はじめに
LangChainとOpenAI APIを使ってシンプルなRAGを作ってみた。
- 検索対象ドキュメント:ローカルにあるPDFファイル
- embeddingモデル:OpenAIのtext-embedding-ada-002
- ベクトルDB:LangchainのInMemoryVectorStore
- LLM:OpenAIのgpt-4o-mini
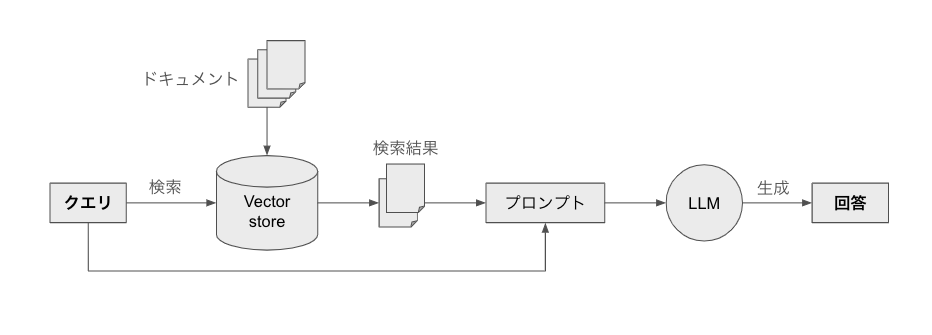
構成
- 図のような構成で、基本的にRAG・AIエージェント本で説明されていたものと同じ。
- 検索対象をローカルのPDFファイルにして、ベクトルDBをInMemoryVectorStoreにした点が異なる。
- 流れは以下の通り。
- ドキュメントをベクトル化して、ベクトルDBに格納。
- ユーザーの質問をベクトル化して、ベクトルDBを検索。
- プロンプトにユーザーの質問と検索結果のドキュメントデータを入れ、LLMに入力。
- LLMが回答を出力。
実装
Pythonと主なライブラリのバージョン
- python==3.10.15
- langchain==0.3.9
- langchain-community==0.3.8
- langchain-core==0.3.21
- langchain-openai==0.2.10
※ OSはMac
ドキュメントの用意
- 内閣府が公開している月例経済報告のpdfファイルをダウンロードして使うことにする。
- 今回は9月、10月、11月の3つのpdfファイルを使う。
OpenAIのAPIキーの設定
- 実行するpythonファイルと同じ階層に.envファイルを作成。
- .envファイルにOpenAIのAPIキーを記載。
.env
OPENAI_API_KEY="your-api-key"
- python-dotenvで環境変数を設定。
from dotenv import load_dotenv
load_dotenv()
ドキュメントの読み込み
- LangChainのPyPDFLoaderを使って読み込む。
- pdfファイルはページ単位で読み込む。
from langchain_community.document_loaders import PyPDFLoader
# pdfファイルのリスト
file_paths = ["./内閣府月例経済報告_202409.pdf", "./内閣府月例経済報告_202410.pdf", "./内閣府月例経済報告_202411.pdf"]
# pdfファイルの各ページを格納するリスト
pages = []
for file_path in file_paths:
loader = PyPDFLoader(file_path)
for page in loader.load():
pages.append(page)
ドキュメントのベクトル化とベクトルDBへの格納
- OpenAIのembeddingモデルtext-embedding-ada-002を使ってドキュメントをベクトル化。
- LangchainのInMemoryVectorStoreをベクトルDBとして使う。
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_openai import OpenAIEmbeddings
vector_store = InMemoryVectorStore.from_documents(pages, OpenAIEmbeddings())
RAG chainの作成
- RAGを実現するchainは、LCEL(LangChain Expression Language)で記載。
- Prompt template、LLM model、Output parserを繋げる基本の形を採用。
- ChatPromptTemplateでプロンプトのテンプレートを作る。
- ユーザーの質問が変数questionに入り、ベクトルDBの検索結果が変数contextに格納される。
- ChatOpneAIでLLMの設定をする。
- 検索を行うretriverはvectore_storeのas_retrieverメソッドで設定。
- as_retrieverはデフォルトで類似検索を行う。
- as_retrieverの引数search_kwargsを使って、検索方法を指定することができる。
-
search_kwargs={"k": 3}は、検索結果を3個に絞っている。
-
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
prompt = ChatPromptTemplate.from_template('''
以下の文脈だけを踏まえて質問に回答してください。
文脈: """
{context}
"""
質問: {question}
''')
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
retriever = vector_store.as_retriever(search_kwargs={"k": 3})
chain = {
"question": RunnablePassthrough(),
"context": retriever,
} | prompt | model | StrOutputParser()
RAGによる回答
- chainのinvokeメソッドを使い、質問をインプット。
query = "11月の月例経済報告の開催日は?"
chain.invoke(query)
- 以下のようにドキュメントの情報を元にLLMが回答してくれた。
'11月の月例経済報告の開催日は令和6年11月26日です。'

- 別の質問:9月の製造業での雇用人員判断DIは?
- 回答:
'9月の製造業での雇用人員判断DIは-22です。'

参考
- LangChainとLangGraphによるRAG・AIエージェント[実践]入門
- LangChain公式サイト