はじめに
この記事は「ドローン空撮画像を洪水判定してみる(Cohere Multimodal Embed 3)- ゼロショット編」の続編です。

前回の記事では、Cohere Multimodal Embed 3 を使ったゼロショットアプローチでドローン空撮画像の洪水判定にチャレンジしました。結果は、実際に浸洪水であるデータのうち、どれくらい見逃さずに洪水と予測できたかを表す 再現率(Recall)は 92.9%と高い値を示しましたが、適合率(Precision)は43.9%に留まりました。これは「浸水でないものを誤って浸水とみなす(False Positive)」割合が高いことを意味しています。そこで、この記事では、再現率(Recall)は維持しながらも誤検知を減らすための改善にチャレンジしてみました。
この記事では、Cohere Multimodal Embed 3 で生成した画像埋め込みベクトルを線形分類器に入力して訓練することにより、精度向上を図る方法を紹介します。この記事で取り上げている洪水検出のような場合は「見逃し」が重大な問題となるため、再現率(Recall)は引き続き重視しつつも適合率(Precision)を上げて誤検知を減らすことに焦点を当てています。
なお、こちらの内容は、ウェビナー【Oracle AI JAM Session #23 生成AIを活かすには埋め込みの理解から!RAGの心臓:埋め込みの基礎から応用まで!】(2025年3月26日)
及び以下のブログで概要をご紹介しているものの詳細となります。
結果概要

線形分類器を用いた精度向上アプローチの結果は以下の通りです。
| 指標 | ゼロショット | 線形分類器(F2最適化) | 改善率 |
|---|---|---|---|
| 正解率(Accuracy) | 0.8111 | 0.9489 | +16.99% |
| 適合率(Precision) | 0.4000 | 0.7571 | +89.29% |
| 再現率(Recall) | 0.8814 | 0.8983 | +1.92% |
| F1スコア | 0.5503 | 0.8217 | +49.33% |
| F2スコア | 0.7104 | 0.8660 | +21.91% |
※ゼロショットの値が前の記事と若干異なっているのは、分類対象としたデータが若干異なるためです。今回の測定結果はゼロショットと線形分類器(F2最適化)の2つの手法で同じデータを分類したものです。
注目ポイント
- 適合率(Precision)が89.29%向上し、0.7571になりました。これは誤検知(False Positive)が大幅に減少したことを意味します
- 再現率(Recall)も性能を維持、もしくは、若干向上しており、洪水を検知できています
- F1スコアが49.33%向上し、0.8217になりました。バランスの取れた性能向上を示しています
アプローチ
前回の記事では、ゼロショットアプローチとして以下の手順を試してみました。
- 画像の埋め込みベクトルを生成
- 分類クラスのキャプション埋め込みベクトルを生成
- コサイン類似度を計算して分類(コサイン類似度が高いクラスへ分類)
つまり、空撮画像の埋め込みベクトルが「この画像は洪水地域のものです」と「この画像は洪水地域のものではありません」の埋め込みベクトルのどちらに近いかで洪水を判定しました(実際にはテキストは英語にしています)。
今回は、このアプローチを拡張し、以下の手順を試してみます。
- 画像の埋め込みベクトルを生成
- 分類クラスのキャプション埋め込みベクトルを生成
- 画像埋め込みベクトルに対して線形分類器をトレーニング
- F2スコアを最大化するハイパーパラメータを探索
- 最適化されたモデルで予測を実施
F2スコアを用いる理由は、洪水検出においては「見逃し」(偽陰性、False Negative)を最小化することが重要だと考えたからです。今回の精度向上編の動機は誤検知を少なくする(適合率を上げる)ことなのですが、やはりこの見逃しを最小化することは犠牲にできないという判断です。F2スコアは再現率をより重視した評価指標で、以下の式で計算されます。
F2 = 5 x (Precision * Recall) / (4 x Precision + Recall)
環境とデータセット
前回の記事と同様に、FloodNet Datasetを使用しています。コードは以下のGitHubリポジトリで公開しています(前回記事のノートブックと名前が同じものがありますが、内容は異なっています)。
事前準備は前回記事と変わりませんので、そちらも参考にしてみてください。
線形分類器のトレーニング
データの準備
前回記事では、FloodNet Dataset の訓練データ(datasets/floodnet/FloodNet-Supervised_v1.0/train) 1445 件をゼロショットで分類しましたが、今回は、この訓練データは、線形分類器の訓練に使用し、テストデータ(datasets/floodnet/FloodNet-Supervised_v1.0/test)をモデル選択時の検証に、評価データ(datasets/floodnet/FloodNet-Supervised_v1.0val)を最終的な評価に使用します。
下記の3つのノートブックを先頭から最後まで実行して、3つのデータセットに対する正解ラベル、画像埋め込みベクトル、ゼロショットのベースラインを生成します。この3つノートブックはターゲットのデータセットを上記のとおりに変更していますが、処理内容は前回記事と変わりませんので、そちらも参考にしてみてください。
- 正解ラベルの生成:100_generate_image_labels.ipynb
- 画像の埋め込みベクトルの生成:200_generate_image_embeddings.ipynb
- ゼロショットによるベースライン測定:300_classify_image.ipynb
線形分類器のトレーニングと評価(F2スコア最適化)
モデル選択とハイパーパラメータ最適化
今回は2つの線形分類器を検討しました。
- ロジスティック回帰
- 線形SVM
この2モデルに対してF2スコアを最大化するためのハイパーパラメータをグリッドサーチで最適化しました。
クラス重み(class_weight)と正則化パラメータ(C)を幅広く探索することで、偏ったデータセット(洪水画像が非洪水画像よりも少ない)に対しても良いパフォーマンスを実現することを目指しました。
最適モデルの選択
グリッドサーチの結果から、最もF2スコアの高いモデルを選択し、テストデータで評価しました。
トレーニングと評価の実行
400_train_linear_classifier_f2.ipynb を先頭から最後まで実行します。
画像埋め込みベクトルの読み込み
最初に200_generate_image_embeddings.ipynbで生成した画像埋め込みベクトルを読み込みます。
訓練データ数: 1445
検証データ数: 448
評価データ数: 450
埋め込みベクトルの次元: 1024
正解ラベルの確認
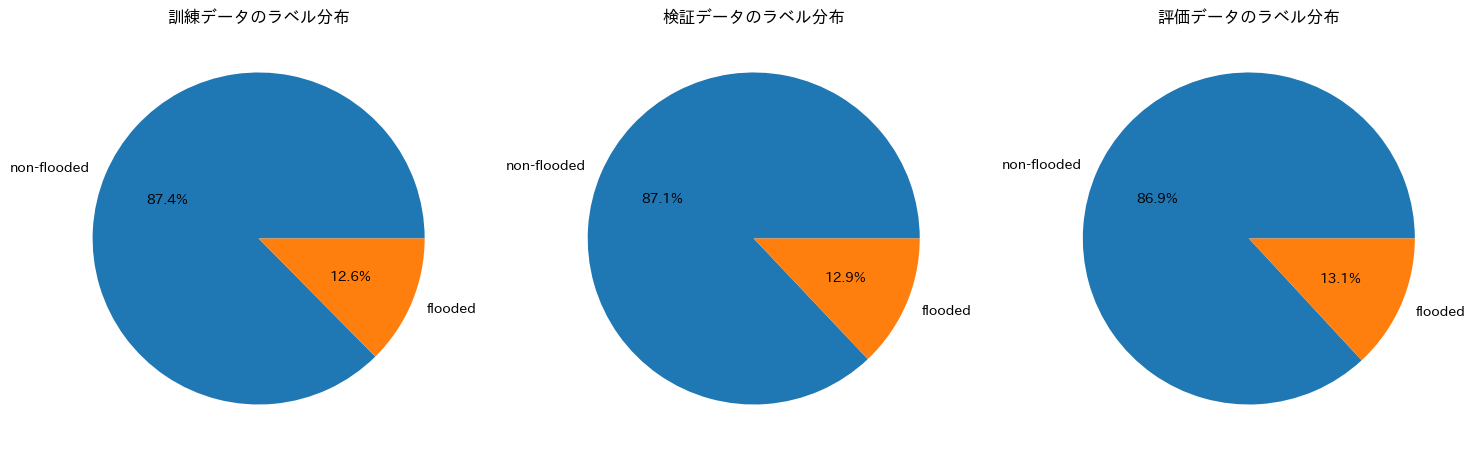
それぞれのデータセットに同程度の割合で正例(洪水:Flooded)が含まれていることが確認できます。
また、多数クラス(non-flooded)と少数クラス(flooded)には大きな不均衡があることもわかります。
このケースでは、すべての予測を洪水でない(non-flooded)とすることで正解率(accuracy)は、87%程度となってしまいますので、正解率(accuracy)に惑わされないことが大切です。
線形分類器モデルのトレーニングとパラメータ最適化
ロジスティック回帰のF1交差検証スコア: 0.7922 ± 0.0971
ロジスティック回帰のF2交差検証スコア: 0.8038 ± 0.1073
ロジスティック回帰の最適パラメータ(F2最適化): {'classifier__C': 0.0001, 'classifier__class_weight': {0: 1, 1: 7}}
ロジスティック回帰の最高F2スコア: 0.8442
偏ったデータセット(洪水画像:flooded が洪水でない画像:non-flooded よりもかなり少ないデータセット)であることを反映して、classifier__C を小さな値(0.0001)にして過学習を防ぎ、classifier__class_weight を、少数クラスである洪水画像:flooded に大きな重みづけをする {0: 1, 1: 7} の組み合わせが最適でした。
線形SVMのF1交差検証スコア: 0.6882 (+/- 0.2102)
線形SVMのF2交差検証スコア: 0.7499 (+/- 0.1831)
線形SVMの最適パラメータ(F2最適化): {'classifier__C': 0.001, 'classifier__class_weight': None}
線形SVMの最高F2スコア: 0.8307
こちらも偏ったデータセットであることを反映して、classifier__C を小さな値(0.001)にして過学習を防ぐことが有効であったようです。
モデルの評価
テストデータ(訓練データとは異なるデータ)を使って両モデルを評価した結果は以下のとおりでした。
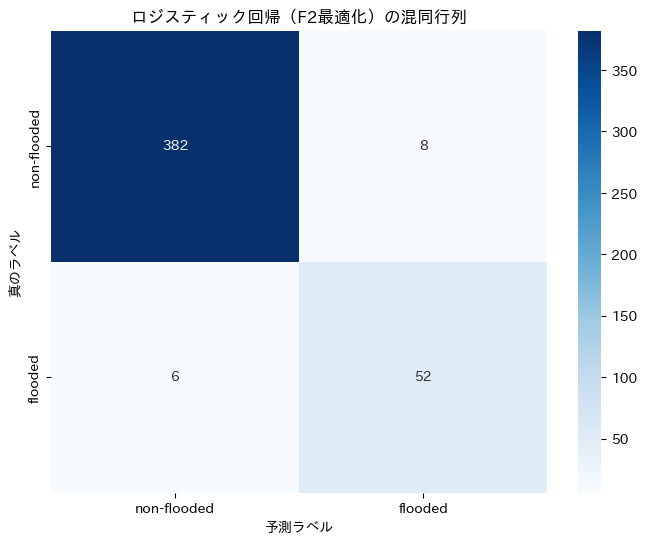
===== ロジスティック回帰(F2最適化) の評価 =====
正解率(Accuracy): 0.9688
適合率(Precision): 0.8667
再現率(Recall): 0.8966
F1スコア: 0.8814
F2スコア: 0.8904
分類レポート:
precision recall f1-score support
non-flooded 0.98 0.98 0.98 390
flooded 0.87 0.90 0.88 58
accuracy 0.97 448
macro avg 0.93 0.94 0.93 448
weighted avg 0.97 0.97 0.97 448
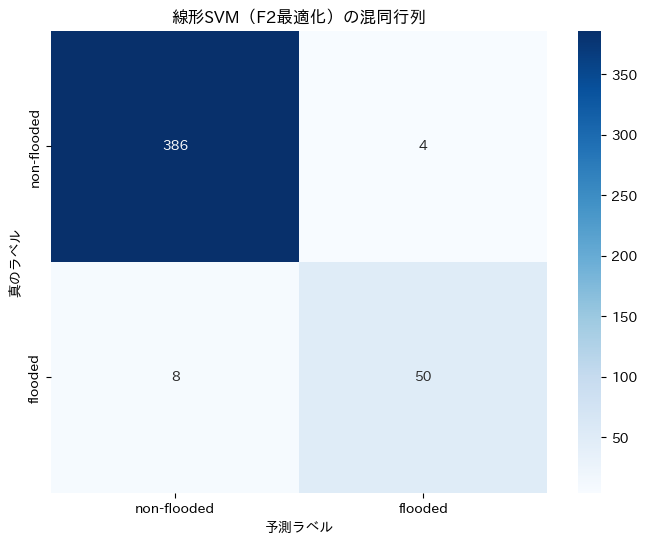
===== 線形SVM(F2最適化) の評価 =====
正解率(Accuracy): 0.9732
適合率(Precision): 0.9259
再現率(Recall): 0.8621
F1スコア: 0.8929
F2スコア: 0.8741
分類レポート:
precision recall f1-score support
non-flooded 0.98 0.99 0.98 390
flooded 0.93 0.86 0.89 58
accuracy 0.97 448
macro avg 0.95 0.93 0.94 448
weighted avg 0.97 0.97 0.97 448
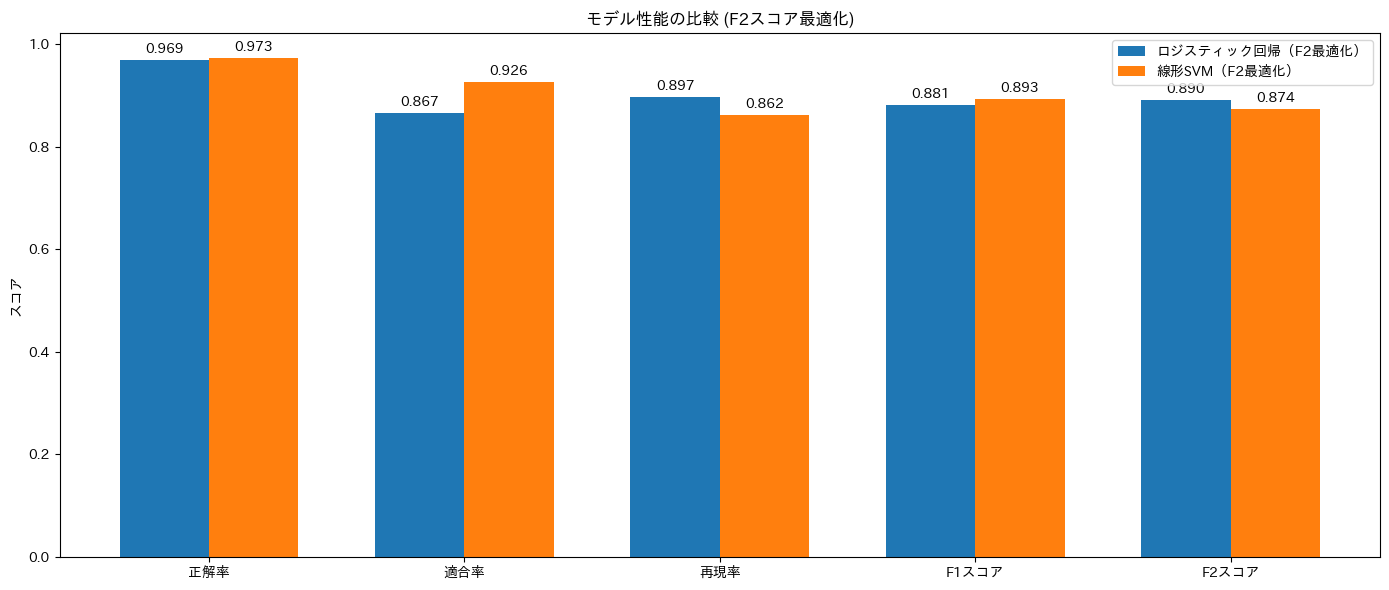
ロジスティック回帰モデルが F2 の最適化(再現率を重視しながら適合率とのバランス)という観点では優れていると評価できます。
評価
評価データ(訓練やモデル選定に使っていないデータ)をロジスティック回帰モデルで分類した結果は以下のとおりでした。
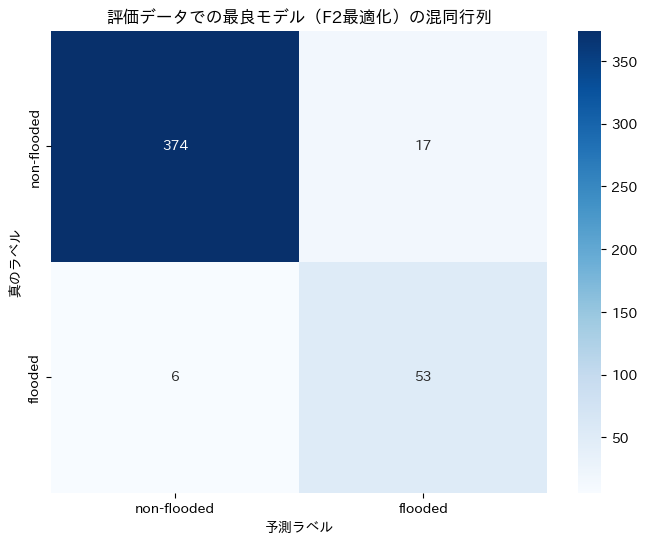
=== 評価データでの最終評価(F2最適化モデル) ===
===== 評価データでの最良モデル(F2最適化) の評価 =====
正解率(Accuracy): 0.9489
適合率(Precision): 0.7571
再現率(Recall): 0.8983
F1スコア: 0.8217
F2スコア: 0.8660
分類レポート:
precision recall f1-score support
non-flooded 0.98 0.96 0.97 391
flooded 0.76 0.90 0.82 59
accuracy 0.95 450
macro avg 0.87 0.93 0.90 450
weighted avg 0.95 0.95 0.95 450
これをゼロショット(分類クラスのラベルとのコサイン類似度のみで分類)と比較した結果は以下のとおりです。
===== モデル比較: コサイン類似度 vs F2最適化線形分類器 =====
コサイン類似度の正解率: 0.8111
F2最適化線形分類器の正解率: 0.9489
改善率: 16.99%
コサイン類似度の適合率: 0.4000
F2最適化線形分類器の適合率: 0.7571
改善率: 89.29%
コサイン類似度の再現率: 0.8814
F2最適化線形分類器の再現率: 0.8983
改善率: 1.92%
コサイン類似度のF1スコア: 0.5503
F2最適化線形分類器のF1スコア: 0.8217
改善率: 49.33%
コサイン類似度のF2スコア: 0.7104
F2最適化線形分類器のF2スコア: 0.8660
改善率: 21.91%
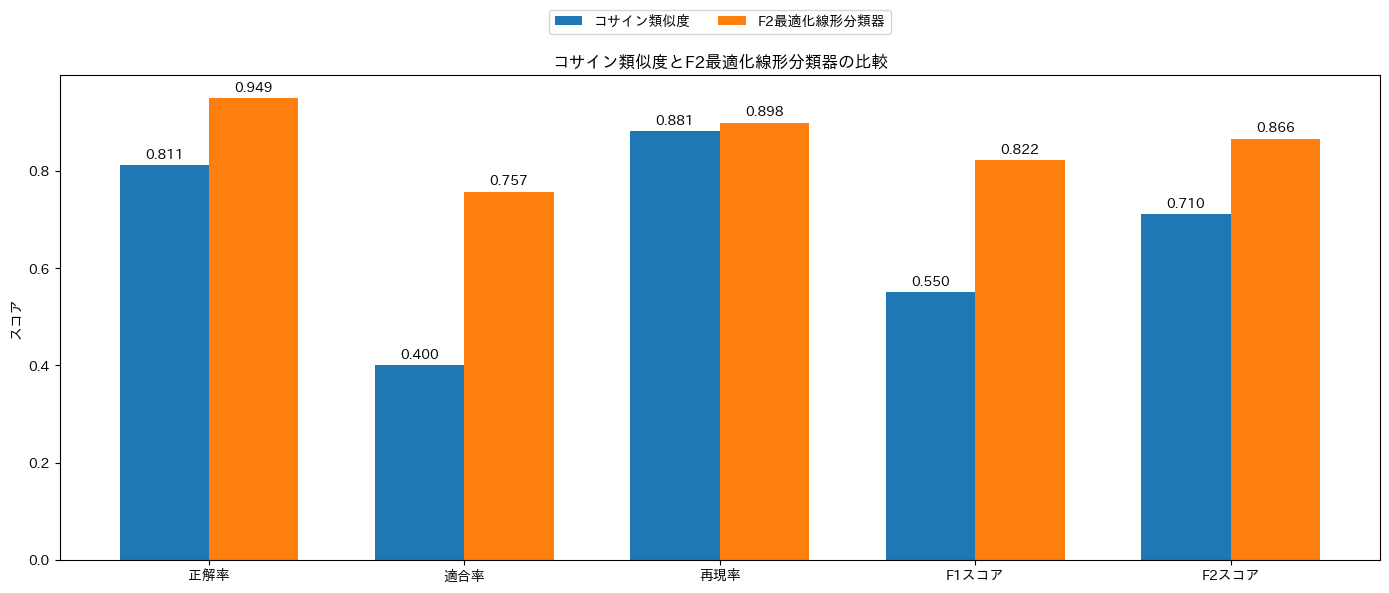
- 洪水の画像を正しく洪水と分類できているかどうかを表す再現率(Recall)は、ゼロショットの 88.1 % から線形分類器では 89.8% と同等、もしくは、若干の向上を示しています
- 洪水と判定した画像が本当に洪水の画像であったかどうかを表す適合率(Precision)は、ゼロショットの 40.0% から線形分類器では 75.7% と大幅な向上がみられました
結論として、再現率を維持しながら線形分類器で適合率を改善することを達成できました。
まとめ
前回の記事では、クラウドで API サービスとして提供されている画像言語のマルチモーダル埋め込みモデル Cohere Multimodal Embed 3 を使ってある程度の洪水判定ができることを確かめましたが、今回の記事では、さらにこの出力(埋め込みベクトル)を線形分類器を使って分類することで、洪水判定の再現率(洪水を見逃さずに見つけられる比率)を維持しながらも、誤判定を大幅に減らせることが確かめられました。
洪水判定のような用途に本格的に導入するためには、再現率、適合率ともにさらに改善が必要かと思います。より多くの訓練データを用意できればさらに精度を改善できる可能性もあります。また、それでも精度が不足する場合にはオープンウェイトのマルチモーダル埋め込みモデルをファインチューニングしたり、大規模なデータセットを使って1からモデルを構築することができます。今回の検証から少なくとも画像データを活用したサービスのコンセプトの検証などには、手軽に利用できるマルチモーダル埋め込みモデルの API サービスの活用も一考に値しそうであることがわかりました。
謝辞
この取り組みはしゅんさんの下記の記事に触発されたものです。この場をお借りいたしましてお礼申し上げます。