
はじめに
記憶を持たないはずのAIが、私を覚えている
LLM自体は記憶を持ちません。直前の会話で何を話したかを本当は「覚えていない」はずなのです。それなのに、ChatGPTのようなチャットアプリや最近のエージェントと会話すると、まるで相手が自分を覚えていてくれて、記憶を持っているかのように感じられます。自分に寄り添ってくれているとさえ感じることがあります。
記憶を持たないものの記憶を考える。この小さな矛盾を紐解いていくと、最近話題になっている「コンテキストエンジニアリング(Context Engineering)」が登場した必然性が見えてきます。LLM とチャットしているときの過去の会話の履歴や、LLM に調べものをしてもらいたいときに LLM に渡す参考情報、背景情報などのをコンテキストといいます。このコンテキスト(文脈情報)を、どの順序で、どれだけ LLM に渡すか。LLM アプリを作る人にとっては、プロンプトエンジニアリングに続く次のテーマとして注目されている考え方です。
そもそも、なぜコンテキストエンジニアリングや、その延長で語られるメモリーエンジニアリング(Memory Engineering)やハーネスエンジニアリング(Harness Engineering)などという発想が必要になったのでしょうか。その答えは、表題にある矛盾した表現「記憶を持たないLLMの記憶」の中にあります。
この記事で辿る道筋
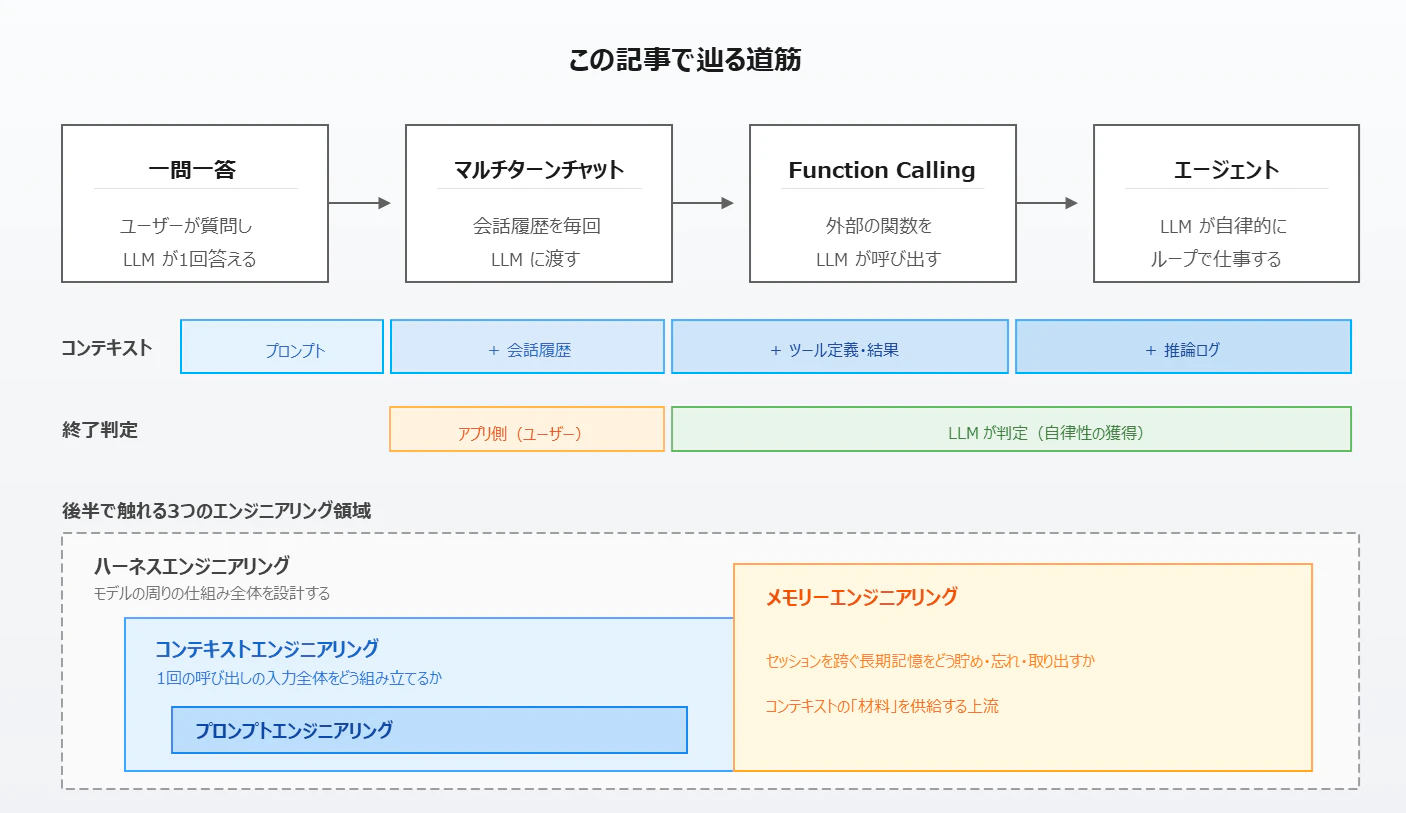
本記事では、LLM アプリをシンプルな「一問一答」形式のアプリケーションから、ユーザーと継続的に会話ができる「マルチターンチャット」、そして、外部環境(データベースや API サービス、ファイルシステムなど)から情報を取得したり、何らかの操作を実行できる「Function Calling」の仕組みを使ったアプリケーション、そして、人の代理人として自律的に仕事を行ってくれる「エージェント」という流れで辿りながら、この問いを考えてみたいと思います。ハウツーではなく、一緒に考える読み物のつもりで書きます。
主役はコンテキストエンジニアリングですが、後半ではその先にあるメモリーエンジニアリングやハーネスエンジニアリングにも少しだけ触れてみようと思います。また途中で「LLM は作るときは膨大なデータで学習するので、大きなデータを扱うのが得意そうに思えるのに、実際に使うときは少量のデータしか扱えず、その扱い方さえも不器用」という意外な弱点にも触れます。コンテキストを設計しなければならない根本の理由は、実はこの意外な弱点にあります。
この記事の図の読み方を開く
図の読み方 ~ どこが LLM の仕事か ~
各アプリケーション形式について、フローチャート(処理の流れ)とシーケンス図(登場人物のやりとり)の両方を載せていきますので、好きなほうから読んでください。終了条件を「誰が判定しているのか」にも、なるべく印を付けて進めます。
本記事の図では、「アプリ側が行う処理」と「LLM が行う処理」を一目で見分けられるように印を付けています。
- フローチャート ... ノード先頭に
【アプリ】または【LLM】と付け、LLM が行うノードは水色で塗ります - シーケンス図 ...
LLMの participant を水色の枠(box)で囲みます
LLM はあくまで「呼ばれたら推論して返す」だけの ステートレス(stateless) な存在です。ここで言うステートレスとは、推論リクエストと推論リクエストの間で状態(記憶)を保持しない という意味です。前回どんな質問を受けたか、どんな会話をしてきたかを、LLM 自身は一切覚えていません(なお、学習時に獲得した知識は当然保持されています。忘れるのはあくまで「実行時のやりとり」です)。それ以外(履歴の保持、ループ制御、ツール実行)はすべてアプリ側(またはサービス側)の仕事だ、という対比を、色と枠で可視化していきます。
一問一答形式のアプリケーション
最もシンプルな LLM アプリです。ユーザーが質問を入力する、それを指示(プロンプト)として LLM に渡す、返ってきた文字列をそのまま画面に表示する。以上です。
疑似コードで書くとおおよそこんな感じです。
疑似コードと実動作コードについて
本記事では、処理の流れを理解しやすくするために、LLM の呼び出しを llm() という関数で簡略化した疑似コードを使います。llm(messages) は「messages を LLM に渡して応答を得る」という意味だと思ってください。各セクションの折りたたみ内には、OpenAI 社が定めた chat.completions API 仕様に沿った実動作コードも載せています。この API 仕様は業界で広く採用されており、OpenAI社自身はもちろん、xAI、OCI Enterprise AI Models、Groq、ローカルで動かす Ollama など、多くのサービスが同じ形式(OpenAI互換API)で LLM を呼び出せるようにしています。実動作コードは api_key と base_url を差し替えるだけで、お使いの環境に合わせて動かせます。
msg = llm(
messages=[
{"role": "user", "content": "日本列島で最も大きな島の名前は?"},
]
)
print(msg.content)
このコードは説明用に簡略化した疑似コードです。
実動作コードでは、LLM としては xAI 社の grok-4-1-fast-reasoning を OCI Enterprise AI Models の OpenAI 互換エンドポイントで呼び出しています。
今後の説明は、疑似コードを元に進めますが参考までに実際に動作するコードの全体も載せておきます。OpenAI 互換APIで記述していますので、OpenAI社のAPIサービスはもちろんのこと、OCI Enterprise AI Models のような OpenAI互換APIをサポートするサービスでもこのまま実行することができます(適切な api_key と base_url を環境変数か .envファイルに設定する必要があります)。
一問一答の実際に動作するコード全体を開く
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
client = OpenAI(
api_key=os.environ["ENTERPRISE_AI_API_KEY"],
base_url=os.environ["ENTERPRISE_AI_BASE_URL"],
)
user_input = input("ユーザーメッセージ> ").strip()
response = client.chat.completions.create(
model="xai.grok-4-1-fast-reasoning",
messages=[
{"role": "user", "content": user_input},
],
)
print(response.choices[0].message.content)
疑似コードを見てみると、llm() を一度だけ呼んでいます。そして、引数の messages には、"日本列島で最も大きな島の名前は?" というユーザーの発言と、それがユーザーの発言であることを意味する情報("role": "user") 1 件だけが入っています。このユーザーの発言を LLM に送って返事を求めているわけです。
このプログラムを実行した様子はこちらです。
$ uv run 0000_chat_completions_simple_qa.py
ユーザーメッセージ> 日本列島で最も大きな島の名前は?
**本州(Honshu)**
日本列島の主要4島(北海道、本州、四国、九州)の中で、最も面積が大きいのは**本州**です。
### 面積比較(参考)
| 島名 | 面積 (km²) |
|----------|--------------|
| **本州** | 約227,960 |
| 北海道 | 約83,424 |
| 九州 | 約36,782 |
| 四国 | 約18,803 |
本州は人口も最多で、東京や大阪などの大都市を抱えています!
"日本列島で最も大きな島の名前は?" というユーザーの質問に対する LLM の回答が表示されています。
このアプリケーションは、LLM に質問して、その回答を表示するというシンプルなものですので、記憶は関係してきません。
今後の発展形のアプリケーションとの比較がし易いようにフローチャートとシーケンス図も載せておきます。
フローチャート(一問一答)
シーケンス図(一問一答)
過去のやりとりというものが存在しないので、一問一答の形式はとてもシンプルな仕組みです。
次に、この一問一答を2回続けて実行してみます。
一問一答を2回繰り返すコードの全体を開く
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
client = OpenAI(
api_key=os.environ["ENTERPRISE_AI_API_KEY"],
base_url=os.environ["ENTERPRISE_AI_BASE_URL"],
)
user_input = input("ユーザーメッセージ> ").strip()
response = client.chat.completions.create(
model="xai.grok-4-1-fast-reasoning",
messages=[
{"role": "user", "content": user_input},
],
)
print("LLMの1回目の応答:", response.choices[0].message.content)
print("--------------------------------")
user_input = input("ユーザーメッセージ> ").strip()
response = client.chat.completions.create(
model="xai.grok-4-1-fast-reasoning",
messages=[
{"role": "user", "content": user_input},
],
)
print("LLMの2回目の応答:", response.choices[0].message.content)
$ uv run 0050_chat_completions_simple_qa_twice.py
ユーザーメッセージ> 私の名前は山田太郎です
LLMの1回目の応答: はじめまして、山田太郎さん!
日本で一番ポピュラーな名前ですね(笑)。何かお手伝いできることありますか? 😊
--------------------------------
ユーザーメッセージ> 私の名前は?
LLMの2回目の応答: あなたの名前は、まだ教えてくれていませんよ!
教えてください、どんなお名前ですか? 😊
LLM は、ユーザーの最初の自己紹介も、LLM自身の返事も覚えていませんでした。シーケンス図も載せておきます。
LLM は、記憶を持たないことが確かめられました。LLM と文脈を保ちながら会話するためには工夫が必要なようです。
マルチターンチャット形式のアプリケーション
ChatGPT のブレイクで一気に広まったのが、マルチターンチャット形式の LLMアプリです。ユーザーと AI が交互に発話していく、あの馴染みのある使い方ですね。
ここで一つ立ち止まって考えてみてほしいのですが、「AI は前のターンのことを覚えている」ように見えるのはなぜでしょうか。
種明かしをすると、先程見たように LLM 自身は何も覚えていません。実際には、アプリケーション側が過去のやりとり(ユーザーの発言と AI の応答)をすべて会話履歴として保持しておき、次のターンで LLM を呼ぶときに、それらをまとめて渡しています。
以後、この記事で「会話履歴」と書いたときは、OpenAI 互換 API でいうところの messages 配列、つまり「system / user / assistant / tool といった役割ごとのメッセージ(contents)を時系列に並べた配列」のことだと思ってください。
マルチターンチャット形式のアプリケーションをコードで見ると次のようなイメージです。
messages = [
{"role": "system", "content": "あなたは親切なAIアシスタントです。名前は、青山アイです。"},
]
while True:
user_input = input("ユーザーメッセージ> ")
if user_input in ("quit", "exit"):
break # ユーザーが quit などと入力したら終了
# ユーザー発言を履歴に追加
messages.append({"role": "user", "content": user_input})
# 履歴全体を LLM に渡して返事を求める
msg = llm(messages)
# LLM の応答も履歴に追加
messages.append({"role": "assistant", "content": msg.content})
print(msg.content)
マルチターンチャットの実際に動作するコード全体を開く
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
client = OpenAI(
api_key=os.environ["ENTERPRISE_AI_API_KEY"],
base_url=os.environ["ENTERPRISE_AI_BASE_URL"],
)
messages = [
{"role": "system", "content": "あなたは親切なAIアシスタントです。名前は、青山アイです。"},
]
while True:
user_input = input("ユーザーメッセージ> ").strip() # ユーザー入力を待つ
if user_input.lower() in ("quit", "exit", "bye", "q"):
break # ← ループの終了条件はアプリ側(ユーザー入力)が握っている
# ユーザー発言を履歴に追加
messages.append({"role": "user", "content": user_input})
# 履歴全体を LLM に渡す
response = client.chat.completions.create(
model="xai.grok-4-1-fast-reasoning",
messages=messages,
)
assistant_text = response.choices[0].message.content
# AI の応答も履歴に追加
messages.append({"role": "assistant", "content": assistant_text})
print(f"\nAIアシスタントの応答> {assistant_text}\n")
このプログラムを実行して、AIアシスタントと会話した様子はこちらです。
$ uv run 0100_chat_completions_multi_turn.py
ユーザーメッセージ> 私の名前は山田太郎です。
AIアシスタントの応答> はじめまして、山田太郎さん!
青山アイです。よろしくお願いします♪
何かお手伝いできることありますか?
--------------------------------
ユーザーメッセージ> 私の名前は何でしたっけ?
AIアシスタントの応答> 山田太郎さんでしたよね?
忘れちゃいましたか?😊 何か他に聞きたいことありますか?
--------------------------------
ユーザーメッセージ>
山田太郎さんの自己紹介を覚えていてくれましたね!
さて、誰が覚えていたのでしょう。
ここで注目したいのは、messages というリストです。これは、ユーザーとLLMの会話の履歴を管理する変数です。
messages = [
{"role": "system", "content": "あなたは親切なAIアシスタントです。名前は、青山アイです。"},
]
このコードで、会話履歴の先頭にシステムプロンプトを設定しています。role が system となっていますね。
システムプロンプトというのは、AIの役割やパーソナリティ(キャラクター)を設定するものです。ここでは、青山アイという名前の親切なAIアシスタントとして振舞うように指示しています。
messages.append({"role": "user", "content": user_input})
このコードでは、ターミナルでユーザーが入力したメッセージを会話履歴 messages に追加しています。
先程の実行例のようにチャットの最初にユーザーが「私の名前は山田太郎です。」と入力したとすると messages の中身はこうなっています。
| 役割(role) | コンテンツ(content) | |
|---|---|---|
| 0 | system | あなたは親切なAIアシスタントです。名前は、青山アイです。 |
| 1 | user | 私の名前は山田太郎です。 |
そして、msg = llm(messages) で会話履歴の全体を LLM に渡して返事を求めます。ここで重要なのは、messages という会話履歴の全体を渡していることです。
先程の実行例では、LLMは「はじめまして、山田太郎さん!青山アイです。よろしくお願いします♪何かお手伝いできることありますか?」と応答しています。
そして、AIの応答を受け取ったチャットアプリケーションは、応答を会話履歴に追加します。
messages.append({"role": "assistant", "content": msg.content})
このコードで、LLMからの応答をrole に assistant を設定して、会話履歴 messages に追加しています。
このときの、会話履歴 messagesの中身はこうなっています。
| 役割(role) | コンテンツ(content) | |
|---|---|---|
| 0 | system | あなたは親切なAIアシスタントです。名前は、青山アイです。 |
| 1 | user | 私の名前は山田太郎です。 |
| 2 | assistant | はじめまして、山田太郎さん!青山アイです。よろしくお願いします♪何かお手伝いできることありますか? |
ここまでで、チャットの最初のターンが完了しました。コードの中では、while ループの先頭に戻ってユーザーの入力を求めています。
次に、先程の実行例では、ユーザーは「私の名前は何でしたっけ?」ととぼけたメッセージを入力しています。
このユーザーメッセージも会話履歴 messages に追加されて、このときの messages の中身は
| 役割(role) | コンテンツ(content) | |
|---|---|---|
| 0 | system | あなたは親切なAIアシスタントです。名前は、青山アイです。 |
| 1 | user | 私の名前は山田太郎です。 |
| 2 | assistant | はじめまして、山田太郎さん!青山アイです。よろしくお願いします♪何かお手伝いできることありますか? |
| 3 | user | 私の名前は何でしたっけ? |
となります。そして、この messages 全体が再び LLM へ送信されます。
実行例では、LLMは、「山田太郎さんでしたよね?忘れちゃいましたか?😊 何か他に聞きたいことありますか?」と応答しています。
このAIの応答もまたrole を assistant として、messagesへ追加されます。
| 役割(role) | コンテンツ(content) | |
|---|---|---|
| 0 | system | あなたは親切なAIアシスタントです。名前は、青山アイです。 |
| 1 | user | 私の名前は山田太郎です。 |
| 2 | assistant | はじめまして、山田太郎さん!青山アイです。よろしくお願いします♪何かお手伝いできることありますか? |
| 3 | user | 私の名前は何でしたっけ? |
| 4 | assistant | 山田太郎さんでしたよね?忘れちゃいましたか?😊 何か他に聞きたいことありますか? |
ユーザーと LLM の会話の記憶が会話履歴 messagesに記録されていっている様子がわかりますね。
フローチャート(マルチターンチャット)
シーケンス図(マルチターンチャット)
LLM は毎回、「今回の会話全体」をコンテキストとして受け取っています。ですから 2 ターン目以降を処理するときも、LLM は、「これまでにこんな会話があって、最後にこう聞かれた」という大きなひとつのコンテキストを受け取っているというわけです。LLM自体に記憶はないけれど過去の記録を受け取っているんですね。
記憶のように見えていた正体は、アプリケーション側が管理する「会話履歴」だったのです。
そして、もう1つここでの重要ポイントは、ループの終了条件を判定しているのは LLM ではなくアプリ側(ユーザーの入力)だということです。ユーザーが quit などのチャット終了の指示を入力するとアプリはチャットを終了します。LLM は依然として「呼ばれたら答える」だけの存在で、チャット終了の意思決定には関与していません。つまり、LLMは、ユーザーと会話したり質問に答えるインテリジェンスを提供していますが、自律性は持っていません。そして、この自律性を持った LLMアプリが後ほど登場するエージェントです。
「コンテキスト」という言葉の整理
「はじめに」でも触れましたが、ここで一度整理しておきます。本記事で「コンテキスト」と言うとき、それは 「LLM を 1 回呼び出すときに渡す入力全体」 を指します。OpenAI 互換 API で言えば messages 配列、つまり推論リクエストに乗せる情報すべてです。
マルチターンチャットの段階では、コンテキストは主に 2 つの要素から構成されています。
- システムプロンプト: エージェントの役割やキャラクター設定
- 会話履歴: ユーザー発言とアシスタント応答の積み重ね
このあと、記事が Function Calling、エージェントと進むにつれて、コンテキストの中身にはさらに別の要素が加わっていきます。「コンテキスト」という言葉の指す範囲は、アプリケーション形式が高度になるほど膨らんでいく、と覚えておいてください。記事の最後に「コンテキストに含まれるものの棚卸し」として全体像を表にまとめていますので、迷ったらそちらも参照してください。
記憶を司るもの、そしてハーネス

チャットでユーザーの名前を覚えていたのは、マルチターンチャット形式のアプリケーション側です。LLMではありませんでした。
ユーザーの名前は、チャットアプリケーション側で会話の履歴を管理している messages というリストに保存されていて、チャットアプリケーションが LLM を呼び出す度にこの messages という会話の履歴全体が推論リクエストで LLM に送られているのです。
つまり、LLMは、推論時には 何も記憶しない のです。記憶を持たない LLM の代わりに記憶を預かり、必要なときに LLM に渡してあげるのはアプリケーション側の仕事です。
記憶力ゼロの LLMには、付き人がいて、誰かに会う度に付き人が「AIさん、あなたは、以前、この方とお会いした時にこんな会話をしていました。覚えているふりをして会話を続けてください」とささやいているイメージです。この付き人のように、LLM 自体にはない機能を補って LLM を助ける仕組み全体のことを ハーネス(harness) と呼びます。ハーネスは英語で「馬具」のこと。馬の力を人が制御して活かすための装具が語源です。LLM という強力なエンジンに手綱や鞍を付けて実用に耐えるようにする仕組み、と捉えるとイメージしやすいかもしれません。記憶の管理はその主要な役割の一つで、後半で改めて取り上げます。
Function Calling を使ったアプリケーション
エージェントの話に入る前に、ぜひ知っておいた方がよい仕組みがあります。Function Calling(関数呼び出し)です。
マルチターンチャットまでは、LLM は「テキストを返すだけ」の存在でした。ここに、「必要なら、こちらが用意しておいた関数を呼んでくれ」と頼める仕組みを足したのが Function Calling です。どんなときに「関数の呼び出し」が必要になるかというと、LLMが知らない情報を必要としたときや外部に対して何か操作をする必要があるときです。前者は天気予報を取得してきたり、社内データベースにアクセスして昨日の売上データを取ってくるような場合です。後者は、ユーザーにメールを送信したり、データベースへ在庫補充のオーダーを登録したりといったことが考えられます。
仕組みとしては、アプリ側があらかじめ「こういう関数が使えるよ」というツール定義(tools)を LLM に渡しておきます。LLM が「この関数を呼びたい」と判断すると、応答の中にツール呼び出し指示(tool_calls)を返してきます。アプリはそれを見て実際の関数を実行し、結果をまた会話履歴に積んで LLM に戻す、という流れです。なお、ツール定義(tools)には、複数のツールを登録しておくことができますし、LLMもツール呼び出し指示(tool_calls)に複数のツールを指定して、複数のツールの呼び出しをアプリに要求することができます。
呼び方が色々ある件 ~ Tool Calling / Tool Use は同じもの ~
この仕組みは、AIモデルプロバイダや時期によって呼び方がまちまちです。よく見かけるのは次の3つです。
- Function Calling ... OpenAI が最初に導入したときの名前。今でも OpenAI のドキュメントで中心的に使われる呼び方です
- Tool Calling ... OpenAI の API 仕様としてはのちに
tools/tool_callsに整理されたこともあり、このフィールド名に揃えて Tool Calling と呼ばれることも多いです。LangChain などのフレームワークでもこの言い回しが主流です - Tool Use ... Anthropic Claude の API で採用されている呼び方です
どれも、「LLM にツール(関数)定義を渡しておき、必要に応じて LLM に呼び出し指示を返してもらう」という、ほぼ同じ仕組みを指しています。本記事では代表として Function Calling と書いていますが、Tool Calling や Tool Use と書かれていたら同じものだと読み替えていただいて構いません。
LLM が「自分で判断する」最初のステップ
LLM は、ユーザーの質問を見て、
- 自分の知識だけで答えられる場合は、普通の応答テキストを返す
- 外部の情報や処理が必要な場合は、どの関数を、どの引数で呼んでほしいかを構造化されたツール呼び出し指示(
tool_calls)として返す
という二択を取れるようになりました。
ここで初めて、LLM が「自分で判断するステップ」が登場します。具体的には、「これ以上のツール呼び出しが必要かどうか」を毎回 LLM 自身が判定するという考え方です。これが、後のエージェントの終了条件にもそのまま繋がってきます。
コードで書くとこんなイメージです。ここでは、天気を答えるダミー関数 get_weather を 1 つだけ用意しておき、LLM が必要と判断したら呼び出してもらう流れにします。
tools = [...] # get_weather(city) の定義(名前・説明・引数をJSON形式で宣言。詳細は後述の表を参照)
messages = [
{"role": "system", "content": "あなたは親切なAIアシスタントです。名前は、青山アイです。必要に応じてツールを呼び出して答えてください。"},
]
messages.append({"role": "user", "content": input("ユーザーメッセージ> ")})
# --- 1 回目の呼び出し(会話履歴 + ツール定義を渡す) ---
msg = llm(messages, tools)
messages.append(msg) # assistant メッセージ(tool_calls を含むことがある)を履歴に追加
if msg.tool_calls:
# LLM が「関数呼び出しが必要」と判定した場合
# → 指示されたツールをアプリ側で実行し、結果を履歴に追加する
for call in msg.tool_calls:
messages.append({
"role": "tool",
"tool_call_id": call.id,
"content": execute_tool(call), # アプリ側でツールを実行
})
# --- 2 回目の呼び出し(ツール結果を踏まえて最終応答を生成) ---
msg = llm(messages, tools)
messages.append(msg)
print(msg.content)
Function Calling の実際に動作するコードの全体を開く
import json
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
client = OpenAI(
api_key=os.environ["ENTERPRISE_AI_API_KEY"],
base_url=os.environ["ENTERPRISE_AI_BASE_URL"],
)
# --- ダミーのツール本体(リテラルから情報を返すだけのシンプル版) ---
WEATHER_DB = {
"東京": {"weather": "雨", "temperature_c": 10, "precipitation_mm": 10},
"大阪": {"weather": "曇り", "temperature_c": 17, "precipitation_mm": 0},
"札幌": {"weather": "雪", "temperature_c": 1, "precipitation_mm": 5},
}
def get_weather(city: str) -> dict:
return WEATHER_DB.get(city, {"error": f"{city} の天気データは登録されていません"})
# --- LLM に渡すツール定義 ---
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "指定された都市の現在の天気・気温・降水量を返す",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "都市名(例: 東京)"},
},
"required": ["city"],
},
},
},
]
# --- ツール呼び出し指示を実行するディスパッチャ ---
def dispatch_tool(tool_call) -> str:
name = tool_call.function.name
args = json.loads(tool_call.function.arguments)
print(f"[tool call] name={name}, args={json.dumps(args, ensure_ascii=False)}")
if name == "get_weather":
result = get_weather(args["city"])
else:
result = {"error": f"未知のツール: {name}"}
return json.dumps(result, ensure_ascii=False)
# --- 会話履歴の初期化 ---
messages = [
{
"role": "system",
"content": (
"あなたは親切なAIアシスタントです。"
"名前は、青山アイです。"
"必要に応じてツールを呼び出して答えてください。"
)
},
]
user_input = input("ユーザーメッセージ> ").strip()
messages.append({"role": "user", "content": user_input})
# --- 1 回目の呼び出し ---
print("[LLM call]")
response = client.chat.completions.create(
model="xai.grok-4-1-fast-reasoning",
messages=messages,
tools=tools,
)
msg = response.choices[0].message
messages.append(msg) # assistant(tool_calls 含む)を履歴に追加
if msg.tool_calls:
# LLM が「関数呼び出しが必要」と判定 → 実行して結果を履歴に追加
for call in msg.tool_calls:
result_json = dispatch_tool(call)
messages.append({
"role": "tool",
"tool_call_id": call.id,
"content": result_json,
})
# --- 2 回目の呼び出し(ツール結果を踏まえて最終応答を生成) ---
print("[LLM call]")
response = client.chat.completions.create(
model="xai.grok-4-1-fast-reasoning",
messages=messages,
tools=tools,
)
msg = response.choices[0].message
messages.append(msg)
print(f"\nAIアシスタントの応答> {msg.content}\n")
このプログラムを実行した様子はこちらです。
$ uv run 0200_chat_completions_function_calling.py
ユーザーメッセージ> 東京の今の天気を教えて。
[LLM call]
[tool call] name=get_weather, args={"city": "東京"}
[LLM call]
AIアシスタントの応答> 東京の今の天気は**雨**です。気温は**10℃**、降水量は**10mm**です。外出の際は傘をお忘れなく!😊
見た目は普通のチャットと同じですが、裏では LLM が 2 回呼ばれ、間にツール呼び出しが挟まっています。messages の中身がどう積み上がっていくかを追いかけてみましょう。
マルチターンチャットと違うのは、llm() に会話履歴 messages だけでなく、使えるツールの一覧 tools も一緒に渡している点です。今回使えるツールは get_weather 1つだけで、定義の中身は次の通りです。
| ツールの名前 | ツールの説明 | パラメータ |
|---|---|---|
| get_weather | 指定された都市の現在の天気・気温・降水量を返す | "city": "都市名(例: 東京)"(必須) |
LLM は、この説明を読んでツールがどのような場合に役立つかを理解し、必要に応じてツール呼び出しを要求できるようになります。引数(パラメータ)の定義も渡されるので、LLM はユーザーの発言から引数の値を組み立てて呼び出しを指示します。
実行例のように「東京の今の天気を教えて。」と入力された直後の messages はこうなっています。
| 役割(role) | コンテンツ(content) | tool_calls | |
|---|---|---|---|
| 0 | system | あなたは親切なAIアシスタントです。名前は、青山アイです。必要に応じてツールを呼び出して答えてください。 | ― |
| 1 | user | 東京の今の天気を教えて。 | ― |
ここで 1 回目の msg = llm(messages, tools) を実行すると、注目したいのは、LLM の返事が「いつものテキスト」ではないことです。get_weather を city="東京" で呼んでほしい、という構造化された指示(tool_calls)だけが返ってきて、content は空になります。この tool_calls を含んだアシスタントメッセージを、そのまま messages に追加します。
| 役割(role) | コンテンツ(content) | tool_calls | |
|---|---|---|---|
| 0 | system | あなたは親切なAIアシスタントです。名前は、青山アイです。必要に応じてツールを呼び出して答えてください。 | ― |
| 1 | user | 東京の今の天気を教えて。 | ― |
| 2 | assistant | (空) |
get_weather(city="東京") を呼び出す指示 |
ちなみに、もし、ユーザーのメッセージが「あなたのお名前は?」だったら LLM は、システムプロンプトで与えられた自分の名前を答えれば良いのでツールが呼び出されることはなく「青山アイです! よろしくお願いします♪」などの応答が返ってきます。つまり、tools を設定して LLM に推論を要求したからといって LLM が必ずツールの呼び出しを指示するわけではありません。あくまでも、ユーザーの要求に応えるために必要な場合にだけツール呼び出しの指示が返って来ます。
次に、アプリ側で実際に get_weather("東京") を実行します(疑似コードの execute_tool(call) の部分)。今回は単なるリテラルの辞書引きなので、{"weather": "雨", "temperature_c": 10, "precipitation_mm": 10} が返ってきます。
ここで重要なのは、ツール結果を会話履歴に追加するときの role が tool になっていることです。user でも assistant でもない、新しい役割です。ツールの実行結果であることを表しています。これで messages の中身はこうなります。
| 役割(role) | コンテンツ(content) | tool_calls | |
|---|---|---|---|
| 0 | system | あなたは親切なAIアシスタントです。名前は、青山アイです。必要に応じてツールを呼び出して答えてください。 | ― |
| 1 | user | 東京の今の天気を教えて。 | ― |
| 2 | assistant | (空) |
get_weather(city="東京") を呼び出す指示 |
| 3 | tool | {"weather": "雨", "temperature_c": 10, "precipitation_mm": 10} |
― |
そして、ツールの実行結果を元に最終的な回答を生成してもらうために、2 回目の msg = llm(messages, tools) を実行します。今度はツールの実行結果まで含んだ messages 全体が渡ります。
LLM は、会話履歴の末尾にある role=tool のメッセージを「get_weather を呼んだ結果」として読み取り、それを自然な日本語にまとめ直して返してきます。今度は LLM からの通常の(Function Calling ではない)応答ですので、tool_calls が空となり、content に最終応答テキストが入ります。それを履歴に追加すると、最終的な messages はこうなります。
| 役割(role) | コンテンツ(content) | tool_calls | |
|---|---|---|---|
| 0 | system | あなたは親切なAIアシスタントです。名前は、青山アイです。必要に応じてツールを呼び出して答えてください。 | ― |
| 1 | user | 東京の今の天気を教えて。 | ― |
| 2 | assistant | (空) |
get_weather(city="東京") を呼び出す指示 |
| 3 | tool | {"weather": "雨", "temperature_c": 10, "precipitation_mm": 10} |
― |
| 4 | assistant | 東京の今の天気は雨です。気温は10℃、降水量は10mmです。外出の際は傘をお忘れなく! 😊 | ― |
重要
マルチターンチャットのときと同じで、LLM は相変わらず何も記憶していません。2 回目のリクエストで LLM が「東京は雨」と答えられるのは、ユーザーの質問と、それに対して自分が get_weather ツールの呼び出しを指示したことを LLM が覚えていたからではなく、アプリケーション側が管理している会話履歴 messages(システムプロンプト + ユーザー発言 + 1 回目のツール呼び出し指示 + ツール結果)を丸ごと受け取って、最終回答を推論しているからです。
記憶力ゼロの LLM が、付き人(アプリケーション)から「あなたはさっき get_weather を引数に"東京"を指定して呼び出して欲しいと言いました。その結果はこうです。続きを答えてください」と渡されているイメージです。
フローチャート(Function Calling)
シーケンス図(Function Calling)
ツールを呼び出すかどうかの分岐そのものはアプリ側で実行されます。しかし、その分岐がどちらに進むかは、LLM が応答としてツール呼び出し指示を返すかどうかで決まります。「分岐を実行するのはアプリ、どちらに進めむべきかを決めるのは LLM」という構図です。
ここで、指定されたツールの実行結果が回答生成のために十分ではないと LLM が判定する可能性があります。つまり、上のシーケンス図の ”「これ以上の呼び出しは不要」と LLM が判定” が、更にツール呼び出しが必要という判定になってツール呼び出し指示が再び返される可能性があります。例えば、「東京の今日の天気を教えて。もし、雨だったら明日の天気も教えて。」と聞かれたら。それがエージェント型のアプリケーションへの橋渡しになります。
ちょっとした寄り道 ~ 出力側にも落とし穴がある ~
この節のひとこと要約
LLMは「長い文章を正確にそのままコピーする」のが意外と苦手です。そのため、Function Calling で大きなデータ(長文、巨大なCSV、長いHTMLなど)をツール引数として LLM に生成させようとすると、途中で切れたり壊れたりしやすい、という落とし穴があります。対策は「大きなデータ本体は LLM を経由させず、ファイルパスや ID だけを受け渡す」ことです。
この節は少し技術的に踏み込むので、なぜそうなるのかの仕組みに興味がなければ、この要約だけ記憶に留めていただいて次の節に進んでいただいても大丈夫です。
ここまでは「何をコンテキストに入れて LLM に渡すか」という入力側の話ばかりしてきました。ですが、Function Calling ではもう一つ、出力側にも注意しておきたい落とし穴があります。それは、LLM にツール呼び出し要求 tools_callsを生成させるときに、引数に大きなデータを設定させようとすると失敗しやすい、という問題です。
よくあるのは、たとえばこんなシナリオです。
- 「10 万字文字の文章を丸ごとこのツールに渡してレビューさせたい」
- 「DB から取り出した巨大な CSV をそのままツール引数としてファイルへ書き込む関数に流し込みたい」
- 「長い XML/HTML を LLM に整形し直させて、構造化されたツール引数として出力させたい」
こういう使い方をすると、ツール呼び出しが途中で切れる、ツール呼び出し要求 tools_callsのJSON が閉じきらない、一部が脱落する、といった症状が高確率で発生します。私自身も、AIエージェントと Oracle AWR — 大きな結果セットをコーディングエージェントに渡したいときの TIPS で、AWR レポートのような数十万文字級の出力を LLM を経由してファイル書き込ませようとすると、先頭だけ書かれて切れる、ツール呼び出し自体が失敗する、といった現象に悩まされた話を書きました。
これは個別の不具合ではなく、エージェント開発では広く知られた実用上の落とし穴です。
私も括弧を閉じ忘れるといったミスを頻繁に犯しますが、LLM も同様です。
なぜ大きな出力が苦手なのか
理由はいくつか重なっていますが、代表的なものを整理すると次のようになります。ざっくり言えば「LLM は一文字ずつ左から右へ順番に文字を吐き出す装置」なので、長く吐けば吐くほどどこかで間違える確率が積み上がる、というのが根っこの理由です。
| 観点 | 何が起きるか |
|---|---|
| 出力トークン上限 | 入力は 100K〜1M トークン取れても、1 回の生成で出せる出力は数 K〜数十 K トークンに制限されるのが普通。途中で finish_reason=length となって JSON/XML が未完のまま止まる |
| 自己回帰生成のエラー蓄積 | LLM はトークンを 1 つずつ左から右に生成する。各ステップの誤り確率を ε とすると、N トークン連続で形式的に正しく出せる確率はざっくり (1−ε)^N で減衰する。JSON のように「一文字でも壊れたら全体が無効」な出力では、長くなるほど破綻率が指数的に上がる |
| 構造整合性は「学習された偏り」頼み | トランスフォーマーには括弧を閉じ忘れない・エスケープを揃えるといった構造保証のメカニズムは内蔵されていない。カッコのバランスや引用符の対応は、すべて学習分布からの確率的な回収に依存している |
| 逐語コピーは Attention の苦手分野 | Attention は「関連情報を重み付けで混ぜる」のは得意だが、「長い区間をそのまま 1 トークンずつ忠実に写経する」のは不得意。似た行に飛んで重複が出たり、行が脱落したり、空白が変わったりする |
| Lost in the Middle の出力版 | 長い入力の中央を参照し損ねる問題は、「長い入力を忠実に出力に写し取る」タスクでもそのまま効いてくる |
| ツール引数は訓練分布から遠い | ツール引数は自然文ではなく厳密な JSON/XML 文字列で、しかも学習データ中の分布が自然文よりずっと薄い。長くなるほど訓練分布から外れていき、破綻しやすくなる |
この問題はベンダー側も正面から認識していて、OpenAI の Structured Outputs や Anthropic の fine-grained tool streaming など、構造化出力(JSONなどを期待したフォーマットで正しく出力すること)を安定させるための仕組みが次々と出てきています。(詳細は気にしなくて構いません。「各社ともこの問題に対策を打ち出している」くらいの理解で十分です。) とはいえ、OpenAI のドキュメントにも「Structured Outputs can still contain mistakes(構造化出力にも依然として間違いが含まれ得る)」「max_tokens 到達時にはスキーマに合う完全な応答が得られないことがある」と明記されている通り、形式保証はかなり改善できても、大きい出力に伴う途中切れや内容誤りは実用上の課題として残り続けています。研究面でも、Berkeley Function Calling Leaderboard (BFCL) や JSONSchemaBench のように、Function Calling や構造化出力の難しさを独立した評価対象として扱うベンチマークが整備されつつあります。
大ざっぱな整理ですが、LLM は「意味を保ちながら要約・変換・整形する」のは得意でも、「巨大なペイロードを損失なく中継する信頼できる輸送路」として使うのはあまり得意ではない、と言ってよさそうです。
ベストプラクティス ~ LLM をバイト中継器にしない ~
そこで、エージェント設計側のベストプラクティスとしては、「大きなデータは LLM を経由させない」ということになります。具体的には次のような原則です。
- ツールは、データ本体ではなく「データの場所」を返す(ファイルパス、オブジェクト ID、URL、一時ストレージ参照など)
- 大きな入力を次のツールに渡したいときも、参照 ID やファイルパスを受け渡し、実体はツール間でファイルシステムや DB 経由で流す
考え方としては、「LLM には意味判断と指示出しだけを任せて、実際の大容量 I/O はツール側とアプリ(ハーネス)側で回す」という分業です。前掲の AWR レポートの記事でデータベース接続用のMCPツールを使わずに CLI にレポートを直接ファイルに書き出させ、LLM にはファイルパスだけを返しているのも、この分業の一つの形です。
入力と出力、どちらも非対称であるということ
のちほど「ちょっとした寄り道 ~ AI(LLM) は膨大な情報を処理する装置ではないということ ~」で、LLM は「作るときはビッグデータ、使うとき(推論時の入力)はスモールインプット」という非対称を持つという話をします。そこに、もう一つの非対称を並べて覚えておいてください。
- 入力側の非対称 ~ 学習時は Web スケール、推論時の入力はコンテキストウィンドウに制限される
- 出力側の非対称 ~ 推論時の入力は数十万〜数百万トークン取れても、1 回の出力はその数十分の一以下に制限される
コンテキストエンジニアリングやハーネスエンジニアリングの設計判断は、この「入力側の有限性」と「出力側の有限性」の両方を踏まえて初めて筋が通ります。どこまでを LLM に読ませ、どこからを LLM に書かせないか、という線引きも、エンジニアリグの主要テーマの一つです。
エージェント型のアプリケーション
先程のサンプルコードでは、最大で一度の Function Calling を行って、その結果が十分でも不十分でも、例え呼び出されたツール(アプリ側では関数として実装されている)がエラーであったとしても通り抜けて終了してしまう構造でした。
これを、LLMが満足するまで Function Calling の終了条件判定(「もうツールは要らないか」)を、ループの中で何回でも繰り返せるようにすると、それがエージェントになります。
LLM がツールを呼ぶ → 結果が返る → それを踏まえてまた LLM を呼ぶ → さらに別のツールを呼ぶ……。これを「LLM がツール呼び出し指示を返さなくなる」まで続けるのが、エージェントループです。
ここでも、LLM 自身は記憶を持たないステートレスのままです。ただ、アプリ側が記憶(状態)として保持すべきものは一気に増えます。
具体的には、次のようなものが「コンテキスト」として、エージェントループの中で膨らみながら LLM に渡されていきます。
- システムプロンプト(system prompt)
- ユーザーとのこれまでの会話履歴(messages)
- LLM が呼び出したツールの種類と引数(ツール呼び出し指示、tool_calls)
- そのツールからの応答(ツール結果、tool results)
- LLM の途中の推論ログ(reasoning)
コードで書くとこんなイメージです。Function Calling のサンプルとよく似ていますが、ループがあることが本質的な違いです。今回はツールを 2 つ、現在の天気を返す get_weather と、翌日の降水予報を返す get_forecast にします。
# ツール定義(今回は 2 つ用意)
# - get_weather(city): 今日の天気を返す
# - get_forecast(city): 翌日の天気を返す
tools = [...] # 定義の詳細は折りたたみコードを参照
messages = [
{"role": "system", "content": "...必要に応じてツールを呼び出してください"},
]
messages.append({"role": "user", "content": input("ユーザーメッセージ> ")})
# ========================================
# ここからがエージェントの本体 = ループ
# ========================================
# マルチターンチャット: ループの終了条件はユーザー(quit入力)
# Function Calling : ループなし、最大1回のツール呼び出しで終了
# エージェント(ここ) : ループの終了条件は LLM 自身が決める ← 自律性
while True:
msg = llm(messages, tools)
messages.append(msg)
# ★終了条件: LLM が「もうツールは要らない」と判定したらループを抜ける
if not msg.tool_calls:
break
# LLM が指示したツールを順に実行し、結果を履歴に追加してループ継続
for call in msg.tool_calls:
messages.append({
"role": "tool",
"tool_call_id": call.id,
"content": execute_tool(call),
})
print(msg.content)
エージェントの実際に動作するコード全体を開く
import json
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
client = OpenAI(
api_key=os.environ["ENTERPRISE_AI_API_KEY"],
base_url=os.environ["ENTERPRISE_AI_BASE_URL"],
project=os.environ["ENTERPRISE_AI_PROJECT_ID"],
)
# --- ダミーのツール本体(リテラルから情報を返すだけ) ---
WEATHER_DB = {
"東京": {"weather": "雨", "temperature_c": 10, "precipitation_mm": 10},
"大阪": {"weather": "曇り", "temperature_c": 17, "precipitation_mm": 0},
"札幌": {"weather": "雪", "temperature_c": 1, "precipitation_mm": 5},
}
FORECAST_DB = {
"東京": {"weather": "晴れ", "precipitation_probability": 0},
"大阪": {"weather": "曇り", "precipitation_probability": 20},
"札幌": {"weather": "雪", "precipitation_probability": 70},
}
def get_weather(city: str) -> dict:
return WEATHER_DB.get(city, {"error": f"{city} の天気データは登録されていません"})
def get_forecast(city: str) -> dict:
return FORECAST_DB.get(city, {"error": f"{city} の予報データは登録されていません"})
# --- LLM に渡すツール定義 ---
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "指定された都市の現在の天気・気温・降水量を返す",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "都市名(例: 東京)"},
},
"required": ["city"],
},
},
},
{
"type": "function",
"function": {
"name": "get_forecast",
"description": "指定された都市の翌日の天気と降水確率(%)を返す",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "都市名(例: 東京)"},
},
"required": ["city"],
},
},
},
]
def dispatch_tool(tool_call) -> str:
name = tool_call.function.name
args = json.loads(tool_call.function.arguments)
print(f"[tool call] name={name}, args={json.dumps(args, ensure_ascii=False)}")
if name == "get_weather":
result = get_weather(args["city"])
elif name == "get_forecast":
result = get_forecast(args["city"])
else:
result = {"error": f"未知のツール: {name}"}
return json.dumps(result, ensure_ascii=False)
# --- 会話履歴の初期化 ---
messages = [
{"role": "system", "content": "あなたは親切なAIアシスタントです。名前は、青山アイです。必要に応じてツールを呼び出して答えてください。"},
]
user_input = input("ユーザーメッセージ> ").strip()
messages.append({"role": "user", "content": user_input})
# --- エージェントループ ---
while True:
print("[LLM call]")
response = client.chat.completions.create(
model="xai.grok-4-1-fast-reasoning",
messages=messages,
tools=tools,
)
msg = response.choices[0].message
messages.append(msg) # assistant(tool_calls 含む)を履歴に追加
if not msg.tool_calls:
break # ← LLM が「もうツールは要らない」と判定 → 終了条件成立
for call in msg.tool_calls:
result_json = dispatch_tool(call)
messages.append({
"role": "tool",
"tool_call_id": call.id,
"content": result_json,
})
print(f"\nAIアシスタントの応答> {msg.content}\n")
実行結果はこんな感じになります。
$ uv run 0300_chat_completions_agent.py
ユーザーメッセージ> 東京の今日の天気を教えて。もし、雨だったら明日の天気も教えて。
[LLM call]
[tool call] name=get_weather, args={"city": "東京"}
[LLM call]
[tool call] name=get_forecast, args={"city": "東京"}
[LLM call]
AIアシスタントの応答> 東京の今日の天気は、**雨**です。気温は10℃、降水量は10mmとなっています。雨なので、明日の天気もお伝えしますね!
**明日の天気**: 晴れ、降水確率0%です。
お出かけの参考にどうぞ! 😊
エージェントループの中では LLM が 3 回、ツールが 2 回呼ばれています。messages がどう積み上がっていくかを、ループの 1 周ごとに追いかけてみましょう。
その前に、ツールの定義(tools)です。
今回は、ツールの定義 tools には、2つのツール get_weather (今日の天気を返すツール)と get_forecast (翌日の天気を返すツール)が定義されています。Function Calling の節と同じ形式です。
まずスタート時点の会話履歴です。システムプロンプトとユーザー発言が入っています。
| 役割(role) | コンテンツ(content) | tool_calls | |
|---|---|---|---|
| 0 | system | あなたは親切なAIアシスタントです。名前は、青山アイです。必要に応じてツールを呼び出して答えてください。 | ― |
| 1 | user | 東京の今日の天気を教えて。もし、雨だったら明日の天気も教えて。 | ― |
ループ 1 周目
msg = llm(messages, tools) で、get_weather と get_forecast の 2 つのツールが利用可能であることを伝えつつ、LLM に推論を要求します。
LLM は「まず今日の天気が必要だ」と判断し、get_weather(city="東京") を呼んでほしいという tool_calls を返してきます。content は空のままです。アプリはその指示を履歴に追加し、ツールを実行して結果を履歴に追加します。
| 役割(role) | コンテンツ(content) | tool_calls | |
|---|---|---|---|
| 0 | system | あなたは親切なAIアシスタントです。名前は、青山アイです。必要に応じてツールを呼び出して答えてください。 | ― |
| 1 | user | 東京の今日の天気を教えて。もし、雨だったら明日の天気も教えて。 | ― |
| 2 | assistant | (空) |
get_weather(city="東京") を呼び出す指示 |
| 3 | tool | {"weather": "雨", "temperature_c": 10, "precipitation_mm": 10} |
― |
ループ 2 周目
ここが先程の単純な Function Calling アプリケーションとの大きな違いです。今日の天気が雨だということはわかりましたが、ユーザーは「もし、(今日が)雨だったら明日の天気も教えて」と聞いているので、2 周目の msg = llm(messages, tools) で LLM は「明日の情報が必要だ、もう 1 つツールを呼ぼう」と判定します。今度は get_forecast(city="東京") を呼ぶ指示が返ってきます。アプリはまた履歴に追加し、ツールを実行して結果を追加します。
| 役割(role) | コンテンツ(content) | tool_calls | |
|---|---|---|---|
| 0 | system | あなたは親切なAIアシスタントです。名前は、青山アイです。必要に応じてツールを呼び出して答えてください。 | ― |
| 1 | user | 東京の今日の天気を教えて。もし、雨だったら明日の天気も教えて。 | ― |
| 2 | assistant | (空) |
get_weather(city="東京") を呼び出す指示 |
| 3 | tool | {"weather": "雨", "temperature_c": 10, "precipitation_mm": 10} |
― |
| 4 | assistant | (空) |
get_forecast(city="東京") を呼び出す指示 |
| 5 | tool | {"weather": "晴れ", "precipitation_probability": 0} |
― |
ループ 3 周目 ~ 終了条件の成立 ~
3 周目の msg = llm(messages, tools) で、LLM は「今日の天気と明日の予報が両方そろった。もうツールは要らない」と判定し、tool_calls を返さずに content として最終応答テキストを返してきます。疑似コードの if not msg.tool_calls: break が成立し、ループを抜けます。最終的な messages はこうなります。
| 役割(role) | コンテンツ(content) | tool_calls | |
|---|---|---|---|
| 0 | system | あなたは親切なAIアシスタントです。名前は、青山アイです。必要に応じてツールを呼び出して答えてください。 | ― |
| 1 | user | 東京の今日の天気を教えて。もし、雨だったら明日の天気も教えて。 | ― |
| 2 | assistant | (空) |
get_weather(city="東京") を呼び出す指示 |
| 3 | tool | {"weather": "雨", "temperature_c": 10, "precipitation_mm": 10} |
― |
| 4 | assistant | (空) |
get_forecast(city="東京") を呼び出す指示 |
| 5 | tool | {"weather": "晴れ", "precipitation_probability": 0} |
― |
| 6 | assistant | 東京の今日の天気は、雨です。気温は10℃、降水量は10mmとなっています。雨なので、明日の天気もお伝えしますね! 明日の天気: 晴れ、降水確率0%です。 お出かけの参考にどうぞ! 😊 |
― |
重要
ここでも、LLM は 1 回も記憶を保持していません。messages は 7 行まで膨らんでいますが、育てているのはあくまでアプリ側(ハーネス側)です。LLM からすれば、3 回とも「自分自身は過去の記憶を持たずに呼ばれて、渡された履歴を見て次の一手を決めた」に過ぎません。
しかし、単なるFunction Calling を使ったAIアプリケーションとは大きな違いがあります。処理の完了を判定するのが LLM になったという点です。つまり、ユーザーのリクエストを解決するまで、与えられたツールを駆使してLLMは自律的にタスクを実行するようになりました。
フローチャート(エージェント)
シーケンス図(エージェント)
クライアント側でループを回す代わりに、OpenAI Responses API や OCI Enterprise AI Agents の Agentic API のように、サービス側で提供しているツールを呼び出すループの場合は、サービス側でループも回してくれる API もあります。ただし、どちらの場合も、LLM 自身が毎回ステートレス(自分自身は記憶を持たず)に呼ばれている点は変わりません。「ループの終了条件を LLM が判定する」という構造もそのままです。誰がループを管理するか、誰がコンテキストを保持するかが違うだけです。
なお、会話履歴については、Responses API/Agentic API場合もアプリケーション側で会話履歴を管理してAPIに渡して上げることもできますし、サービス側の短期記憶機能を活用することでもできます。
この会話履歴(内部的には messages 配列)こそが、エージェントの「記憶」の正体です。ユーザーと AI のやりとりに加えて、ループの中で発生したツール呼び出しとその結果が積み重なっていきます。
エージェントループの中身を覗く
エージェントが 1 回の応答を返すまでに、会話履歴がどのくらい膨らんでいるかは、コードからは見えにくいものです。そこで役立つのがトレーシングです。前回の記事では、OCI Enterprise AI Agents のエージェントに LangSmith のトレーシングを追加する方法を紹介していますので参考にしてみてください。
前回の記事 ー OCI Enterprise AI Agents で LangSmith トレーシングを使ってみた!
矛盾の解決 ~ 記憶しているのは誰か ~
ここまで辿ってくると、冒頭の記憶を持たないはずの LLM が記憶を持っているように見えるという矛盾に対する答えが見えてきます。各節でその答えの断片には既に触れてきましたが、ここで全体像を一度整理しておきたいと思います。
LLM は本当に自分自身の記憶を持たず、前の会話のことを何も覚えていません。それでも私たちが AI と会話して「文脈を分かっている」と感じるのは、アプリケーション側(あるいはサービス側)が会話履歴やツール呼び出し結果を蓄え、毎回 LLM の入力としてまとめ直して渡しているからです。
言い換えると、こういうことです。
- LLM は、毎回、与えられたコンテキストだけを見て答える「一問一答の装置」である
- 記憶のように見えるものの実体は、アプリ側が管理する「会話履歴 + ツール履歴」である
- マルチターンもエージェントも、「毎回その時点のコンテキストを作り直して LLM に渡す」という処理のループである
- ループの終了は、マルチターンチャットアプリは、ユーザーが決める(exit するなど)が、エージェントでは LLM 側が判定する(自律性)
つい LLM を擬人化して「彼は前回の会話を覚えている」と表現したくなりますが、技術的には「アプリがせっせと会話履歴を作り直して渡している」と言ったほうが正確です。
ちょっとした寄り道 ~ AI(LLM) は膨大な情報を処理する装置ではないということ ~
ここで、よくある AI の誤解にも触れておきたいと思います。
映画などに登場する「人類を滅ぼす AI」や「あらゆる情報を瞬時に処理する万能 AI」は、ものすごく大量のデータをリアルタイムに取り込んで、人間には見つけられない情報・結論を一瞬で導き出す、といった描かれ方をすることが多いですね。犯罪に手を染めたり、戦争を仕掛けたりする AI たちは、たいていこの路線で描かれます。
しかし、実際の(少なくとも現在の)LLM は、だいぶ違う存在です。
AI を「作る」ときには、たしかに膨大なデータと計算資源が必要です。インターネット上のテキスト、コード、書籍など、途方もない量のデータを事前学習として流し込み、モデルが作られます。
一方、AI を「使う」とき、つまり推論時に一度に受け取れる入力の量はずっと限られています。コンテキストウィンドウと呼ばれる上限があり、どれだけ大きいモデルでも、一度に扱えるのは書籍数十冊分くらいまでです。しかも、長いコンテキストをすべて等しく使いこなせるわけでもなく、真ん中あたりの情報を見落としやすいといった傾向も報告されています(Lost in the Middle: How Language Models Use Long Contexts, arXiv:2307.03172)。イメージとしては、100ページの仕様書を LLM に読ませて「重要な制約を教えて」と聞いたとき、冒頭の数ページと末尾の数ページに書かれた制約は拾えるのに、50ページあたりに埋もれている制約は見落としがち、という感じです。 情報システムのログであれば、数千行のログを LLM に貼り付けて「エラーの原因を探して」と頼んだとき、最初の方と最後の方のエラーメッセージは的確に拾うのに、途中のほうに出ていた決定的な一行を見落とす、といった挙動として現れることもあります。本記事の文脈で言えば、マルチターンチャットが長く続いたとき、ユーザーが「最初のほう」と「直近」で話した内容は覚えていても、会話の中盤で伝えた重要な前提条件を LLM が忘れたように振る舞う、というのが典型的な現れ方です。この Lost in the Middle(真ん中で迷子になる問題)は、1Mトークンを超えるようなコンテキストウィンドウを持つ LLM が登場する中で、既に解決されていると宣伝されることがあります。確かに、この論文で当初報告されたような真ん中あたりの情報を見つけることができないという極端な問題は軽減されています。しかし、入力コンテキストが大きいとLLMの推論でその情報を十分に活用できないという問題やユーザーの要求と関係のない情報のノイズがあった場合に能力が低下していまうといった問題自体は、いまだにエージェントなどのLLMを使ったアプリケーション開発の主要な課題として残っています。コンピューターの(物理的な)メモリーは、容量いっぱいにデータを書き込んでも、どこにデータを置いても、近くに無関係な情報があっても、そのすべてを等しく完全に利用することができますが、LLM のコンテキストウィンドウはそうではないということは覚えておいた方がいいですね。
つまり、
- 作るときはビッグデータ
- 使うときはスモールインプット、かつ不完全にしか利用できない
- しかも使うときの「出力」は、その入力よりもさらに制約が大きい
というギャップが、現実の LLM にはあるのです。Function Calling の節で触れた「大きなペイロードを LLM に生成させると壊れやすい」という話は、この出力側の制約の大きさと自己回帰生成の弱さが重なって起きていました。
| 局面 | 必要なデータ量 | 取り込み方 |
|---|---|---|
| 学習時 | 途方もなく多い(Webスケール) | 事前に全部流し込む |
| 推論時の入力 | 限定的(コンテキストウィンドウ、数十万〜百万トークン程度) | 1 回ごとに渡し直す |
| 推論時の出力 | さらに限定的(入力の数十分の一程度、数 K〜数十 K トークン) | 1 回ごとに自己回帰的に生成 |
この推論時の入出力両方の制約を覚えておくと、次の節で話す「コンテキストをどう設計するか」の重みが少し変わってきます。
もうひとつの寄り道 ~ コンテキストは「量」だけでなく「質」も問題になる ~
上の寄り道では、コンテキストウィンドウの容量や出力トークン数といった「量」の制約を見てきました。しかし実は、コンテキストには「質」の問題もあります。何でもいいからたくさん入れれば LLM が賢くなるわけではなく、中身の質が悪いと、量が十分でも出力はおかしくなります。
こうしたコンテキストの質に起因する失敗は、まとめて Context Fails と呼ばれることがあります。LLMの活用の現場で報告されている代表的なパターンをいくつか紹介します。
矛盾する情報の共存(Context Clash)
コンテキストの中に互いに矛盾する情報があると、LLM はどちらを採用すべきか判断できなくなります。たとえば、RAG で古い仕様書と新しい仕様書が同時に検索結果として取り込まれたり、マルチターンチャットの途中で前提条件が変わったのに、古い前提が会話履歴に残り続けたりすると、回答が二転三転したり、古い情報に基づいた誤った結論を出したりします。
ノイズや無関係な情報の混入(Context Pollution / Context Distraction)
必要な情報がコンテキストの中にあっても、周囲にノイズや無関係な情報が多すぎると、LLM の焦点がぼけてしまいます。エージェントが試行錯誤する中で蓄積された失敗ログがそのまま「有効な履歴」として残っていたり、会話中の雑談がメモリーに保存されていたりすると、本来のタスクへの集中を妨げます。「情報を増やせば賢くなる」のではなく、「無関係な情報は積極的に害になる」というのが、LLM のコンテキストの厄介なところです。
参考:ReAct を蝕むコンテキスト汚染(Context Pollution)
タスク境界の曖昧化(Context Confusion)
エージェントが複数のタスクを順番にこなしているとき、前のタスクの文脈が残ったまま次のタスクに入ると、「いまどのタスクの話をしているのか」がモデルにとって曖昧になります。マルチエージェント構成では、あるエージェントが出した中間的な仮説を、別のエージェントが確定事実として受け取ってしまうこともあります。これも、コンテキストの「中身の整理」が不十分なために起きる問題です。
誤情報の残留と増幅(Context Poisoning)
もっとも厄介なのが、誤った情報がコンテキストに入り込み、それが「事実」として参照・再利用されることで、誤りが雪だるま式に増えていくパターンです。たとえば、会話履歴を要約する処理で誤った要約が生成されると、その要約が次の要約の入力になり、元の会話とはかけ離れた「事実」が作られてしまいます。さらにセキュリティの観点では、外部ドキュメント経由で悪意ある情報をエージェントの長期メモリに書き込み、以後のセッションを汚染し続けるという攻撃手法も報告されています。
コンピューターの(物理的な)メモリーは、どんなデータを書き込んでも他のデータを壊しませんし、ゴミデータが隣にあっても必要なデータを正確に読み出せます。しかし LLM のコンテキストでは、矛盾・ノイズ・誤情報といった「質の問題」が、モデルの推論そのものを歪めてしまいます。前の寄り道で見た「量」の制約と、ここで見た「質」の制約。この両面があるからこそ、コンテキストに何を入れ、何を入れないかという「設計」が重要になってくるのです。
特にエージェントでは、この問題の影響が一段深くなります。先ほど見たように、エージェントでは「もうタスクは完了した」という終了判定を LLM 自身が行います。そしてその判定の根拠もまたコンテキストです。コンテキストが汚染されていれば、回答の質が落ちるだけでなく、タスクが中途半端なまま打ち切られたり、逆に終わらないループに陥ったりと、タスク全体の成否にまで波及しかねません。
矛盾の解決のその先
このギャップを踏まえると、「記憶しているのは誰か」という問いの先に、もう一段問いが出てきます。
コンテキストウィンドウは有限です。アプリ側が抱えている会話履歴やツール応答を、すべてそのまま詰め込めるとは限りません。会話が長くなれば、古いやりとりを間引いたり、要約したり、別の記憶領域に追い出したりする必要が出てきます。
そして、入れすぎれば見落とされ、削りすぎれば文脈が崩れる。どちらも困るのです。
そして、コンテキストエンジニアリングへ
ここまで来ると、「コンテキストエンジニアリング」という言葉の意味が少し腑に落ちてきます。
LLM の「記憶」の実体はアプリ側で構成される「コンテキスト」であり、そのコンテキストにはかなり限られた長さしか与えられていない。さらに、何を入れるかによって LLM の振る舞いが大きく変わる。だとすれば、そのコンテキストを「設計」する仕事は、もうプロンプト(指示)を書くことだけでは済まなくなってきます。
たとえば、具体的には次のような問いが、開発者側の設計・エンジニアリングのテーマとなります。
- システムプロンプトにどこまで書くか
- 会話履歴をどこまで残し、どこからを要約に置き換えるか
- RAG でどのチャンクを取りに行き、どれを捨てるか、どの順序でコンテキストに配置するか
- ツール定義やツール応答を、どの粒度でコンテキストに残すか
- 推論ログ(reasoning)や中間ログを次のターンに持ち越すか、それとも切り捨てるか
プログレッシブディスクロージャーという考え方
箇条書きの一番上に挙げた「システムプロンプトにどこまで書くか」は、実は一見するよりずっと奥の深い問いです。エージェントに覚えさせたい指示やノウハウをすべてシステムプロンプトに詰め込んでしまうと、どんな質問が来ても毎ターン同じ巨大な前置きを LLM に読ませることになります。コンテキストウィンドウを圧迫するうえ、前述の「真ん中で迷子になる問題」の影響も受けやすくなります。
そこで最近注目されているのが、必要になったときに必要な指示だけを読み込ませる、プログレッシブディスクロージャー(progressive disclosure、段階的開示)という考え方です。Anthropic が提唱している Agent Skills はその代表例で、スキルごとに SKILL.md のようなファイルを用意しておき、システムプロンプトにはスキルの一覧と短い説明だけを載せておきます。エージェントは、ユーザーの要求を見て「これは docx スキルが必要そうだ」と判断したときに初めて、その SKILL.md の中身を読み込んでコンテキストに加えます。
見方を変えると、システムプロンプトを「index(目次)」と「body(本文)」に分け、本文の読み込みを実行時の判断に委ねている、とも言えます。アプリ側の仕組みに「必要なときに必要な指示を差し込む機構」を組み込むことで、毎ターンのコンテキストを軽く保ちつつ、いざというときの指示の厚みは失わない、という両取りを狙っているわけです。
この発想は Agent Skills に限った話ではありません。RAG でのドキュメント検索、ツール定義の動的な絞り込み、長期記憶からの抜粋なども、広く見れば「何を常駐させ、何を必要時に取りに行くか」というプログレッシブディスクロージャーの一種だと整理できます。
「ツール定義の動的な絞り込み」については、Oracle が紹介している Semantic Tool Memory というパターンが分かりやすい実装例です。数百あるツールをあらかじめベクトルストアに索引化しておき、推論時にユーザーの要求とセマンティック検索で照らし合わせて、関連するツールだけを tools に載せて LLM に渡す、というやり方です。ツールの呼び方(引数の組み立て方)という「手続き的な知識」を、コンテキストの中ではなく外部記憶に置いておいて、必要になったときに検索で取りに行く。こう見ると、Agent Skills の SKILL.md を動的に差し込む発想と、本質的には同じ形をしていることが分かります。
これらをまとめて考える領域が、コンテキストエンジニアリングと呼ばれているものだと理解すると、だいぶ整理が着くのではないでしょうか。
表形式に整理しておきますね。
| アプリケーション形式 | アプリが管理するコンテキストの主な中身 | 終了条件を判定するのは | コンテキストエンジニアリングの主な関心事 |
|---|---|---|---|
| 一問一答 | 今回のプロンプトのみ | ループなし | プロンプトの書き方(プロンプトエンジニアリング) |
| マルチターンチャット | 会話履歴 | アプリ側(ユーザー入力) | 履歴の保持・要約・切り詰め |
| Function Calling | 会話履歴 + ツール呼び出し指示 + ツール応答 | LLM(ツール呼び出し指示の有無) | ツール定義と応答の粒度設計 |
| エージェント | 会話履歴 + ツール呼び出し指示 + ツール応答 + 推論ログ | LLM(ループ内で繰り返し判定) | 何を詰め、何を捨て、何を外部記憶に逃がすか |
アプリケーションが高度になるほど、コンテキストの構成要素は増え、扱う設計の自由度も、事故る可能性も増えていきます。だからこそ、手法論に入る前にいったん「LLM 自身は何も覚えていない」「終了の意思決定が LLM 側に移ってきた」という出発点に立ち返っておくと、全体の見通しがずいぶん良くなります。
発展的な話題 ~ メモリーエンジニアリングとの関係 ~
ここ最近、コンテキストエンジニアリングと並んで「メモリーエンジニアリング(Memory Engineering)」という言葉も耳にするようになってきました。せっかくなので、両者の関係にも少し触れておきたいと思います。
そもそも、何が違うのか
ここまで話してきた「コンテキスト」は、基本的には「今このセッション(会話)の中で、LLM に渡している入力」の話でした。会話履歴、ツール定義、ツール呼び出し指示と結果、推論ログ……これらはすべて、今このターンの入力をどう組み立てるかに関わります。つまり、短期記憶の話しでした。
一方、メモリーエンジニアリングは、もう少し長いタイムスケールを扱います。セッションを跨いで、ユーザーやエージェントにとって意味のある情報をどう残し、どう取り出すか。平たく言えば「エージェントの長期記憶をどう設計するか」という話です。
たとえば、以下のような情報は、その場の会話履歴に埋めっぱなしにするよりも、外部の記憶として明示的に管理した方が扱いやすくなります。
- ユーザーの名前、言語、好み、過去の質問傾向
- エージェントが過去に成功した手順、失敗した手順
- プロジェクト固有の用語集、ドメインルール
- 別のスレッドで起きた出来事の要約
記憶の種類 ~ よく引き合いに出される分類 ~
人間の認知科学から借りてきて、エージェントの記憶も次のように分類されることがあります。
| 種別 | 中身のイメージ | エージェントでの例 |
|---|---|---|
| エピソード記憶(Episodic) | いつ、誰と、何があったかの個別の出来事 | 「昨日、このユーザーからこういう質問を受けて、こう答えた」 |
| 意味記憶(Semantic) | 世界や自分についての一般化された知識 | 「このユーザーは日本語で、丁寧な口調を好む」 |
| 手続き記憶(Procedural) | やり方・手順 | 「このツールを呼ぶときの引数の組み立て方」「よくある不具合の対処手順」 |
この分類は、本記事のような解説だけの話ではなく、実際のエンタープライズ製品の設計の骨格としてもそのまま使われています。Oracle が 2026 年に発表した Oracle AI Agent Memory のドキュメントでも、エージェントに持たせるメモリーをセッションの間継続する「working memory(タスクコンテキスト、会話ステート、サマリー)」と「long-term factual memory(ユーザーの好み、学習済みルール、過去の成果)」の2層に整理したうえで、格納する実体は上の意味記憶・エピソード記憶・手続き記憶の区別に沿ってベクトル/リレーショナル/グラフ/JSON を使い分ける、という設計になっています。認知科学由来の分類は、抽象的なお題目ではなく、実装の型としても定着しつつあると見てよさそうです。
これらをどう貯め、どう忘れ、どう思い出させるか。そこを工夫する領域が、メモリーエンジニアリングだと考えるとイメージがつきやすくなります。
具体的には、次のような処理の組み合わせとして現れます。「生の会話やツール出力から、名前・好み・学んだ事実といった構造化情報を抽出する(extraction)」「時系列に積み上がったエピソード記憶を、重複を畳んで意味記憶にまとめ直す(consolidation)」「エージェント自身が後から自分の記憶を書き換えたり、矛盾する古い知識を整合させたりできるライトバックループを作る」といった流れです。
コンテキストエンジニアリングとの関係
両者は対立するものではなく、むしろ補完関係にあります。
- メモリーエンジニアリングは、セッションをまたぐ長期記憶を「どう貯め、どう忘れ、どう検索するか」を設計する
- コンテキストエンジニアリングは、その長期記憶から必要なものを取り出し、会話履歴やツール応答と合わせて「今このターンにどう組み立てるか」を設計する
という分担だと捉えると、整理しやすくなります。
| 観点 | コンテキストエンジニアリング | メモリーエンジニアリング |
|---|---|---|
| 主なタイムスケール | 1 ターン〜1 セッション | セッション横断・長期 |
| 扱うデータ | 会話履歴、ツール定義、ツール応答、推論ログ | ユーザープロファイル、エピソード、手順、ドメイン知識 |
| 主な関心事 | コンテキストウィンドウへの詰め方 | 記憶の保存・要約・忘却・検索 |
| 位置づけ | 下流(消費側) | 上流(供給側) |
実装としては、ベクトル DB や KV ストアに出し入れする「外部記憶」と、それを毎ターンどう引くかの「リトリーバ」、そして取ってきた記憶をコンテキストに溶け込ませる「アセンブラ」のような役割分担になります。Letta(旧 MemGPT) や LangGraph の LangMem といったフレームワークは、このあたりをまとめて扱おうとしている例です。
もう一つ、アプローチの軸が異なる例として押さえておきたいのが、データベース統合型の Oracle AI Agent Memory です。Letta や LangMem がアプリケーション側のフレームワークとして記憶を扱うのに対して、Oracle は「エージェントの記憶は、エンタープライズデータが既に居る場所と同じ場所に置くべきだ」という立場を取っています。具体的には、ベクトル・JSON・グラフ・リレーショナルを単一エンジン(converged database)で扱える Oracle AI Database の上に、メモリー管理専用の Python SDK(Oracle AI Agent Memory SDK for Python)を載せる構成です。意味記憶・エピソード記憶・手続き記憶をバラバラのストアに分散させると、「データの同期」「アクセス制御の二重管理」「ライフサイクル管理の不整合」といった問題がついて回ります。これを 1 つのプラットフォームに寄せてしまおう、というわけです。ブログの中に「Agent memory is the next system of record that matters.(エージェントの記憶は、次の "システム・オブ・レコード" になる)」という表現が出てくるのが印象的で、エンタープライズの世界では記憶そのものが基幹データと同格の扱いになりつつあることがうかがえます。
記憶を外部化すると、今度は記憶自体のガバナンスという別の宿題もついてきます。会話から抽出された個人情報の扱い、GDPR/CCPA 的な削除要求、外部入力による「記憶汚染(memory poisoning)」、バックアップとリカバリといった話です。本記事ではこれ以上踏み込みませんが、後でハーネスエンジニアリングの節で触れる「ガードレール」「権限制御」「ロギング」といった論点が、記憶を外に持たせた瞬間にそのまま記憶側にも降ってくる、ということは押さえておいてください。Oracle の主張のように「データベースで既にやっている権限制御とライフサイクル管理を、そのまま記憶にも適用する」という考え方はその一つの答えです。
コンテキストエンジニアリングとメモリーエンジニアリングについてまとめると「毎ターンのコンテキストの中身を設計する技術」、メモリーエンジニアリングはさらにその「材料となる長期記憶を設計する技術」、と理解することができます。
さらにその先 ~ ハーネスエンジニアリングという広がり ~
コンテキストエンジニアリングとメモリーエンジニアリングの話まで来ると、もう一つ、最近よく耳にするようになった言葉に触れておきたくなります。「ハーネスエンジニアリング(Harness Engineering)」です。
Agent = Model + Harness
ハーネス(harness)はもともと「馬具」や「装具」を意味する言葉です。AI エージェントの文脈では、2026年初頭ごろから次のような定義で使われるようになりました。
エージェントとは、モデルとハーネスの組み合わせである(Agent = Model + Harness)。ハーネスとは、エージェントを構成する要素のうち「モデルそのもの以外のすべて」を指す。
具体的には、本記事で「アプリ側の仕事」として整理してきたものが、ほぼそのままハーネスの担当範囲になります。
- ツール定義の管理とツール実行
- 短期記憶(会話履歴やツール結果の保持、要約、コンパクション)
- 長期記憶(セッションを跨いだ状態の永続化)
- エージェントループの駆動と停止条件の判定補助
- ガードレール、権限制御、リトライ
- ロギング、トレーシング、評価(eval)
本記事のフローチャートで言えば、水色で塗った【LLM】のノード以外のすべて(灰色の【アプリ】ノード群)が、ハーネスと呼ばれている領域だと思ってください。「LLM 自身は何も覚えていない」「終了の意思決定をしているのは誰か」と問い続けてきた答えの "誰か" には、実は最近こういう名前が付いた、というわけです。
また、さきほどプログレッシブディスクロージャーとして紹介した『必要なときに必要な指示を差し込む仕組み』も、実はハーネスが担う典型的な仕事の一つです。
4つの「エンジニアリング」の包含関係
プロンプト、コンテキスト、メモリー、ハーネスの四つは、対立概念ではなく入れ子・補完の関係として整理されることが多いです。
| 用語 | 守備範囲 | ひとことで言うと |
|---|---|---|
| プロンプトエンジニアリング | 1 回の入力テキストの書き方 | モデルに何を聞くか |
| コンテキストエンジニアリング | 1 回の呼び出しの入力全体(会話履歴・ツール定義・ツール応答・推論ログ・外部記憶からの抜粋など)の組み立て方 | モデルに何を渡すか |
| メモリーエンジニアリング | セッションを跨ぐ長期記憶(エピソード・意味・手続き記憶)の貯め方・忘れ方・取り出し方 | モデルに何を覚えさせるか |
| ハーネスエンジニアリング | モデルの周りの仕組み全体(ループ、ツール、状態、長期記憶、ガードレール、評価まで) | モデルの周りをどう設計するか |
おおまかには「プロンプト ⊂ コンテキスト ⊂ ハーネス」という入れ子関係が軸になります。メモリーエンジニアリングはこの図の中では少し特殊な位置づけで、コンテキストの「上流(材料の供給元)」として働きながら、実装上はハーネスの中の「長期記憶」担当パートとしても位置づけられる、という橋渡し役です。本記事で辿ってきた「一問一答 → マルチターン → Function Calling → エージェント」という進化は、見方を変えれば「ハーネスがどんどん厚くなり、その中で長期記憶というレイヤーが独立した名前を持ち始めた歴史」そのものでもあります。
本記事の主役はあくまでコンテキストエンジニアリングなので、ハーネスエンジニアリングそのものの各論にはこれ以上踏み込みません。ただ、「LLM の記憶の正体はモデルの外側にある」という本記事の結論が、そのまま「だからモデルの外側=ハーネス全体を設計する必要がある」という次の問いに繋がっていく、ということだけ書き添えておきます。コンテキストエンジニアリングやメモリーエンジニアリングの各論を読み進めていく中で「これは結局ハーネスのどの部分の話なんだろう?」と一段上から眺める視点を持っておくと、迷子になりにくいと思います。
まとめ
最後に、本記事の流れを振り返っておきます。
| 観点 | 要点 |
|---|---|
| LLM の前提 | LLM 自体はステートレスで、何も記憶していない |
| 一問一答 | そもそも記憶もループも存在しなかった |
| マルチターンチャット | アプリ側が会話履歴(messages)を管理し、毎ターンその全体を LLM に渡すようになった。ループの終了条件もアプリ側にあった |
| Function Calling(Tool Calling / Tool Use も同義) | 「もう関数呼び出しは要らない」という終了条件を LLM 自身が判定するようになった |
| エージェント | Function Calling の判定を毎ターン繰り返すループに拡張したものとして理解できる |
| 「記憶」の正体 | LLM の中ではなく、アプリ側にある |
| コンテキストの制約(入力側) | LLM に一度に渡せるコンテキストには有限の上限があり、使いこなし方にもクセがある |
| 出力側の制約 | 特に Function Calling では、大きなペイロードを LLM に生成させると途中で壊れる・切れるという実務上の落とし穴がある。データ本体は LLM を経由させず、ツール側のファイル出力や参照 ID で受け渡すのがセオリー |
| コンテキストエンジニアリング(Context Engineering) | 何をどう渡すか、さらに何を LLM に書かせないかを設計する、という発想が必要になった |
| メモリーエンジニアリング(Memory Engineering) | セッションを跨ぐ長期記憶の設計という、さらにその先の領域として整理されつつある |
| ハーネスエンジニアリング(Harness Engineering) | コンテキストエンジニアリングもメモリーエンジニアリングも、より広い「Agent = Model + Harness」という枠組みの一部として位置づけられつつある |
コンテキストに含まれるものの棚卸し
エージェントまで進んだ段階で、1 回の LLM 呼び出しに渡す「コンテキスト」には、おおむね次のような要素が入っています。初出の整理も兼ねて、日本語と API などで使われる英語名を並べておきます。
| 日本語名 | 英語名 (API上の表現) |
中身 |
|---|---|---|
| システムプロンプト | system prompt | エージェントの役割や方針、制約 |
| 会話履歴 | messages | ユーザー発言とアシスタント応答の時系列、必要に応じて要約 |
| ツール定義 | tools | 呼び出せる関数の仕様(名前、引数、スキーマ) |
| ツール呼び出し指示 | tool_calls | LLM が「この関数を呼びたい」と返した指示 |
| ツール結果 | tool results / role=tool のメッセージ | 呼び出した関数の実行結果 |
| 推論ログ | reasoning | モデルが出す中間的な思考過程(モデルや API により扱いは異なる) |
| 外部記憶から引いてきた情報 | retrieved memory | RAG のヒットチャンクや、長期記憶からの抜粋 |
コンテキストエンジニアリングは、この「どれを」「どの粒度で」「どの順で」詰め込むかを設計する営みであり、メモリーエンジニアリングはそのうち「外部記憶から引いてくる材料」をどう貯めて、どう忘れて、どう取り出すかを設計する営みだ、と位置づけておくと頭が整理しやすくなりますね。
Context Fails の棚卸し
そして、本記事の途中で触れたように、コンテキストは「量」だけでなく「質」の面でも落とし穴を抱えています。コンテキストの質に起因する代表的な失敗パターン(Context Fails)を改めて整理しておきます。
| パターン | 何が起きるか | 典型的な発生場面 |
|---|---|---|
| Context Clash(矛盾) | 互いに矛盾する情報が共存し、LLM がどちらを採用すべきか判断できなくなる | RAG で新旧の仕様書が同時にヒットする、会話途中で前提が変わったが古い前提が履歴に残る |
| Context Pollution / Distraction(汚染・注意散漫) | ノイズや無関係な情報が多すぎて、本来のタスクへの焦点がぼける | エージェントの失敗ログが有効な履歴として残る、会話中の雑談がメモリーに保存される |
| Context Confusion(混乱) | タスクの境界が曖昧になり、「いま何の話をしているか」がモデルにとって不明確になる | 複数タスクを順番にこなす中で前のタスクの文脈が残る、マルチエージェント間で仮説が確定事実として伝搬する |
| Context Poisoning(毒入れ) | 誤った情報がコンテキストに残留し、参照・再利用されるうちに誤りが増幅する | 要約の誤りが次の要約に波及する、外部ドキュメント経由で悪意ある情報が長期メモリに書き込まれる |
コンテキストに「何を入れるか」の棚卸しと、「入れ方を間違えると何が起きるか」の棚卸し。この二つを揃えて眺めると、コンテキストエンジニアリング・メモリーエンジニアリング・ハーネスエンジニアリングという3つの領域が、それぞれ何に対処しようとしているのかが見えてきました。コンテキストエンジニアリングは、毎ターンの入力を適切に組み立てることで Context Fails を防ぐ。メモリーエンジニアリングは、長期記憶の貯め方・忘れ方を設計することで、汚染された記憶が将来のコンテキストに混入するのを防ぐ。そしてハーネスエンジニアリングは、ツール管理やループ制御からガードレール・評価に至るまで、モデルの周りの仕組み全体を設計することで、Context Fails が実害に至る前に食い止める。三つは別々の技術ではなく、同じ問題を異なるレイヤーから押さえているということが見えて来ましたね。
本記事で繰り返し問いかけてきた「終了の意思決定をしているのは誰か」も、ここに繋がっています。終了判定を LLM に委ねたエージェントでは、Context Fails は単なる回答ミスにとどまらず、タスクの早期打ち切りや無限ループといった形でタスク全体を台無しにしかねません。だからこそ、コンテキストの設計が「回答の質を上げるためのコツ」ではなく「エンジニアリング」と呼ばれるようになったのだと思います。
コンテキスト/メモリー/ハーネスエンジニアリングの各論に踏み込む前に、「LLM は何も覚えていない」「記憶しているのは誰か」「終了の意思決定をしているのは誰か」という素朴な問いを振り返って再確認しておくと、あとから出会うテクニックや用語の輪郭が、ぐっと理解しやすくなるのではないでしょうか。
この記事がその準備運動になれば嬉しいです。
参考リンク
- 前回の記事 ー OCI Enterprise AI Agents で LangSmith トレーシングを使ってみた!
- Lost in the Middle: How Language Models Use Long Contexts (arXiv:2307.03172)
- OpenAI Responses API
- OpenAI Function Calling ガイド
- Anthropic Claude Tool Use ガイド
- OCI Enterprise AI Agents
- MemGPT: Towards LLMs as Operating Systems (arXiv:2310.08560)
- Letta(旧 MemGPT) ー LLM のための長期記憶フレームワーク
- LangMem ー エージェントのための記憶管理ライブラリ
- Introducing Oracle AI Agent Memory: A Unified Memory Core for Enterprise AI Systems
- Agent Memory: Why Your AI Has Amnesia and How to Fix It (Oracle Developers Blog)
- Agent Memory: Building Memory-Aware Agents (Oracle × DeepLearning.AI 短期コース)
- The Anatomy of an Agent Harness (LangChain Blog)
- Effective harnesses for long-running agents (Anthropic)
- Introducing Agent Skills
- AIエージェントと Oracle AWR — 大きな結果セットをコーディングエージェントに渡したいときの TIPS
- Introducing Structured Outputs in the API (OpenAI)
- Structured model outputs (OpenAI API docs)
- Fine-grained tool streaming (Anthropic Claude API docs)
- The Berkeley Function Calling Leaderboard (BFCL)
- Repeat After Me: Transformers are Better than State Space Models at Copying (arXiv:2402.01032)
- The Pitfalls of Next-Token Prediction (PMLR)
- Tokenization Falling Short: On Subword Robustness in Large Language Models (arXiv:2406.11687)
- Interpreting the Repeated Token Phenomenon in Large Language Models (arXiv:2503.08908)
- 【Developers Summit 2026】Memory Is All You Need