ある種ナイスタイミング
- 本記事を書いているまさにその時、Kubeflow v1.0RCがリリースされました。
- 私の環境のv0.71では、PipelineやKalibなど、いつくかの機能が動かないので、なる早でv1.0RCを試したいと思います…
- が、v0.71の記事を書いちゃったので、供養を兼ねて(ほとんどの手順はv1.0に転用できるし)。
この記事は何?
- Kubeflow v0.71のインストール方法
- 自前のNotebookコンテナイメージを使ってみた&Notebook環境にノードのデータ(KaggleのTitanic)をマウントしてみた
の2本立てです。
当初期待していたPipelinesやKalibはうまく動かせず、v1.0RC今度使ってみよう、で終わります
(KaggleのTitanicデータで前処理Pipeline作成&パラメータチューニング、までやりたかった)
Kubeflowを使おうとした背景
筆者はいつくか機械学習系のプロジェクトを回しているのですが、
- 実戦投入中の機械学習モデル精度管理
- データ処理の自動化
- アドホックなデータ分析の成果物管理
等に課題を感じていました。
最初のうちは自前でツールを整備して対処していたものの、データ分析業務(本業)に時間を取られるようになり、やがてツールは放置。陳腐化したツールは誰も使えず、精度検証や学習用のデータ前処理が他人にはできない…という状況になっていました。
MLOpsの文脈でよく耳にする「Kubeflow」を使えば上記の状態を改善できるのでは? とKubeflow試用を決意しました。
手順
本記事ではUbuntu18.04環境に、kubernetes、Kubeflow環境を整えます。
また、Dockerは別途セットアップ済みとします。
microk8sでk8sインストール
Kubeflowの前に、kubernetes(k8s)環境を整備します。
構築方法はいろいろありますが、今回は最も簡単なmicrok8sを使って構築しました。
(余談ですが、Kubeflow v1.0RCからはmicrok8sのアドオンとしてkubeflowが提供されるようになっています。microk8s選んで良かった。)
インストールは下記サイトを参考にすすめます。
https://v0-7.kubeflow.org/docs/other-guides/virtual-dev/getting-started-multipass/
スクリプト化されており、たった6行で終わります。
git clone https://github.com/canonical-labs/kubernetes-tools
cd kubernetes-tools
git checkout eb91df0 # v1.0向けに更新されるかもしれないのでcheckout
sudo ./setup-microk8s.sh
microk8s.enable registry # 自前Notebookイメージ使用に必要
microk8s.enable gpu # GPUを搭載している場合
このスクリプトでは、microk8sのv1.15がインストールされます
snap installで入る最新のmicrok8sのバージョンはv.1.17でKubeflow v0.7が非対応ですので注意。
インストール後は、
kubectl get pod --all-namespaces
ですべてのPodがRunningになっていることを確認します。
(Optional) Kubernetes Dashboradへのアクセス
デバッグ時に役立つ、k8sのダッシュボードには次のようにアクセスします。
次のコマンドを打ち、出力されたTOKENを記録
token=$(microk8s.kubectl -n kube-system get secret | grep default-token | cut -d " " -f1)
microk8s.kubectl -n kube-system describe secret $token
ポートフォワーディング
microk8s.kubectl port-forward -n kube-system service/kubernetes-dashboard 10443:443 --address=0.0.0.0
https://<hostname>:10443 にアクセスし、先のTOKENでサインインします。

Dashboardが表示されたらOKです。
kubeflowインストール
https://v0-7.kubeflow.org/docs/started/k8s/kfctl-k8s-istio/
の手順に従って進めます。
(先に使用したkubernetes-toolsのようにkubeflow-toolsというスクリプトも用意されているのですが、インストールされるkubeflowのバージョンが古いため使用しませんでした。)
kfctl バイナリダウンロード
wget https://github.com/kubeflow/kubeflow/releases/download/v0.7.1/kfctl_v0.7.1-2-g55f9b2a_linux.tar.gz
tar -xvf kfctl_v0.7.1-2-g55f9b2a_linux.tar.gz
環境変数を設定
# kfctlの実行ファイルにPATHを通す
export PATH=$PATH:"<path-to-kfctl>"
# deploymentの名前を適当につける (筆者は’kf-yums')
export KF_NAME=<your choice of name for the Kubeflow deployment>
# yamlファイル等を配置するディレクトリ(筆者は`~/.local/`)
export BASE_DIR=<path to a base directory>
export KF_DIR=${BASE_DIR}/${KF_NAME}
export CONFIG_URI="https://raw.githubusercontent.com/kubeflow/manifests/v0.7-branch/kfdef/kfctl_k8s_istio.0.7.1.yaml"
インストール
mkdir -p ${KF_DIR}
cd ${KF_DIR}
# 一度で成功しないことがある。何度かリトライ。
kfctl apply -V -f ${CONFIG_URI}
kubectl get pod --all-namespaces を実行すると、多数のコンテナが作成されていることが判る。すべてがRunningになるまで、しばらく待機。
kubeflow Dashboardにアクセス
ポートフォワーディング
# 誰でもアクセスできてしまうため、適宜アクセス制限をかけたほうがよい
kubectl port-forward -n istio-system svc/istio-ingressgateway 10080:80 --address 0.0.0.0
httpで10080番ポートにアクセスすると、Dashboard(のWelcome画面)が現れます。
なお、この構成ではURLを知っていれば誰でもアクセスできるため、セキュリティ上の懸念があります。 社内で使用する場合Dex等を使用してパスワード保護したり、ポートフォワーディングでのアクセス制限を検討したほうが良いかもしれません。

進むとNamespaceの作成画面に遷移するため、適当に設定します (筆者はkf-yumsとしました)

Finish、でKubeflowのDashboardにアクセスできます。
自前イメージでNotebook Serverを立てる
Kubeflowの機能の一つに、Jupyter Notebookのホスティング機能があります。
メモリ、CPU、(GPU)等必要なリソースと環境(Dockerイメージ)を指定するだけで、誰でも簡単にオレオレNotebook環境を作成可能。分析基盤構築の時間を削減できます。
本機能を使用して、自前のJupyter Notebook入りDockerイメージのホスティングを行ってみます。
また、k8sが動いている端末上のデータを、Notebookから参照可能にします。
自前イメージのビルドとPush
https://www.kubeflow.org/docs/notebooks/custom-notebook/
を参考にすすめます。
とりあえずは、RandomForestとか使えれば良いか…と下記のようなDockerfileを作成。
FROM python:3.8-buster
RUN pip --no-cache-dir install pandas numpy scikit-learn jupyter
ENV NB_PREFIX /
EXPOSE 8888
CMD ["sh","-c", "jupyter notebook --notebook-dir=/home/jovyan --ip=0.0.0.0 --no-browser --allow-root --port=8888 --NotebookApp.token='' --NotebookApp.password='' --NotebookApp.allow_origin='*' --NotebookApp.base_url=${NB_PREFIX}"]
ビルドします。
docker build -t myimage .
microk8sのコンテナレジストリ(localhost:32000)に本イメージをPushするため、daemon.jsonを次のように編集します。
> sudo vim /etc/docker/daemon.json
下記を追記
{
"insecure-registries" : ["localhost:32000"]
}
追記したらDockerを再起動し、microk8sのレジストリにPushします。
sudo systemctl restart docker
docker tag myimage:latest localhost:32000/myimage:latest
docker push localhost:32000/myimage:latest
レジストリPushされたイメージは次のように確認できます。
microk8s.ctr -n k8s.io images ls | grep myimage
Notebookから端末のデータを参照可能にする
上で作成したNotebookイメージには、入力データは含めていません(普通、含められません。)
ノード上の入力データをNotebook内から参照できるよう、事前にPV、PVCを作成しておきます。
ここでは、/data/titanic/ に配置したKaggleのTitanicデータセットを、Notebookから参照できるようにしてみます。
# kaggleから事前にダウンロードしたデータが配置されているものとする
> find /data/titanic
titanic/gender_submission.csv
titanic/train.csv
titanic/test.csv
PersistentVolume(PV)、PersistentVolumeClaim(PVC)を次の通り定義。
kind: PersistentVolume
apiVersion: v1
metadata:
name: titanic-pv
namespace: <kubeflowで作成したnamespace>
spec:
storageClassName: standard
capacity:
storage: 1Gi
claimRef:
namespace: <kubeflowで作成したnamespace>
name: titanic-pvc
accessModes:
- ReadWriteOnce
hostPath:
path: /data/titanic/
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: titanic-pvc
namespace: <kubeflowで作成したnamespace>
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
これを、titanic_data.yaml として保存し、
kubectl apply -f titanic_data.yaml
これでVolumeが作成されました。Notebook Server作成時に本Volumeを指定することで、中のデータをNotebookから参照できます。
Notebook Server作成
Kubeflow Dashboardから、Notebook Servers -> NEW SERVERと進みます。
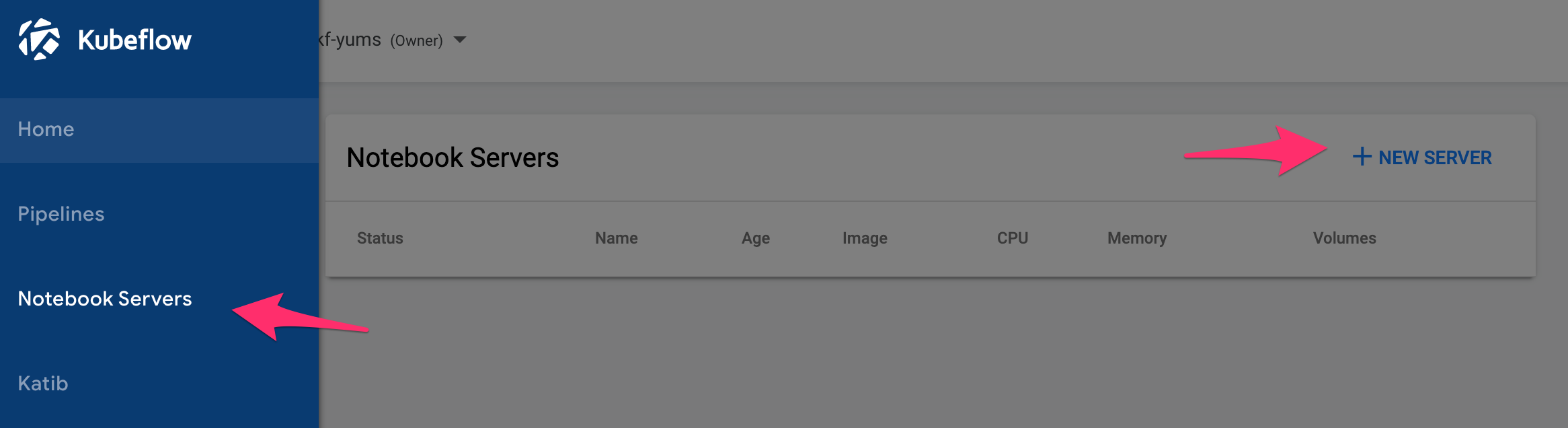
Notebook作成画面に進んだら、
Imageの項目のCustom Imageにチェックを入れ、先にPushしたイメージ
localhost:32000/myimage:latest
を指定します。

- ノートブックサーバー名
- CPU
- Memory
- Workspace Volume
は適当に設定します。

DataVolumesの項目では、先に作成したPVCを指定します。

以上を設定したら、下段のCREATEを押すと

わずか数秒で、Notebook Serverが立ち上がります。
(立ち上がらない場合、何かしらのエラーが裏で生じています。k8sのdashboardで確認できます。)
CONNECTを押すと、いつものJupyter Notebookの画面が現れます。
Titanicデータももちろん、マウントされています。

あとはいつものようにNotebookを作成し、色々データ分析しましょう。

Notebook Server以外の、動かせなかった機能たち
以上でNotebook Serverのホスティングができましたが、Kubeflowには他にも様々な機能があります。
特に注目しているのは、
- データ加工・学習・推論の処理実行と、各種KPIのトラッキングが行える
Pipeline - パラメータチューニングができる
Kalib
の2機能。
ただこの2つ… 私の環境では動きませんでした。
PipelineはJobを実行したらDockerがない、とエラー。
microk8sがコンテナの実行にDockerではなく、containerdを使用しているのが元凶でした。
issueも立ってた。
KalibはもJobを実行すると、
INFO:hyperopt.utils:Failed to load dill, try installing dill via "pip install dill" for enhanced pickling support.
INFO:hyperopt.fmin:Failed to load dill, try installing dill via "pip install dill" for enhanced pickling support.
とメッセージを出して処理が進まず。
closedされていますが、一応issueが
どちらもUpdateで解決しそうな匂いがあるので、Kubeflow v1.0RCを早速ためしてみます。