はじめに
pytorchのWeightedRandomSamplerについてまとめてみた。
なお本記事は英文のこちらの記事を参考にまとめているのでご承知おきください。
参考記事にもあるように、WeightedRandomSamplerの公式ドキュメントを見ても実装方法について情報が詳しく無く、なかなかとっつきにくい。ここではその実装方法と効果についてまとめる。
WeightedRandomSamplerの学習結果への効果の検証は、別記事にまとめる。
記事を読んでわかること
-
WeightedRandomSamplerのパラメータの設定方法 -
WeightedRandomSamplerをDataLoaderに組み込む方法 - 効果と、考えられうる弊害
どういうときに使う?
画像のクラス分類で、不均衡データセットを扱う場合に、少数クラスのアップサンプリングを行うために有用。
少数クラスのサンプリング確率を上げ、ミニバッチ内のデータの不均衡を無くすことが可能になる。
検証
不均衡データセットを用意し、WeightedRandomSamplerの適応前後でのサンプリングの変化を見てみる。
インバランスデータの用意
データはKaggleで公開されてるものを使う。
今回は、こちらからダウンロードできるtoyota_carsを使って、インバランスデータセットを用意する。
車種の中からcarmyとcrownを採用し、この車種を見分ける2クラス分類問題を想定する。それぞれのクラス数は以下。carmyが多数クラスでcrowmが少数クラスのため、それぞれラベルを0, 1とする。
少数クラスの占める割合は、3.4%。
| class | label_count | label |
|---|---|---|
| carmy | 2246 | 0 |
| crown | 77 | 1 |
※toyota_carsのラベルとクラス数はこの記事にまとめている。
ミニバッチ内のクラス数を調査
まずは何も適応しないDataLoaderにおいて、ミニバッチ内でクラス数の偏りを調査する。
バッチサイズはbach_size=32として、ラベルを表示してみる。
動作を軽くするため、datasetの返り値は「画像のパス」と「ラベル」になるようにした。(コーディングの詳細はこちら。)
import torch.utils.data as data
dataloader = data.DataLoader(dataset, batch_size=batch_size, shuffle=True)
batch_iterator = iter(dataloader)
path, labels = next(batch_iterator)
print(labels)
## 出力
# tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1,
# 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
少数クラスはバッチ内にわずか2つのみであることがわかる。
iteration=10までのラベル数の割合を棒グラフで表示すると以下のようになる。
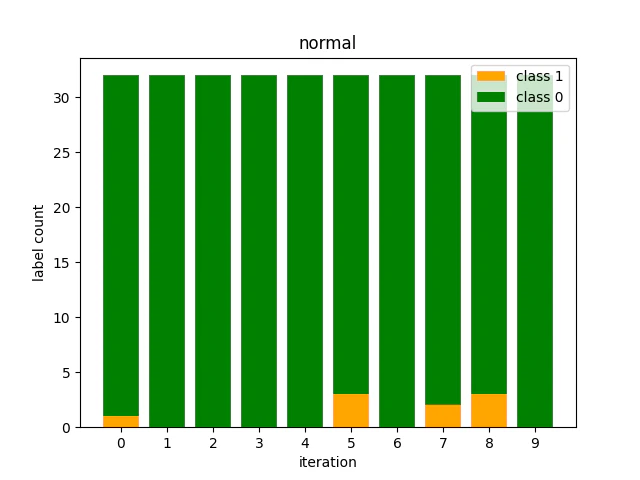
このように、10イテレーションの中で少数クラスがサンプリングされたのは9回のみとなり、全体のわずか3%弱と少数クラスの割合とおおよそ一致する結果となる。
この偏りがインバランスなクラス分類で発生する問題であり、少数クラスの分類性能を上げる難しさに繋がる。
WeightedRandomSamplerを実装
まず、各クラスのラベル数を取得し、その逆数をweightとして用いる。
ポイントは全てのデータにそれぞれweightを設定し、samplerとしてDataLoaderの引数として設定すること。
方法は任意だが、例えば以下のように行う。
camryとcrownのラベル数をそれぞれlabelcount_0, labelcount_1とするとき、weightを以下のように設定する。
labelcount = np.array([labelcount_0, labelcount_1])
class_weight = 1 / labelcount
print(class_weight)
## 出力
# [0.00044543 0.01298701]
weightはclass_weightにnumpy.array型に格納した。
続いて、各データにweightを割り振り、list型で保存する
## サンプルにweightを設定
sample_weight = [class_weight[list_files[i][1]] for i in range(len(list_files))]
print(sample_weight[:5)
## 出力
# [0.00044543429844097997, 0.00044543429844097997, 0.00044543429844097997]
ここで、list_filesには[['path', label, class_name]]がlistで格納されている。
最後に、samplerとしてWeightedRandomSamplerを実装する。
from torch.utils.data import WeightedRandomSampler
sampler = WeightedRandomSampler(weights=sample_weight, num_samples=len(list_files), replacement=True)
ここでreplacement=Trueとしている。これはアップサンプリングに伴い、少数クラスのサンプリングの重複を許容するため。
設定したsamplerをDataLoaderの引数として設定すれば、実装は完了。
import torch.utils.data as data
dataloader_WRS = data.DataLoader(dataset, sampler=sampler, batch_size=batch_size)
効果の確認
各ミニバッチごとのラベルを棒グラフで表すと以下のようになる。

少数クラスがアップサンプリングされ、バッチ内でおおよそ半々になっていることがわかる。
更にその割合もイテレーションごとにばらつきを持っている。
各バッチごとで少数クラスが占める割合を調べる。
1000イテレーションまで回し、各バッチごとの少数クラスの割合をヒストグラムで表すと、以下のようになる。

おおよそ50%付近のところで中央値を持つ。
また、少数クラスは多数クラスと半々になるようにアップサンプリングされるが、その割合は各バッチごとにばらつきを持ち、中には7割以上が少数クラスになるようにアップサンプリングされるバッチも存在している事がわかる。
各データのサンプリング回数について
ここまでWeightedRandomSamplerを使ったアップサンプリングの方法についてまとめてきた。
ここからは、適応によりサンプリング回数がどのように変化するかを見てみる。
まずは先程と同様、適応前を調べる。
イタレーションごとに使用されたデータの割合をプロットし、どのようにサンプリングが行われているのか可視化する。
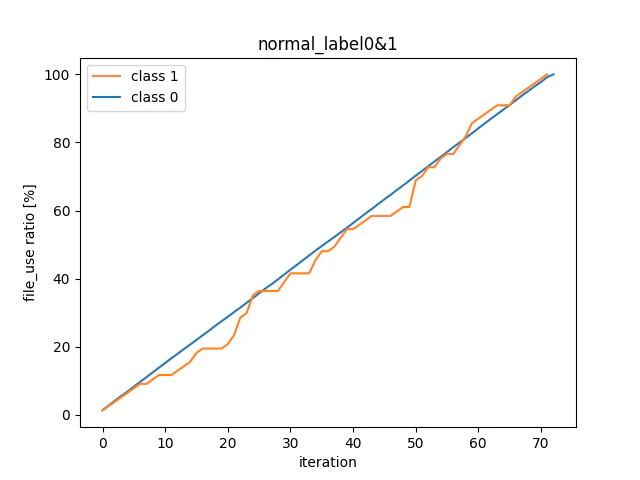
上のグラフのように、少数クラスはデータ数が少ないため直線では無いものの、両クラスのデータを使い切るまでのイタレーション数は、約70と一致している事がわかる。
続いて、WeightedRandomSampler適応後のサンプリング回数を調べる。
先程と同様に、各クラスごとに使用されたデータの割合をプロットすると以下の様になる。
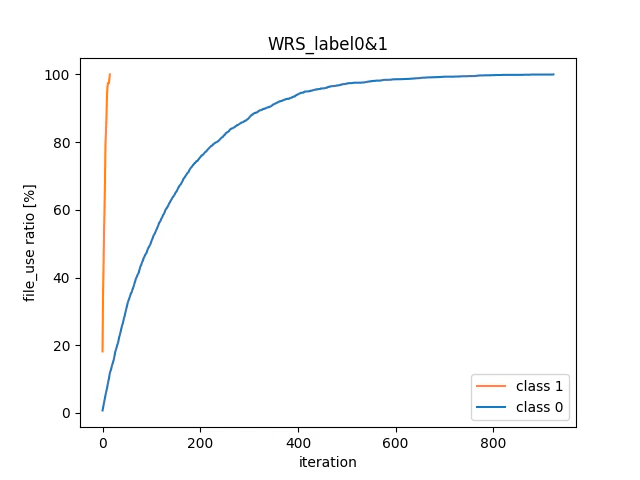
少数クラスはアップサンプリングされているため、適応前より早い15イタレーションですべてのデータを使い切っているのに対し、多数クラスは900イタレーション以上回してデータを使い切っている。
適応前と比較しても、全てのデータを使い切るのに10倍以上の学習回数が必要ということがわかる。
このことから、WeightedRandomSamplerを適応するとバッチごとの不均衡は解消され、少数クラスのサンプリング回数が増加するものの、全データを使い切るまでに必要な学習回数が大幅に増加することがわかる。
結果として、少数クラスの過学習や多数クラスのサンプリング回数低下に伴うPrecisionの悪化などが予想される。
少なくとも少数クラスにはデータオーギュメンテーションによる水増し等が必要で、sampler適応以外にも調整が必要であることは間違いない。
さいごに
今回、WeightedRandomSamplerの実装方法とその効果についてまとめてみた。
更に、少し踏み込んで、適応による弊害についても考察してみた。
不均衡データセットにおけるクラス分類に対し、このAPIの適応は強力に働くと考えられる一方、その弊害を考慮した調整が必要であることが考えられる。
今後、実際にクラス分類を解きながら、どのような調整が効くのかなど、まとめていきたい。
Githubはこちら↓↓
参考