tensorflowでHellowWorld的な存在であるMNISTですが、全然HellowWorldじゃないですね。
どちらかと言えば、SeeYouNiwakaみたいな気分になります。
しかも、何も考えずに実行してみると、だいたい精度90%前後で出てくるし、tensorboardに飛ばすと隠れ層みたいなのが出てくるし、すげえDeepLearningじゃん!みたいな気持ちになりますが、別にDeepLearningではありません。
とまあ、とにかく実行させて結果が出てきて「これで満足でしょ?」みたいなスタンスなのが、MNISTです。
それではあんまりだと思うので、簡単にニューラルネットワークを実装できるスクリプトでtensorflowの解説を行います。(DeepLearningではありません![]() )
)
環境はmacで行うことをオススメします。
WindowsOfficeのエクセルでcsvを編集してしまいますと、tensorflowで読み込むことができません。
ここまで、ドヤ顔で言っていますが、間違っていたらすみません。。。
勉強したてのスクリプトを公開しているだけなので、ふーん、ぐらいの気持ちで間違っている所があればソッと修正リクエストお願いします![]()
データのダウンロード
今回はサザエさんの過去のじゃんけんのデータから、来週はどの手が出る確率が一番高いか求めましょう。
以下のDropboxにデータを置いておいたのでダウンロードしてください。
[トレーニング用]
(https://www.dropbox.com/s/yepiz333ydy3oeg/sazae_train.csv?dl=0)
[テスト用]
(https://www.dropbox.com/s/35nda3833xj8jcy/sazae_eval.csv?dl=0)
tensorflowのインストールはpipとか使ってやってみてください。
インストールコマンド
バージョンは1.0系以降にするようにしましょう。
python2.7系を使っています。
(余談ですが、英語が嫌な人はもう辞めましょう。tensorflowに関する日本語の記事は少なく、しかも1.0系になってからリファレンスも修正がかかっており、古いリファレンスを使ってる記事で溢れているため、当分はtensorflowの公式ドキュメントの英語を読み取ることがメインとなります)
ニューラルネットワークについて
細かい概念の説明は他の記事に任せます。
tensorflowで行うニューラルネットワークで重要なことは、重みの誤差を調べて導いた新たな重みを学習(更新)することです。
改めて言いますが、学習(更新)しているのは重みです。
ニューラルネットワークでは、入力した配列をゴニョゴニョして、出力したい結果に整形して出力します。
ダウンロードしたサザエさんのcsvを見てみましょう。
1~3列目は正解のラベルで、1がある列の手がその週で出された手です。
・1列目がグー
・2列目がチョキ
・3列目がパー
4列目が先週、5列目が先々週に出したじゃんけんの手になります。
・1 = グー
・2 = チョキ
・3 = パー
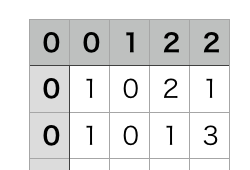
インプットデータが4,5列目、アウトプットデータが1,2,3列目になります。
学習の簡単な流れ
1.サザエさんのcsvから、ランダムに取ってきた4個の入力データ(4,5列目)を入力
2.出力(予測)した結果が出力データ(1~3列目)と違うか誤差を計算、重みを修正
この1と2を繰り返すだけです。
簡単ですね。
pythonで実行してみよう
上記では、配列と言いましたが、正しくはテンソルという形式に保存します。
だいたい配列だと思ってほしいですが、細かい話はググってください。
細かいリファレンスの紹介はめんどくさいのでコメントアウトに書きました。
# -*- coding: utf-8 -*-
import tensorflow as tf
import tensorflow.contrib.slim as slim
# CSVをparse(トレーニング用)
filename_queue = tf.train.string_input_producer(["sazae_train.csv"])
# TextLineReaderは1行ずつ読むリファレンスです
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# record_defaultsですが、若干違うかもしれませんので、その都度修正してください。
output1, output2, output3, input1, input2 = tf.decode_csv(value, record_defaults=[[1], [1], [1], [1.0], [1.0]])
# テンソル形式で保存
inputs = tf.stack([input1, input2])
output = tf.stack([output1,output2,output3])
# ランダムでBatchを作成
# batch_sizeは30~100が一般なイメージ。多すぎると学習が発散します。
# min_after_queueはデータからランダムに取得する数です、このmin_after_queueからバッチを取得します。
# min_afte_queue はデータ全体の40%がオススメです。
# capatcity = batchsize * 3 + min_after_queue が公式推奨みたいです。
inputs_batch, output_batch = tf.train.shuffle_batch([inputs, output], batch_size=4, capacity=60, min_after_dequeue=40)
## NNの生成
# 中間層の生成
hiddens = slim.stack(inputs_batch, slim.fully_connected, [2,4], activation_fn=tf.sigmoid, scope="hidden")
# 出力層の生成
# 出力が多クラスの活性化関数ではsoftmax、2クラスではsigmoid(今回は出力が3次元なのでsoftmax)
prediction = slim.fully_connected(hiddens, 3, activation_fn=tf.nn.softmax, scope="output")
# output_batchとNNの出力結果の誤差を計算
loss = slim.losses.softmax_cross_entropy(prediction, output_batch)
# 誤差から、新しい重みを更新
# optimizerは誤差更新のアルゴリズム(詳しくはググって)
# learning_rateは誤差更新の振り幅、小さいと時間がかかるがしっかり修正され、大きいとすぐに良さげな修正ができるがしっかりとした修正がされにくい
train_op = slim.optimize_loss(loss, slim.get_or_create_global_step(), learning_rate=0.01, optimizer='Adam')
# CSVをparse(評価用)
filename_queue_eval = tf.train.string_input_producer(["sazae_eval.csv"])
key, value = reader.read(filename_queue_eval)
output1_eval, output2_eval, output3_eval, input1_eval, input2_eval = tf.decode_csv(value, record_defaults=[[1], [1], [1], [1.0], [1.0]])
inputs_eval = tf.stack([input1_eval, input2_eval])
output_eval = tf.stack([output1_eval, output2_eval, output3_eval])
inputs_batch_eval, output_batch_eval = tf.train.shuffle_batch([inputs_eval, output_eval], 20, capacity=120, min_after_dequeue=80)
hiddens_eval = slim.stack(inputs_batch_eval, slim.fully_connected, [2,4], activation_fn=tf.sigmoid, scope="hidden")
prediction_eval = slim.fully_connected(hiddens_eval, 3, activation_fn=tf.nn.softmax)
# 一旦、リセットしてから始められるようにする
init_op = tf.initialize_all_variables()
# トレーニング関数
def run_training():
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# ミニバッチ処理ループ
try:
# sees.run(a), aに実行したいインスタンスをぶっこむ
sess.run(init_op)
for i in range(2000):
# inputs_batch,output_batch,predictionは同時に実行することで、predictionに使用したバッチを出力できる
_, t_loss = sess.run([train_op, loss])
pre, kati, te = sess.run([prediction, output_batch, inputs_batch])
if (i+1) % 100 == 0:
print t_loss
# print pre
# print te
# print kati
# print ''
for k in range(100):
correct_prediction = tf.equal(tf.argmax(prediction_eval, 1), tf.argmax(output_batch_eval, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print sess.run(accuracy)
finally:
coord.request_stop()
coord.join(threads)
run_training()
結果を見てみよう
何かとwarniningが出たかと思いますが、とりあえずは気にしないでください。
以下の値は、ニューラルネットワークの出力結果とoutput_bathの誤差を計算した結果です。
2000回学習して、100回ごとに結果を出力しています。
本来なら、この誤差がどんどん0に近づきます。
一番最後の0.3は正答率を計算したので、今回は30%です。
評価用のcsvから、ランダムで20バッチずつ取り出して正答率の計算する作業を100回行って、平均正答率を出しています。

当たり前みたいな話をしますが、、、
4個のバッチでこんなのが出たとします(ありえない話ですが)
input_bath1 = [0,1,0]
output_bath1 = [2,2]
input_bath2 = [1,0,0]
output_bath2 = [1,1]
input_bath3 = [0,0,1]
output_bath3 = [3,3]
input_bath4 = [0,1,0]
output_bath4 = [2,2]
ニューラルネットの予測結果では全問不正解になりそうですね。
これは、たまたま2週連続で出た手が3週連続出る傾向になってしまっています。
この時、ニューラルネットは悪い感じに重みを修正します。
こんな偶然のバッチはありませんが、4個のバッチ程度では変な組み合わせがたまたま何度も出てきて、変な学習をするので上記画像では1.0より誤差が小さくなることがなかったのです。
では、たまたま変な組み合わせが出ないように、バッチを増やして傾向を薄くしましょう!
inputs_batch, output_batch = tf.train.shuffle_batch([inputs, output], batch_size=4, capacity=60, min_after_dequeue=40)
↓
inputs_batch, output_batch = tf.train.shuffle_batch([inputs, output], batch_size=40, capacity=520, min_after_dequeue=400)
バッチが増えた分、処理の時間が増えたと思います。
正答率55%まで来ました!

もっと正答率を上げるには畳み込んでDeepLearningなどがありますが、現状の特徴の次元(2次元)では少なすぎて畳み込めません。
とは言いましたが、この程度のデータだとたまたま色々な傾向が見つかったり見つからなかったりして、結果が出てしまいますので、ニューラルネットワーク面白いですね。
結果の中身を見てみよう
ここからはニューラルネットワークを愛でる時間です![]()
# 下記のコメントアウトを外してみましょう.
# print pre
# print te
# print kati
# print ''
# バッチサイズを4に戻そう
inputs_batch, output_batch = tf.train.shuffle_batch([inputs, output], batch_size=4, capacity=60, min_after_dequeue=40)
pythonで実行してみると、行列がいっぱい出て来たと思います。
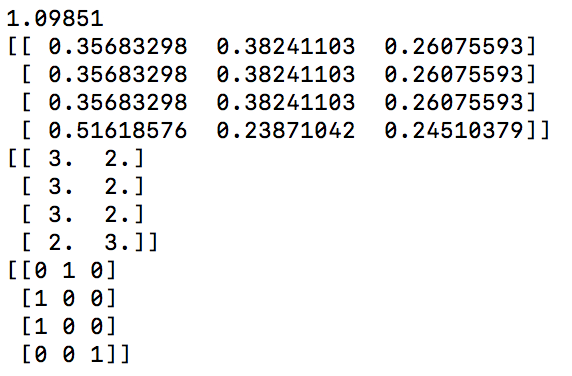
1つ目の小数点がいっぱいある行列は予測の結果です。
・1列目がグーの出る確率
・2列目がチョキの出る確率
・3列目がパーの出る確率
3つ足せば、100%になります。
2つ目の2列の行列はinput_bathになります。
3つ目の3列の行列はoutput_bathになります。
各行列の1行目にのみ着目すると下記のようになります。
prediction = [0.3568, 0.3824, 0.2607]
input_bath = [3,2]
output_bath = [0,1,0]
これはinput_bathに対して、ゴニョゴニョ重みをかけたりした結果、
1が出る確率約37%、2が出る確率約38%、3が出る確率約26%という事になります。
それで、正解のoutput_batchは[0,1,0]なので、見事正解ですね![]()
まあ、他の3つは不正解ですが![]()
こんな感じで完成したニューラルネットワークの予測結果を見て愛でることもできます。
楽しいですね。
次回予告
せっかくなので、クラウドでも実行してみましょう。
【Google Cloud Platform】初めてやるクラウドでの機械学習
上記の記事を参考に、今回のモデルをクラウドに保存してテストします。