はじめに
今回は以下の記事の続きです。
本プログラムは飛行機をSACにより連続値制御で操縦することを目指したプログラムです。
飛行のモデリングは『航空機力学入門 (加藤寛一郎・大屋昭男・柄沢研治 著 東京大学出版会)』の3章「微小擾乱の運動方程式」をベースに作成しています。
そしてSACの実装は東京大学松尾研究室の「サマースクール2024 深層強化学習」をベースにしております。
水平旋回を目指して学習させた結果が以下です。

プログラムはgooglecolabで実行できるように公開しています。
準備
# 必要なライブラリのインポート.
import os
import glob
from collections import deque
from datetime import timedelta
import pickle
from base64 import b64encode
import math
import numpy as np
import torch
from torch import nn
from torch.distributions import Normal
import torch.nn.functional as F
import gym
import matplotlib.pyplot as plt
from IPython.display import HTML
# Gymの警告を一部無視する.
gym.logger.set_level(40)
# matplotlibをColab上で描画するためのコマンド.
%matplotlib inline
フライトシミュレータ環境
import numpy as np
from scipy.integrate import odeint, solve_ivp
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import time
import mpl_toolkits.mplot3d.art3d as art3d
from IPython.display import HTML
import matplotlib.animation as animation
from tqdm.notebook import tqdm
# --- 回転行列の定義 ---
def rotation_matrix(psi, theta, phi):
# z軸周り回転
R_z = np.array([[np.cos(psi), -np.sin(psi), 0],
[np.sin(psi), np.cos(psi), 0],
[0, 0, 1]])
# y軸周り回転
R_y = np.array([[np.cos(theta), 0, np.sin(theta)],
[0, 1, 0],
[-np.sin(theta), 0, np.cos(theta)]])
# x軸周り回転
R_x = np.array([[1, 0, 0],
[0, np.cos(phi), -np.sin(phi)],
[0, np.sin(phi), np.cos(phi)]])
# 全体の回転行列
R = R_z @ R_y @ R_x
return R
#全体座標系における速度ベクトルの取得
def get_global_velosity(U0, u, alpha, beta, psi, theta, phi):
# 機体座標系での速度ベクトル
u_b = U0 + u
v_b = u_b * np.sin(beta)
w_b = u_b * np.tan(alpha)
vel_b = np.array([u_b, v_b, w_b])
# 全体座標系での速度ベクトル
vel_e = rotation_matrix(psi, theta, phi) @ np.atleast_2d(vel_b).T
vel_e = vel_e.flatten()
return vel_e
#紙飛行機の描写関数
def plot_paper_airplane(x, y, z, phi, theta, psi, scale, ax):
"""
3次元座標と角度が与えられたとき、その状態の紙飛行機のような図形をプロットする
Args:
x: x座標
y: y座標
z: z座標
psi: ロール角 (ラジアン)
theta : ピッチ角 (ラジアン)
phi: ヨー角 (ラジアン)
機体の大きさをいじりたければscaleを変える
"""
#三角形を描く
poly_left_wing = scale * np.array([[2, 0.0, 0],
[-1, 1, 0],
[-1, 0.1, 0]])
poly_right_wing = poly_left_wing.copy()
poly_right_wing[:,1] = -1 * poly_right_wing[:,1]
poly_left_body = scale * np.array([[2, 0.0, 0.0],
[-1, 0.0, +0.1],
[-1, 0.1, 0.0]])
poly_right_body = poly_left_body.copy()
poly_right_body[:,1] = -1 * poly_right_body[:,1]
R = rotation_matrix(psi, theta, phi) # yaw, pitch, roll
for points in [poly_left_wing, poly_left_body, ]:
# 紙飛行機の点を回転
translated_rotated_points = (R @ points.T).T + np.array([x, y, z])
#描写
ax.add_collection3d(art3d.Poly3DCollection([translated_rotated_points],facecolors='orangered', linewidths=1, edgecolors='k', alpha=0.6))
for points in [poly_right_wing, poly_right_body]:
# 紙飛行機の点を回転
translated_rotated_points = (R @ points.T).T + np.array([x, y, z])
#描写
ax.add_collection3d(art3d.Poly3DCollection([translated_rotated_points],facecolors='lime', linewidths=1, edgecolors='k', alpha=0.6))
変更点
前回のプログラムからの変更点です
- 連続値制御に伴い、actionの範囲を[-1, 1]に変更し、またactionの数を4つに変更
- infoをgym形式に合わせ辞書形式に変更
- 環境についてidを登録し使用するよう変更
- 時間増分dtを0.2に変更しより細かい時間幅に変更
- observartionに状態量とその微分を渡すようにし、明示的に入れていた速度を削除
- max_episode_stepsの計算を修正
- 終了条件を修正
- 報酬の与え方を修正(45°ごとに旋回完了したら時間の短さに応じて報酬)
Copilotによる報酬の与え方のアドバイス
強化学習で目標をできるだけ早く達成するためには、報酬の設定が非常に重要です。以下のポイントを考慮すると良いでしょう:
- 即時報酬: 目標に近づく行動に対して即時に報酬を与えることで、エージェントがその行動を強化します。
- 負の報酬: 目標から遠ざかる行動や無駄な行動に対して負の報酬(ペナルティ)を与えることで、エージェントがその行動を避けるようにします。
- 時間に基づく報酬: 目標を達成するまでの時間に基づいて報酬を設定します。例えば、目標を早く達成するほど高い報酬を与えるようにします。
- 段階的報酬: 目標に向かう途中の小さなステップやサブゴールに対しても報酬を設定し、エージェントが段階的に学習できるようにします。
これらのポイントを組み合わせることで、エージェントが効率的に学習し、目標を早く達成することが期待できます。具体的なタスクや環境に応じて報酬の設定を調整することも重要です。
import gym
class FlightSimulatorEnv(gym.Env):
metadata = {'render.modes': ['rgb_array']}
# --- 機体パラメータ ---
g = 9.81
# 初期条件
U0 = 293.8
W0 = 0
theta0 = 0.0
# 縦の有次元安定微係数: ロッキードP2V-7
Xu = -0.0215
Zu = -0.227
Mu = 0
Xa = 14.7
Za = -236
Ma = -3.78
Madot = -0.28
Xq = 0
Zq = -5.76
Mq = -0.992
X_deltat = 1.0 #10sで10m/s加速か #0.01 #0
Z_deltae = -12.9
Z_deltat = 0
M_deltae = -2.48
M_deltat = 0
# 横・方向の有次元安定微係数: ロッキードP2V-7
Yb=-45.4
Lb=-1.71
Nb=0.986
Yp=0.716
Lp=-0.962
Np=-0.0632
Yr=2.66
Lr=0.271
Nr=-0.215
#Y_deltaa=0
L_deltaa=1.72
N_deltaa=-0.0436
Y_deltar=9.17
L_deltar=0.244
N_deltar=-0.666
# --- 縦の運動方程式 ---
# 行列A, Bの定義
A_long = np.array([[Xu, Xa, -W0, -g * np.cos(theta0)],
[Zu / U0, Za / U0, 1 + Zq / U0, (g / U0) * np.sin(theta0)],
[Mu + Madot * (Zu / U0), Ma + Madot * (Za / U0), Mq + Madot * (1 + Zq / U0),
(Madot * g / U0) * np.sin(theta0)],
[0, 0, 1, 0]])
B_long = np.array([[0, X_deltat],
[Z_deltae / U0, Z_deltat / U0],
[M_deltae + Madot * (Z_deltae / U0), M_deltat + Madot * (Z_deltat / U0)],
[0, 0]])
# --- 横・方向の運動方程式 ---
# 行列A, Bの定義
A_lat = np.array([[Yb / U0, (W0 + Yp) / U0, (Yr / U0 - 1), g * np.cos(theta0) / U0, 0],
[Lb, Lp, Lr, 0, 0],
[Nb, Np, Nr, 0, 0],
[0, 1, np.tan(theta0), 0, 0],
[0, 0, 1 / np.cos(theta0), 0, 0]])
B_lat = np.array([[0, Y_deltar / U0],
[L_deltaa, L_deltar],
[N_deltaa, N_deltar],
[0, 0],
[0, 0]])
# --- 統合モデル ---
def aircraft_dynamics(self, t, x, U0, A_long, B_long, A_lat, B_lat, u_inp):
u_long = u_inp[:2]
u_lat = u_inp[2:]
# 縦の運動方程式
dxdt_long = A_long @ np.atleast_2d(x[:4]).T + B_long @ np.atleast_2d(u_long).T
dxdt_long = dxdt_long.flatten()
# 横・方向の運動方程式
dxdt_lat = A_lat @ np.atleast_2d(x[4:9]).T + B_lat @ np.atleast_2d(u_lat).T
dxdt_lat = dxdt_lat.flatten()
# 機体座標系から全体座標系での速度ベクトルへの変換
vel_e = get_global_velosity(U0=U0, u=x[0], alpha=x[1], beta=x[4], psi=x[8], theta=x[3], phi=x[7])
# 縦と横・方向の状態量の変化と位置の変化を結合
dxdt = np.concatenate((dxdt_long, dxdt_lat, vel_e))
return dxdt
def __init__(self):
self.dt = 0.2 #[s]
self.max_episode_time = 100 #[s]
self.max_episode_steps = int(self.max_episode_time/self.dt)
self.action_space = gym.spaces.Box(low=-1, high=1, shape=(4,), dtype=np.float32)
self.observation_space = gym.spaces.Box(low=-np.inf, high=np.inf, shape=(24,), dtype=np.float32) #self.observation_space.shape で使うので注意
self.reward_range = (-np.inf, np.inf)
self.reset()
def reset(self):
self.x = np.zeros(self.observation_space.shape[0]//2)
self.t = 0
self.observation = np.zeros(self.observation_space.shape)
self.once_reward_flags = [False, False, False, False]
self.done = False
self.all_soly = self.x.reshape(len(self.x),1)
return self.observation
def step(self, action):
start_time = time.time()
#tanhでactionが出てくるので(-1, 1)
self.u_inp = np.array(action)
# t~t+dtまで微分方程式を解く (RK45メソッドを使用)
sol = solve_ivp(self.aircraft_dynamics, [self.t, self.t+self.dt], self.x,
args=(self.U0, self.A_long, self.B_long, self.A_lat, self.B_lat, self.u_inp),
method='RK45')
#t~t+dtまでの結果を追加
self.all_soly = np.append(self.all_soly, sol.y, axis=1)
#次のt+dtにおける初期条件
self.x = sol.y[:, -1] #現在の最終状態
self.t += self.dt
#状態量の微分値
self.dxdt = self.aircraft_dynamics(self.t, self.x, self.U0, self.A_long, self.B_long, self.A_lat, self.B_lat, self.u_inp)
#状態量(積分値12 微分値12)
self.observation = np.concatenate((self.x, self.dxdt))
# --- 報酬の設定 ---
self.rewards = np.array([])
# --- 時間に応じた報酬の設定 ---
#短時間で達成できるようにしたい
self.rewards = np.append(self.rewards, 0) #時間に応じて減額
#高度を変えないでほしい 1000ftで-1
self.rewards = np.append(self.rewards, -1 * abs(self.x[11])/10**3)
#バンク角が大きすぎないでほしい
if abs(self.x[7])%(2*np.pi) > np.pi /4:
self.rewards = np.append(self.rewards, 0)#-1 * (abs(self.x[7])%(2*np.pi) - np.pi/4))
else:
self.rewards = np.append(self.rewards, 0)
#180°旋回することを目的とする
target_vecor = np.array([-1, 0, 0])
#target_vecor = np.array([0, -1, 0])
#速度ベクトルと目標ベクトルのコサイン類似度で報酬
vel_e = self.observation[21:24]
cosine_similarity = np.dot(target_vecor, vel_e)/(np.sqrt(np.dot(target_vecor, target_vecor))*np.sqrt(np.dot(vel_e, vel_e)))
self.rewards = np.append(self.rewards, cosine_similarity-1) #[-1,1]のままだとずっと後ろに進んでいれば報酬が増え続けるので[-2,0]にする。
#時間幅に依存しないようにしたい
self.rewards *= self.dt
# --- 一度だけの報酬の設定 ---
#途中経過
#45°旋回完了
if cosine_similarity > -0.7 and self.once_reward_flags[0]==False:
self.rewards = np.append(self.rewards, 10/self.t) #1* self.max_episode_time / self.t)
self.once_reward_flags[0] = True
#90°旋回完了
elif cosine_similarity > 0.0 and self.once_reward_flags[1]==False:
self.rewards = np.append(self.rewards, 10/self.t) #1* self.max_episode_time / self.t)
self.once_reward_flags[1] = True
#135°旋回完了
elif cosine_similarity > 0.7 and self.once_reward_flags[2]==False:
self.rewards = np.append(self.rewards, 20/self.t) #1* self.max_episode_time / self.t)
self.once_reward_flags[2] = True
#180°旋回完了
elif cosine_similarity > 0.95 and self.once_reward_flags[3]==False:
self.rewards = np.append(self.rewards, 20/self.t) #1* self.max_episode_time / self.t)
self.once_reward_flags[3] = True
else:
self.rewards = np.append(self.rewards, 0)
# --- 終了判定 ---
#ほぼ目標を向いたら終了
#if cosine_similarity > 0.95:
#ほぼ目標を向いて高度が0になったら終了
if cosine_similarity > 0.95 and abs(self.x[11]) < 100:
self.done = True
self.rewards = np.append(self.rewards, 100 /self.t) #* self.max_episode_time / self.t)
else:
self.rewards = np.append(self.rewards, 0)
# --- ゲームオーバー判定 ---
if self.t >= self.max_episode_time:
self.done = True
self.rewards = np.append(self.rewards, -1)
else:
self.rewards = np.append(self.rewards, 0)
#報酬の合計
self.reward = np.sum(self.rewards)
#info
elapsed_time = time.time() - start_time
self.info = {'elapsed_time': elapsed_time,
"rewards": self.rewards}
#print(self.t, self.done, self.reward)
#print(self.info)
return self.observation, self.reward, self.done, self.info
def render(self, mode='rgb_array'):
if mode == 'rgb_array':
plt.ion()
fig, axes = plt.subplots(2, 2, figsize=(2*6.4, 2*4.8), dpi=72, tight_layout=True, subplot_kw=dict(projection='3d'))
for i in range(2):
for j in range(2):
ax = axes[i,j]
#fig.add_axes(ax)
ax.invert_zaxis()
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
ax.set_xlim(0, 500)
ax.set_ylim(-250, 250)
ax.set_zlim(100, -100)
# 軌跡
ax.plot(self.all_soly[9], self.all_soly[10], self.all_soly[11])
ax.set_xlim(min(min(self.all_soly[9]),0), max(max(self.all_soly[9]), 500),)
ax.set_ylim(min(min(self.all_soly[10]),-250), max(max(self.all_soly[10]), 250),)
ax.set_zlim(max(max(self.all_soly[11]), 100),min(min(self.all_soly[11]),-100))
#紙飛行機
plot_paper_airplane(x=self.x[9], y=self.x[10], z=self.x[11], phi=self.x[7], theta=self.x[3], psi=self.x[8], scale=100, ax=ax)
axes[0,0].view_init(elev=90, azim=-90)
axes[1,0].view_init(elev=0, azim=-90)
axes[1,1].view_init(elev=0, azim=0)
# 描画をキャンバスに保存
fig.canvas.draw()
# キャンバスからRGBデータを取得
image = np.frombuffer(fig.canvas.tostring_rgb(), dtype=np.uint8)
image = image.reshape(fig.canvas.get_width_height()[::-1] + (3,))
#メモリ開放
plt.clf()
plt.close()
return image
def render_old(self, mode='rgb_array'):
if mode == 'rgb_array':
plt.ion()
fig = plt.figure(dpi=100)
ax = Axes3D(fig)
fig.add_axes(ax)
ax.invert_zaxis()
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
ax.set_xlim(0, 500)
ax.set_ylim(-250, 250)
ax.set_zlim(100, -100)
# 軌跡
ax.plot(self.all_soly[9], self.all_soly[10], self.all_soly[11])
ax.set_xlim(min(min(self.all_soly[9]),0), max(max(self.all_soly[9]), 500),)
ax.set_ylim(min(min(self.all_soly[10]),-250), max(max(self.all_soly[10]), 250),)
ax.set_zlim(max(max(self.all_soly[11]), 100),min(min(self.all_soly[11]),-100))
#紙飛行機
plot_paper_airplane(x=self.x[9], y=self.x[10], z=self.x[11], phi=self.x[7], theta=self.x[3], psi=self.x[8], scale=100, ax=ax)
# 描画をキャンバスに保存
fig.canvas.draw()
# キャンバスからRGBデータを取得
image = np.frombuffer(fig.canvas.tostring_rgb(), dtype=np.uint8)
image = image.reshape(fig.canvas.get_width_height()[::-1] + (3,))
#メモリ開放
plt.clf()
plt.close()
return image
def close(self):
pass
def seed(self, seed=None):
print(f"{seed=}")
pass
Soft Actor-Critic(SAC)の実装
方策モデルをNNにしたことで、連続値の状態から連続値のアクションを出力できるようになりました。さらに、DQNでは貪欲法でアクションを一つだけ選ぶ方法でしたが、NNになったため、複数のアクションの値を同時に出力で切るようになりました。
また、アクションには乱数zが乗っているため、毎回同じ行動をとるのではなく、ランダム性が生まれるようになりました。

https://qiita.com/pocokhc/items/354a2ddf4cbd742d3191
から画像を引用
#状態を受け取り,ガウス分布の平均と標準偏差の対数を出力する方策モデル
class SACActor(nn.Module):
def __init__(self, state_shape, action_shape):
super().__init__()
self.net = nn.Sequential(
nn.Linear(state_shape[0], 256),
nn.ReLU(inplace=True),
nn.Linear(256, 256),
nn.ReLU(inplace=True),
nn.Linear(256, 2 * action_shape[0]),
)
#tanhでmean(actionに相当)を[-1, 1]にする(こちらではノイズ載せた後にtanhをかけないため)
def forward(self, states):
return torch.tanh(self.net(states).chunk(2, dim=-1)[0])
def sample(self, states):
means, log_stds = self.net(states).chunk(2, dim=-1)
return reparameterize(means, log_stds.clamp(-20, 2))
def reparameterize(means, log_stds):
""" Reparameterization Trickを用いて,確率論的な行動とその確率密度を返す. """
# 標準偏差.logから戻す
stds = log_stds.exp()
# 標準ガウス分布から,ノイズをサンプリングする.
#引数のmeansはサイズの指定のみ
noises = torch.randn_like(means)
# Reparameterization Trickを用いて,N(means, stds)からのサンプルを計算する.
us = means + noises * stds
# tanh を適用し,確率論的な行動を計算する.
actions = torch.tanh(us)
# 確率論的な行動の確率密度の対数を計算する.
# ガウス分布 `N(0, stds * I)` における `noises * stds` の確率密度の対数(= \log \pi(u|a))を計算する.
log_pis = -0.5 * math.log(2 * math.pi) * log_stds.size(-1) - log_stds.sum(dim=-1, keepdim=True) - (0.5 * noises.pow(2)).sum(dim=-1, keepdim=True)
log_pis -= torch.log(1 - actions.pow(2) + 1e-6).sum(dim=-1, keepdim=True)
return actions, log_pis
#Clipped Double Q
#stateとactionを受け取ってQを2つ(Double)出力する
class SACCritic(nn.Module):
def __init__(self, state_shape, action_shape):
super().__init__()
self.net1 = nn.Sequential(
nn.Linear(state_shape[0] + action_shape[0], 256),
nn.ReLU(inplace=True),
nn.Linear(256, 256),
nn.ReLU(inplace=True),
nn.Linear(256, 1),
)
self.net2 = nn.Sequential(
nn.Linear(state_shape[0] + action_shape[0], 256),
nn.ReLU(inplace=True),
nn.Linear(256, 256),
nn.ReLU(inplace=True),
nn.Linear(256, 1),
)
def forward(self, states, actions):
x = torch.cat([states, actions], dim=-1)
return self.net1(x), self.net2(x)
class ReplayBuffer:
def __init__(self, buffer_size, state_shape, action_shape, device):
# 次にデータを挿入するインデックス.
self._p = 0
# データ数.
self._n = 0
# リプレイバッファのサイズ.
self.buffer_size = buffer_size
# GPU上に保存するデータ.
self.states = torch.empty((buffer_size, *state_shape), dtype=torch.float, device=device)
self.actions = torch.empty((buffer_size, *action_shape), dtype=torch.float, device=device)
self.rewards = torch.empty((buffer_size, 1), dtype=torch.float, device=device)
self.dones = torch.empty((buffer_size, 1), dtype=torch.float, device=device)
self.next_states = torch.empty((buffer_size, *state_shape), dtype=torch.float, device=device)
def append(self, state, action, reward, done, next_state):
self.states[self._p].copy_(torch.from_numpy(state))
self.actions[self._p].copy_(torch.from_numpy(action))
self.rewards[self._p] = float(reward)
self.dones[self._p] = float(done)
self.next_states[self._p].copy_(torch.from_numpy(next_state))
self._p = (self._p + 1) % self.buffer_size
self._n = min(self._n + 1, self.buffer_size)
def sample(self, batch_size):
idxes = np.random.randint(low=0, high=self._n, size=batch_size)
return (
self.states[idxes],
self.actions[idxes],
self.rewards[idxes],
self.dones[idxes],
self.next_states[idxes]
)
class SAC():
def __init__(self, state_shape, action_shape, device=torch.device('cuda'), seed=0,
batch_size=256, gamma=0.99, lr_actor=3e-4, lr_critic=3e-4,
replay_size=10**6, start_steps=10**4, tau=5e-3, alpha=0.2, reward_scale=1.0):
# シードを設定する.
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
# リプレイバッファ.
self.buffer = ReplayBuffer(
buffer_size=replay_size,
state_shape=state_shape,
action_shape=action_shape,
device=device,
)
# Actor-Criticのネットワークを構築する.
self.actor = SACActor(
state_shape=state_shape,
action_shape=action_shape
).to(device)
self.critic = SACCritic(
state_shape=state_shape,
action_shape=action_shape
).to(device)
self.critic_target = SACCritic(
state_shape=state_shape,
action_shape=action_shape
).to(device).eval()
# ターゲットネットワークの重みを初期化し,勾配計算を無効にする.
self.critic_target.load_state_dict(self.critic.state_dict())
for param in self.critic_target.parameters():
param.requires_grad = False
# オプティマイザ.
self.optim_actor = torch.optim.Adam(self.actor.parameters(), lr=lr_actor)
self.optim_critic = torch.optim.Adam(self.critic.parameters(), lr=lr_critic)
# その他パラメータ.
self.learning_steps = 0
self.batch_size = batch_size
self.device = device
self.gamma = gamma
self.start_steps = start_steps
self.tau = tau
self.alpha = alpha
self.reward_scale = reward_scale
def explore(self, state):
""" 確率論的な行動と,その行動の確率密度の対数 \log(\pi(a|s)) を返す. """
state = torch.tensor(state, dtype=torch.float, device=self.device).unsqueeze_(0)
with torch.no_grad():
action, log_pi = self.actor.sample(state)
return action.cpu().numpy()[0], log_pi.item()
def exploit(self, state):
""" 決定論的な行動を返す. """
state = torch.tensor(state, dtype=torch.float, device=self.device).unsqueeze_(0)
with torch.no_grad():
action = self.actor(state)
return action.cpu().numpy()[0]
def is_update(self, steps):
# 学習初期の一定期間(start_steps)は学習しない.
return steps >= max(self.start_steps, self.batch_size)
def step(self, env, state, t, steps):
t += 1
# 学習初期の一定期間(start_steps)は,ランダムに行動して多様なデータの収集を促進する.
if steps <= self.start_steps:
action = env.action_space.sample()
else:
action, _ = self.explore(state)
next_state, reward, done, _ = env.step(action)
# ゲームオーバーではなく,最大ステップ数に到達したことでエピソードが終了した場合は,
# 本来であればその先も試行が継続するはず.よって,終了シグナルをFalseにする.
# NOTE: ゲームオーバーによってエピソード終了した場合には, done_masked=True が適切.
# しかし,以下の実装では,"たまたま"最大ステップ数でゲームオーバーとなった場合には,
# done_masked=False になってしまう.
# その場合は稀で,多くの実装ではその誤差を無視しているので,今回も無視する.
#if t == env.max_episode_steps:
# done_masked = False
#else:
# done_masked = done
done_masked = done
# リプレイバッファにデータを追加する.
self.buffer.append(state, action, reward, done_masked, next_state)
# エピソードが終了した場合には,環境をリセットする.
if done:
t = 0
next_state = env.reset()
return next_state, t
def update(self):
self.learning_steps += 1
states, actions, rewards, dones, next_states = self.buffer.sample(self.batch_size)
self.update_critic(states, actions, rewards, dones, next_states)
self.update_actor(states)
self.update_target()
def update_critic(self, states, actions, rewards, dones, next_states):
curr_qs1, curr_qs2 = self.critic(states, actions)
with torch.no_grad():
next_actions, log_pis = self.actor.sample(next_states)
next_qs1, next_qs2 = self.critic_target(next_states, next_actions)
next_qs = torch.min(next_qs1, next_qs2) - self.alpha * log_pis
target_qs = rewards * self.reward_scale + (1.0 - dones) * self.gamma * next_qs
loss_critic1 = (curr_qs1 - target_qs).pow_(2).mean()
loss_critic2 = (curr_qs2 - target_qs).pow_(2).mean()
self.optim_critic.zero_grad()
(loss_critic1 + loss_critic2).backward(retain_graph=False)
self.optim_critic.step()
def update_actor(self, states):
actions, log_pis = self.actor.sample(states)
qs1, qs2 = self.critic(states, actions)
loss_actor = (self.alpha * log_pis - torch.min(qs1, qs2)).mean()
self.optim_actor.zero_grad()
loss_actor.backward(retain_graph=False)
self.optim_actor.step()
def update_target(self):
for t, s in zip(self.critic_target.parameters(), self.critic.parameters()):
t.data.mul_(1.0 - self.tau)
t.data.add_(self.tau * s.data)
学習用クラス
def wrap_monitor(env):
""" Gymの環境をmp4に保存するために,環境をラップする関数. """
return gym.wrappers.RecordVideo(env, '/tmp/monitor', episode_trigger=lambda x: True)
def play_mp4():
""" 保存したmp4をHTMLに埋め込み再生する関数. """
path = glob.glob(os.path.join('/tmp/monitor', '*.mp4'))[0]
mp4 = open(path, 'rb').read()
url = "data:video/mp4;base64," + b64encode(mp4).decode()
return HTML("""<video width=400 controls><source src="%s" type="video/mp4"></video>""" % url)
from torch.utils.tensorboard import SummaryWriter
%load_ext tensorboard
# TensorBoardをColab内に起動. リアルタイムに学習経過が更新されます
writer = SummaryWriter('./logs')
class Trainer:
def __init__(self, env, env_test, algo, seed=0, num_steps=10**6, eval_interval=10**4, num_eval_episodes=3):
self.env = env
self.env_test = env_test
self.algo = algo
# 環境の乱数シードを設定する.
self.env.seed(seed)
self.env_test.seed(2**31-seed)
# 平均収益を保存するための辞書.
self.returns = {'step': [], 'return': []}
# データ収集を行うステップ数.
self.num_steps = num_steps
# 評価の間のステップ数(インターバル).
self.eval_interval = eval_interval
# 評価を行うエピソード数.
self.num_eval_episodes = num_eval_episodes
def train(self):
""" num_stepsステップの間,データ収集・学習・評価を繰り返す. """
# 学習開始の時間
self.start_time = time.time()
# エピソードのステップ数.
t = 0
# 環境を初期化する.
state = self.env.reset()
#for steps in range(1, self.num_steps + 1):
for steps in tqdm(range(1, self.num_steps + 1)):
# 環境(self.env),現在の状態(state),現在のエピソードのステップ数(t),今までのトータルのステップ数(steps)を
# アルゴリズムに渡し,状態・エピソードのステップ数を更新する.
state, t = self.algo.step(self.env, state, t, steps)
# アルゴリズムが準備できていれば,1回学習を行う.
if self.algo.is_update(steps):
self.algo.update()
# 一定のインターバルで評価する.
if steps % self.eval_interval == 0:
self.evaluate(steps)
def evaluate(self, steps):
""" 複数エピソード環境を動かし,平均収益を記録する. """
returns = []
for _ in range(self.num_eval_episodes):
state = self.env_test.reset()
done = False
episode_return = 0.0
while (not done):
action = self.algo.exploit(state)
state, reward, done, _ = self.env_test.step(action)
episode_return += reward
returns.append(episode_return)
mean_return = np.mean(returns)
self.returns['step'].append(steps)
self.returns['return'].append(mean_return)
writer.add_scalar('Reward', mean_return, steps)
#print(f'Num steps: {steps:<6} '
# f'Return: {mean_return:<5.1f} '
# f'Time: {self.time}')
#tqdm.write(f'Num steps: {steps:<6} '
# f'Return: {mean_return:<5.1f} '
# f'Time: {str(timedelta(seconds=int(time.time() - self.start_time)))}')
def visualize(self):
""" 1エピソード環境を動かし,mp4を再生する. """
env = wrap_monitor(gym.make(self.env.unwrapped.spec.id))
state = env.reset()
done = False
while (not done):
action = self.algo.exploit(state)
state, _, done, _ = env.step(action)
del env
return play_mp4()
#""" 1エピソード環境を動かし,gifを再生する. """
## 最終的に得られた方策のテスト(可視化)
#env = FlightSimulatorEnv()
#frames = []
#state = env.reset()
#frames.append(env.render(mode='rgb_array'))
#done = False
#while not done:
# #action, _ = algo.explore(state)
# action = self.algo.exploit(state)
# #state, reward, done, _ = env.step(action)
# state, _, done, _ = env.step(action)
# frames.append(env.render(mode='rgb_array'))
#env.close()
#del env
#
#plt.figure(figsize=(frames[0].shape[1]/72.0, frames[0].shape[0]/72.0), dpi=72)
#patch = plt.imshow(frames[0])
#plt.axis('off')
#
#def animate(i):
# patch.set_data(frames[i])
#
#anim = animation.FuncAnimation(plt.gcf(), animate, frames=len(frames), interval=2000/len(frames))
#anim.save("paper_plane.gif", writer="imagemagick")
#HTML(anim.to_jshtml())
def plot(self):
""" 平均収益のグラフを描画する. """
fig = plt.figure(figsize=(8, 6))
plt.plot(self.returns['step'], self.returns['return'])
plt.xlabel('Steps', fontsize=24)
plt.ylabel('Return', fontsize=24)
plt.tick_params(labelsize=18)
plt.tight_layout()
実行
ENV_ID = 'my-v0'
SEED = 0
REWARD_SCALE = 1.0
start_steps=50 * 10 ** 3 #学習せずに集めるだけの回数
NUM_STEPS = 100 * 10 ** 3 #学習ステップ
EVAL_INTERVAL = 1 * 10 ** 3 #評価間隔
replay_size=10**6 #バッファの数(全ステップよりも大きくする必要性)
#env = FlightSimulatorEnv()
#env_test = FlightSimulatorEnv()
env = gym.make(ENV_ID)
env_test = gym.make(ENV_ID)
#追加
if torch.cuda.is_available():
device = torch.device("cuda")
else:
device = torch.device("cpu")
print("!!!GPUではなくCPUで実行されているため低速です!!!")
#SAC default param
#state_shape,
#action_shape,
#device=torch.device('cuda'),
#seed=0,
#batch_size=256,
#gamma=0.99,
#lr_actor=3e-4,
#lr_critic=3e-4,
#replay_size=10**6,
#start_steps=10**4,
#tau=5e-3,
#alpha=0.2,
#reward_scale=1.0
algo = SAC(
state_shape=env.observation_space.shape,
action_shape=env.action_space.shape,
seed=SEED,
reward_scale=REWARD_SCALE,
device = device,
start_steps = start_steps,
replay_size=replay_size
)
trainer = Trainer(
env=env,
env_test=env_test,
algo=algo,
seed=SEED,
num_steps=NUM_STEPS,
eval_interval=EVAL_INTERVAL,
)
trainer.train()
報酬の可視化
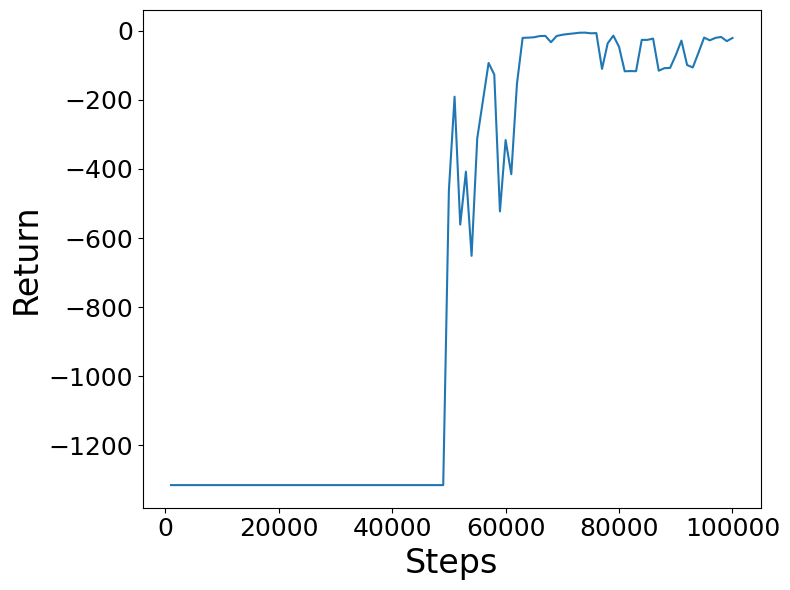
60000ステップあたりから報酬が頭打ちになっています。
trainer.plot()
最終的な飛行の可視化
今回から、4方向から見た際の飛行を動画で可視化するように変更しました。
trainer.visualize()
飛行を見る限り、高度を上げながら旋回を行い、90°旋回出来たら今度は高度を落としていくという飛行になっていることがわかりました。
入力・報酬の時間遷移の可視化
# 最終的に得られた方策のテスト(可視化)
env = env_test
frames = []
rewards = []
for episode in range(1):
state = env.reset()
done = False
while not done:
action = algo.exploit(state)
state, reward, done, info = env.step(action)
frames.append(action)
rewards.append(info["rewards"])
env.close()
test_time = np.linspace(0, (len(frames)-1)*env.dt, len(frames))
elevator_values = [item[0] for item in frames]
throttle_values = [item[1] for item in frames]
aileron_values = [item[2] for item in frames]
rudder_values = [item[3] for item in frames]
plt.figure()
plt.plot(test_time, elevator_values, label="elevator")
plt.plot(test_time, throttle_values, label="throttle")
plt.plot(test_time, aileron_values, label="aileron")
plt.plot(test_time, rudder_values, label="rudder")
plt.xlabel("time [s]")
plt.ylabel("value")
plt.xlim(0, (len(frames)-1)*env.dt)
plt.ylim(-1, 1)
plt.legend()
plt.show()
# 報酬の遷移
labels = ["time",
"altitude",
"bank angle",
"nose",
"once",
"done",
"over",
]
test_time = np.linspace(0, (len(rewards)-1)*env.dt, len(rewards))
rewards = np.array(rewards).T
plt.figure()
for i, reward in enumerate(rewards):
plt.plot(test_time, reward, label=labels[i])
#plt.plot(test_time, np.cumsum(reward), label=labels[i])
#plt.plot(test_time, np.cumsum(np.sum(rewards, axis=0)), label="sum")
plt.xlabel("time [s]")
plt.ylabel("value")
plt.xlim(0, (len(frames)-1)*env.dt)
#plt.ylim(-1, 1)
plt.legend()
plt.show()
plt.figure()
for i, reward in enumerate(rewards):
#plt.plot(test_time, reward, label=i)
plt.plot(test_time, np.cumsum(reward), label=labels[i])
#plt.plot(test_time, np.cumsum(np.sum(rewards, axis=0)), label="sum")
plt.xlabel("time [s]")
plt.ylabel("value")
plt.xlim(0, (len(frames)-1)*env.dt)
#plt.ylim(-1, 1)
plt.legend()
plt.show()
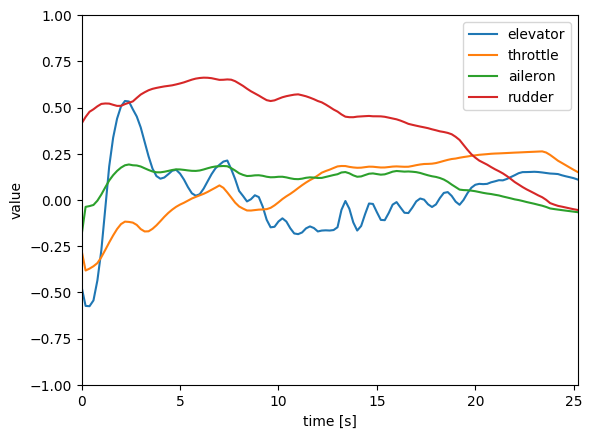
1枚目は各入力の遷移ですが、スロットルは上昇時は絞り、降下時には少し開いていることがわかります。
また、各舵の制御に関しては、ある程度滑らかなものになっています。
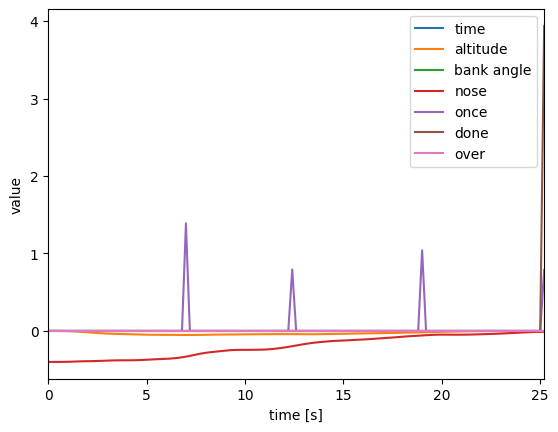
次に、2枚目が報酬の値となっています。
45度ずつ旋回ができたら与えたonceという報酬によりうまく旋回の学習ができたようです。
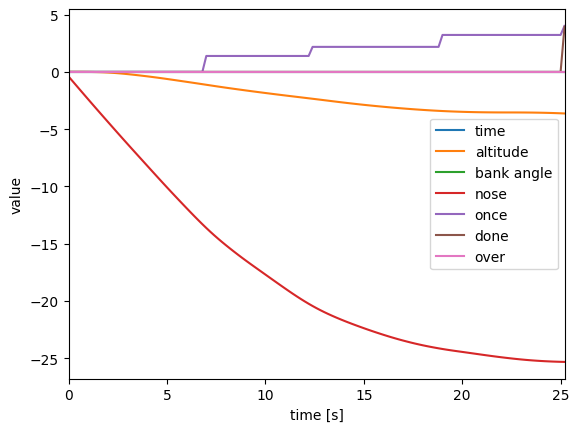
また、3枚目は累積の報酬を示したものがこちらとなります。
こう見るとノーズが目標と違っているために減らされた報酬が大きいことがわかり、高度よりも需要なパラメータになっていたことがわかります。
まとめ
今回はSACにより、水平旋回をさせるプログラムを作りました。
離散値状態・離散値行動であったQ学習、
連続値状態・離散値行動であったDQNと比較し、
連続状態量、連続行動量が使用可能となったため、滑らかな飛行が可能となった一方、学習にかなりの時間がかかるようになりました。
これにて飛行機の自動操縦の基礎的なプログラムは完成したと考えており、あとは運動方程式を変えたり、報酬を変えたり、ニューラルネットワークをより複雑なものにするなど個別の変更だと思います。
そのため、このシリーズはいったんここで終了としたいと思います。
しかし、他にも習ったこととして、模倣学習やモデルベース学習、LLMなどの基盤モデルを使用した強化学習などまだまだ発展したものはありますので、いつかチャレンジしたいと考えています。
また、飛行機同士を戦わせるような将棋や碁でやっているような学習もいつかやってみたいです。
ありがとうございました。