装
- 2006-02-02: PDFと文字 (39) – Windowsへ表示とPDF作成の相違
- 2006-02-03: PDFと文字 (40) – Unicode標準形式NFCの問題点
- 2006-02-07: PDFと文字 (41) – Unicode標準形式NFCの問題点(続き)
- 2006-02-09: PDFと文字 (42) – ハングル音節文字の合成
- 2006-02-11: PDFと文字 (43) – ラテンアルファベットのリガチャ
その他
- 2012-08-16: 文字数制限 - yanok.net
- 2016-11-07: Unicodeとは? その歴史と進化、開発者向け基礎知識 - Build Insider
- 2016-11-14: Unicodeと、C#での文字列の扱い - Build Insider
- 2017-11-14: 絵文字を支える技術の紹介
- 2018-04-28: ㇹ゚ン゚'ㇳ̃ヴ゙ニ゙コ゚ヮヰ文̂字̠コ゚−ト゚ノ゙ㇵナ゚ㇱ(現在に至るまでの文字コードの軌跡と簡単な使い方について) - へっぽこびんぼう野郎のnewbie日記
C++とUnicode
いやぁ長かったですがここまでがまえがきです(えっ
C/C++における標準化以前の文字の扱い
そもそもC/C++には組み込み型としてとくに文字を表すための型があるわけではありません。じゃあcharはどうなんだということですが、あれは断じて文字を表すための型ではありません。
だいたいC標準では文字を受け取る引数はint型だったりしますし、一方C++ではcharだったり極めて乱暴でいい加減な取り扱いです。Cを作り上げた連中の脳みそを解剖してみたい。
なぜか?ASCIIこそが文字なのであってそれ以外は2流市民だからです。平家にあらずんば人にあらず(正確にはこの一門にあらざらん者は、みな人非人たるべし)ってやつです。つまり文字とは8bitで表されるという認識なのです。
C++標準化委員会のメンバーの認識も概ねそこから揺らぎません。
日本のC++への影響力の低下
C++の規格書はC++標準化委員会(WG21)で議論されて規格化、ISOから発行されます。
さて、ISOの標準化プロセスには国を代表して標準化委員会の議論に関わる各国の支部があり、National Body(NB)コメントを受け付けるフェーズがあるのだそうです。
日本にも支部があり、C++03の頃までは規格書の翻訳をしてJISとして発行する作業が行われたのだそうですが、C++11以降そういう作業は行われていないのだそうです。
江添亮氏の古いブログを引っ張ってくると
本の虫: 日本語のC++参考書の行く末
2013-10-28そもそも、英語で書かれているC++の標準規格はどうなのか。金はどこから出るのか。C++の標準規格は、C++標準化委員会で議論され、検証され、文面案を書き、投票されて、ドラフトに入り、最終的に規格として制定される。どこから金が出ているのか。C++標準化委員会のメンバーは、個人で参加している者もいるが、大半はスポンサーがいる。スポンサーがC++の規格や、教育や、コンパイラーやライブラリの実装などに長けた人間に金を出して、C++の標準規格の作業に従事させているのだ。そうすることによって、スポンサーは、C++の規格を、スポンサーにとって都合がいいように、影響を与えることができる。
日本では、今、このスポンサーが存在しない。かつては存在したのだ。
C++標準化員会は、私もいまいち仕組みがよく分かっていないのだが、私としては、C++ Working Groupという単位の印象が強い。C++WGは、主要な各国に支部があり、日本にも支部がある。私もそこに、スポンサーなしの個人として籍をおいている。
最初のC++の正式な規格、C++98は、1998年に制定された。当時、日本では、C++の標準規格の日本語訳がほしいと考えるスポンサーがたくさんいた。そのため、スポンサーに雇われたC++WGのメンバー達は、作業を分担してC++の標準規格の全文を翻訳し、同等のJIS規格として制定した。
しかし、いまC++11の規格書の日本語訳は存在しない。一体どうなっているのか。C++標準化委員会は何をしているのか。これは、スポンサーがいないためである。
これは私の誤解と偏見で語るのだが、どうもC++WGの日本支部というのは、その前身が、EC++団体の人間だったらしいのだ。
先程の絵文字は多くの日本人や日本向けにサービスを行うに当たり十分に理解している人たちの支援があったわけですが、C++に関しては日本からのNBコメントは期待できない状況にあり、他国に任せっきり、という状態です。中国/韓国/ベトナムにC++Working Groupってあるのかな・・・?
C++98とUCS
この頃はまだUnicodeがどうなっていくのか誰もわからない状況。しかも固定長に文字が収まるという夢をみんな見ていた。
何れにせよどうなるかわからない以上実装依存とするより他になく、wchar_t型が導入されたものの、特にどのようなエンコードを利用するかは規定せず、
wchar_t型のひとつのオブジェクトは、実装がサポートするロケールの文字セットの任意の一文字を表現できる。
ということにした。これが幻想であったことに気がつくのはもう少し後の話である。
このようにwchar_tは実装依存のエンコードが用いられる。じつのところUnicodeのいずれかのエンコードであるとすら定まっていない。
__STDC_ISO_10646__マクロが定義されているときのみ、wchar_tはUnicodeのいずれかのエンコードを用いていることが保証される。
そしてC++はISO/IEC 10646-1:1993を参照している。ちなみにこの頃はUTF-8/UTF-16/UTF-32というものはなくUCS-2/UCS-4とか呼んでいた。
なお恐ろしいことに規格書的にはC++17が出ている今なお1993年のものを参照し続けている。P0417R0: ISO 10646:2014という2014年のを見るように変えようぜっていう提案も出たのだが、通った気配がない。
__STDC_ISO_10646__
このマクロは先にwchar_tがUnicodeのいずれかのエンコードを用いていることを保証すると同時に、実装がいつのISO/IEC 10646-1規格を参照しているかを示している。値はyyyymmL(例:199712L)のようになっている。
ちなみに皆様おなじみWandboxのclang7.0.0で値を調べたところ、201505になった。
劣等生の地位に置かれたwchar_t
そもそもcharすらどんなエンコードであるかの保証がないにもかかわらず、そんなことは都合よく忘れ、wchar_tは実装依存でポータブルではないなどとのたまう輩やはてはwchar_tはMicrosoftの独自拡張だ、などと言い出す輩が現れた。
標準規格上だけ見ても劣等生の位置に置かれた。
localeというやつがある。役割はisspace, isprint, iscntrl, isupper, islower, isalpha, isdigit, ispunct, isxdigit, isalnum, isgraphの分類と、文字コードの変換である。表面上はcharTという任意の文字型に対して扱えるように見える。しかしそれは完全な誤りであり、設計をよく見れば見るほどchar以外を想定していない。
もちろん文字コードの変換はぶっ壊れており、その他は無駄に役に立たないロケールを見に行く分だけパフォーマンスを悪化させるゴミである。まともなC++erならisdigitなど使うことはできないはずであることは経験則で知っているはずだ。
最悪なことにlocaleは文字列から数値変換を担うもっとも基底に位置する関数であるstrtol系関数にも影響を与える。つまり
int n;
std::cin >> n
のようなコードですら影響下にある。完全にぶっ壊れたゴミにもかかわらずそこかしこに顔をだすんだから始末に負えない。
なお極めて残念なことにC++17が出ている現在でも状況は悪化の一途をたどっている。一刻も早くdeprecatedにしなければならない。
その他の例を見てみよう。file I/Oではファイル名を指定する機会が多い。
std::fstream file("path/to/file");
しかし、このpath指定にはなんとcharしか用いることができない。Unicodeに関してだけは我々の救世主であるMicrosoftが提供するC++の実装では、wchar_tも受け付けるように独自拡張がなされている。
C++17で追加されたfilesystemライブラリによって、ようやくどうにかUnicodeなpathを取り扱う手段が提供された。
崩壊したwchar_t型
先にも述べたように、
wchar_t型のひとつのオブジェクトは、実装がサポートするロケールの文字セットの任意の一文字を表現できる。
という形でwchar_t型は定義された。しかし現実にはどうなったか。
Microsoft Windows環境においてはwchar_tはUTF-16をつかう、という事になった。これはWin32APIによるところが大きい。先に述べた
MicrosoftがUnicodeといえば、もれなくUTF-16を指す。
というのはそういうことだ。
その他のLinuxとかとかではUTF-32だ、という事が多い。これはコードポイントと一致するエンコードだからだろうか。
追記:
char8_tによせて - なるせにっき
(前略)元々そこに詰められていたのはEUCの類だったわけです。という経緯が分かると、なぜC/C++標準で執拗にUnicode決めうち仕様を避けているのかが分かってくるのではないでしょうか。
ごめんよ、EUC、普通に脳内から存在を抹消していたでござる。
いずれにせよ結合文字列などがある以上、すでに任意の一文字を固定長で表すことはできず、ここにwchar_t型は崩壊した。
またwchar_t型の大きさが規定されなかったため、portableに文字をやり取りする型として利用できなかったという事情もある。
そんな状況からか、mingw環境ではまともにwchar_t型が使えない状況が続いている。
utf16_t型の提案
2001年に実はC/C++に対してUnicode側からutf16_t型を追加しようぜという提案があったことを執筆時に初めて知った。
Proposal for a C/C++ language extension to support portable UTF-16
これだ。提案内容をまとめると
- UTF-16を保証する型として
utf16_t型を追加する -
utf16_t型な文字列リテラルを作るためにprefixとしてuを追加する - エンディアン(バイトオーダー)は処理系に依存する
というものだ。UTF16だけに絞っている理由は、メモリー効率がUTF-8/UTF-16/UTF-32を比較したときにUTF-16がもっとも良くなるからだ。未だにメモリーは貴重な時代であり、またキャッシュミスを起こしにくくするという意図もあったらしい。
と同時にすでに当時、WindowsやJava、データベースがUTF-16に対応しており、UTF-16を保証する型が必要やろ、という主張だった。
Boost.locale事件
Unicodeに対して理解を示す人が多く現れる一方で、誤った情報に惑わされたり、旧来の英語第一主義、8bit文字主義に囚われた人も数多く存在した。ここでBoostというC++標準のSTLの実験場とも言われる場で起こったささやかな事件を紹介するとしよう。
2011年にBoost.localeが採択された。しかしその内容に皆さんご存知の江添亮氏が異議を唱えた。
問題は何だったか。Boostという場に持ち込まれるようなライブラリにもかかわらず、英語第一主義でその他の言語を2級市民扱いしていたこと、おおよそ世界に星のように存在する言語を取り扱うに適さないインターフェース、謎のUTF-16嫌悪、狂信的char型信仰など問題のかたまりであった。
std::localeがぶっ壊れているのはもう諦めたがBoostよ、お前もか。
- 2011-04-19: 本の虫: Boost.Localeがクソすぎる
- 2011-04-24: 本の虫: Boost.Localeが採択された
- 2011-04-27: 本の虫: Boost.localeは何の冗談だ
- 2011-04-28: 本の虫: Japanese programmers don't know English
- 2011-04-28: 本の虫: Translation is impossible
- 2011-05-03: 本の虫: How Not To Localize Your Software
- 2011-05-18: 本の虫: Sorting it all Out: 英語を強制させないことだってできるさ。あるいはアホになるか。どっちでもいいけど
C++11とUnicode
さて、当初C++0xと呼ばれていたC++03の次の規格は議論が長引き、0xのxは実は16進数なんだとかいう皮肉が飛び出し、しまいにはC++1xと呼ばれ、ようやくC++11が発行された。
その詳細はすでにご存知の人が大半だろうが、改めて見ていこう。
char16_t/char32_t型の追加
ref: char16_tとchar32_t - cpprefjp C++日本語リファレンス
16bitと32bitの文字を表すための型としてchar16_t/char32_t型が追加された。
ここで大切なのはUTF-16/UTF-32の保証がないことである。
char16_t/char32_t型な文字列リテラルを作るために文字列リテラルのprefixとしてu/Uが追加された。
u"ありきたり";//__STDC_UTF_16__が定義されていればUTF-16でさもなくば実装依存のエンコード
U"ありきたり";//__STDC_UTF_32__が定義されていればUTF-32でさもなくば実装依存のエンコード
同様に文字リテラルに対してもprefixが追加された。
__STDC_UTF_16__/__STDC_UTF_32__マクロが定義されているときのみUTF-16/UTF-32の保証があり、さもなくば実装依存である。あちこちの解説が間違えまくっているのだが、常にUTF-16/UTF-32の保証があるってわけではない。
どうやらC/C++は同じくISOから出ているUnicodeに意地でも依存したくないらしい。
UTF-8文字列リテラル
ref:
同じくISOから出ているUnicodeに意地でも依存したくないのかと思いきや、もう片方では手のひらを返す内容が追加された。
u8"ありきたり";//確実にUTF-8でエンコードされる
u8を文字列のprefixにつけると確実にUTF-8になる。嘘かと思った読者のためにわざわざC++11の規格書を引っ張ってこよう。
§ 2.14.5 String literals [lex.string]
7 A string literal that begins with u8, such as u8"asdf", is a UTF-8 string literal and is initialized with the given characters as encoded in UTF-8.
ほーら、まじでUTF-8って明確に書いてある。何たる手のひら返し!
ちなみに文字リテラルに対するprefixu8はC++17まで先送りされた。意味がわからない。
さて、ここで恐ろしい話として、u8prefixが付いた文字列リテラルの型はprefixなしに等しい。つまりchar8_tではなくcharなのである。これについては後述する。
std::wstring_convert/std::codecvt_utf8/std::codecvt_utf8_utf16
ref:
- wstring_convert - cpprefjp C++日本語リファレンス
- codecvt_utf8 - cpprefjp C++日本語リファレンス
- codecvt_utf8_utf16 - cpprefjp C++日本語リファレンス
文字コードの変換も標準に追加された。先に言っておくと仕様がガバのプーさんでセキュリティ的リスクまであるという事がわかりC++17でdeprecatedになった。
こいつはUnicode間の変換をするもので、大きく2通りの利用の仕方が存在した。
1つ目はstd::wstring_convertを利用したbasic_stringの変換で、
std::wstring_convert<std::codecvt_utf8<char32_t>, char32_t> converter;
// UCS-4/UTF-32からUTF-8に変換
std::u32string u32str = U"\U0001F359";
std::string u8str = converter.to_bytes(u32str);
// UTF-8からUCS-4/UTF-32に変換
std::u32string restored = converter.from_bytes(u8str);
std::wstring_convert<std::codecvt_utf8_utf16<char16_t>, char16_t> converter;
// UTF-16からUTF-8に変換
std::u16string u16str = u"\U0001F359";
std::string u8str = converter.to_bytes(u16str);
// UTF-8からUTF-16に変換
std::u16string restored = converter.from_bytes(u8str);
のように利用した。
もう一つはstreamに対して
wifstream ifs("UTF-8N.txt");
ifs.imbue(locale(locale::empty(), new codecvt_utf8<wchar_t>));
のように渡す利用法である。ちなみにこの場合
#include <fstream>
#include <codecvt>
int main()
std::wifstream file;
file.open("arikitari_na_text.txt");
static_assert(sizeof(wchar_t) == 2, "error.");//Linuxではつかうcvt違うから直してくれ
file.imbue(std::locale(std::locale(""), new std::codecvt_utf8_utf16<wchar_t, 0x10ffff, std::consume_header>()));
if(!file) return -1;
//なんか
}
のようにするとBOM skipができた。
ref: C++のstreamでbom skipする方法をまた忘れないうちに書き留める
ただし最初に述べたようにC++17でdeprecatedになりました。
P0618R0 Deprecating <codecvt>
理由を意訳すると
- 不正なコードポイントに対する安全なエラー処理の方法を提供していなかったため、セキュリティ上の欠陥があった。
- 試しに使おうとしたけどあまりにも複雑過ぎていっちょんわからんかった
- まともに実装されてない。libstdc++は最近(注:2017年3月からみて)やっと実装したくらいだし誰も使ってねーだろ(注:MSVCもまともに実装されたのはVS2015からという印象)
- Unicodeじゃないエンコード(Shift-JISとかBig5とかな)はどんどん利用されなくなっているから(そいつらは無視していいのにもかかわらずそいつらの対応を視野に入れているせいで無駄に複雑で安全ではないゴミのような)
codecvtはさっさと非推奨にしろ。このクソが歴史的負債になる前に。
といった感じだった。
付け加えておくとパフォーマンス的にもクソで、
utf8 のファイルの読み込み
見限って自力で変換を書いてstreambuf化する人まで現れた。
deprecatedになった第一報を聞いたときは驚いたけど、
https://t.co/Zercxns9Jz
— yumetodo-鳥の氷河から逃げる (@yumetodo) April 3, 2017
P0618R0 Deprecate <codecvt>
>Users should use dedicated text-processing libraries instead.
えっ、つまりC++標準は文字コード変換を放棄した?
よくよく考えればdeprecatedになってくれてよかった。
そんなわけでC++17現在C++標準はUnicode同士の変換を提供していなくて、各自適当なライブラリを使えとのこと。
参考資料
- 2010-04-10: 本の虫: C++0x本:UnicodeとUCSについて
- 2010-05-25: 本の虫: 最近の若い者は・・・
- 2010-06-10: 本の虫: C++のlocaleがクソすぎる
- 2013-10-20: 本の虫: 2013-10 post-Chicago mailingの簡易レビュー
- 2013-10-28: 本の虫: 日本語のC++参考書の行く末
- 2014-03-25: 本の虫: 2014-02-post-Issaquahのレビュー: N3900-3909
- 2016-01-20: 本の虫: C++標準化委員会の文書のレビュー: P0160R0-P0172R0
- 2016-09-12: 本の虫: C++標準化委員会の文書: P0411R0-P0417R0
- 2017-03-02: P0618R0 Deprecating
- codecvt_utf8 - cpprefjp C++日本語リファレンス
- codecvt_utf8_utf16 - cpprefjp C++日本語リファレンス
- wstring_convert - cpprefjp C++日本語リファレンス
- utf8 のファイルの読み込み
UnicodeとC++のこれから
ここまでUnicodeとC++が、人類がそれにどう向き合ってきたかを見てきた。
ではUnicodeとC++のこれからについて見ていこう。
Unicodeの各エンコードを保証する型がなぜ必要か
Unicodeではない文字エンコードの利用が減ってきている現代に置いて、UnicodeをC++がまともにサポートすることは極めて重要である。
Unicodeの普及率は凄まじい。例えばUTF-8は全Webサイトのうち90%を超える割合で利用されている。
もはやUnicodeは全世界のありとあらゆる文字セットの全体集合としての役割を果たしている。ローカライズの文脈でもしUnicodeではない文字エンコードを利用するとしても実装コスト的にそれはUnicodeとの変換で扱うことを検討すべき時代なのだ。
wchar_tは文字が固定長で表せるという幻想のもとに設計された。今となっては時代遅れである。
C++11でchar16_t/char32_t型が追加された一方でchar8_t型が入らなかった。
明らかにその他大勢のエンコードとUTF-8は区別されるべきであるのにもかかわらずcharに悪魔合体させられている。
char16_t/char32_tについても問題があり、それぞれUTF-16/UTF-32を必ずしも保証しない。
しかも面白いことになぜかu8prefixの文字列リテラルだけはUTF-8が保証された。
UnicodeにC++がまともに向き合うには
- UTF-8を保証する
char8_t型の追加 -
char16_t/char32_tはUTF-16/UTF-32を保証する
が最低限必要不可欠である。core言語側でこの対応が入りさえすればあとはlibraryが腐ってても各々作ることでデータのやり取りが可能だ。逆にこれが入らない限りユーザが勝手気ままにこれに相当する型をつくり、互換のない地獄がさらに続く。
標準ライブラリの中ですら、すでに弊害が出ている。
C++17ではfilesystemライブラリが追加された。パスを表すクラスとしてpathというクラスが追加された。
int main()
{
using namespace std::filesystem ;
// ネイティブナローエンコード
path p1( "/dev/null" ) ;
// ネイティブワイドエンコード
path p2( L"/dev/null" ) ;
// UTF-16エンコード
path p3( u"/dev/null" ) ;
// UTF-32エンコード
path p4( U"/dev/null" ) ;
}
まず面白いことにchar16_t/char32_t型はUTF-16/UTF-32の保証がないにもかかわらず、filesystem libraryの文面によればUTF-16/UTF-32だとしている。つまり__STDC_UTF_16__/__STDC_UTF_32__マクロが定義されていない環境では壊れてしまう。
さらに大きな問題がある。u8prefixの付いた文字列リテラルはUTF-8でエンコードされる保証が存在するが、これを直接
int main()
{
using namespace std::filesystem ;
// ネイティブナローエンコードとして解釈される
path p( u8"ファイル名" ) ;
}
のように渡すと、ネイティブナローエンコードとして解釈されるため、たまたま偶然ネイティブナローエンコードがUTF-8でない限り、壊れてしまう。
流石にまずいと考えたのか
int main()
{
using namespace std::filesystem ;
// UTF-8エンコードとして解釈される
// 実装の使う文字エンコードに変換される
path = u8path( u8"ファイル名" ) ;
}
のように、pathクラスを生成するu8path関数がある。まったく直感的ではない。もしchar8_tがあれば単にコンストラクタをoverloadできたであろうに。
char8_t型反対派の主張
C++11以前、char16_t/char32_t型が提案されていたころ、char8_t型に触れられることはなかった。最初から提案すらされていなかったのだ。
本の虫: C++標準化委員会の文書: P0370R1-P0379R0
C++11のときにchar8_tが必要だと訴えたら、charは古典的にバイト列を表現する型なので十分だ。char型以外の型があるのは混乱する。などと理解のないUnicodeの世界に生きていない名だたる委員達から散々に批判された。その委員達も、今では、「やっぱりchar8_tがないのは失敗だったなぁ」とぼやいている。それ見たことか。
このbyte列という概念が曲者であることがよく分かるエピソードがある。
2018年7月23日、東京大手町のMorgan StanleyにてC++ Now and Tomorrowが開催された。そこに参加した私はC++の始祖たるBjarne Stroustrup氏になぜchar8_t型がないのか聞く機会を得た。内容は
C++ Now and TomorrowでBjarne Stroustrup氏になぜchar8_t型がないのか聞いてきた
にまとめてある。
要約すると
- 文字エンコードをって別にUnicodeだけじゃなくて日本語にはSJISがあるし、そもそもASCIIあるやん。
- Unicodeを特別扱いしたくない
- 文字エンコードについてはlibraryでどうにかするべきだ、core言語は何もしない
というものである。まったく文字の何たるかを理解していない。(英語力不足によるtranslation lostを十分差し引いてお読みください)
Unicodeが世界中の文字セットの全体集合として機能しているのは、断じて一時的なものではない。利用状況を見てもShift-JISやBig5などのUnicodeではないエンコードの利用は低下している。
Unicode対応にcore言語でのサポートが必要なのは明らかである。なぜか。
まずあきらかにcharと区別がつく形でchar8_t型が必要だ。unsigned charなどの既存の型の流用ではoverloadできない。
さらに
enum class char8_t : unsigned char {};
のようなenum classを使うのもだめだ。u8prefixの付いた文字列リテラルを使うのにヘッダーファイルのincludeが必要になってしまう。
組み込み型で独立した型としてchar8_t型が必要である。これはcore言語で対応する案件だ。
char8_tを追加する提案の変遷
- N3398: String Interoperation Library
- P0372R0: A type for utf-8 data
- P0482R0: char8_t: A type for UTF-8 characters and strings
- P0482R1: char8_t: A type for UTF-8 characters and strings (Revision 1)
- P0482R2: char8_t: A type for UTF-8 characters and strings (Revision 2)
- P0482R3: char8_t: A type for UTF-8 characters and strings (Revision 3)
- P0482R4: char8_t: A type for UTF-8 characters and strings (Revision 4)
- P0482R5: char8_t: A type for UTF-8 characters and strings (Revision 5)
以上がC++標準化委員会に出ていたchar8_t型を何らかの方法で追加する提案である。
注意点は、この提案のchar8_t型はUTF-8であることを保証していない。現状のchar16_t/char32_tと同じだ。まあ実用上は困らないと言えるが。
同時並行でC言語の標準化委員会にも
が出ている。
最終的にP0482R5がC++20に採用された。C++標準化委員会、ついに文字とは何かを理解する!
ではその詳細を見ていこう。とはいえそろそろ力尽きてきたので江添亮氏のブログで解説されている部分は引用にとどめ、その他も詳しくは書かない。
N3398
本の虫: 2012-09 pre-Portland mailingのあまり簡易ではないレビュー
文字列などの変換を行うライブラリ。この提案は、char8_tをunsigned charのtypedef名としている。signed char, unsigned char, charは区別されるので、通常のcharとは区別できるから問題ないとしている。そんな奇妙な解決方法は嫌だ。char8_tは本物の型であるべきだし、そもそもUTF-8文字リテラルとUTF-8文字列リテラルは、char8_t型であるべきだったのだ。
char8_tをunsigned charのtypedef名とする、この提案はクソだ。それならない方がましだ。
P0372R0
本の虫: C++標準化委員会の文書: P0370R1-P0379R0
UTF-8の1単位を表現するchar8_t型の提案。char8_tからcharへの標準変換はできるが、逆はできない。
C++11のときにchar8_tが必要だと訴えたら、charは古典的にバイト列を表現する型なので十分だ。char型以外の型があるのは混乱する。などと理解のないUnicodeの世界に生きていない名だたる委員達から散々に批判された。その委員達も、今では、「やっぱりchar8_tがないのは失敗だったなぁ」とぼやいている。それ見たことか。
P0482R0
本の虫: C++標準化委員会の文書: P0480R0-P0489R0
UTF-8文字型であるchar8_tの提案。UTF-8文字列リテラルの型もchar8_t[]型になる。
移行のために、char8_t[]からchar[]への暗黙の型変換を追加する。この暗黙の型変換を追加するには標準変換の細かいルールを変更しなければならないので、最初からdeprecated扱いで入れるのもありだ。
std::u8stringからstd::stringへの暗黙の変換も提供する。
必ず入れなければならない。
deprecatedにするのは
-
codecvt<char16_t, char, mbstate_t>,codecvt<char32_t, char, mbstate_t>,codecvt_byname<char16_t, char, mbstate_t>,codecvt_byname<char32_t, char, mbstate_t> std::filesystem::u8path
の2つ。C++17のUnicode間変換の非推奨化のあともかろうじて生き残っていたネイティブナローエンコードとの変換が非推奨になることで本格的にcodecvtは完全に空気になる。
またu8pathとかいう馬鹿げた関数もいらないので非推奨にする。
P0482R1
R0からの変更点はgccをforkして実装してみた話が追加されたり、文章として読みやすくなったくらいである
P0482R2
R1からの変更点は以下の通り。
- C標準化委員会に提案中のN2231に合わせて
mbrtoc8とc8rtomb関数を追加 -
basic_ostream<char>::operator<<()とbasic_istream<char>::operator>>()に対してchar8_tのoverloadを追加
P0482R3
R2からの変更点はclangで実装してみた話が追加された。
P0482R4
割愛
P0482R5
本の虫: C++標準化委員会の2018サンディエゴ会議の結果
UTF-8文字リテラル、UTF-8文字列リテラルの文字の型を表現するchar8_tを追加する提案。私が9年前にC++0xのときに提案したところ、「でもchatは生のバイト列を表現するのに適切な型だからー」と寝ぼけた主張で却下されたにもかかわらず、後になって「やっぱchar8_tにしとけばよかったなぁ」となったので変更された。私には愚痴を言う権利がある。
変更点は以下の通り
- C標準化委員会に提案中のN2231に依存する文面を非依存な形に書き換え。
-
hash<pmr::u8string>の特殊化を追加 -
atomic_refに対する特殊化を追加 -
u8streamposを<iosfwd>の宣言に書き忘れてたので追記 - R2で
basic_ostream<char>::operator<<()とbasic_istream<char>::operator>>()に対してchar8_tのoverloadを追加したが、この提案文章の動機と関係がなく、char16_t/char32_tに対して現在同様のものがないため、削除 -
mbrtoc8とc8rtomb関数の説明を書き忘れていたので追記 -
codecvt<char16_t, char, mbstate_t>,codecvt<char32_t, char, mbstate_t>,codecvt_byname<char16_t, char, mbstate_t>,codecvt_byname<char32_t, char, mbstate_t>とstd::filesystem::u8pathについてはすでにC++20でdeprecatedになることが決まっていたので忘れる -
codecvt<char16_t, char8_t, mbstate_t>,codecvt<char32_t, char8_t, mbstate_t>,codecvt_byname<char16_t, char8_t, mbstate_t>,codecvt_byname<char32_t, char8_t, mbstate_t>を追加
u/Upreifx付きの文字列リテラルがUTF-16/UTF-32でエンコードされることを保証する提案
- P1041R0: Make char16_t/char32_t string literals be UTF-16/32
- P1041R1: Make char16_t/char32_t string literals be UTF-16/32
現状u/Upreifx付きの文字列リテラルはエンコードが規定されていない。一方でu8prefix付き文字列リテラルについてはUTF-8が保証されている。なのでUTF-16/UTF-32でエンコードされることを保証する提案。
C++規格書が参照するUCSの規格書にない用語を利用している問題を解決する提案
- P0417R0: C++17 should refer to ISO/IEC 10646 2014 instead of 1994
- P0417R1: C++17 should refer to ISO/IEC 10646 2014 instead of 1994 (R1)
- P1025R0: Update The Reference To The Unicode Standard
現在C++はISO/IEC 10646-1:1993を参照している。ちなみにこの頃はUTF-8/UTF-16/UTF-32というものはなくUCS-2/UCS-4とか呼んでいた。つまり存在しない用語を利用していることになる。
FAQ - Unicode and ISO 10646
で解説されているように、UnicodeとISO/IEC 10646は極めて緊密に連携を取ってはいるものの、完全に同一というわけではない。
P1025R0ではどちらかといえばUnicodeのほう、それも10.0かそれ以降を参照するべきだとし、どうしてもISO/IEC 10646にこだわりたいなら
ISO/IEC 10646:2017 Information technology – Universal Coded Character Set (UCS) plus 10646:2017/DAmd 1, or successor
が該当だとしている。
C++20に採択されたchar8_t型を追加する提案の不可解な点
P0482R5をよく見るとなぜかcodecvt<char16_t, char8_t, mbstate_t>, codecvt<char32_t, char8_t, mbstate_t>, codecvt_byname<char16_t, char8_t, mbstate_t>, codecvt_byname<char32_t, char8_t, mbstate_t>が追加されています。
これはUnicode間の変換がガバガバなまま復活を遂げたと理解すればいいのでしょうか・・・?
C++ - C++20に採択されたchar8_t型を追加する提案の不可解な点|teratail
にて質問中です。
まとめ
ついにchar8_tがC++20で追加された。これはC++でまともにUnicodeを扱うための大きな一歩である。しかしC++でUnicodeを扱うための戦いは始まったばかりであり(ry
追記1
ところでC++でUnicode関連の調査検討を行うStudy Groupとしてsg16というのがあることをすっかり忘れていました。
https://github.com/sg16-unicode
議事録が長大なREADME.mdにひたすら書かれるという方法で公開されているようです。
今回のchar8_tの提案もこのsg16の管轄のようで、ほかにはBoost.Textとか言うのが提案されているようです。
https://tzlaine.github.io/text/doc/html/index.html
追記2: SG20 Education draft事件
片方で一歩前進するともう片方で二歩後退するのが世の常なのか、SG20 Education(C++教育のためのガイドラインを作る作業部会)で大惨事が起こっているようです。
SG20 EducationでC++教育のためのガイドラインを作ろうとしているのだが、そのたたき台として示されたドラフトがひどすぎる。https://t.co/eZ3eUgPq1y
— Ryou Ezoe (@EzoeRyou) 2019年1月10日
そして、「UTF-8は最初に教えなくてもよい」ときたもんだ。UTF-8以外の文字エンコードは実質死んだ。そもそもプログラミングをはじめる前にみんなUTF-8は使えっている。英語圏ですら、プログラミングを学ぶ前に絵文字を使った経験がない若い世代などいるわけがない。
— Ryou Ezoe (@EzoeRyou) 2019年1月10日
D1389R0: Standing Document for SG20: Guidelines for Teaching C++ to Beginners
https://www.cjdb.com.au/wg21/sg20/d1389/d1389#typesbasicprimary-primary-types
The distinction between pre-C++20 and C++20 is simply the acknowldgement of UTF-8. This is not to suggest that students should be introduced to the details of UTF-8 any earlier, but rather to get the idea of UTF-8 support on their radar, so that when they need to care about locales, they won’t need to shift from thinking about why char is insufficient in the current programming world: they can just start using what they are already familiar with.
なんでchar8_tが必要か理解するためにあえて先に教えないとかのたまっている。正気か?
てめーら手元の数学とか何でもいいから教科書を開いてみろ、どこにそんなアホみたいに遠回りして教えようとする教科書がある?
補足説明
Twitterやはてなブックマークのコメントを見ていていくつか誤解が生まれているようなので補足します
char8_t型追加はどのレイヤーの話か
C++という言語を語るにあたり、言語そのものを指すcore言語、言語が定める標準ライブラリのSTLがありますが、今回core言語のお話です。
C++でUnicodeを扱うための戦いは始まったばかりであり
というのは、library側の大改造はこれから、という意味合いでした。
C++みたいな低レイヤー言語で文字にそんなこだわる?
C++は低レイヤーもできる言語であって、用途は多岐にわたり、結構高レイヤーなこともできます。
したがって文字の話は避けて通れないんですね。
ユーザー的にはコードポイント単位で扱いたいのでは?
libraryサイドの話ですね。
個人的には各エンコードの文字列に対してコードポイント単位、グリフ単位でアクセスできるiteratorがほしいところです。
あとUnicode同士の変換。そして正規表現の改善。同時並行でぶっ壊れているlocaleとカビの生えたiostream
派生しているWebページ
- 原理主義的に C++ の文字列の扱いを根本から変えるにはどうするべきか - Togetter
- C++標準化委員会、ついに文字とは何かを理解する: char8_t - Togetter: この記事への反応まとめ
- char8_tによせて - なるせにっき
- 書記素分割/Unicode カテゴリー判定 | ++C++; // 未確認飛行 C ブログ
License
CC BY-SA 3.0
![]()