この記事はJubatus Advent Calenderの15日目の記事です。
Jubatusには数々の機械学習アルゴリズムが実装されています。
ここではあまり利用されることがないクラスタリング機能に着目して、実装されているアルゴリズムやその特性などをみていきたいと思います。
クラスタリングとは
クラスタリングとはデータの集まりを、データ間の類似度などの指標に従って類似したデータのグループ(クラスタ)に分割する機械学習の手法です。
正解データなしに利用することができる教師無学習であり、類似したデータ集合を抽出することができるためSNS上の話題抽出などに利用されます。
Jubatusに実装されているクラスタリングアルゴリズム
2016年12月現在、Jubatusには3つのクラスタリングアルゴリズムが実装されています。
各アルゴリズムを簡単に説明します。
K-Meansアルゴリズム
クラスタリングでは代表的なアルゴリズムの一つです。
K-Meansでは予め指定されたクラスター数に従って、クラスターの重心をデータの特徴空間に配置します。
以下のようにデータが最適に分割されるようになるまで重心位置を更新します。
- クラスター重心をランダムに配置する
- 全てのデータを最も近い重心が近いクラスタに所属すると仮定する
- 所属するデータの位置情報を使って重心位置を更新する
- 重心位置が変動しなくなるまで、2から繰り返す
クラスタの重心位置を計算に用いる関係上、クラスタは超球面であることが暗黙の前提になります。
ここのつたない説明を読むよりも、K-Meansのアルゴリズムを視覚的に説明してくれているサイトがあり、非常に分かりやすいのでぜひご参照ください。
混合ガウスモデル(GMM)アルゴリズム
GMMはデータの分布を多変量正規分布の重ね合わせで表現し、そのデータが所属する確率が最も高い確率の正規分布をそのデータのクラスタとする手法です(正直、筆者はこのアルゴリズムうまく説明する自信がないので、ぐぐっていただけると助かります!)。
GMMにおいても予めクラスタ数(=正規分布の数)を決めておく必要があります。
DBSCAN
DBSCANではデータ間の距離(ユークリッド距離)が指定された値以内であればデータをひとつのクラスタにまとめていくアルゴリズムです。まだクラスタに所属していないデータで、クラスタに所属したデータとの距離が指定された値以内であればそのクラスタに取り込んでいきます。
クラスタに取り込めるデータがなくなると、まだクラスタに所属していないデータ間の距離を計算し、新規のクラスタが作成できるかどうか判断します。
DBSCANでは、K-MeansやGMMとは異なりひとつのクラスタに所属させるデータ間の距離を定義する代わりに、事前にクラスタ数を定めておく必要がありません。
Jubatusを使ってクラスタリング
それでは実際にJubatusを使ってクラスタリングを実施してみたいと思います。なお、ソースコードはgithubに配置してあります。
クラスタリングの対象として、scikit-learnのクラスタリングのページを参考に、2次元の数値データ(位置座標)をもつデータを準備しました。
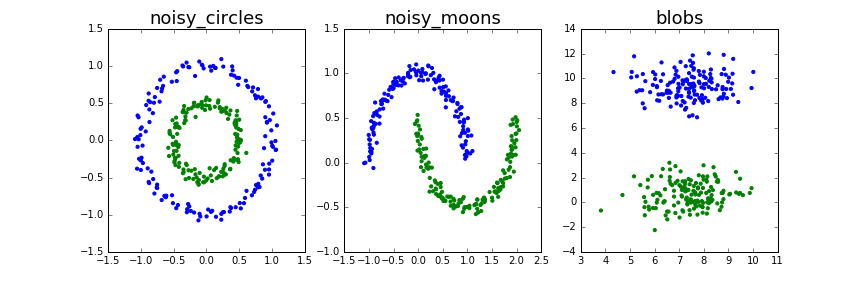
クラスタリング結果として期待したい(理想的な)クラスタを青色と緑色で示しています。
最右のblobsはともかくnoisy_circlesとnoisy_moonsはクラスタの形状が複雑で手ごわそうです。
K-Meansによるクラスタリング結果
まずはK-Meansを使ってクラスタリングしてみましょう。
ここではembedded-jubatusを使って、Jubatusのアルゴリズム部分をJubatusサーバを介さず直接呼び出しています。
まずは、Jubatusに渡す設定を定めます。
CONFIG = {
'method': 'kmeans',
'parameter': {
'k' : 2,
'seed' : 0,
},
'compressor_parameter': {
'bucket_size': 2,
},
'compressor_method' : 'simple',
'converter': {
'num_filter_types': {},
'num_filter_rules': [],
'string_filter_types': {},
'string_filter_rules': [],
'num_types': {},
'num_rules': [
{'key': '*', 'type': 'num'}
],
'string_types': {},
'string_rules': [
{'key': '*', 'type': 'space',
'sample_weight': 'bin', 'global_weight': 'bin'}
]
},
}
'method'によってK-Meansアルゴリズムを指定しています。'k'がクラスター数の指定です。またJubatusではbucket_sizeで指定した値のデータを追加するクラスタリングが実行されます。つまり、上記の設定ではデータを2個追加する度にクラスタリングが実行されることになります。また、Jubatusには大量のデータが効率的に処理するために一定のデータがたまるとデータを縮約するコアセット機能が実装されていますが、ここでは簡単化のためコアセット機能を用いないように設定('compressor_method'をsimple)しています。
'converter'はデータの変換処理です。入力されたデータをどのように特徴に変換するかを指定しています。詳しくは公式サイトをご参照ください。
ここでは'num_rules'にて入力された数値データ(データの2次元座標)をそのまま特徴としています。
K-Meansでクラスタリングした結果が以下のようになります。
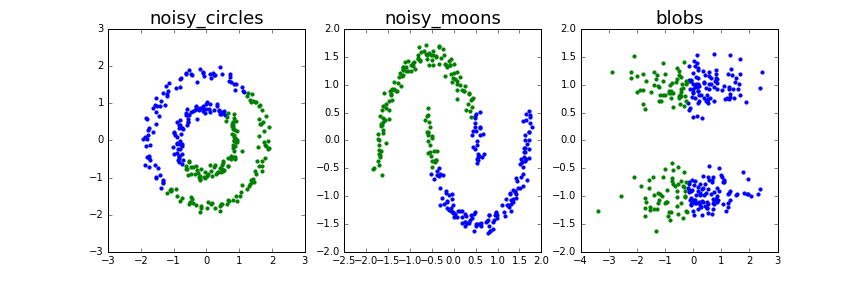
うーん、うまくクラスタリングできていませんね。K-Meansでは超球面のクラスタに分割しようとするためnoisy_circlesやnoisy_moonsなどのクラスタ形状が複雑な場合はうまくクラスタリングすることは難しいようです。
blobsのようなデータ分布だとK-Meansで正しく分類できることが期待されるのですが、おそらく分布が楕円状になっているため今回はうまくクラスタリングできなかったものと考えられます。
GMMによるクラスタリング結果
続いてGMMによるクラスタリングを試してみましょう。
先ほどのK-Meansでの設定から以下を変更します。
CONFIG['method'] = 'gmm'
GMMのハイパーパラメータはK-Meansと同等であるため、'method'を変更するだけでGMMを実行することができます。
GMMによるクラスタリング結果は次のようになりました。;
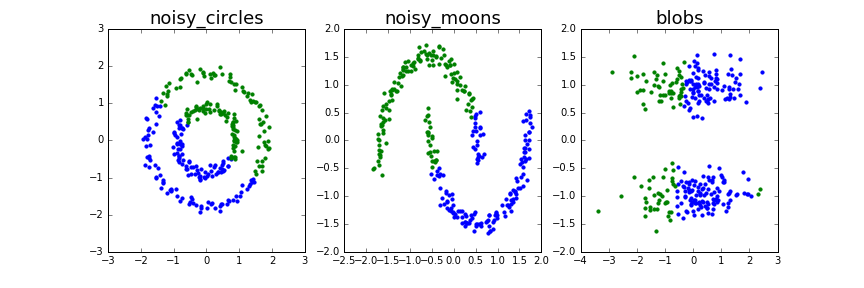
若干の違いはあるものの、K-Meansと同じような結果になっています。
GMMは分布を用いることで、K-Meansより複雑な形状のクラスタでもクラスタリングできるようになっているのですが、ここでは若干期待外れの結果になっています。今後、原因の分析したいと思います。
DBSCANによるクラスタリング結果
最後にDBSCANによるクラスタリングを試してみたいと思います。
DBSCANはK-MeansやGMMとはハイパーパラメータが異なるため、以下のように設定します。
CONFIG['method'] = 'dbscan'
if 'k' in CONFIG['parameter']:
del(CONFIG['parameter']['k'])
if 'seed' in CONFIG['parameter']:
del(CONFIG['parameter']['seed'])
CONFIG['parameter']['eps'] = 0.3
CONFIG['parameter']['min_core_point'] = 2
k,seedを削除し、eps,min_core_pointを追加しています。epsは前述したひとつのクラスタと識別するデータ間の距離です。またmin_core_pointはeps内の距離にあるデータ数がここで指定した数値以下だった場合はクラスタとして採用しないとするものです。孤立点が独立したクラスタとして認識されることを防ぐような目的に使います。
上記の設定でクラスタリングを実行した結果が以下の通りです。
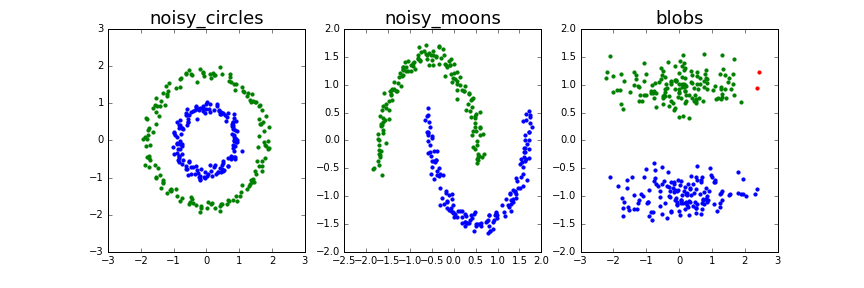
noisy_circlesやnoisy_moonsでほぼ理想的なクラスタを抽出できていることが分かります。
データ間の距離だけでクラスタを識別するため、クラスタの形状が複雑でも対応できるようです。
blobsでは右上に赤色の点があります。これは3つ目のクラスタとして認識されてしまったデータ群です。
まとめ
Jubatusの数ある機械学習アルゴリズムでも目立たない存在であるクラスタリング機能を使い、様々な分布のデータでクラスタリングの抽出を試みました。
今回の例ではDBSCANが最も理想的なクラスタを抽出しました。
ただ、DBSCANにも弱点があり、それはepsの値を決めるのが非常に難しいということです。
値を大きくしすぎてしまうと全てのデータを一つのクラスタにまとめてしまい、また値を小さくしすぎてしまうと多数の小さなクラスタができてしまいます。
今回の実験においてもクラスタ結果を見ながらepsの値を変更する、という試行錯誤を5,6回は行っています。
また、今回は2次元平面上のデータであったため、クラスタリング結果を可視化して、epsを調整することができましたが、文章データを対象にした場合、データサイズによっては特徴空間は数万次元~数十万次元になることも珍しくありません。このような高次元特徴空間では可視化自体が困難であるため、別の調整方法を考える必要があります。
このように、実データにおけるクラスタリングを考えたとき、Jubatusのクラスタリング機能はまだまだ改善の余地が大きいといえます。
我こそはという方はぜひ、Jubatusクラスタリング機能への機能追加・改善のコミットお待ちしております!
次回のJubatus Advent Calendarは@shiodatによる可視化についてです。よろしくお願いします!