みなさん、こんにちは山口です。
この記事はノンプロ研(ノンプログラマーのためのスキルアップ研究会)の『ノンプロ研 Advent Calendar 2021』 23日目の記事です。
集計表を集計しなおしたい
ノンプロ研のSlackのGASチャンネルに、書き込まれた質問が発端でした。仕事で使う集計表を集計しなおしたいというご希望です。
ある教室にクラスが3つあって、先生が4人(A, B, C, D)いるとします。クラスの担当表はこのような形になります。
表A クラス別の担当表
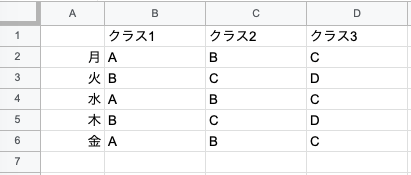
これを各先生がどのクラスを担当したかという風に集計しなおします。
表B 先生別の担当表
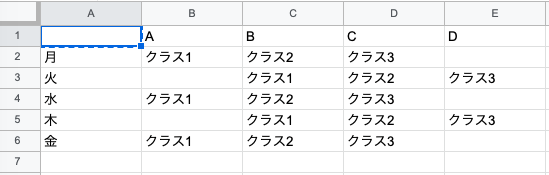
これ、簡単そうにみえて結構ややこしいです。Rやpythonやパワークエリーだと便利なメソッドがあって一発なのですが、残念ながらGASにはありません。
しかし、毎回Rにデータをもっていくのも面倒なので、GASでクラスを書いてみました。
集計表と構造化データ
表Aも表Bも縦軸と横軸にラベルがある、いわゆる集計表とよばれるものです。しかし、集計表はにんげんには見やすいものの、コンピューターにとっては読みにくいフォーマットになっています。
そこでコンピューターにわかりやすい整然データと呼ばれる形式に変換することを考えます。
表C 整然データ
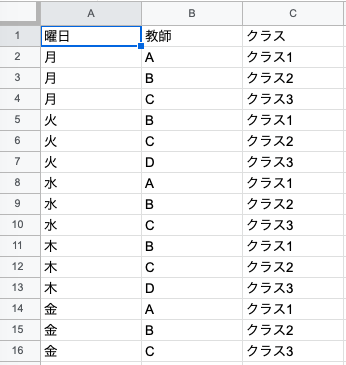
整然データは1行目にのみラベルがあり、あとはすべてデータがならんでいます。表A,表Bに比べると縦長になっています。
整然データは
- 1つの変数は1つの列にまとまっている
- 1つのデータは1行にまとまっている
- 1つのセルには1つの値しかはいっていない
というような特徴があります。
このあたりはこちらの記事がとてもわかりやすいです。
表Aから表Bに直接変換することもできなくはないのですが、コンピュータからすると整然データのほうがあつかいやすいため、集計表をいったん整然データに変換します。そして整然データから、目的とする集計表をつくります。こうすることで、どのような集計表でも集計しなおせるので、汎用性も高まります。
Rのtidyrパッケージでは、集計表を整然データに変換するのに pivot_longer、整然データを集計表に変換するのに pivot_wider という関数が用意されています。これをGoogle Apps Scriptで書いてみました。
コード
こちらがTableクラスです。
class Table {
constructor(tableData) {
this.values = tableData;
[this.headers, ...this.data] = tableData;
}
/**
* クロス表のデータを構造化データに変換する
*
* @param {string}rowName 行のラベル名
* @param {string}columnName 列のラベル名
* @param {string}dataName データのラベル名
*/
pivotLonger(rowName = '行ラベル', columnName = '列ラベル', dataName = 'データラベル') {
const newValues = [[rowName, dataName, columnName]];
const values = this.getValues();
const rowNames = this.getRowName();
values.forEach((record, i) => record.
forEach((value, j) => newValues.push([rowNames[i], value, this.headers[j + 1]]))
);
return newValues;
}
/**
* 構造化データをクロス表に変換する
*
* @param {string}}rowLabel クロス表の行にするラベル名
* @param {string}columnLabel クロス表の列にするラベル名
* @param {string}dataLabel クロス表のデータにするラベル名
*/
pivotWider(rowLabel, columnLabel, dataLabel) {
const data = this.values;
const header = data.shift(); // [ '曜日', '教師', 'クラス' ]
const rowIndex = header.indexOf(rowLabel); //0
const columnIndex = header.indexOf(columnLabel); //1
const dataIndex = header.indexOf(dataLabel); //2
const rowLabels = data.map(record => record[rowIndex]);
const rowLabelArray = unique(rowLabels); // [ '月', '火', '水', '木', '金' ]
const colLabels = data.map(record => record[columnIndex]);
const colLabelArray = unique(colLabels); //[ 'A', 'B', 'C', 'D' ]
const nullArray = colLabelArray.map(() => '');
const newData = rowLabelArray.map(() => nullArray.concat());
data.forEach(record => {
const rowNumber = rowLabelArray.indexOf(record[rowIndex]);
const colNumber = colLabelArray.indexOf(record[columnIndex]);
newData[rowNumber][colNumber] = record[dataIndex];
})
//newDataに行と列を足す
const newTable = newData.concat();
newTable.unshift(colLabelArray);
const newRowLabel = rowLabelArray.concat();
newRowLabel.unshift('');
newTable.forEach((row,i) => row.unshift(newRowLabel[i]));
return newTable;
};
getValues() {
const result = this.values.map(record => {
const [_, ...values] = record;
return values;
});
result.shift();
return result;
}
getRowName() {
const rowName = this.data.map(record => record[0]);
return rowName;
}
getColName() {
const colName = this.headers;
colName.shift();
return colName;
}
}
途中で受け取った配列をユニークな配列に変換する必要があり、unique関数も作りました。
これをTableクラスに続けて書きます。
/**
* 受け取った配列をユニークにして返す
*
* @param {array} 配列
* @result {array} 配列
*/
function unique(array){
const object = new Set(array);
const result = Array.from(object);
return result;
}
これで出来上がりです。
表データを二次元配列として渡すとTableクラスが作成されます。
ヘッダーは1行目だけという前提です。
ついでに値(getValues)、行ラベル(getRowName)、列ラベル(getColName)をそれぞれ配列で取り出すメソッドを追加しました。これは @etau さんからパクりました。
使い方
では実際に使ってみましょう。
まず空のスプレッドシートを作って、スクリプトエディターを立ち上げてください。
次に下のsheetSetUp関数をエディターに貼り付けて、保存して、実行しましょう。
初回は権限の承認画面が出るので、承認してください。
function sheetSetUp(){
const values = [ [ '', 'クラス1', 'クラス2', 'クラス3' ],
[ '月', 'A', 'B', 'C' ],
[ '火', 'B', 'C', 'D' ],
[ '水', 'A', 'B', 'C' ],
[ '木', 'B', 'C', 'D' ],
[ '金', 'A', 'B', 'C' ] ]
const sheet = SpreadsheetApp.getActiveSheet();
sheet.getRange(1,1,values.length,values[0].length).setValues(values);
}
すると表Aが出来上がります。
上のtableクラスとunique関数をエディターに貼り付けます。これで準備完了です。
集計表から整然データへ変換
まず、集計表から整然データへ変換します。
下記のコードをエディターに 貼り付けて、保存して、実行します。
function makePivotLongerTable() {
const sheet = SpreadsheetApp.getActiveSpreadsheet().getSheetByName('シート1');
const originalData = sheet.getDataRange().getValues();
const table = new Table(originalData);
const newTable = table.pivotLonger('曜日', 'クラス', '教師');
const sheet2 = SpreadsheetApp.getActiveSpreadsheet().insertSheet();
sheet2.getRange(1, 1, newTable.length, newTable[0].length).setValues(newTable);
}
すると新しいシートが挿入されて整然データが出来上がります。
コード4行目の曜日、クラス、教師が1行目のラベルになっているのがわかると思います。
ご自分のデータで使うときにはここを適宜書き換えてください。
整然データから集計表へ
次にこの整然データから集計表を作り直します。
下記のコードをエディターに貼りつけて、実行します。
1行目の「シート2」のところは整然データのあるシート名です。適宜変更して下さい。
function makePivotWiderTable() {
const sheet = SpreadsheetApp.getActiveSpreadsheet().getSheetByName('シート2');
const sheet2Data = sheet.getDataRange().getValues();
const table2 = new Table(sheet2Data);
const newTable = table2.pivotWider('曜日', '教師', 'クラス');
const sheet2 = SpreadsheetApp.getActiveSpreadsheet().insertSheet();
sheet2.getRange(1, 1, newTable.length, newTable[0].length).setValues(newTable);
}
これで出来上がりました!
GAS以外のやり方
Rではpivot_longer, pivot_wider というメソッドですが、以前は gather, spreadと呼ばれていました。古い記事だとこの名前で出ています。
Pyhonのpandas では unstack, stackあたりだと思います。また pivotを使うと集計表から集計表に直接組み直せます。
パワークエリーでもできるようです。
さらにスプレッドシートの関数だけでも可能です。
こちらは @plumfield56 謹製
中間テーブルはF3にQuery関数が入っています。
出力はindex, matchの組み合わせでできています。
関数だけでもかなりいけますね〜。