本文書について
タイトルは少し盛りました。
frequentryではありません。すみません
本文書では、COTOHA APIの構文解析機能を使って、任意のテキストから質問と回答のペアを生成する「QA生成器」について述べる。
QA生成器
背景
商品文書やらチャットデータから、FAQを作りたいというニーズは結構あるらしい。
ものは試しと作ったQA生成器だが、割と面白いと好評だったので調子にのって公開してみる。
概要
↓下記のように解析される文があったとして
「今朝おばあさんが川から拾った桃を切ろうとしたら、桃が突然割れて中から男の子が飛び出してきた」
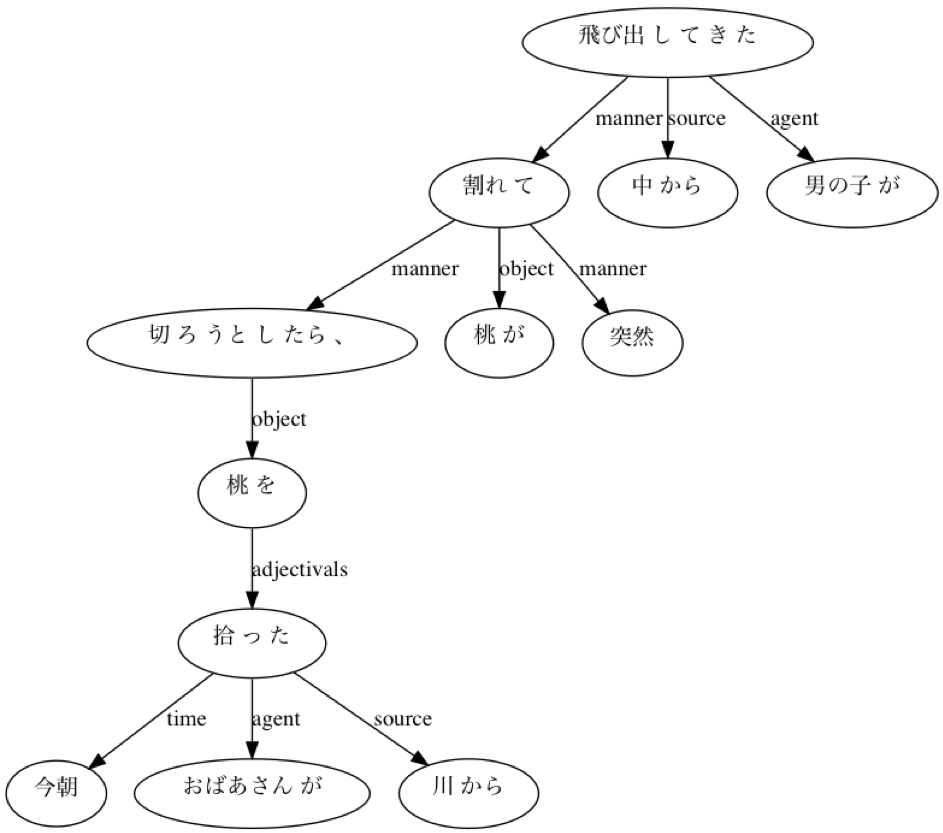
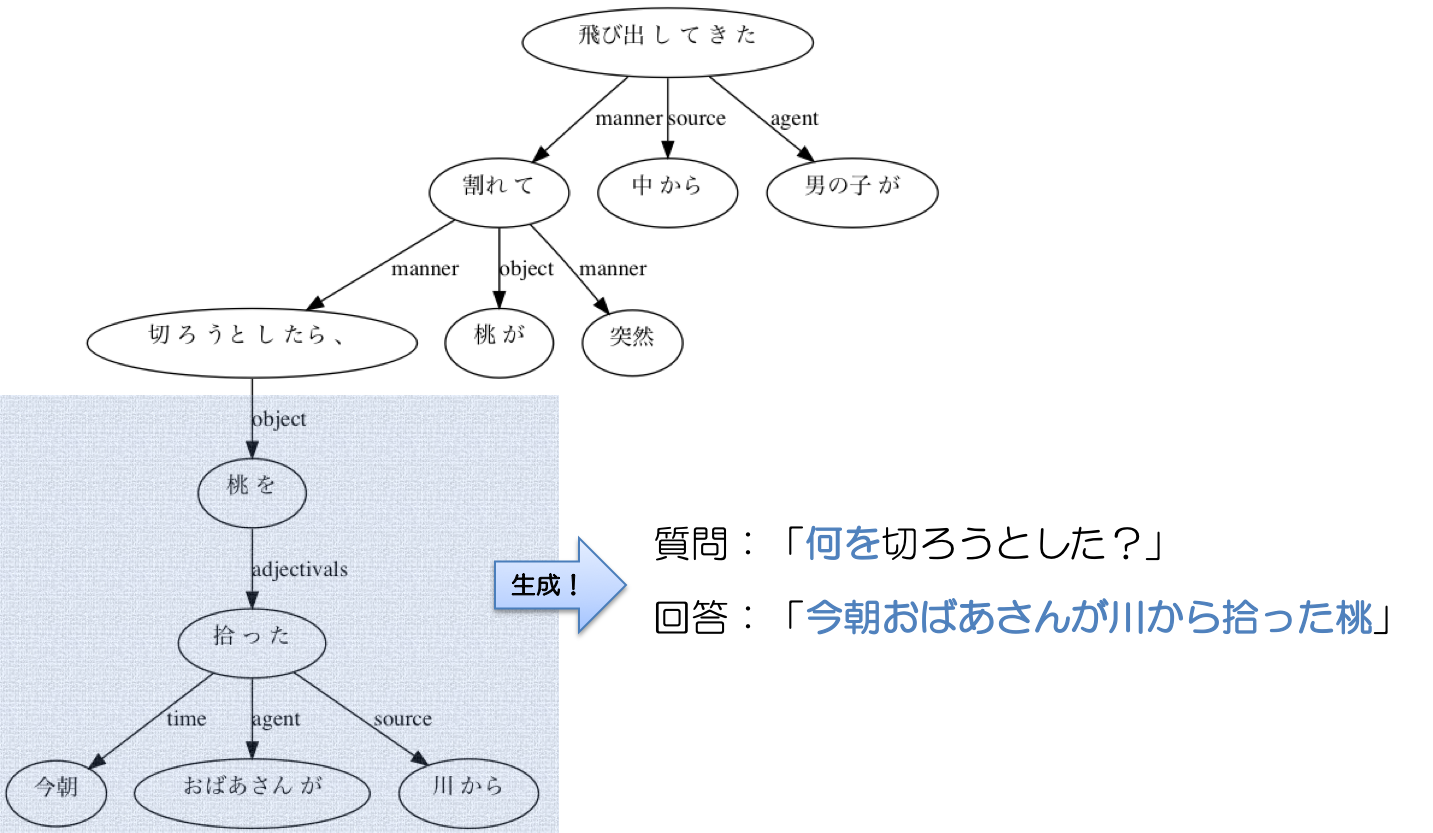
↓こうすれば質問文が作れる。
↓さらに、場所や時間に関する質問文も作れる。
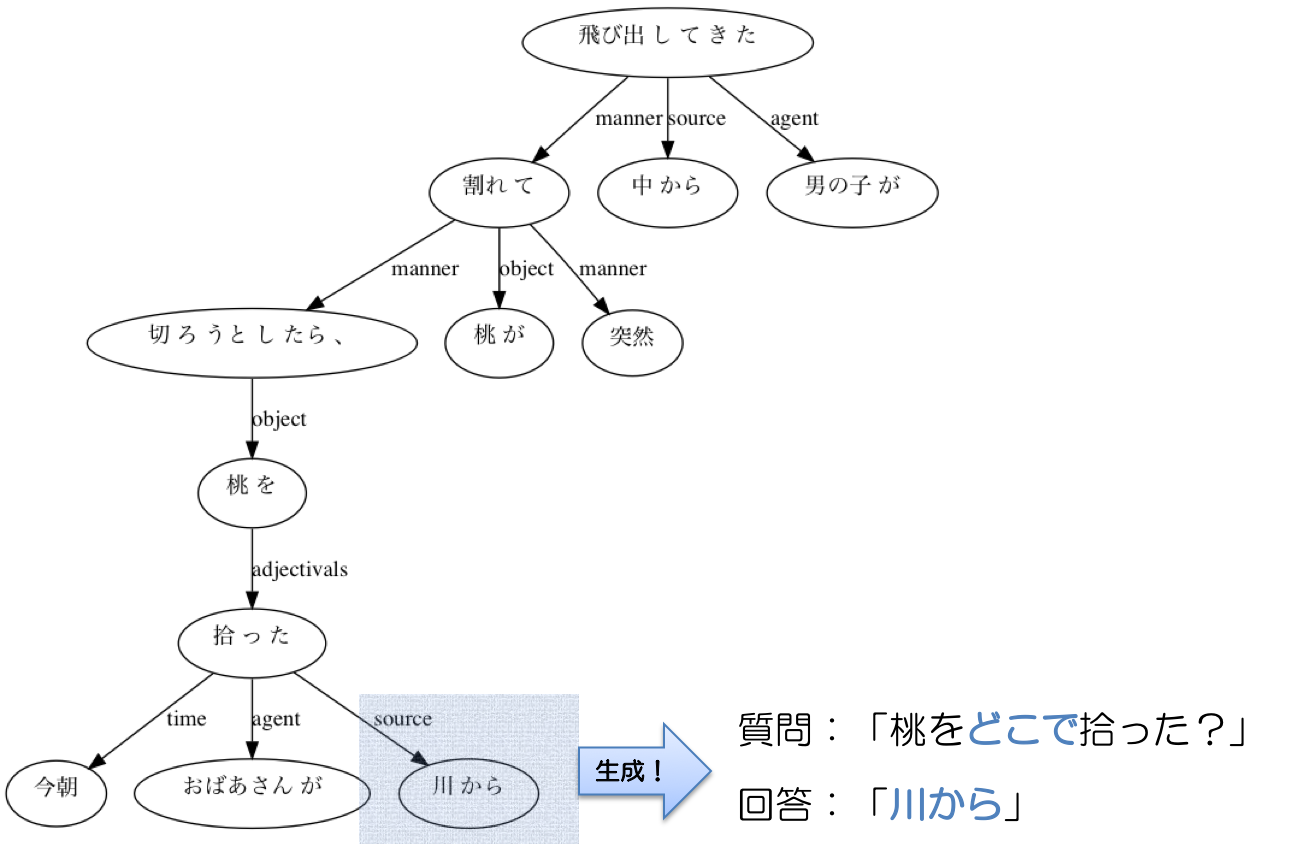
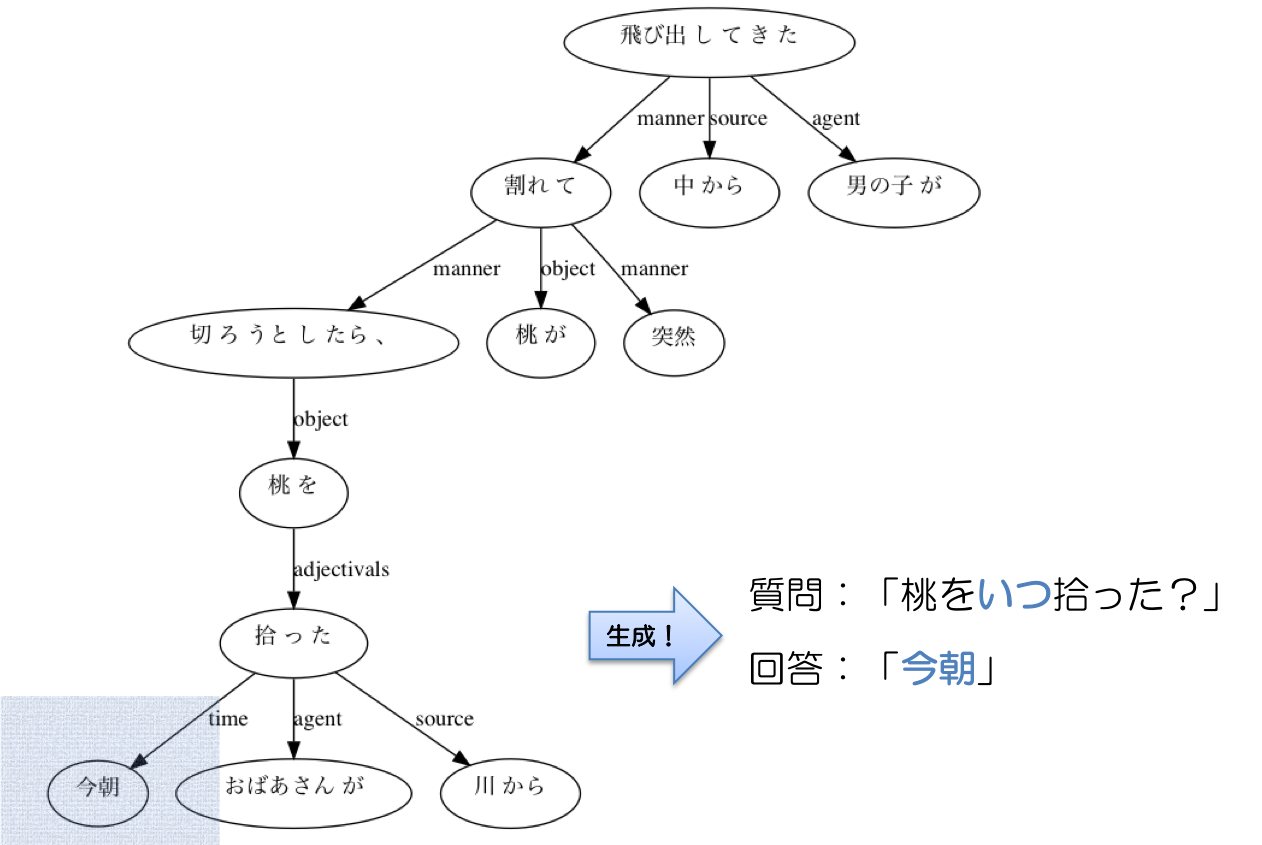
このように、構文解析結果に object や place や time などの、深層格情報が含まれているため、ある程度のバリエーションを持った質問文を作ることができる。
動作環境
python3.6.2
スクリプト全体
クリックして開いてください
# -*- coding: utf-8 -*-
import os
import json
import requests
import pickle
CLIENT_ID = 'XXX'
CLIENT_SECRET = 'XXX'
API_BASE_URL = 'https://api.ce-cotoha.com/api/dev/nlp/'
ACCESS_TOKEN_PUBLISH_URL = 'https://api.ce-cotoha.com/v1/oauth/accesstokens'
def get_access_token():
headers = {'Content-Type': 'application/json',
'charset': 'UTF-8',}
data = {'grantType':'client_credentials',
'clientId':CLIENT_ID,
'clientSecret':CLIENT_SECRET}
data = json.dumps(data)
response = requests.post(ACCESS_TOKEN_PUBLISH_URL, headers=headers, data=data)
response = json.loads(response.text)
return response['access_token']
if not os.path.isfile('./ACCESS_TOKEN.pickle'):
ACCESS_TOKEN = get_access_token()
with open('ACCESS_TOKEN.pickle', mode='wb') as f:
pickle.dump(ACCESS_TOKEN, f)
with open('ACCESS_TOKEN.pickle', mode='rb') as f:
ACCESS_TOKEN = pickle.load(f)
def parse(sentence):
global ACCESS_TOKEN
headers = {'Content-Type': 'application/json',
'charset': 'UTF-8',
'Authorization': 'Bearer '+ACCESS_TOKEN}
data = {'sentence':sentence,}
data= json.dumps(data)
response = requests.post(API_BASE_URL+'v1/parse', headers=headers, data=data)
response = json.loads(response.text)
if response['status'] == 99998:
ACCESS_TOKEN = get_access_token()
with open('ACCESS_TOKEN.pickle', mode='wb') as f:
pickle.dump(ACCESS_TOKEN, f)
return parse(sentence)
return response
class QAGeneration:
def __init__(self):
self.parsed_sentence = None
self.dependencies = list()
self.chunkid2text = dict()
def _extract_dependencies(self,jsonfile):
chunkid2text = dict()
dependencies = list()
# 解析結果(json)から係り受け情報を抽出
for chunk in jsonfile["result"]:
chunk_id = chunk["chunk_info"]["id"]
tokens = [token["form"] for token in chunk["tokens"]]
chunkid2text[chunk_id] = "".join(tokens)
for link in chunk["chunk_info"]["links"]:
dependencies.append([chunk_id,link["link"],link["label"]])
return dependencies,chunkid2text
def _TorF_id_in_subtree_root_id(self,id,subtree_root_id):
checklist = [item for item in self.dependencies if item[0]==subtree_root_id]
if id in [item[1] for item in checklist]:
return True
else:
for p,c,_ in checklist:
if c in [item[0] for item in self.dependencies]:
return self._TorF_id_in_subtree_root_id(id,c)
return False
def _get_subtree_texts(self,subtree_root_id):
parent_ids = [item[0] for item in self.dependencies]
if subtree_root_id not in parent_ids:
return self.chunkid2text[subtree_root_id]
else:
text = ''
for item in self.dependencies:
if item[0]!=subtree_root_id:continue
text += self._get_subtree_texts(item[1])
text += self.chunkid2text[subtree_root_id]
return text
def generate_QA(self,sentence):
self.parsed_sentence = parse(sentence)
self.dependencies,self.chunkid2text = self._extract_dependencies(self.parsed_sentence)
qas = list()
qas += self._agent2what_QA()
qas += self._aobject_ha2what_QA()
qas += self._object_wo2what_QA()
qas += self._object_ga2what_QA()
qas += self._time2when_QA()
qas += self._place2where_QA()
qas += self._source2where_QA()
qas += self._goal_he2where_QA()
qas += self._goal_ni2where_QA()
qas += self._purpose2why_QA()
return qas
def _agent2what_QA(self):
question_and_answers = list()
target_dependencies = [item for item in self.dependencies if item[2]=='agent']
for item in target_dependencies:
target_id = item[1]
q = ''
a = ''
for i in range(len(self.chunkid2text)):
if i==target_id:
q += '何が、'
a = self._get_subtree_texts(i)
elif self._TorF_id_in_subtree_root_id(i,target_id):
continue
else:
q += self.chunkid2text[i]
q += 'か?'
q = q.replace('。','')
question_and_answers.append([q,a])
return question_and_answers
def _aobject_ha2what_QA(self):
question_and_answers = list()
target_dependencies = [item for item in self.dependencies if item[2]=='aobject' \
and self.chunkid2text[item[1]][-1]=='は']
for item in target_dependencies:
target_id = item[1]
q = ''
for i in range(len(self.chunkid2text)):
if i==target_id:
q += '何が、'
a = self._get_subtree_texts(i)
elif self._TorF_id_in_subtree_root_id(i,target_id):
continue
else:
q += self.chunkid2text[i]
q += 'か?'
q = q.replace('。','')
question_and_answers.append([q,a])
return question_and_answers
def _object_wo2what_QA(self):
question_and_answers = list()
target_dependencies = [item for item in self.dependencies if item[2]=='object' \
and self.chunkid2text[item[1]][-1]=='を']
for item in target_dependencies:
target_id = item[1]
q = ''
for i in range(len(self.chunkid2text)):
if i==target_id:
q += '何を'
a = self._get_subtree_texts(i)
elif self._TorF_id_in_subtree_root_id(i,target_id):
continue
else:
q += self.chunkid2text[i]
q += 'か?'
q = q.replace('。','')
question_and_answers.append([q,a])
return question_and_answers
def _object_ga2what_QA(self):
question_and_answers = list()
target_dependencies = [item for item in self.dependencies if item[2]=='object' \
and self.chunkid2text[item[1]][-1]=='が']
for item in target_dependencies:
target_id = item[1]
q = ''
for i in range(len(self.chunkid2text)):
if i==target_id:
q += '何が'
a = self._get_subtree_texts(i)
elif self._TorF_id_in_subtree_root_id(i,target_id):
continue
else:
q += self.chunkid2text[i]
q += 'か?'
q = q.replace('。','')
question_and_answers.append([q,a])
return question_and_answers
def _time2when_QA(self):
question_and_answers = list()
target_dependencies = [item for item in self.dependencies if item[2]=='time']
for item in target_dependencies:
target_id = item[1]
q = ''
for i in range(len(self.chunkid2text)):
if i==target_id:
q += 'いつ、'
a = self._get_subtree_texts(i)
elif self._TorF_id_in_subtree_root_id(i,target_id):
continue
else:
q += self.chunkid2text[i]
q += 'か?'
q = q.replace('。','')
question_and_answers.append([q,a])
return question_and_answers
def _place2where_QA(self):
question_and_answers = list()
target_dependencies = [item for item in self.dependencies if item[2]=='place' \
and self.chunkid2text[item[1]][-1]=='で']
for item in target_dependencies:
target_id = item[1]
q = ''
for i in range(len(self.chunkid2text)):
if i==target_id:
q += '何処で'
a = self._get_subtree_texts(i)
elif self._TorF_id_in_subtree_root_id(i,target_id):
continue
else:
q += self.chunkid2text[i]
q += 'か?'
q = q.replace('。','')
question_and_answers.append([q,a])
return question_and_answers
def _source2where_QA(self):
question_and_answers = list()
target_dependencies = [item for item in self.dependencies if item[2]=='source' \
and self.chunkid2text[item[1]][-2:]=='から']
for item in target_dependencies:
target_id = item[1]
q = ''
for i in range(len(self.chunkid2text)):
if i==target_id:
q += '何処から'
a = self._get_subtree_texts(i)
elif self._TorF_id_in_subtree_root_id(i,target_id):
continue
else:
q += self.chunkid2text[i]
q += 'か?'
q = q.replace('。','')
question_and_answers.append([q,a])
return question_and_answers
def _goal_he2where_QA(self):
question_and_answers = list()
target_dependencies = [item for item in self.dependencies if item[2]=='goal' \
and self.chunkid2text[item[1]][-1]=='へ']
for item in target_dependencies:
target_id = item[1]
q = ''
for i in range(len(self.chunkid2text)):
if i==target_id:
q += '何処へ'
a = self._get_subtree_texts(i)
elif self._TorF_id_in_subtree_root_id(i,target_id):
continue
else:
q += self.chunkid2text[i]
q += 'か?'
q = q.replace('。','')
question_and_answers.append([q,a])
return question_and_answers
def _goal_ni2where_QA(self):
question_and_answers = list()
target_dependencies = [item for item in self.dependencies if item[2]=='goal' \
and self.chunkid2text[item[1]][-1]=='に']
for item in target_dependencies:
target_id = item[1]
q = ''
for i in range(len(self.chunkid2text)):
if i==target_id:
q += '何に'
a = self._get_subtree_texts(i)
elif self._TorF_id_in_subtree_root_id(i,target_id):
continue
else:
q += self.chunkid2text[i]
q += 'か?'
q = q.replace('。','')
question_and_answers.append([q,a])
return question_and_answers
def _purpose2why_QA(self):
question_and_answers = list()
target_dependencies = [item for item in self.dependencies if item[2]=='purpose']
for item in target_dependencies:
target_id = item[1]
q = ''
for i in range(len(self.chunkid2text)):
if i==target_id:
q += 'なぜ、'
a = self._get_subtree_texts(i)
elif self._TorF_id_in_subtree_root_id(i,target_id):
continue
else:
q += self.chunkid2text[i]
q += 'か?'
q = q.replace('。','')
question_and_answers.append([q,a])
return question_and_answers
if __name__ == "__main__":
qa_generator = QAGeneration()
results = qa_generator.generate_QA('今朝おばあさんが川から拾った桃を切ろうとしたら、桃が突然割れて中から男の子が飛び出してきた')
for q,a in results:
print(' Q : ',q)
print(' A : ',a)
print()
使ってみる
「今朝おばあさんが川から拾った桃を切ろうとしたら、桃が突然割れて中から男の子が飛び出してきた」
Q : 今朝何が、川から拾った桃を切ろうとしたら、桃が突然割れて中から男の子が飛び出してきたか?
A : おばあさんが
Q : 今朝おばあさんが川から拾った桃を切ろうとしたら、桃が突然割れて中から何が、飛び出してきたか?
A : 男の子が
Q : 何を切ろうとしたら、桃が突然割れて中から男の子が飛び出してきたか?
A : 今朝おばあさんが川から拾った桃を
Q : 今朝おばあさんが川から拾った桃を切ろうとしたら、何が突然割れて中から男の子が飛び出してきたか?
A : 桃が
Q : いつ、おばあさんが川から拾った桃を切ろうとしたら、桃が突然割れて中から男の子が飛び出してきたか?
A : 今朝
Q : 今朝おばあさんが何処から拾った桃を切ろうとしたら、桃が突然割れて中から男の子が飛び出してきたか?
A : 川から
Q : 今朝おばあさんが川から拾った桃を切ろうとしたら、桃が突然割れて何処から男の子が飛び出してきたか?
A : 中から
「何を切ろうとしたか?」に対して「今朝おばあさんが川から拾った桃を」などの、構文解析結果を踏まえてまとまったフレーズを回答として抽出できる点が良いところ。
一方で、「何が切ろうとしたか?」「おばあさんが」など、人が回答となる質問にもかかわらず「何」という疑問詞を使う点は改善したいところ。おばあさんが人であることを理解できれば、「誰が」などのwho質問に置き換えられそう。
「おばあさんが川で洗濯をしていると、川上から大きな桃がどんぶらこっこ どんぶらこっこ」
Q : 何が、川で洗濯をしていると、川上から大きな桃がどんぶらこっこ どんぶらこっこか?
A : おばあさんが
Q : おばあさんが川で洗濯をしていると、川上から何が、どんぶらこっこ どんぶらこっこか?
A : 大きな桃が
Q : おばあさんが川で何をしていると、川上から大きな桃がどんぶらこっこ どんぶらこっこか?
A : 洗濯を
Q : おばあさんが何処で洗濯をしていると、川上から大きな桃がどんぶらこっこ どんぶらこっこか?
A : 川で
Q : おばあさんが川で洗濯をしていると、何処から大きな桃がどんぶらこっこ どんぶらこっこか?
A : 川上から
質問らしくするために、最後に「か?」を挿入している。
オノマトペで終わる文でも、まあ質問文としては成り立っている…か?
「んでバーが川で洗濯してたら、川上から大きな桃が ジャスティスウェーイ ジャスティスウェーイ」
Q : んで何が、川で洗濯してたら、川上から大きな桃が ジャスティスウェーイ ジャスティスウェーイか?
A : バーが
Q : んでバーが川で洗濯してたら、何が、 ジャスティスウェーイ ジャスティスウェーイか?
A : 川上から大きな桃が
Q : んでバーが何処で洗濯してたら、川上から大きな桃が ジャスティスウェーイ ジャスティスウェーイか?
A : 川で
Q : んでバーが川で洗濯してたら、何処から大きな桃が ジャスティスウェーイ ジャスティスウェーイか?
A : 川上から
突然バイブスが上がっても問題なく質問生成できた。
参考:https://news.nicovideo.jp/watch/nw1526903
まとめ
深層格情報をうまく使うことで、自然な文で、質問及び回答生成ができた。
工夫次第でさらに高度な質問も生成できそう。