はじめに
この記事はいまさらながらに強化学習(DQN)の実装をKerasを使って進めつつ,目的関数のカスタマイズやoptimizerの追加,複数入力など,ちょっとアルゴリズムに手を加えようとした時にハマった点を備忘録として残したものです.そのため,DQNの解説記事というよりも初心者向けKerasTipsになります.
実行環境
Python3.5.2
Keras 1.2.1
tensorflow 0.12.1
DQNとは
DQN(DeepQNetwork)がDeepMindから発表されて2年以上経つので,もはやいたる所に解説記事や実装サンプルがあり,ここでの詳しい解説は不要だと思います.が,ざっくり言うと,Q-Learningという強化学習手法のQ関数部分を,深層学習により近似することで、動画像から直接Q値を推定することを可能にした学習手法です.
DQNの理論としては
- ゼロからDeepまで学ぶ強化学習
- Pythonではじめる強化学習
- 全力で人工知能に対決を挑んでみた (理論編)[ニコニコ動画]
- DQNの生い立ち + Deep Q-NetworkをChainerで書いた
あたりの解説記事が非常に丁寧でわかりやすいので是非そちらをごらんください.
他の深層学習研究と同様.強化学習もここ数年で一気に研究が進み,2013年発表のDQNは最新手法とは言えませんが,アルゴリズムがシンプルでわかりやすく,実装しやすいので今回はこちらを扱います.
Kerasとは
KerasはTheano,TensorFlowベースの深層学習ラッパーライブラリです.Theano,TensorFlowのおかげでだいぶ深層学習にとっつきやすくなってきたものの,まだまだアルゴリズムをガリガリ書いていくのが大変.ということで,ネットワーク構造をかなりシンプルに書けるようにしたライブラリがKerasです.私のような機械学習初心者にも比較的簡単にコードを組めるようになっています.Kerasを始めて触るという方は,基本的な部分を以前深層学習ライブラリKerasでRNNを使ってsin波予測という記事で書いたので,よろしければそちらをごらんください.
Keras(Tensorflow)でのDQN実装
KerasやTensorflowでのDQN実装解説記事も数多出ています.
- いまさらだけどTensorflowでDQN(完全版)を実装する
- TensorFlowでDQN -箱庭の人工知能虫ー
- DQNをKerasとTensorFlowとOpenAI Gymで実装する
- 超シンプルにTensorFlowでDQN (Deep Q Network) を実装してみる 〜導入編〜
- Keras+DQNでリバーシのAI書く
- DQNプニキにホームランを打たせたい
ので,Kerasについてわかっていて,DQN実装が見たいという方は上の記事をご覧いただいた方がいいかとおもいます.
また,アルゴリズム実装はおいといて,さっさとKerasで強化学習試したいんじゃ!という方は,keras-rlという強化学習特化kerasライブラリがあるのでそちらをご覧ください.使い方については
[Python] Keras-RLで簡単に強化学習(DQN)を試す
の記事が参考になるかと思います.
超シンプルにKerasでDQNを実装してみる
長々と前置きをしましたが本題です.
今回はKerasに慣れるということで,もともとTensorflow等で実装されているものを改変するほうがわかりやすいと思い,すでにTensorflowで実装・公開されているものを使わせていただくことにします.
章題もそのままですが,ALGO GEEKS様の超シンプルにTensorFlowでDQN (Deep Q Network) を実装してみる 〜導入編〜であげて頂いているコードを拝借します.非常にコンパクトかつ分かりやすい実装になっており,学習時間も短くすぐ結果が見られる良サンプルのため,こちらをKerasにコンバートしていきます.
今回実装したコードはgithubにあげました.
ゲーム
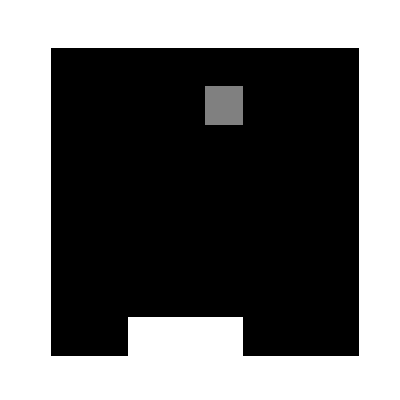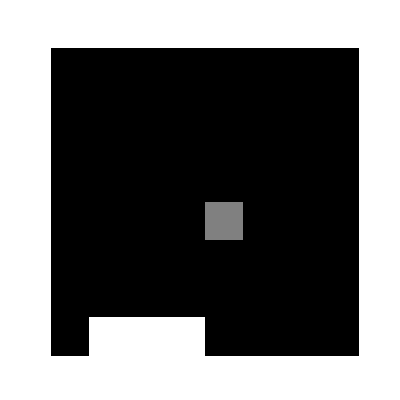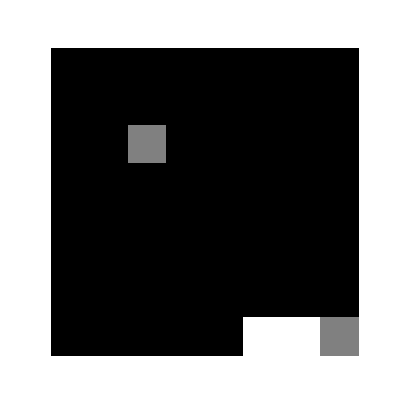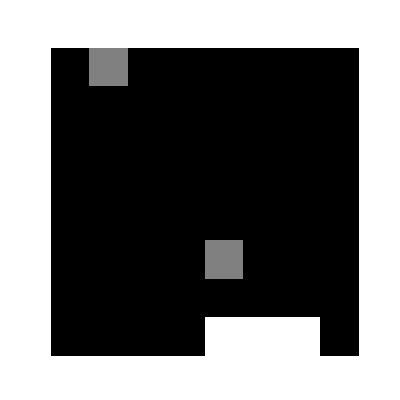
(1000epoch回したあとの様子)
学習環境は非常にシンプルで,図のように8x8のマスのなかで,次々に落ちてくるボールを最下段のバーでキャッチするというゲームです.今回実装するにあたり,本家サイト様とルールを若干変えており,
- ボールをキャッチしたら+1報酬
- ボールを落としたら-1報酬
- アクションは(1:右に動く,0:動かない,-1:左に動く)の三種類
- ボールの落ちる場所はランダム,インターバルは4フレーム
- ボールを落とした時点でゲームオーバー
となっています.
書き換え
tensorflowでは
# input layer (8 x 8)
self.x = tf.placeholder(tf.float32, [None, 8, 8])
# flatten (64)
x_flat = tf.reshape(self.x, [-1, 64])
# fully connected layer (32)
W_fc1 = tf.Variable(tf.truncated_normal([64, 64], stddev=0.01))
b_fc1 = tf.Variable(tf.zeros([64]))
h_fc1 = tf.nn.relu(tf.matmul(x_flat, W_fc1) + b_fc1)
# output layer (n_actions)
W_out = tf.Variable(tf.truncated_normal([64, self.n_actions], stddev=0.01))
b_out = tf.Variable(tf.zeros([self.n_actions]))
self.y = tf.matmul(h_fc1, W_out) + b_out
# loss function
self.y_ = tf.placeholder(tf.float32, [None, self.n_actions])
self.loss = tf.reduce_mean(tf.square(self.y_ - self.y))
# train operation
optimizer = tf.train.RMSPropOptimizer(self.learning_rate)
self.training = optimizer.minimize(self.loss)
# saver
self.saver = tf.train.Saver()
# session
self.sess = tf.Session()
self.sess.run(tf.global_variables_initializer())
となっていました.
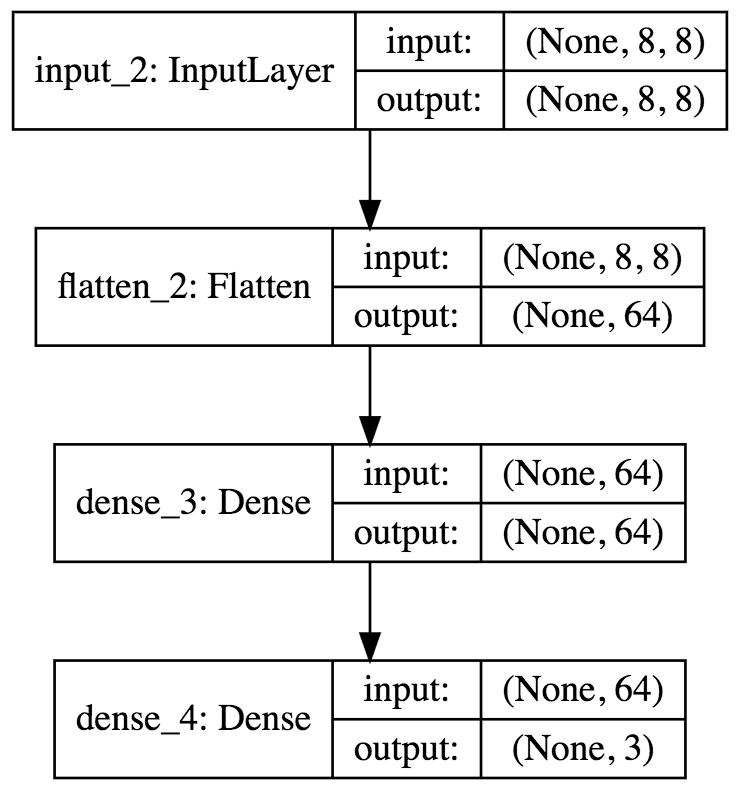
本来のDQNではConv層を3層挟んだあと,全結合してReluを当てているのですが,今回はそもそも8x8と画素数が小さいですし,Conv層は学習に時間がかかるのでこのようになっているのかと思います.こちらをKerasで書き直すと
self.model = Sequential()
self.model.add(InputLayer(input_shape=(8, 8)))
self.model.add(Flatten())
self.model.add(Dense(32, activation='relu'))
self.model.add(Dense(self.n_actions))
optimizer=RMSprop(lr=self.learning_rate)
self.model.compile(loss='mean_squared_error',
optimizer=optimizer,
metrics=['accuracy'])
のようになります.
Kerasの一番の魅力はネットワークを組むコードがかなりシンプルになるところです.
これで8x8のゲーム画面ピクセルを入力するとアクションそれぞれに応じた3つのQ値が出力されるモデルができました.
Q値取得はpredict関数を使って
def Q_values(self, states):
res = self.model.predict(np.array([states]))
return res[0]
でいいですし,experience memoryの部分は,
# training
self.model.fit(np.array(state_minibatch), np.array(y_minibatch), batch_size=minibatch_size,nb_epoch=1,verbose=0)
となります.モデルのsave, loadは
def load_model(self, model_path=None):
yaml_string = open(os.path.join(f_model, model_filename)).read()
self.model = model_from_yaml(yaml_string)
self.model.load_weights(os.path.join(f_model, weights_filename))
self.model.compile(loss='mean_squared_error',
optimizer=RMSProp(lr=self.learning_rate),
metrics=['accuracy'])
def save_model(self, num=None):
yaml_string = self.model.to_yaml()
model_name = 'dqn_model{0}.yaml'.format((str(num) if num else ''))
weight_name = 'dqn_model_weights{0}.hdf5'.format((str(num) if num else ''))
open(os.path.join(f_model, model_name), 'w').write(yaml_string)
self.model.save_weights(os.path.join(f_model, weight_name))
のようになります.コンパクトです.
この実装はわかりやすさ,コンパクトさに重きを置いたものになっていたため,本来のDQNとは異なる点がいくつかあります.
- target networkがない
- loss関数でクリッピングをしていない
- ネットワークに畳み込みを使っていない
- optimizerとして通常のRMSPropを使っており,DQNで推奨されているRMSPropGravesではない
- (replay memoryを満帆にしてから学習開始)
- (Q値に関係なくrandomに行動選択する割合を1から線形に降下させていく)
今回はこれらの点にあたりつつ,Kerasで実装していく際につまったポイントを述べていきます.
Tips1: モデルのコピー
DQNでは,選択したactionを過大評価しないよう,experience memoryを行う(行動を評価する)際と,行動選択を選択する際で使うモデルを分けるという方策がとられています.元々の論文[1]では両者で同じモデルを使っており,natureに掲載された2015年の論文[2]では,両者を分けて新しくtarget networkを導入しています.これによって,古いパラメータを使って教師信号を作ることになります,このあたりの解説は,
introduction to double deep Q-learning
に大変わかりやすく解説されていますので,是非そちらをご覧ください.
実装面の話では,何フレームかに一回,行動選択に利用しているモデルをコピーして,ターゲットモデルに渡さなければいけません.
Kerasではどうするかというと,
from keras.models import model_from_config
def clone_model(model, custom_objects={}):
config = {
'class_name': model.__class__.__name__,
'config': model.get_config(),
}
clone = model_from_config(config, custom_objects=custom_objects)
clone.set_weights(model.get_weights())
return clone
self.target_model = clone_model(self.model)
のように,モデルと重みをそれぞれ新しいモデルに渡すことでコピーすることができます.
ただ,
import copy
self.target_model = copy.copy(self.model)
## deepcopyはエラーになる
# self.target_model = copy.deepcopy(self.model)
のように標準copy関数でも,モデル,パラメータはコピーされているようです(公式にはみつけられませんでした)が,ちょっと挙動がこわいので先の方法のほうがよいでしょう.
今回は,clone_modelをつかって定期的にtarget_modelに現modelをコピーし,Q値を評価更新する際にはtarget_modelを用いるようにします.(余談ですが改良版DQNのDDQNでは,'現modelに状態を入れて出た最大のQ値をとるaction'(A)をもとめ,target modelに状態を入れて出たQ値でAに対応するものを利用しています)
def Q_values(self, states, isTarget=False):
model = self.target_model if isTarget else self.model
res = model.predict(np.array([states]))
return res[0]
def store_experience(self, states, action, reward, states_1, terminal):
self.D.append((states, action, reward, states_1, terminal))
return (len(self.D) >= self.replay_memory_size)
def experience_replay(self):
state_minibatch = []
y_minibatch = []
action_minibatch = []
# sample random minibatch
minibatch_size = min(len(self.D), self.minibatch_size)
minibatch_indexes = np.random.randint(0, len(self.D), minibatch_size)
for j in minibatch_indexes:
state_j, action_j, reward_j, state_j_1, terminal = self.D[j]
action_j_index = self.enable_actions.index(action_j)
y_j = self.Q_values(state_j)
if terminal:
y_j[action_j_index] = reward_j
else:
if not self.use_ddqn:
v = np.max(self.Q_values(state_j_1, isTarget=True))
else: # for DDQN
v = self.Q_values(state_j_1, isTarget=True)[action_j_index]
y_j[action_j_index] = reward_j + self.discount_factor * v
state_minibatch.append(state_j)
y_minibatch.append(y_j)
action_minibatch.append(action_j_index)
# training
self.model.fit(np.array(state_minibatch), np.array(y_minibatch), verbose=0)
Tips2: loss関数のカスタマイズ
先ほどの例では単純に'mean_squared_error'を使っていましたが,DQNでは学習の安定性を向上させるために、エラーであるtarget − Q(s,a;θ)の値を-1から1の範囲でクリップします.このあたりは
DQNをKerasとTensorFlowとOpenAI Gymで実装する
に大変わかりやすく解説されてますので,是非そちらをご覧ください.
Kerasにはデフォルトで数種類のloss関数を用意しており,'mean_squared_error'のように名前を書くだけで使えますが,今回のように自分でloss関数を定義したくなることはままあります.
もちろん,Kerasにはそのための方法が用意されており(若干取り回しが悪いですが)
def loss_func(y_true, y_pred):
error = tf.abs(y_pred - y_true)
quadratic_part = tf.clip_by_value(error, 0.0, 1.0)
linear_part = error - quadratic_part
loss = tf.reduce_sum(0.5 * tf.square(quadratic_part) + linear_part)
return loss
self.model.compile(loss=loss_func, optimizer='rmsprops', metrics=['accuracy'])
のように独自でloss関数を定義することができます(y_trueが教師データ,y_predがモデルの出力です).model.fitやmodel.evaluateを呼び出した際はこちらの関数が使われます.
[参考] How to use a custom objective function for a model? #369
若干取り回しが悪い,といったのはloss関数にy_true, y_pred以外の外部パラメータを導入するのが非常にやっかいだからです.
今回の例では,experience memoryにてy_trueに代入する値として,現modelからの出力Q値リストをそのまま代入(更新がある部分だけを更新)し([1.2, 0.5, 0.1] -> [1.3, 0.5, 0.1]), loss関数内部で現modelからの出力Q値リストとの絶対値差分をとっています.そのため,errorでは更新があった部分のみに値が残り,他は0になっています([1.3, 0.5, 0.1] - [1.2, 0.5, 0.1] = [0.1, 0, 0]).最終的には更新があった部分しかloss値に影響しないようになっており,他の外部変数は必要ありません.
しかし,loss関数に教師信号(更新値のみ)(1.3),モデル出力([1.2, 0.5, 0.1]),選択アクション(0)を渡し,モデル内でそれらからloss値を計算しようとすると途端に面倒になります. Tensorflowでは
state = tf.placeholder(tf.float32, [None, 8, 8]) # 状態
a = tf.placeholder(tf.int64, [None]) # 行動
supervisor = tf.placeholder(tf.float32, [None]) # 教師信号
output = self.inference(state)
loss = lossfunc(output, supervisor)
...
loss_val = sess.run(loss, feed_dict={
self.state: np.float32(np.array(state_batch),
self.action: action_batch,
self.super_visor: y_batch
})
def lossfunc(self, a, output, supervisor)
a_one_hot = tf.one_hot(a, self.num_actions, 1.0, 0.0) # 行動をone hot vectorに変換する
q_value = tf.reduce_sum(tf.mul(output, a_one_hot), reduction_indices=1) # 行動のQ値の計算
# エラークリップ
error = tf.abs(supervisor - q_value)
quadratic_part = tf.clip_by_value(error, 0.0, 1.0)
linear_part = error - quadratic_part
loss = tf.reduce_mean(0.5 * tf.square(quadratic_part) + linear_part) # 誤差関数
のように非常にシンプルにかけますが,Kerasではそうもいきません,どうするかというと,y_true, y_pred, その他外部関数を入力とし,loss値を出力とするモデルを作る必要があります.
Tips3: 複数入力,複数出力
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers import Lambda, Input
losses = {'loss': lambda y_true, y_pred: y_pred, #dummy loss func
'main_output': lambda y_true, y_pred: K.zeros_like(y_pred)}
def customized_loss(args):
import tensorflow as tf
y_true, y_pred, action = args
a_one_hot = tf.one_hot(action, K.shape(y_pred)[1], 1.0, 0.0)
q_value = tf.reduce_sum(tf.mul(y_pred, a_one_hot), reduction_indices=1)
error = tf.abs(q_value - y_true)
quadratic_part = tf.clip_by_value(error, 0.0, 1.0)
linear_part = error - quadratic_part
loss = tf.reduce_sum(0.5 * tf.square(quadratic_part) + linear_part)
return loss
...
def init_model(self):
state_input = Input(shape=(1, 8, 8), name='state')
action_input = Input(shape=[None], name='action', dtype='int32')
x = Flatten()(state_input)
x = Dense(32, activation='relu')(x)
y_pred = Dense(3, activation='linear', name='main_output')(x)
y_true = Input(shape=(1, ), name='y_true')
loss_out = Lambda(customized_loss, output_shape=(1, ), name='loss')([y_true, y_pred, action_input])
self.model = Model(input=[state_input, action_input, y_true], output=[loss_out, y_pred])
self.model.compile(loss=losses,
optimizer=RMSprop(lr=self.learning_rate),
metrics=['accuracy'])
slef.init_model()
...
res = model.predict({'state': np.array([states]),
'action': np.array([0]), #dummy
'y_true': np.array([[0] * self.n_actions]) #dummy
})
return res[1][0]
...
self.model.fit({'action': np.array(action_minibatch),
'state': np.array(state_minibatch),
'y_true': np.array(y_minibatch)},
[np.zeros([minibatch_size]),
np.array(y_minibatch)],
batch_size=minibatch_size,
nb_epoch=1,
verbose=0)
...圧倒的に面倒.Kerasはデフォルトでかなりシンプルかける仕組みになっていますが,そこからちょっと外れたことをやろうとすると一気に面倒くさくなってきます.
先ほどと変わった点は,
- 入力に新たにaction_inputが加わっている
- y_trueも入力として扱っている(入力は3つ)
- lossを計算するために独自レイヤー定義に用いるLambdaを使っている
- 出力としてloss値とQ値を出すようにしている
点です.つらい.loss関数の引数を変える等の大幅なカスタマイズが出来ない以上こうせざるをえません.ちなみにこの方法はKeras公式のexample(https://github.com/fchollet/keras/blob/master/examples/image_ocr.py)に載っています.
ポイントとしては,
- Lambdaを使うことで,インプットと層内の処理,出力の形を自由に設計できる.
- インプット,アウトプットにnameをつかって名前をつけ,prediction, fit時に使用している.
- アウトプットが複数ある際にはそれぞれにloss関数を適用できる.
- modelのアウトプットにloss値が含まれるため,model.compile時に指定するloss関数はダミーでよく,loss値にかける関数は値をそのまま出力し,Q値にかける関数は常に出力0になるようになっている.
- predictを呼び出す際には使わないインプットにはダミー値を指定し(不要?),fitを呼び出す際には,教師信号もインプットとしてあつかう.
といったところでしょうか.
正直こんな書き方をするくらいならTensorflowを使ったほうがマシ説もありますが,Kerasオンリーで書くならこのような感じになるのでしょうか.モデル組だけKerasでやって,残りの部分はTensorflowを使うという方法もあります.
Tips4: optimizerの変更
記事が思ったより長くなってきてしまったので詳しい解説は省きますが(後日追記するかも?),DQNではoptimizerとして通常のRMSPropではなくRMSPropGravesを用いるとパフォーマンスが出やすいとされています.機械学習初心者なので,式を見てもなぜ早くなるのかさっぱりなのですが(どなたかお教えください...),学習が早くなるとのことなら是非使いたいところです(DQN+RNNの論文等は別のoptimizerを使っているようです).しかし,ChainerにはデフォルトではいっているこのRMSPropsGravesですが,Tensorflow,Kerasには入っていません(試していませんがChainerバックグラウンドのKerasであれば使えるのかもしれません).
そのため,自分でoptimizerを実装する必要があります.Tensorflow版は
いまさらだけどTensorflowでDQN(完全版)を実装する
こちらで詳しく解説されていますので,そちらをご参照ください.論文[3]に乗っている式をみれば実装できます.
epochを重ねて行った時のloss値の推移の違いは以下のようになりました.
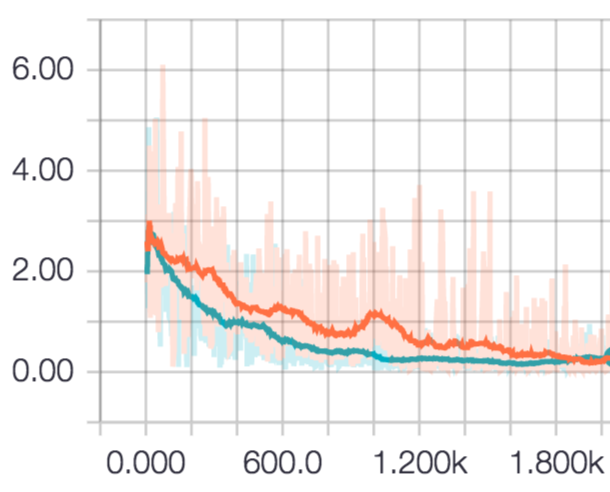
赤がRMSPropで回したもの,青がRMSPropGravesで回したものです.
はじめのうちはRMSPropGravesの方が優勢かと思われましたが,2000回回すと両者同程度の所に落ち着きました.課題が簡単だったせいかもしれません.
Kerasではoptimizerの定義はhttps://github.com/yukiB/keras/blob/master/keras/optimizers.pyに全部ありますので,ここを書き換えてあげれば良さそうです.WIPですが,githubにコードをあげておきます.
もう少し複雑なゲームで試す
ここまでで大分モデルの性能も改善したはずなので,ピクセル数をふやし,全結合の前にConv層を3層追加してみます.
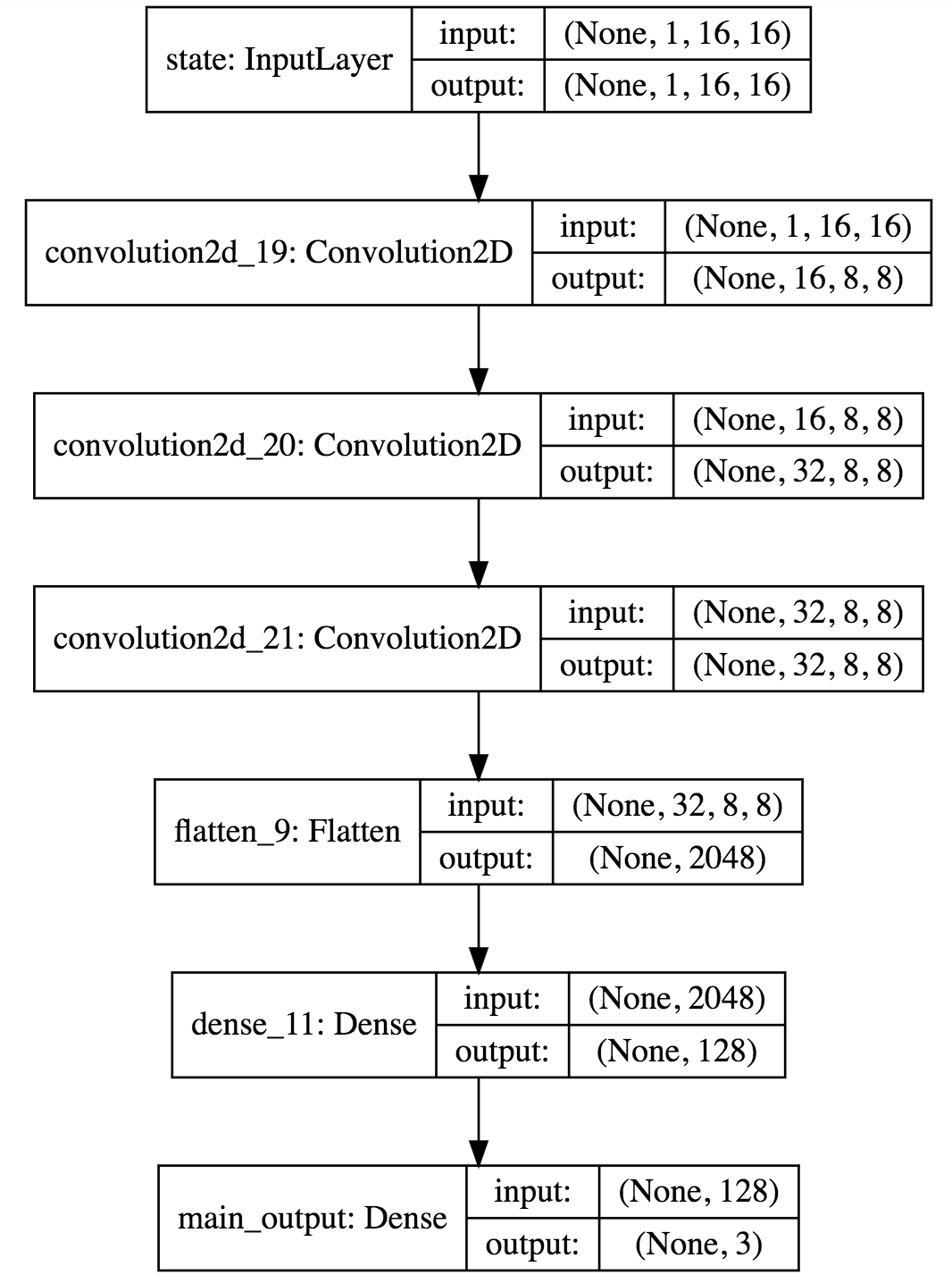
1000回回した結果は以下のようになりました.
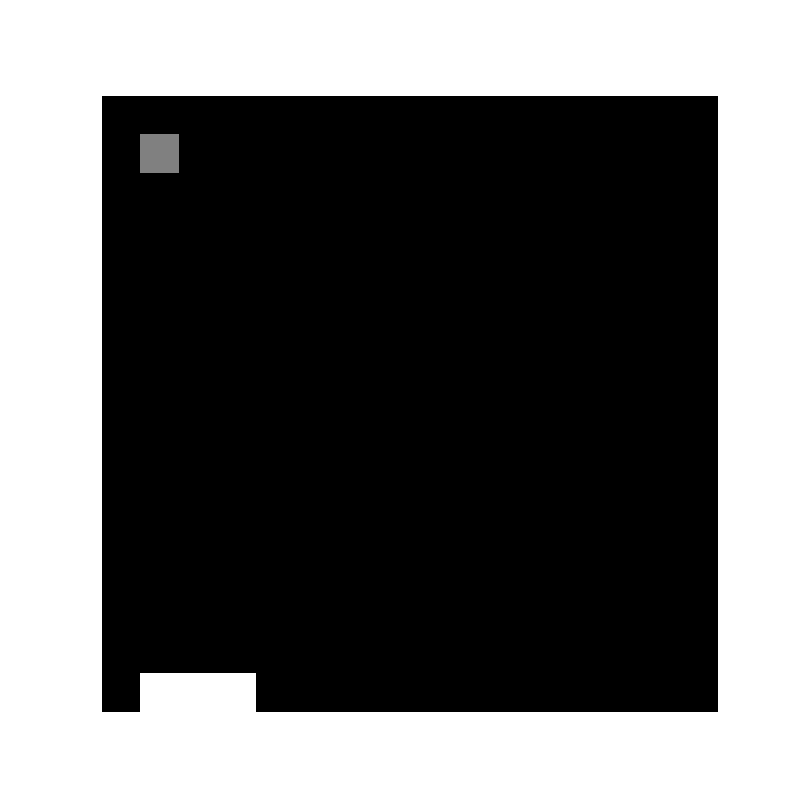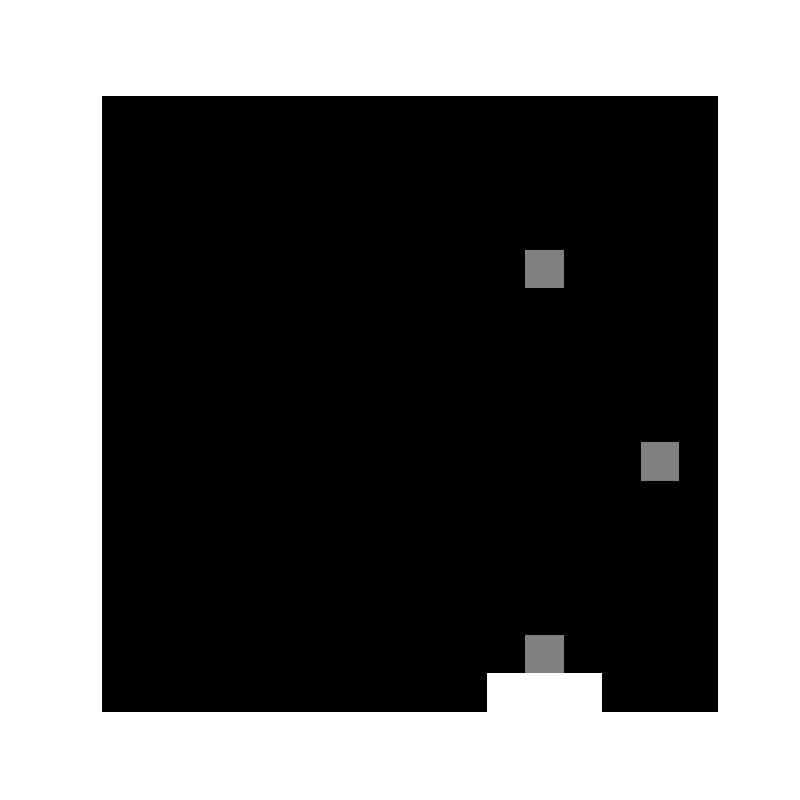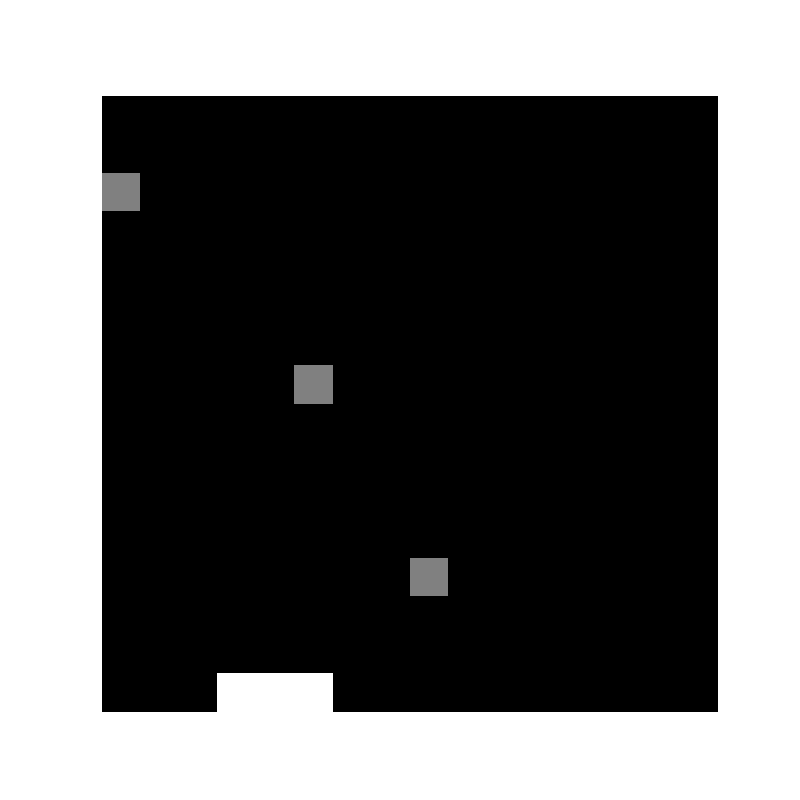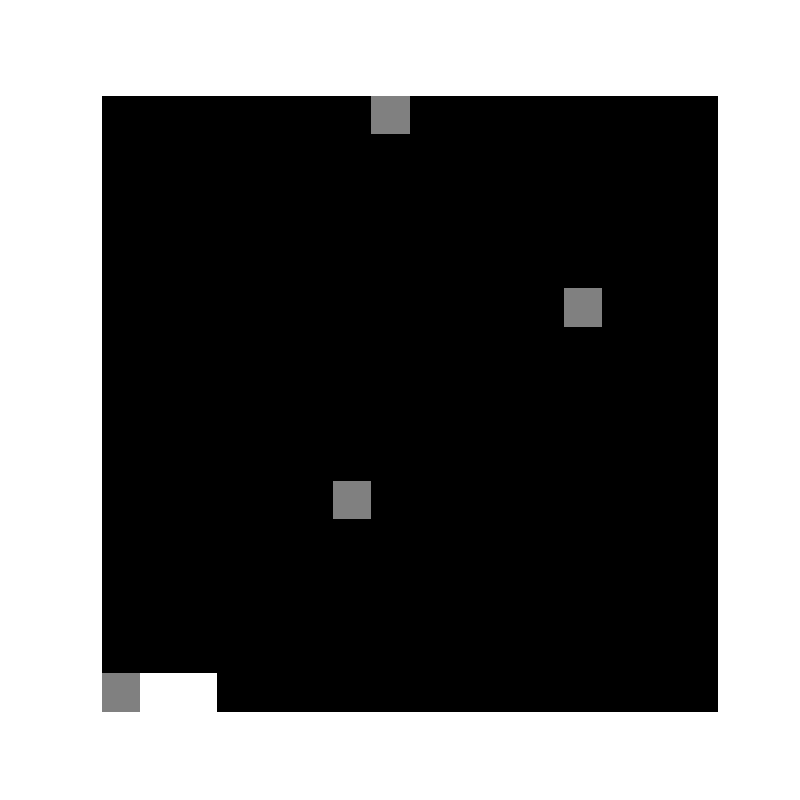
続いて,もう少し複雑なゲームを作り,同じモデルを使って学習を回してみます.
ガラケー時代にとてもはやったCAVEというゲームを簡単にmatplotlibで実装しました.
ボタンを押すと上昇,離すと下降するうにょうにょしたやつを,できるだけ壁にぶつからないようにして進めていくゲームです.
ゲーム画面は48x48で,先ほど作ったネットワーク(Conv3層+全結合Relu)をつかって,
- 入力: ダウンサンプリングした直近4フレーム
- 出力: ボタン入力(ON, OFF)
となるようにしました.
結果としては上下の壁にぶつかることはまずなくなりましたが,道中のブロックに対する回避はあまり学習してくれず,スコアが伸びませんでした.一応入力データとして4フレーム分はとっているのですが,ブロック同士の位置関係によってはもっと遡ったフレームデータが効いてくることも考えられるので,LSTMを組み合わせたDQN等も検討したほうがいいかもしれません.このあたりの話はまた次回

(学習結果をみてるだけで無限に時間が過ぎてしまって危ない)
おわりに
今回はKerasでDQNを組むにあたって,初心者が躓きやすそうなところを取り上げてみました.
初めての強化学習ということで今回はDQNを扱いましたが,かなり時代に乗り遅れている(DDQNやLSTMを組み合わせたものなどはまだまだ現役です)ので次回はA3C等を使って(組んで?)みたいと思います.
今回のコードはここにあります.
参考文献
[1] V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves I. Antonoglou, D. Wierstra, M. Riedmiller. “Playing Atari with Deep Reinforcement Learning” arXiv:1312.5602, 2013.
[2] V. Mnih, et al. “Human-level control through deep reinforcement learning” nature, 2015.
[3] Alex Graves, “Generating Sequences With Recurrent Neural Networks” arXiv preprint arXiv http://arxiv.org/abs/1308.0850