はじめに
マルチモーダル埋め込みモデル(Vision-Language系)は、自然言語や画像から意味的に類似した画像を見つける画像検索や画像の分類に便利なモデルですよね。最近では、多くのクラウドサービスプロバイダーで利用可能になって来ています。

そこで、間もなく OCI にもやって来そうと期待している Cohere 社の Cohere Multimodal Embed 3 を Zero-shot で使って、空撮画像が洪水で浸水している地域のものか、浸水していないかを分類するタスクにチャレンジしてみました。ここで言っているZero-shotとは、洪水画像を用意して特別なモデルの訓練をしないという意味です。汎用のマルチモーダル埋め込みモデルを使用して画像と分類ラベルテキストの埋め込みベクトルを生成して、それらの間のコサイン類似度の大小だけに基づいて分類を行ってみようということです。
| ドローン空撮画像 | FloodNetの領域分割ラベリング (正解:浸水) |
今回の検証での予測 |
|---|---|---|
 |
 |
浸水 |
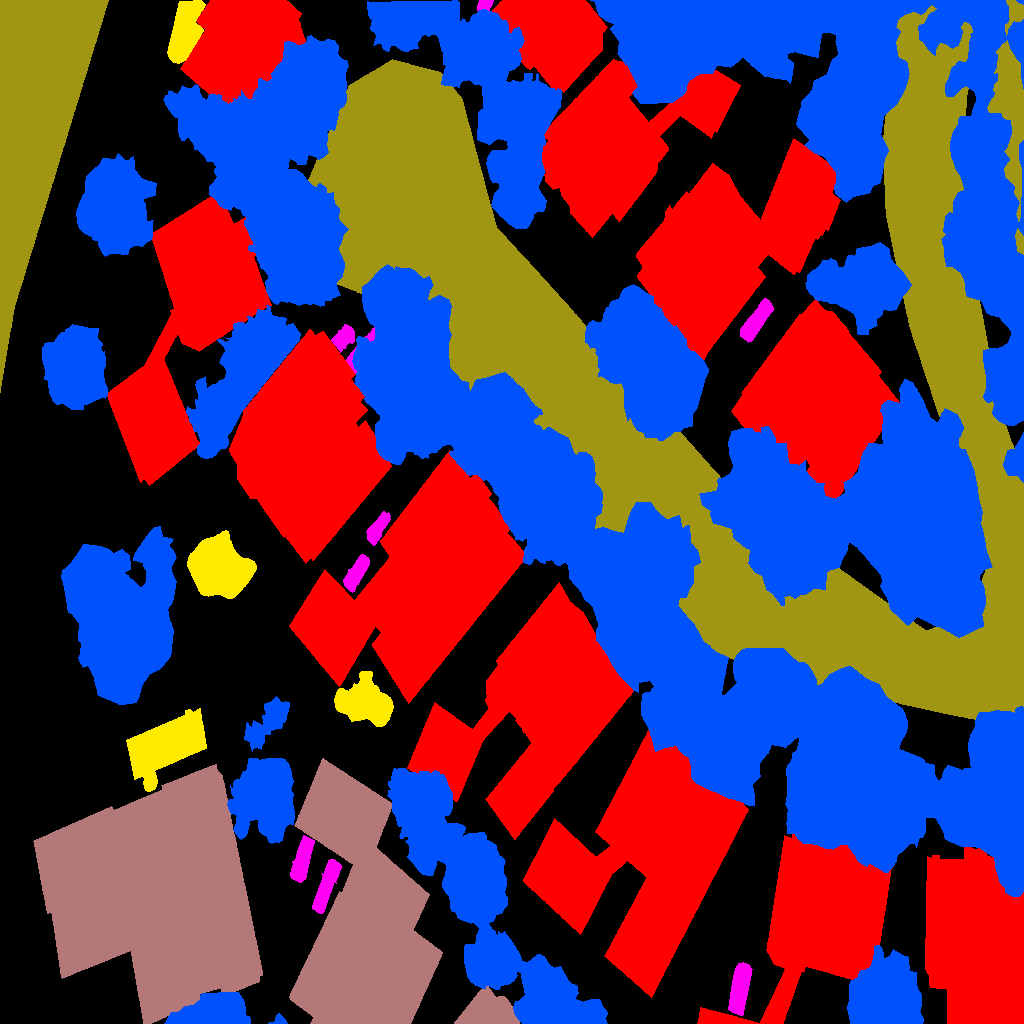
FloodNetの領域分割ラベリングの領域のうち以下の2色が洪水による浸水を表しています。
| 建物の浸水 | 道路の浸水 |
|---|---|
 |
 |
今回の検証では、左端の「ドローン空撮画像」をマルチモーダル埋め込みベクトルを使って浸水しているか、していないかに分類し、FloodNet Dataset の領域分割ラベリングと整合しているかを評価します。この検証では、画像の領域分割や領域ごとの判定は行っていません。あくまでも画像単位で浸水判定しています。
なお、こちらの内容は、ウェビナー【Oracle AI JAM Session #23 生成AIを活かすには埋め込みの理解から!RAGの心臓:埋め込みの基礎から応用まで!】(2025年3月26日)
及び以下のブログで概要をご紹介しているものの詳細となります。
結果概要
1445枚のドローン(UAS)による空撮画像を分類した結果の概要は以下のとおりです。

- 実際に浸水であるデータのうち、どれくらい見逃さずに浸水と予測できたかを表す Recall(再現率)は、92.9% でした。見逃し(False Negative)が少ないため、浸水画像をなるべく取りこぼしなく検出したい用途では有用である可能性があります
-
予測が「浸水」とされたもののうち、どれくらい実際に浸水だったか を表す Precision(適合率)は、43.9% でした。これは「浸水でないものを誤って浸水とみなす(False Positive)の割合が高い」ことを意味しています。「誤検知」を減らして、浸水と予測したら確実に浸水であって欲しいといった用途では Zero-shot では難しいようです(Zero-shot を超えた精度を目指す、
精度向上編も準備中です)
精度向上編を公開しました!(2025/4/3)
コード
以下の GitHub Repository で使用したノートブックを公開しています。
こちらのコードのうち FloodNet Dataset の扱いについては、Alexander Galeaさんの multimodal-embeddings のノートブック を参考にさせていただいています。
データセット
Community Data License Agreement – Permissive, Version 1.0 で公開されている FloodNet Dataset を使用しました。FloodNet Dataset については、FloodNet: A High Resolution Aerial Imagery Dataset for Post Flood Scene Understanding をご参照ください。
上記リポジトリの Readme の Dropbox のリンク(↓の赤丸)からダウンロードすることができます。
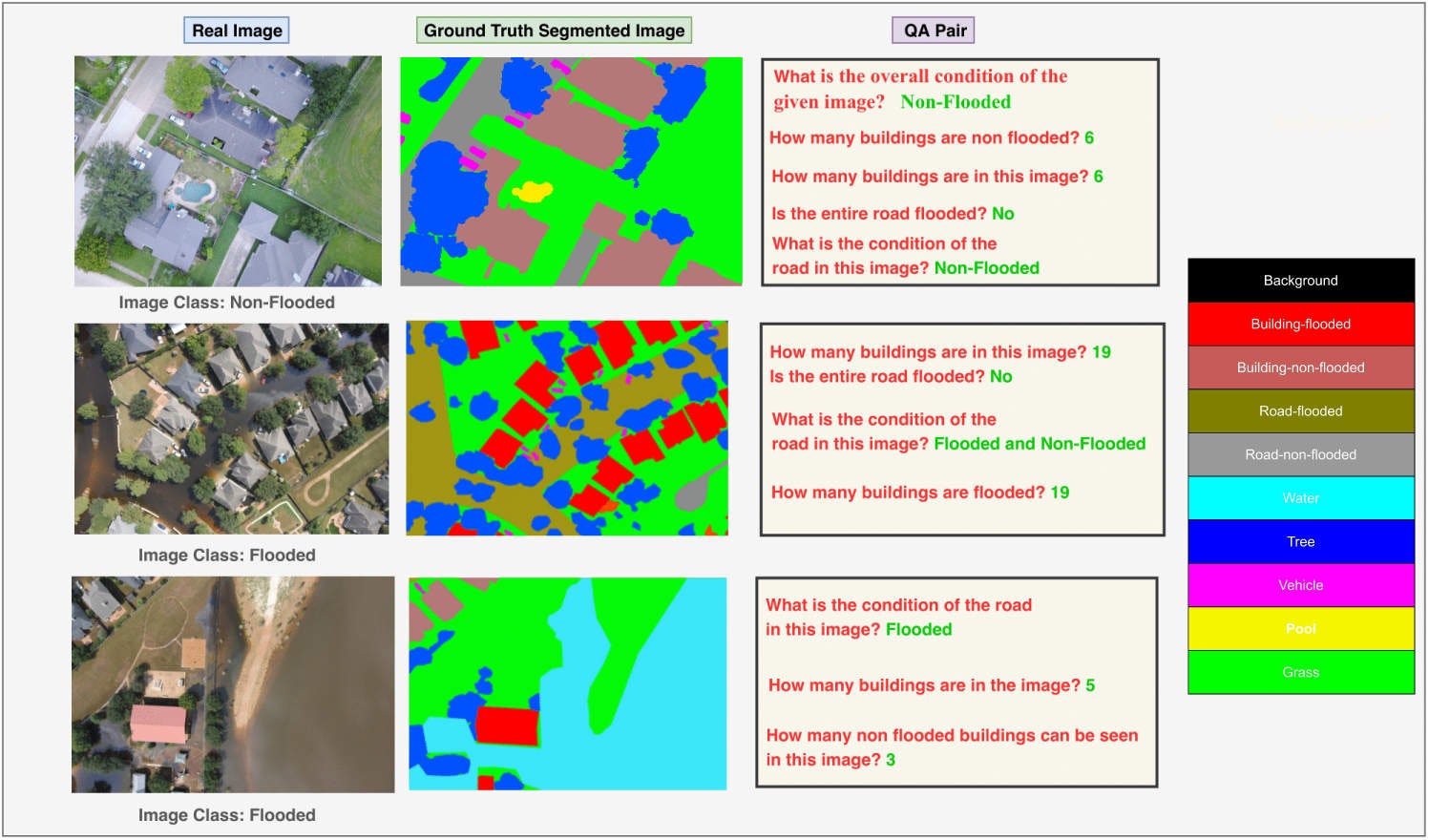
図.1 FloodNet の semantic annotation(https://github.com/BinaLab/FloodNet-Supervised_v1.0 より)
ダウンロードした zip ファイルには、ColorMasks-FloodNetv1.0 と FloodNet-Supervised_v1.0 の 2つのフォルダがあります。
-
FloodNet-Supervised_v1.0:空撮画像データファイルが格納されたフォルダ。更にtest(評価用)train(訓練用)val(検証用)の3 つのフォルダに分かれています。 -
ColorMasks-FloodNetv1.0:上の画像中央の「Ground Truth Segmentd Image」のようにFloodNet-Supervised_v1.0の各画像の領域ごとに写っているオブジェクトとそれが浸水しているかどうかを分類した画像です。正解ラベルとして使用します
今回は、Cohere Multimodal Embed 3 の Zero-shot 分類のみでモデルの訓練は行いませんので、一番多くの画像が格納されている FloodNet-Supervised_v1.0/train/train-org-img フォルダの 1445枚の画像を分類してみました。
手順
手順のロードマップ
- Cohere 社 API キーの取得と環境変数への設定
- セットアップ:コードと画像データセットの準備と環境変数の設定、ライブラリのインストール
- 正解ラベルの生成(
100_generate_image_labels.ipynb) - 画像の埋め込みベクトルの生成(
200_generate_image_embeddings.ipynb) - 画像の分類(
300_classify_image.ipynb)
セットアップ
前提条件
Cohere 社の API サービスを利用するための API キーが必要です。
https://dashboard.cohere.com/api-keys で取得できます。トライアルキー(無償)もあります。ただし、トライアルキーはレート制限があり画像の埋め込みは、1分あたり5枚までとなります。この記事と同じテストをされる場合には、有償プロダクションキーの取得がおすすめです。トライアルキーを使う場合には、1分間に5回を超えて埋め込みリクエストを送信しないようコードを修正してください。
コードのクローン
git clone https://github.com/kutsushitaneko/floodnet-image-classification.git
cd floodnet-image-classification
なお、Python 仮想環境の利用をおすすめします。テストした Python のバージョンは、3.11.9 です。
データセットの配置
-
floodnet-image-classificationフォルダ直下にdatasets/floodnetフォルダを作成します
FloodNet Dataset の Dropbox リンクからダウンロードしたファイルを展開し、datasets/floodnetフォルダへ配置します

環境変数の設定
floodnet-image-classification フォルダ直下に .env という名前のファイルを作成して、.env_sample にある書式で Cohere の API キーと埋め込みモデルのID(今回は、embed-english-v3.0です。今後、バージョンアップなどがあった場合には修正してください)を設定します。
COHERE_API_KEY=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
COHERE_EMBED_MODEL_ID=embed-english-v3.0
ライブラリのインストール
pip install -r requirements.txt
正解ラベルの生成(100_generate_image_labels.ipynb)
FloodNet Dataset では、正解ラベルは、各画像の領域ごとに写っているオブジェクトとそれが浸水しているかどうかを分類したカラーマップ(図.1 中央)として ColorMasks-FloodNetv1.0 に格納されています。
今回は画像単位に浸水があるかどうかを判定しますので、このカラーマップを調べて Building Flooded(RGB:255,0,0)もしくは、Road Flooded(RGB:160,150,20)のピクセルがある場合には"flooded"、これらのピクセルが無い場合には"non-flooded"としてテキストの正解ラベルを生成します。分類後の評価に使用します。
なお、カラーマップの色の意味(カラーパレット)は、datasets\floodnet\ColorMasks-FloodNetv1.0\ColorPalette-Values.xlsxに定義されています。

図.2 FloodNet のカラーマップ
次のコードは、FloodNetデータセットの色分けされたマスク画像から、その画像が洪水エリアか非洪水エリアかを判定する核心部分です。
def label_from_colormask(image_path):
colormask_path = Path("datasets/floodnet/ColorMasks-FloodNetv1.0/ColorMasks-TrainSet") / f"{image_path.stem}_lab.png"
color_mask = Image.open(colormask_path).convert('RGB')
all_pixels = list(color_mask.getdata())
unique_colors = [str(color) for color in (set(all_pixels))]
flood_colors = [
(255,0,0), # building-flooded
(160, 150, 20), # road-flooded
]
is_flooded = any(str(colormask) in unique_colors for colormask in flood_colors)
return "flooded" if is_flooded else "non-flooded"
この関数は以下のことを行なっています:
- 元画像に対応するカラーマスク画像を開く
- 画像内のすべてのピクセルの色情報を取得
- ユニークな色のリストを作成
- 洪水を表す特定の色(建物浸水の赤色(255,0,0)や道路浸水の黄土色(160,150,20))が一つでも含まれているかを確認
- 含まれていれば「flooded」、なければ「non-flooded」というラベルを返す
正解ラベルの生成の実行
Jupyter ノートブック環境で、100_generate_image_labels.ipynb を先頭セルから最後まで順番に実行してください。画像ファイルへの相対パスと正解ラベルをカラムとして持つ labels.csv ファイルが作成されます。
実際に実行せずに実行の様子だけ知りたい場合は、with_outputフォルダの 100_generate_image_labels.ipynb を参考にしてみてください。
画像の埋め込みベクトルの生成(200_generate_image_embeddings.ipynb)
Cohere Embed は、画像データを Data URL形式で受け取りますので、画像を変換する必要があります。
次の関数でそれを行っています。
def image_to_base64_data_url(image_path):
with Image.open(image_path) as img:
buffered = BytesIO()
img.save(buffered, format="JPEG")
img_base64 = base64.b64encode(buffered.getvalue()).decode("utf-8")
data_url = f"data:image/jpeg;base64,{img_base64}"
return data_url
この関数は以下のことを行っています:
- 画像ファイルをPILのImageオブジェクトとして開く
- BytesIOを使用してバッファにJPEG形式で保存
- バッファの内容をBase64エンコードし、UTF-8文字列に変換
- 最後に「data/jpeg;base64,」というプレフィックスを付けてデータURLを作成
この変換は、Cohere APIに画像データを送信するために必要なステップです。APIは画像ファイルのパスではなく、Base64エンコードされたデータURLを受け付けるためです。
また、次のコードで画像埋め込みベクトルを生成して保存しています。
# CSVファイルのヘッダーを初期化(最初の1回のみ)
pd.DataFrame(columns=['image_path', 'label', 'embedding']).to_csv('image_embeddings.csv', index=False)
# DataFrameをイテレーション
for index, row in tqdm(df.iterrows(), total=len(df)):
image_path = row['image_path']
label = row['label']
data_url = image_to_base64_data_url(image_path)
ret = co.embed(
input_type="image",
images=[data_url],
model=model_id,
embedding_types=["float"],
)
# 1件分のデータをDataFrameとして作成
embedding_df = pd.DataFrame([{
'image_path': image_path,
'label': label,
'embedding': ret.embeddings.float[0]
}])
# mode='a'(append)とheader=Falseで追記モードで保存
embedding_df.to_csv('image_embeddings.csv', mode='a', header=False, index=False)
- Cohere の
embed()メソッドで埋め込みリクエストを送信しています -
input_typeには、画像埋め込みベクトルを生成する際には "image" を指定します
※Cohereのトライアルキーを使用する場合(1分あたり5枚の制限がある)には、このコードに適宜 sleep を入れて対応してください。
画像の埋め込みベクトルの生成の実行
200_generate_image_embeddings.ipynb を先頭セルから最後まで順番に実行してください。
FloodNet-Supervised_v1.0/train/train-org-img フォルダの 1445枚の画像の画像埋め込みベクトルを生成し、画像の相対パス、正解ラベル(テキスト)、画像埋め込みベクトルを image_embeddings.csv に保存します。私の環境(Cohere プロダクションキー)では、画像埋め込みベクトル生成に 30分程かかりました。Cohere Multimodal Embed 3(英語バージョン)を使っています。
画像の分類(300_classify_image.ipynb)
概略以下のような処理を行います。
-
image_embeddings.csvを読み込む - データ数、ベクトルの次元数、正解ラベルの分布を確認
- 分類クラスのキャプションを設定
class_captions = [ 'A satellite image of a non-flooded area of land.', 'A satellite image of a flooded area of land.' ]- flooded に対しては、"A satellite image of a flooded area of land."
-
non-flooded に対しては、"A satellite image of a non-flooded area of land."
ここで、単に flooded や non-flooded といった単語にしない理由は、マルチモーダル埋め込みモデルは対照学習の際に、"A photo of オブジェクト"のような形式のキャプションと画像のポジティブペア、ネガティブペアを使って学習していると考えられるためです。ただし、Cohere Embed がどのようなペアで学習しているかは私が知る限り公表されていないため、これが最善かどうかは不明です。また、FloodNet は衛星写真ではなく、ドローン(無人航空機)による空撮映像だったことには後で気が付きました^^;このキャプションを変えることで、調整ができる可能性もあります。
- 分類クラスのキャプション(非浸水:'A satellite image of a non-flooded area of land.'と浸水:'A satellite image of a flooded area of land.')のテキスト埋め込みベクトルを生成。Cohere Multimodal Embed 3(英語バージョン)を使っています。
ret = co.embed( input_type="classification", texts=class_captions, model=model_id, embedding_types=["float"], ) class_embeddings = np.array(ret.embeddings.float)- Cohere の
embed()メソッドで埋め込みリクエストを送信しています -
input_typeには、分類タスクの場合には "classification" を指定します - Cohere Embed は、テキストの埋め込みベクトル生成の際には、テキストを96個までまとめて処理できるため texts には、2つのキャプションが設定されている class_captions リストを設定し、1度に2つの埋め込みベクトルを生成します
- Cohere の
- 各画像と浸水キャプション、非浸水キャプションそれぞれのコサイン類似度を計算。scikit-learn の
cosine_similarity関数を使っています - 確率分布の計算。SciPy の Spatial ライブラリの
softmax関数を使っています - 確率分布から予測クラスを決定
- 混同行列(Confusion Matrix) の計算
画像の分類の実行
300_classify_image.ipynb を先頭セルから最後まで順番に実行してください。
結果
| 再現率(Recall) | 適合率(Precision) | F1スコア |
|---|---|---|
| 0.929 | 0.439 | 0.596 |
| 混同行列 | 予測 | ||
|---|---|---|---|
| 浸水 | 非浸水 | ||
| 実際 | 浸水 | True Positives: 169 | False Negatives: 13 |
| 非浸水 | False Positives: 216 | True Negatives: 1047 | |
| 実際の浸水画像の数 | 実際の非浸水画像の数 | 総数 |
|---|---|---|
| 182 | 1263 | 1445 |
- 実際に浸水であるデータのうち、どれくらい見逃さずに浸水と予測できたかを表す Recall(再現率)は、92.9% でした。見逃し(False Negative)が少ないため、浸水画像をなるべく取りこぼしなく検出したい用途では有用である可能性があります
- 予測が「浸水」とされたもののうち、どれくらい実際に浸水だったか を表す Precision(適合率)は、43.9% でした。これは「浸水でないものを誤って浸水とみなす(False Positive)の割合が高い」ことを意味しています。「誤検知」を減らして、浸水と予測したら確実に浸水であって欲しいといった用途では Zero-shot では難しいようです
精度向上について

ゼロショットだけでもなかなか良い再現率(Recall)を達成することができましたが、誤検知は減らしたいところですね。Cohere Multimodal Embed 3 で生成した埋め込みベクトルを線形分類器に入力して訓練し、精度向上を図った検証については別の記事でご紹介する予定です。
精度向上編を公開しました!(2025/4/3)