0.はじめに
伝えたいこと
- 生産性を向上させる、基本的な正規表現
目次
- 正規表現の概要
- 正規表現の基本的な構文
- 正規表現の応用的な構文
- 私がよく使う正規表現
- 付録
参考図書
このスライドでは、主にこの本から引用、参照しています。

正規表現の動作確認
このスライドでの正規表現は、サクラエディタ Ver. 2.2.0.1で、動作確認しました。
正規表現確認用ファイル を用いて、動作確認しました。
1.正規表現の概要
正規表現とは?
「regular expression」の訳語。
文字列のパターンを記述するため「表現式」。
たとえば、[0-9]という正規表現は「0から9までの数字1文字」を表すパターン。
文字列の検索や置換に使える。
正規表現の使いどころ
- 修正個所に対する影響範囲の調査
- 入力チェック処理
- ログの検索、抽出
正規表現を学ぶ利点
- ほどほどに「単純」であること
- それでいて「強力」であること
(正規表現で解決できる問題は多くある) - そして「廃れない」こと
(約半世紀の歴史がある。実装的・理論的裏付けがあり、簡単に廃れるようなものでない)
「正規表現 技術入門」p.2より引用
正規表現エンジン
さまざまなプログラミング言語、アプリケーションで正規表現は使える。
- Java, Python, Perl, JavaScript....
- Eclipse, Sakura Editor, Word....
ただし、書き方や挙動に違いがあるので、注意が必要。
2. 正規表現の基本的な構文
基本的な正規表現のメタ文字
メタ文字:特別な意味を持つ文字
正規表現のメタ文字は2種類ある
- 構成要素: 数字を表す
\dのように、それ自身があるパターンを表すもの - 演算子: 「4回の繰り返し」を表す
{4}のように、他の正規表現と組み合わせてパターンを表すもの
| 名称 | 演算子 |
|---|---|
| 選択 | | |
| 量指定子 | * + ? {} |
| グループ化 | () (?:) |
| 名称 | 構成要素 |
|---|---|
| ドット(任意の1文字) | . |
| 文字クラス | [abc] |
| アンカー | ^ $ \b \B |
「正規表現 技術入門」p.6より引用
ドット(構成要素)
任意の1文字を表す。
「a.b」という正規表現は、以下の文字にマッチする。
- 『aab』
- 『a b』
【注意事項】
- どこまで任意か?NUL文字、改行文字も含むのか?
- 1文字の定義は?マルチバイト文字は1文字か?
文字クラス(構成要素)
「アルファベット」や「数字」など「一連の文字たち」を表すときに使う。
-
[abc]:「a, b, c」のいずれか -
[0-9]:数字 -
[A-Z]:大文字のみのアルファベット -
[A-Za-z]:大文字と小文字のアルファベット -
[^0-9A-Za-z]:数字やアルファベット以外
【注意事項】
- 「-」(ハイフン)は範囲指定、「^」(ハット)は否定を表す。
- ブラケットの先頭に「^」を書かないと、「否定」を表さない。
量指定子(演算子)
パターンの繰り返しを表す演算子。
-
*:0回以上の任意回の繰り返し -
+:1回以上の任意回の繰り返し -
?:0回か1回か、あるかないか? -
{n,m}:n回からm回の繰り返し -
{n}:n回の繰り返し -
{n,}:n回以上の任意回の繰り返し
[Try] 以下の正規表現でマッチする文字列を確認
ab*cab+cab?cab{2,3}c
選択(演算子)
複数パターンの選択。
「(abc|ABC)」という正規表現は、『abc』または『ABC』にマッチする。
文字クラスは、1文字だけの「選択」を表したもの。
[x-z]はx|y|zと同等。
アンカー(構成要素)
文字列でなく「位置」にマッチするメタ文字。
-
^:行頭 -
$:行末 -
\b:単語の境界(単語と空白との間) -
\B:単語の境界以外
【注意事項】
\bは単語の境界の「空白」でなく、単語の境界そのものにマッチする。
『a b』という文字に対して、a\bは『a』にマッチして、『a 』(スペースあり)にマッチしない。
特殊文字を表すエスケープシーケンス
-
\t:水平タブ -
\n:改行(Line Feed) -
\r:復帰(Carriage Return) -
\f:改ページ
文字クラスを表すエスケープシーケンス
文字クラスを略した表現。
-
\d:数字([0-9]) -
\D:数字以外([^0-9]) -
\w:単語構成文字([A-Za-z0-9_]) -
\W:単語構成文字([^A-Za-z0-9_]) -
\s:空白文字([\t\n\f\r]) -
\S:空白文字以外([^\t\n\f\r])
【注意事項】
- 大文字は「否定」を表す。
-
\wはアンダースコアも含む
3. 正規表現の応用的な構文
番号指定で置換
()でグループ化したパターンは、番号指定で参照可能。
日付フォーマットを「yyyy/mm/dd」から「dd/mm/yyyy」に変える場合、
- 置換前:
(\d{4})/(\d{2})/(\d{2}) - 置換後:
$3/$2/$1
[Try] 名前指定で置換
グループ化したパターンに名前を付けられる。
番号指定よりメンテナンス性が向上。
- 構文:
(?<name>式) - 参照方法:
$+{name}
※サクラエディタで動作する構文
日付フォーマットを「yyyy/mm/dd」から「dd/mm/yyyy」に変える場合
- 置換前:
(?<year>\d{4})/(?<month>\d{2})/(?<day>\d{2}) - 置換後:
$+{day}/$+{month}/$+{year}
最長一致
文字列『aaa』に対して、a+というパターンは『aaa』にマッチする。
しかし、「文字列『a』の1回以上の繰り返し」と考えた場合、以下の文字列にもマッチするはずである。
- 『a』
- 『aa』
+は「できる限り長くマッチさせる」ように振る舞う(最長一致)ので、『aaa』にマッチする。
「欲張りな量指定子」(greedy quantifier)とも呼ぶ。
[Try] 最短一致
「できる限り短くマッチさせる」場合は、量指定子の直後に?を付ける。
文字列『aaa』に対して、a+?というパターンは『a』にマッチする。
| 最長一致 | 最短一致 |
|---|---|
* |
*? |
+ |
+? |
? |
?? |
{n} {n,m} |
{n}? {n,m}? |
「控え目な量指定子」(lazy quantifier)とも呼ぶ。
最短一致の活用例
引用符で囲まれた文字を抽出するのに便利。
文字列『"america","japan","china"』に対して、個々の文字列にマッチさせたい場合、正規表現 ".*?" で、引用符で囲まれた文字列ごとにマッチする。
4. 私がよく使う正規表現
カンマごとに改行する
JavaのtoStringメソッドの結果などは、カンマ区切りの長い1行で出力される。
カンマごとに改行して見やすくする。
- 置換前:
, - 置換後:
\r\n
Windowsの改行コードは「CF+LF」。改行を取り除く場合は、「\r\n」を消す必要がある。
iBatis用のUPDATE文を作成
UPDATE文のSET句に関して。
たいてい列名とパラメータ名は同じなので、置換でSET句を生成する。
id
name
date
id = #id#
name = #name#
date = #date#
- 置換前:
(\w+) - 置換後:
$1 = #$1#"
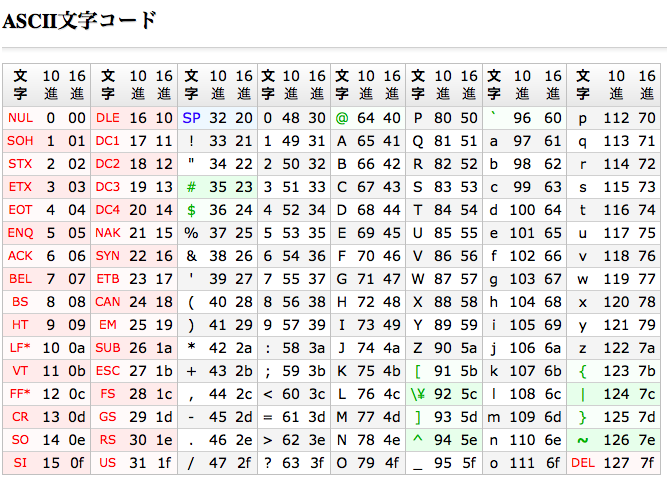
半角文字以外を検索
半角文字をASCII文字コード表のx01からx7Eまでとみなして、それ以外を検索する。
- 検索パターン:
[^\x01-\x7E]
5. 付録
正規表現と数学
- 1950年代、数学者クリーネが正規表現のモデルを考える
- 正規表現の研究は、有限オートマトンの研究と密接に紐づいていた。
正規表現とワイルドカードの違い
ワイルドカードは、検索などグロブ(英語版)の際に指定するパターンに使用する特殊文字の種類で、どんな対象文字、ないし文字列にもマッチするもののことである。カードゲームのワイルドカードに由来する呼称。
-
Windowsコマンドプロンプト
-
*: 任意の長さの文字 -
?: 任意の1文字
-
-
SQLのWHERE句 LIKE演算子
-
%: 任意の長さの文字 -
_: 任意の1文字
-
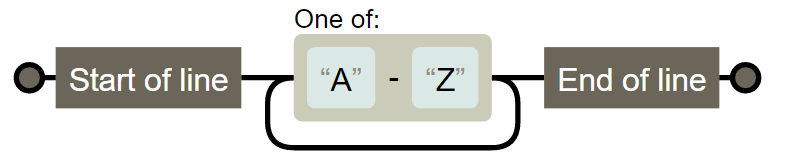
正規表現の可視化ツール
- Regexper : オートマトンに変換
^[A-Z]+?$ を可視化