はじめに
強化学習を試してみたい題材はあるけど、自分でアルゴリズムを実装するのは・・・という方向けに、
オリジナルの題材の環境を用意し、keras-rlで強化学習するまでの流れを説明します。
実行時の環境
- Python 3.5
- keras 1.2.0
- keras-rl 0.2.0rc1
- Jupyter notebook
使用するライブラリ
keras
pip install keras
簡単にネットワークが構築できると話題のディープラーニングのフレームワークです。
keras-rl
kerasを利用して、DQNなどの深層強化学習のアルゴリズムを実装したライブラリです。
対応しているアルゴリズムはこちらを参照。
gitのリポジトリをcloneしてインストールします。
git clone https://github.com/matthiasplappert/keras-rl.git
pip install ./keras-rl
OpenAI gym
pip install gym
強化学習向けに、さまざまな環境が用意してあるライブラリです。
keras-rlが、強化学習の環境にgymのインターフェースを要求するのでインストールします。
keras-rlのexampleにgymのCartPoleをDQNで学習するコードがあるので、試してみましょう。
強化学習の環境の構築
keras-rlに学習してもらう強化学習の環境は、OpenAI gymのEnvを実装します。
実装するgymのEnvのコメントには、(https://github.com/openai/gym/blob/master/gym/core.py#L27)
When implementing an environment, override the following methods
in your subclass:
_step
_reset
_render
_close
_configure
_seed
And set the following attributes:
action_space: The Space object corresponding to valid actions
observation_space: The Space object corresponding to valid observations
reward_range: A tuple corresponding to the min and max possible rewards
と書いてありますが、最低限、下記を実装すればOKです。
_step
_reset
action_space
observation_space
今回は簡単に、直線上を動く点を例とし、ランダムな初期位置から速度を操作して、原点にたどり着くことを目標とすることを例とします。
import gym
import gym.spaces
import numpy as np
# 直線上を動く点の速度を操作し、目標(原点)に移動させることを目標とする環境
class PointOnLine(gym.core.Env):
def __init__(self):
self.action_space = gym.spaces.Discrete(3) # 行動空間。速度を下げる、そのまま、上げるの3種
high = np.array([1.0, 1.0]) # 観測空間(state)の次元 (位置と速度の2次元) とそれらの最大値
self.observation_space = gym.spaces.Box(low=-high, high=high) # 最小値は、最大値のマイナスがけ
# 各stepごとに呼ばれる
# actionを受け取り、次のstateとreward、episodeが終了したかどうかを返すように実装
def _step(self, action):
# actionを受け取り、次のstateを決定
dt = 0.1
acc = (action - 1) * 0.1
self._vel += acc * dt
self._vel = max(-1.0, min(self._vel, 1.0))
self._pos += self._vel * dt
self._pos = max(-1.0, min(self._pos, 1.0))
# 位置と速度の絶対値が十分小さくなったらepisode終了
done = abs(self._pos) < 0.1 and abs(self._vel) < 0.1
if done:
# 終了したときに正の報酬
reward = 1.0
else:
# 時間経過ごとに負の報酬
# ゴールに近づくように、距離が近くなるほど絶対値を減らしておくと、学習が早く進む
reward = -0.01 * abs(self._pos)
# 次のstate、reward、終了したかどうか、追加情報の順に返す
# 追加情報は特にないので空dict
return np.array([self._pos, self._vel]), reward, done, {}
# 各episodeの開始時に呼ばれ、初期stateを返すように実装
def _reset(self):
# 初期stateは、位置はランダム、速度ゼロ
self._pos = np.random.rand()*2 - 1
self._vel = 0.0
return np.array([self._pos, self._vel])
DQNの構築と学習
keras-rlのexampleのdqn_cartpole.pyを参考にして、DQNの構築と学習をするコードを書きます。
from keras.models import Sequential
from keras.layers import Dense, Activation, Flatten
from keras.optimizers import Adam
from rl.agents.dqn import DQNAgent
from rl.policy import EpsGreedyQPolicy
from rl.memory import SequentialMemory
env = PointOnLine()
nb_actions = env.action_space.n
# DQNのネットワーク定義
model = Sequential()
model.add(Flatten(input_shape=(1,) + env.observation_space.shape))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(nb_actions))
model.add(Activation('linear'))
print(model.summary())
# experience replay用のmemory
memory = SequentialMemory(limit=50000, window_length=1)
# 行動方策はオーソドックスなepsilon-greedy。ほかに、各行動のQ値によって確率を決定するBoltzmannQPolicyが利用可能
policy = EpsGreedyQPolicy(eps=0.1)
dqn = DQNAgent(model=model, nb_actions=nb_actions, memory=memory, nb_steps_warmup=100,
target_model_update=1e-2, policy=policy)
dqn.compile(Adam(lr=1e-3), metrics=['mae'])
history = dqn.fit(env, nb_steps=50000, visualize=False, verbose=2, nb_max_episode_steps=300)
# 学習の様子を描画したいときは、Envに_render()を実装して、visualize=True にします,
テストと結果の描画
学習したAgentをテストして、結果を描画してみます。
各ステップの情報を記憶するCallbackを実装して(keras-rlにはない?)、
testを実行し、Callbackにたまった結果をplotします。
import rl.callbacks
class EpisodeLogger(rl.callbacks.Callback):
def __init__(self):
self.observations = {}
self.rewards = {}
self.actions = {}
def on_episode_begin(self, episode, logs):
self.observations[episode] = []
self.rewards[episode] = []
self.actions[episode] = []
def on_step_end(self, step, logs):
episode = logs['episode']
self.observations[episode].append(logs['observation'])
self.rewards[episode].append(logs['reward'])
self.actions[episode].append(logs['action'])
cb_ep = EpisodeLogger()
dqn.test(env, nb_episodes=10, visualize=False, callbacks=[cb_ep])
%matplotlib inline
import matplotlib.pyplot as plt
for obs in cb_ep.observations.values():
plt.plot([o[0] for o in obs])
plt.xlabel("step")
plt.ylabel("pos")
Testing for 10 episodes ...
Episode 1: reward: 0.972, steps: 17
Episode 2: reward: 0.975, steps: 16
Episode 3: reward: 0.832, steps: 44
Episode 4: reward: 0.973, steps: 17
Episode 5: reward: 0.799, steps: 51
Episode 6: reward: 1.000, steps: 1
Episode 7: reward: 0.704, steps: 56
Episode 8: reward: 0.846, steps: 45
Episode 9: reward: 0.667, steps: 63
Episode 10: reward: 0.944, steps: 29
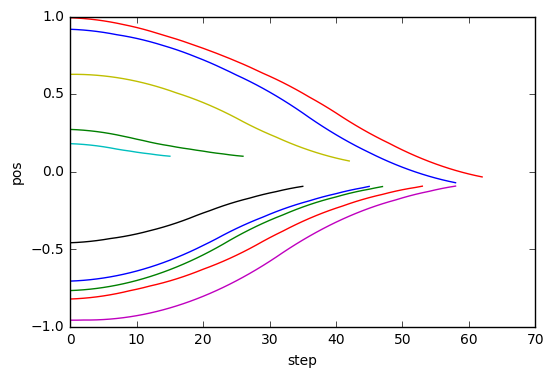
位置0にスムーズに向かうように学習ができました。