はじめに
ganでアニメキャラクターを生成するというのは結構やり尽くされた分野のようにも思えますが、1から解説していこうと思います。
主に参考にしたサイト
できあがったもの


実行環境
windows10
ryzen3700x
rtx2070(8GB)
メモリ32GB
tensorflow-gpu==1.15.0
Cudnn7.6.5
Cuda10.0
Keras2.3.1
こちらの1.xで作った環境です。
データセットの作成
1.画像の取得
何かしら、画像を集めてください。
2.画像の分類
集めた画像から、今回の学習に適した画像を選別していきます。
今回は白黒とカラーの中から、カラーを選別していきます。
こちらのサイトのプログラムを使用しました。
しかし正直性能はいまいちですので、大量にあるときに一段階目の仕分けに使えるかなという感じです。
opencvはパスに全角文字が使用されていると読み込めないので注意
こちらのコードを実行すればそれぞれ選別されてコピーされます。
import cv2
import numpy as np
import os
# モノクロ画像に変換
def to_gray(path):
img = cv2.imread(path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cv2.imwrite(os.path.splitext(path)[0] + '_gray.jpg', gray)
# 彩度を変更
def conv_saturation(path,sat):
img = cv2.imread(path)
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
h, s, v = cv2.split(hsv)
s[:,:] = sat
hsv = cv2.merge((h,s,v));
img = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)
cv2.imwrite('{}_sat{:03d}.jpg'.format(os.path.splitext(path)[0],sat), img)
# 提示ソースの判定用の値
def get_ratio(path):
img = cv2.imread(path)
b, g, r = cv2.split(img)
r_g = np.count_nonzero(abs(r - g))
r_b = np.count_nonzero(abs(r - b))
g_b = np.count_nonzero(abs(g - b))
diff_sum = float(r_g + r_b + g_b)
return diff_sum / img.size # > 0.005
# カラー画像か判定
# Detect if image is color, grayscale or black and white with Python/PIL
# https://stackoverflow.com/questions/20068945/detect-if-image-is-color-grayscale-or-black-and-white-with-python-pil
def detect_color_image(file, MAYBE_COLOR = 300):
from PIL import Image, ImageStat
from functools import reduce
MONOCHROMATIC_MAX_VARIANCE = 0.005
COLOR = 1000
v = ImageStat.Stat(Image.open(file)).var # =分散
is_monochromatic = reduce(lambda x, y: x and y < MONOCHROMATIC_MAX_VARIANCE, v, True)
if is_monochromatic:
return "Monochromatic image"
else:
mes = '?'
if len(v)==3: # color
maxmin = abs(max(v) - min(v))
if maxmin > COLOR:
mes = "Color"
image_copy(file, Color_path)
elif maxmin > MAYBE_COLOR:
mes = "Maybe color"
image_copy(file, Maybe_color_path)
else:
mes = "grayscale"
image_copy(file, grayscale_path)
return '{}({})'.format(mes, maxmin)
elif len(v)==1:
image_copy(file, Black_and_white_path)
return "Black and white"
else:
image_copy(file, unknown_path)
return "Don't know..."
def image_copy(file, dst):
import shutil
shutil.copy(file, dst)
#画像の入力元、出力先のパス設定
from pathlib import Path
import glob
#opencvはasciiのみ
base_path = "./base_path"
Color_path = "./color_sorted/color"
Maybe_color_path = "./color_sorted/maybe_color"
grayscale_path = "./color_sorted/gray"
Black_and_white_path = "./color_sorted/bw"
unknown_path = "./color_sorted/unknown"
paths = glob.glob(base_path + "/*")
# 各画像を判定
for path in paths:
print(path)
print(get_ratio(path)) # 提示ソースの判定値
print(detect_color_image(path))
print()
なお最後のほうの
#画像の入力元、出力先のパス設定
from pathlib import Path
import glob
#opencvはasciiのみ
base_path = "./base_path"
Color_path = "./color_sorted/color"
Maybe_color_path = "./color_sorted/maybe_color"
grayscale_path = "./color_sorted/gray"
Black_and_white_path = "./color_sorted/bw"
unknown_path = "./color_sorted/unknown"
は自分で設定してください。
3.顔検出
古い記事ですが、これが画像検出の中心みたいですね。
今回はopencvを使って検出していきます。
なおこちらの記事のコードをもとに作成しています。
import cv2
import sys
import os.path
from time import sleep
import glob
import os
def detect(filename, num, cascade_file = "./lbpcascade_animeface.xml"):
#print(filename)
if not os.path.isfile(cascade_file):
raise RuntimeError("%s: not found" % cascade_file)
cascade = cv2.CascadeClassifier(cascade_file)
image = cv2.imread( filename , cv2.IMREAD_COLOR)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.equalizeHist(gray)
#元のminsizeは24x24だが、128でやるなら50x50は最低必要
faces = cascade.detectMultiScale(gray,
# detector options
scaleFactor = 1.1,
minNeighbors = 5,
minSize = (50, 50))
#顔の切り取り
for i, (x,y,w,h) in enumerate(faces):
# 一人ずつ顔を切り抜く
face_image = image[y:y+h, x:x+w]
output_path = os.path.join(face_output_dir, '{0}-{1}.jpg'.format(num,i))
#print(output_path)
#output_path = os.path.join(output_dir,'{0}.jpg'.format(i))
cv2.imwrite(output_path,face_image)
#赤枠で囲った画像の保存
#上のfor内でやると、赤線がカットされた画像に映り込む
for i, (x,y,w,h) in enumerate(faces):
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 2)
cv2.imwrite(paint_output_dir + str(num) + ".jpg", image)
#asciiのみ
face_output_dir = "./cut_images/"
paint_output_dir = "./painted_images/"
img_source = "./colar_source/*"
files = glob.glob(img_source)
for num, filename in enumerate(files):
print(filename)
detect(filename, num)
face_output_dirには切り抜いた画像が入ります
paint_output_dirには切り抜いた部分が赤く囲われた画像が入ります
img_sourceには切り取りたい画像があるフォルダパス + /* とすることで、フォルダ内の画像すべてを指定できます。
どれも半角文字のみ対応しています。
全角文字に対応したいならこの記事を参考にしてください。
事前準備
こちらからlbpcascade_animeface.xmlをダウンロードしてプログラムと同じフォルダにおいてください。
コードを実行すると切り取られた画像と切り取った部分を赤い枠で囲った画像が出力されます。
切り取り時の変数
なお、切り取る時の変数は公式ですと以下のようになっています。
具体的に解説した記事には以下のものがあります。
今回はmin_sizeのみ変えて使用しました。
その他の方法
また、このように新しい方法もあるみたいですあります
しかしpytorchを使ったことがないので今回は使用しませんでした。
4.手動顔切り取り
なお、切り取り切れていない顔も存在するので、以下の記事を参考にguiで顔を切り取れるプログラムも作成しました。
今回は見落としはあるかもしれませんが、十分データが集まったので使いませんでした。
出来上がったものがこちらです
5.リサイズ
集まった顔は顔以外がまざっているのでそれらを主導で除去したのち、128x128にリサイズします。
学習中にやってもいいのですが、学習データを小さくするためにも、今回は先にリサイズしておきます。
import cv2
import sys
import os.path
from time import sleep
import glob
import os
#ファイルネームをもとのに一致。マルチ用
def resizer(filename):
print(filename)
image = cv2.imread(filename , cv2.IMREAD_COLOR)
#ここの第二変数でリサイズ後のサイズを指定
resize_image = cv2.resize(image,(128,128),interpolation = cv2.INTER_AREA)
output_path = os.path.join(resized_output_dir, os.path.splitext(os.path.basename(filename))[0]+"_128.jpg")
cv2.imwrite(output_path, resize_image)
resized_output_dir = "./128resized_images/"
img_source = "./cut_images/*"
files = glob.glob(img_source)
#普通の実行
for filename in files:
print(filename)
resizer(filename)
#sleep(1)
"""
#マルチスレッド版
from multiprocessing import Pool
if __name__ == '__main__':
p = Pool()
p.map(resizer, files)
"""
resized_output_dirには保存先を
img_sourceには切り取りたい画像があるフォルダパス + /* とすることで、フォルダ内の画像すべてを指定できます。
どれも半角文字のみ対応しています。
128*128以外のサイズにリサイズしたいときはcv2.resize()の第二変数でサイズを指定してください
左右反転して学習データの水増し
顔は大体右か左を向いているので、左右反転させた画像も作成することでデータを増やすことができます。
回転させたり動かす方法もありますが、端の問題がありますので、今回はやりません。
先ほどのリサイズと同じようなコードです。
import cv2
import sys
import os.path
from time import sleep
import glob
import os
def resizer_and_generator(filename):
image = cv2.imread(filename , cv2.IMREAD_COLOR)
resize_image = cv2.resize(image,(128,128),interpolation = cv2.INTER_AREA)
output_path = os.path.join(resized_output_dir, os.path.splitext(os.path.basename(filename))[0]+"_128.jpg")
cv2.imwrite(output_path, resize_image)
swapped_image = cv2.flip(resize_image, 1)
output_path2 = os.path.join(resized_output_dir, os.path.splitext(os.path.basename(filename))[0]+"_128_2.jpg")
cv2.imwrite(output_path2, swapped_image)
resized_output_dir = "./128resized_images/"
img_source = "./cut_images/*"
files = glob.glob(img_source)
#普通の実行
for filename in files:
print(filename)
resizer_and_generator(filename)
#sleep(1)
"""
#マルチスレッド
from multiprocessing import Pool
if __name__ == '__main__':
p = Pool()
p.map(resizer_and_generator, files)
"""
6.データセットの作成
画像を全て読み込み、numpyのarrayに変換して保存します。
いちいち画像を一枚ずつ読み込むと遅くなってしまうのです。
ローカルでやるなら問題はありませんが。
こちらが参考にしたサイトです
なおkerasをしようしています。
動作環境ではkeras2.3.1です(tensorflow1.x用)
import matplotlib.pyplot as plt
import sys
from keras.preprocessing.image import array_to_img,img_to_array,load_img
import numpy as np
import os
import glob
X_train=[]
Y_train=[]
X_test=[]
Y_test=[]
files = glob.glob("./128resized_images/*", recursive=True)
n=0
for image in files:
temp_img=load_img(image)
temp_img_array=img_to_array(temp_img)
print(temp_img_array.shape)
X_train.append(temp_img_array)
n=n+1
np.savez("./gan.npz",x_train=X_train,y_train=Y_train,x_test=X_test,y_test=Y_test)
filesには画像があるフォルダを指定してください。
なおデータの作成時にメモリにすべて載せて保存するので、メモリが必要になってきます。
今回、カラーの128*128を約3500枚データセットにしたところ659MBになりました。
実行するとgan.npzというファイルが出力されます(もっとましな名前はなかったのか...)
学習
これらを参考にしました。
こちらを参考に色々変えてみました。
googlecolab上でも実行したのですが、記事を書くころには忘れてしまったのでローカルでのやり方を書きます。
といってもこれも色々忘れているので、少々間違いがあるかも。
from keras.models import Sequential
from keras.layers import Dense, Conv2DTranspose, Dropout
from keras.layers import Reshape, GlobalAveragePooling2D, GlobalMaxPooling2D
from keras.layers.core import Activation
from keras.layers.normalization import BatchNormalization
#from keras.layers.convolutional import UpSampling2D
from keras.layers.convolutional import Conv2D, MaxPooling2D, AveragePooling2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.core import Flatten
from keras.optimizers import Adam
import numpy as np
from PIL import Image
import os
import glob
import random
import argparse
#import cv2
import matplotlib.pyplot as plt
from keras.preprocessing.image import array_to_img,img_to_array,load_img
#from keras.applications.vgg16 import VGG16
#from keras.layers import Input
#from keras.layers.core import Dropout
#from keras.models import Model
n_colors = 3
def generator_model5():
model = Sequential()
model.add(Dense(8*8*128, input_shape=(100,))) #1024,100 10
model.add(Activation('relu'))
model.add(Reshape((8, 8, 128)))
model.add(Conv2DTranspose(128, (5, 5), strides=2, padding='same'))
model.add(Activation('relu'))
model.add(Conv2DTranspose(64, (5, 5), strides=2, padding='same'))
model.add(Activation('relu'))
model.add(Conv2DTranspose(32, (5, 5), strides=2, padding='same'))
model.add(Activation('relu'))
model.add(Conv2DTranspose(n_colors,(5, 5), activation='tanh', strides=2, padding='same'))
return model
def discriminator_model7():
model = Sequential()
model.add(Conv2D(16, (5, 5), input_shape=(128, 128, n_colors), padding='same'))
model.add(LeakyReLU(alpha=0.2))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (5, 5), padding='same'))
model.add(LeakyReLU(alpha=0.2))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (5, 5), padding='same'))
model.add(LeakyReLU(alpha=0.2))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, (5, 5), padding='same'))
model.add(LeakyReLU(alpha=0.2))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(256, (5, 5), padding='same'))
model.add(LeakyReLU(alpha=0.2))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(GlobalAveragePooling2D())
model.add(Dense(128))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(1))
model.add(Activation('sigmoid'))
return model
def generator_containing_discriminator(generator, discriminator):
model = Sequential()
model.add(generator)
#discriminator.trainable = False
model.add(discriminator)
return model
def combine_images(generated_images, cols=5, rows=5):
shape = generated_images.shape
h = shape[1]
w = shape[2]
image = np.zeros((rows * h, cols * w, n_colors))
for index, img in enumerate(generated_images):
if index >= cols * rows:
break
i = index // cols
j = index % cols
image[i*h:(i+1)*h, j*w:(j+1)*w, :] = img[:, :, :]
image = image * 127.5 + 127.5
image = Image.fromarray(image.astype(np.uint8))
return image
#自分で作りました
def combine_and_make_gif(generated_images, filename, dir_name="./gen_unique", duration=1000/15):
from time import sleep
from PIL import Image
import os, glob
import sys
import cv2
shape = generated_images.shape
h = shape[1]
w = shape[2]
ims = []
for image in generated_images:
image = image * 127.5 + 127.5
image = Image.fromarray(image.astype(np.uint8))
ims.append(image)
#10, 15, 20がいい
duration = 1000/15
ims[0].save(f'{dir_name}/{filename}.gif', save_all=True, append_images=ims[1:],
optimize=False, duration=duration, loop=0)
print(f'{dir_name}/{filename}.gif')
#自分で作りました
def make_gif(img100, filename, dir_name="./gen_unique", duration=1000/15):
from time import sleep
from PIL import Image
import os, glob
import sys
import cv2
import numpy
#10, 15, 20がいい
duration = 1000/15
img100[0].save(f'{dir_name}/{filename}.gif', save_all=True, append_images=img100[1:],
optimize=False, duration=duration, loop=0)
print(f'{dir_name}/{filename}.gif')
#動画の作成
#https://daeudaeu.com/pil_cv2_tkinter/#PIL_OpenCV2
#pil>cv2に変換しないと
#パラメーター
fps = 1000 / duration
height = 1280
width = 1280
# encoder(for mp4)
fourcc = cv2.VideoWriter_fourcc('m', 'p', '4', 'v')
# output file name, encoder, fps, size(fit to image size)
video = cv2.VideoWriter(f'{dir_name}/{filename}.mp4',fourcc, fps, (width, height))
for img in img100:
pil_image_array = numpy.array(img)
# RGB -> BGR によりCV2画像オブジェクトに変換
cv2_image = cv2.cvtColor(pil_image_array, cv2.COLOR_RGB2BGR)
video.write(cv2_image)
video.release()
print('written')
def set_trainable(model, trainable):
model.trainable = trainable
for layer in model.layers:
layer.trainable = trainable
#saveした重みをロードできるようにした
def main(BATCH_SIZE=55, ite=1000, savenum=0):
batch_size = BATCH_SIZE
ite=ite
savenum = savenum
discriminator = discriminator_model7()
generator = generator_model5()
discriminator_on_generator = generator_containing_discriminator(generator, discriminator)
set_trainable(discriminator, False)
opt =Adam(lr=0.0001, beta_1=0.5)
discriminator_on_generator.compile(loss='binary_crossentropy', optimizer=opt)
print('generator.summary()---')
generator.summary()
print('discriminator_on_generator.summary()---')
discriminator_on_generator.summary()
set_trainable(discriminator, True)
discriminator.compile(loss='binary_crossentropy', optimizer=opt)
print('discriminator.summary()---')
discriminator.summary()
if savenum != 0:
generator.load_weights('./gen_images/generator_%d.h5' % savenum, by_name=True)
discriminator.load_weights('./gen_images/discriminator_%d.h5' % savenum, by_name=True)
f=np.load("./gan.npz")
X_train=f["x_train"]
# Rescale -1 to 1
print(X_train.shape)
X_train = X_train / 127.5 - 1.
for i in range(savenum,31 * 10000):
print(i)
idx = np.random.randint(0, X_train.shape[0], batch_size)
batch_images = X_train[idx]
noise = np.random.uniform(size=[batch_size, 100], low=-1.0, high=1.0) #32*32 10
generated_images = generator.predict(noise)
X = np.concatenate((batch_images, generated_images))
y = [1] * batch_size + [0] * batch_size
d_loss = discriminator.train_on_batch(X, y)
noise = np.random.uniform(size=[batch_size, 100], low=-1.0, high=1.0) ##32*32
g_loss = discriminator_on_generator.train_on_batch(noise, [1] * batch_size)
#ここの数値で画像生成頻度が変わるね
#if i % 10 == 0:
if i % (ite//10) == 0:
print("step %d d_loss, g_loss : %g %g" % (i, d_loss, g_loss))
image = combine_images(generated_images)
#os.system('mkdir -p ./gen_images')
os.makedirs(os.path.join(".", "gen_images"), exist_ok=True)
image.save("./gen_images/gen%05d.png" % i)
if i % ite == 0:
generator.save_weights('./gen_images/generator_%d.h5' % i, True)
discriminator.save_weights('./gen_images/discriminator_%d.h5' % i, True)
#100x100のgifを作る
def generate(BATCH_SIZE=55, ite=10000, nice=False):
z=100
g = generator_model5()
g.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5))
g.load_weights('./gen_images/generator_%d.h5'%ite)
if nice:
d = discriminator_model3()
d.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5)) #optimizer="SGD"
d.load_weights('./gen_images/discriminator_%d.h5'%ite)
#noise dimention!!
noise = np.random.uniform(-1, 1, (BATCH_SIZE*20, 100)) ##32*32
generated_images = g.predict(noise, verbose=1)
d_pret = d.predict(generated_images, verbose=1)
index = np.arange(0, BATCH_SIZE*20)
index.resize((BATCH_SIZE*20, 1))
pre_with_index = list(np.append(d_pret, index, axis=1))
pre_with_index.sort(key=lambda x: x[0], reverse=True)
nice_images = np.zeros((BATCH_SIZE,) + generated_images.shape[1:3], dtype=np.float32)
nice_images = nice_images[:, :, :, None]
for i in range(BATCH_SIZE):
idx = int(pre_with_index[i][1])
nice_images[i, :, :, 0] = generated_images[idx, :, :, 0]
image = combine_images(nice_images)
else:
img100=[]
noise = np.random.uniform(size=[z, z], low=-1.0, high=1.0) ##32*32 10x10
#全て同じノイズを使用する
for line in range(z):
noise[line] = noise[0]
for j in range(BATCH_SIZE):
#このi:100は特徴量の数
for i in range(z):
#noise[j][i]=-1+j*2/BATCH_SIZE
noise[i][i]=-100+(j*200)/BATCH_SIZE
generated_images = g.predict(noise)
image = combine_images(generated_images, cols=10, rows=10)
#print("この画像のタイプは")
#print(type(image))
img100.append(image)
print(j)
filename = ("generate100_%05d" % ite)
make_gif(img100, filename, dir_name="./gen_unique", duration=100)
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--mode", type=str)
parser.add_argument("--batch_size", type=int, default=512)
parser.add_argument("--iteration", type=int, default=100)
parser.add_argument("--savenum", type=int, default=0)
parser.add_argument("--nice", dest="nice", action="store_true")
parser.set_defaults(nice=False)
args = parser.parse_args()
return args
#savenumを追加
if __name__ == "__main__":
args = get_args()
if args.mode == "train":
main(BATCH_SIZE=args.batch_size,ite=args.iteration, savenum=args.savenum)
elif args.mode == "generate":
generate(BATCH_SIZE=args.batch_size,ite=args.iteration, nice=args.nice)
実行前に、gen_imagesとgen_uniqueというフォルダをプログラムのあるディレクトリに作ってください。
gen_imagesは学習時に、gen_uniqueは生成時に使用します。
このプログラムは、学習と生成の二つのモードがあります。
学習時は、
python keras-dcgan_datasetver_100.py --mode train --batch_size 512 --iteration 100 --savenum 200
と実行してください。
この時、
batch_sizeはGPUのメモリが許す限り大きくすると学習が早く進むそうです
iterationはその数値ごとに厚みの保存を、その1/10の頻度で画像を生成します。
savenumは初回は0、その後は使用したい厚みの番号を入力してください。
元のプログラムと違ってっこのプログラムはセーブ&ロード機能があるので、まとまった時間が取れなくても実行できます。
というかなんでみんなこういう機能つけないんだろうね。
生成時は、
python keras-dcgan_datasetver_100.py --mode generate --batch_size 100 --iteration 200
と実行してください。
実行すると入力ノイズを変えた際のgifとmp4が出力されます。
といってもノイズのいじり方はおそらく間違っています。
画像だけを生成する方法は忘れました。
すみません。
画像を生成したい場合は元のプログラムを見てください。
ここで、私が適当にプログラムを作ったので以下に注意してください。
iterationは使用する厚みの番号を使用してください。
batch_sizeは生成する画像の枚数を指定しますが、生成gifが10*10に画像を並べたものなので、100を超えると使用されません。100未満だと真っ白な部分ができます。
100をお勧めします。
なお、生成した画像がイテレーション数とともにどう変わってきたかをgifにしたいときは
from time import sleep
from PIL import Image
import os, glob
import sys
import cv2
dir_name= "./gen_images"
#10, 15, 20がいい
ugoira_delay = 1000/15
illust_id = 0000
#保存した画像をもとにgifを作成
frames = glob.glob(f'{dir_name}/*.png')
frames.sort(key=os.path.getmtime, reverse=False)
ims = []
for frame in frames:
ims.append(Image.open(frame))
ims[0].save(f'{dir_name}/{illust_id}.gif', save_all=True, append_images=ims[1:], optimize=False, duration=ugoira_delay, loop=0)
print(f'{dir_name}/{illust_id}.gif')
#動画の作成
frames = glob.glob(f'{dir_name}/*.png')
frames.sort(key=os.path.getmtime, reverse=False)
#パラメーター
fps = 1000 / ugoira_delay
height = 640
width = 640
# encoder(for mp4)
fourcc = cv2.VideoWriter_fourcc('m', 'p', '4', 'v')
# output file name, encoder, fps, size(fit to image size)
video = cv2.VideoWriter(f'{dir_name}/{illust_id}.mp4',fourcc, fps, (width, height))
for frame in frames:
img = cv2.imread(frame)
video.write(img)
video.release()
print('written')
これがおそらく動きます。
仕組みは、gen_images内の画像を順番につなげているだけです。
アレンジ
活性化関数
このサイトでは、活性化関数はTanhがよさそうです。
バッチノーマライゼーション
これらのサイトによるとバッチノーマライゼーションは畳み込みと活性化関数の間に置くといいそうです。
実際generatorでそのように変更すると、ノイズから画像に変わるまでのエポックが早くなり、学習が早くなりました。
ここにあるように、
DCGANではbatch normalizationをgeneratorとdiscriminatorの両方に適用します。但し、全ての層に適用すると不安定になってしまうようで、generatorの出力層と、discriminatorの入力層には適用しないようにします。
実際に無くした方が良くなりました。
また、discriminatorにバッチノーマライゼーションを入れると全然生成されなくなりました。
これは間違いと本物の画像をまとめて正規化するのは良くないとのことです。
また、実はbatch normalizationが入っていません。生成画像と本物の画像を同じバッチに入れているのがよくなさそうなので分けてみるなど、色々と試してみたのですがこちらの記事にもあるようにどうもうまくいきませんでした。(一応動くことには動くのですが、クオリティが落ちてしまいました。)
こちらの記事によると、discriminatorにbatch normalizationを入れるとdiscriminatorが強くなりすぎてうまくいかない場合があるとのことなので、そういうことなのかもしれません。他のKerasでの実装例を見ても、discriminatorにはbatch normalizationが入っていないものがほとんどです。ここではこれ以上は深堀らないでおくことにします。
プーリング
poolingをmaxpoolingからaveragepoolingにかえてみた
画像がぼやけてしまうので却下
全結合
これらのサイトによると、全結合をGlobal Average Poolingに変えることで
精度を維持したままパラメータの数を減らすことができるようです。
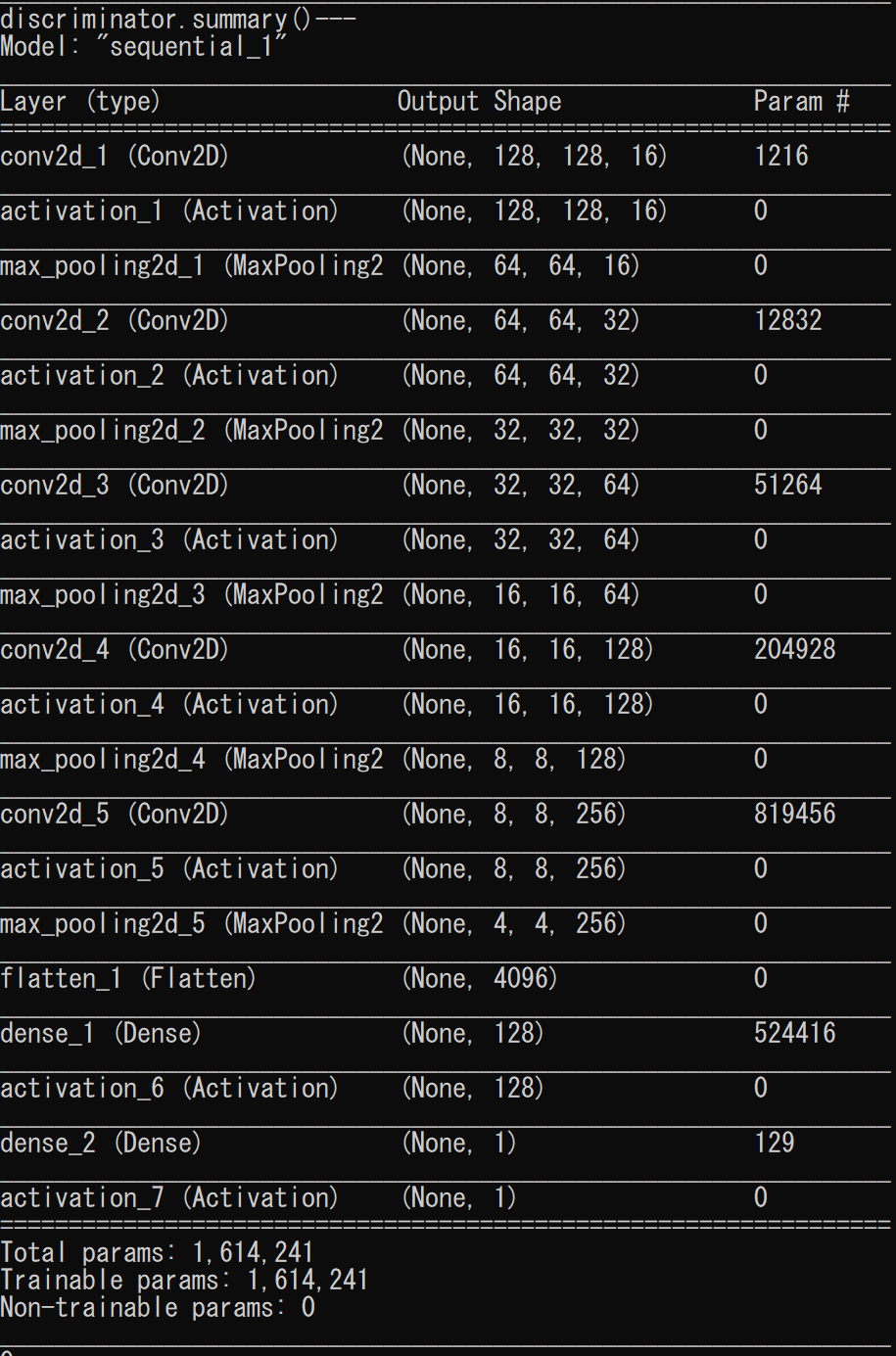
flattenがこちら
そしてGlobal Average Poolingがこちら
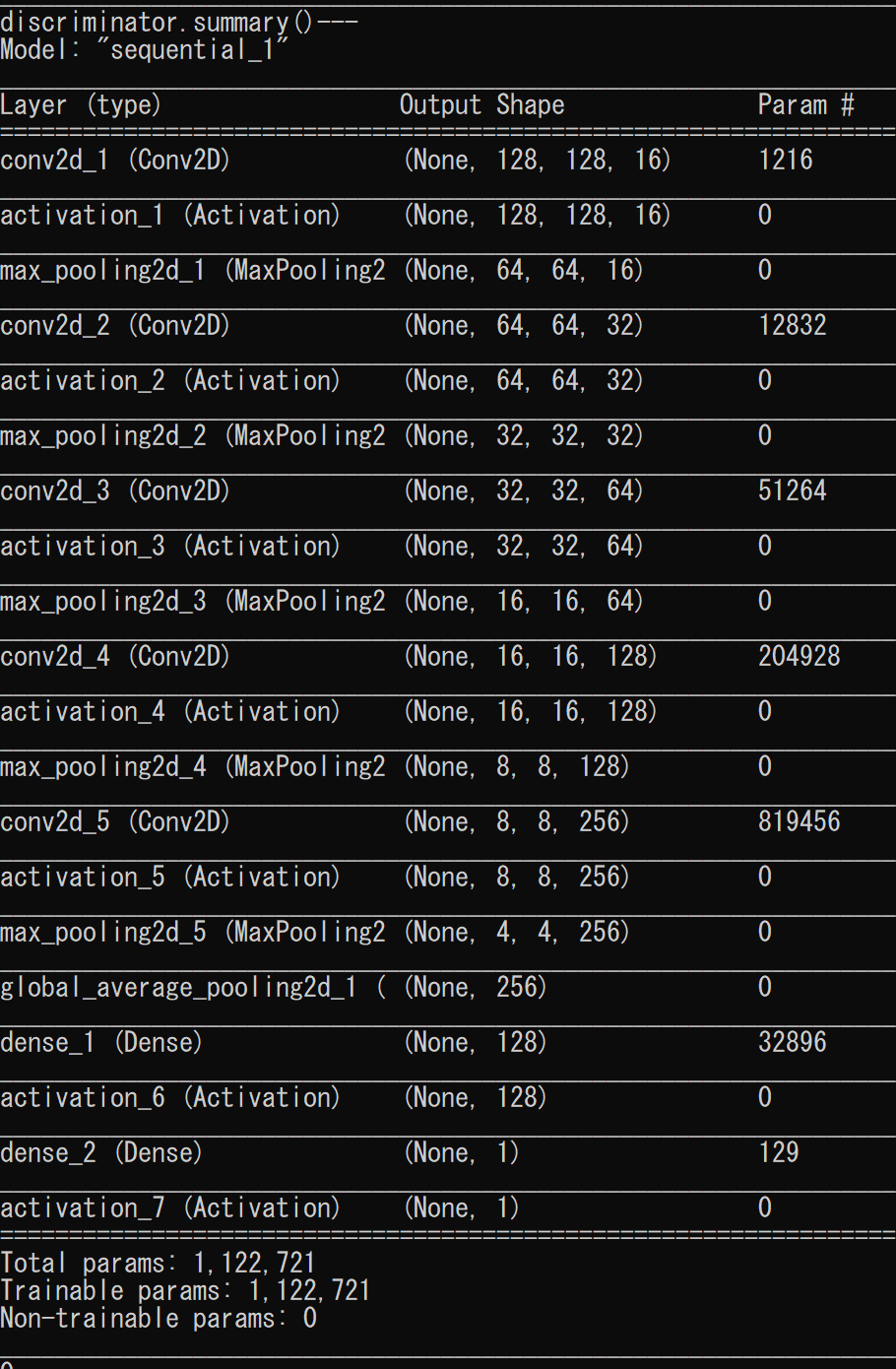
discriminatorのパラメータの数が2/3になりました。
画像生成にはあまり影響はありませんでした。
画像はまあまあ甲乙つけがたい
まとめ
いつか記事にしようといろいろ考えていたら何か月も過ぎ、結構内容をわすれていました。
なので画像も全然ありません。
データセット作成までの内容は結構しっかりしているので是非参考にしてください。
学習については試行錯誤していたのでどれが最新のプログラムかわからなくなってしまって正直適当です。
すみません。
またほかのganについても試してみようと思うので、その時は記事を書きながらやってみます。
これを試そうと思っています。