どうにかしてTorchVisionのPre-TrainedをTensorFlowで使いたい
はじめに
この記事は、NTTテクノクロス Advent Calendar 2020 の24日目です🎅
メリークリスマス!NTTテクノクロスの広瀬です🎄
普段の業務では高精細VR配信エンジン1や機械学習による画像認識AIエンジンの研究開発に取り組んでいます。
その他にも、社内で取り組まれているAI関連開発で起きた「ちょっと困った」をサポートする活動をしています。
さて、今回はTorchVisionにあってTensorFlowにはないVGG-11やらResNet-18をTensorFlowで使うためにはどうしたらいいんだ?と疑問が湧いたので、使える方法はないか考えてみました。
概要
数年前と比べるとエッジデバイス向けのモデル等の研究が進んでおり、IoTと機械学習の親和性も高まってきました。
GitHubに公開されているソースも軽量なモデルを使用しているものも多いのですが、Servingの便利さから普段使いのフレームワークにTensorFlowを選択しているとここで問題が発生します。

TensorFlowにはResNet18や34が無いのです❗ TorchVisionが羨ましい
ただ変換するだけならツール2を使う手もあるのですが、業務では最先端の研究結果を検証も行う為、ONNX経由による制約3を受けてしまいます。
そこで今回は、力技でのパラメータ移植にチャレンジしていこうと思います![]()
戦略
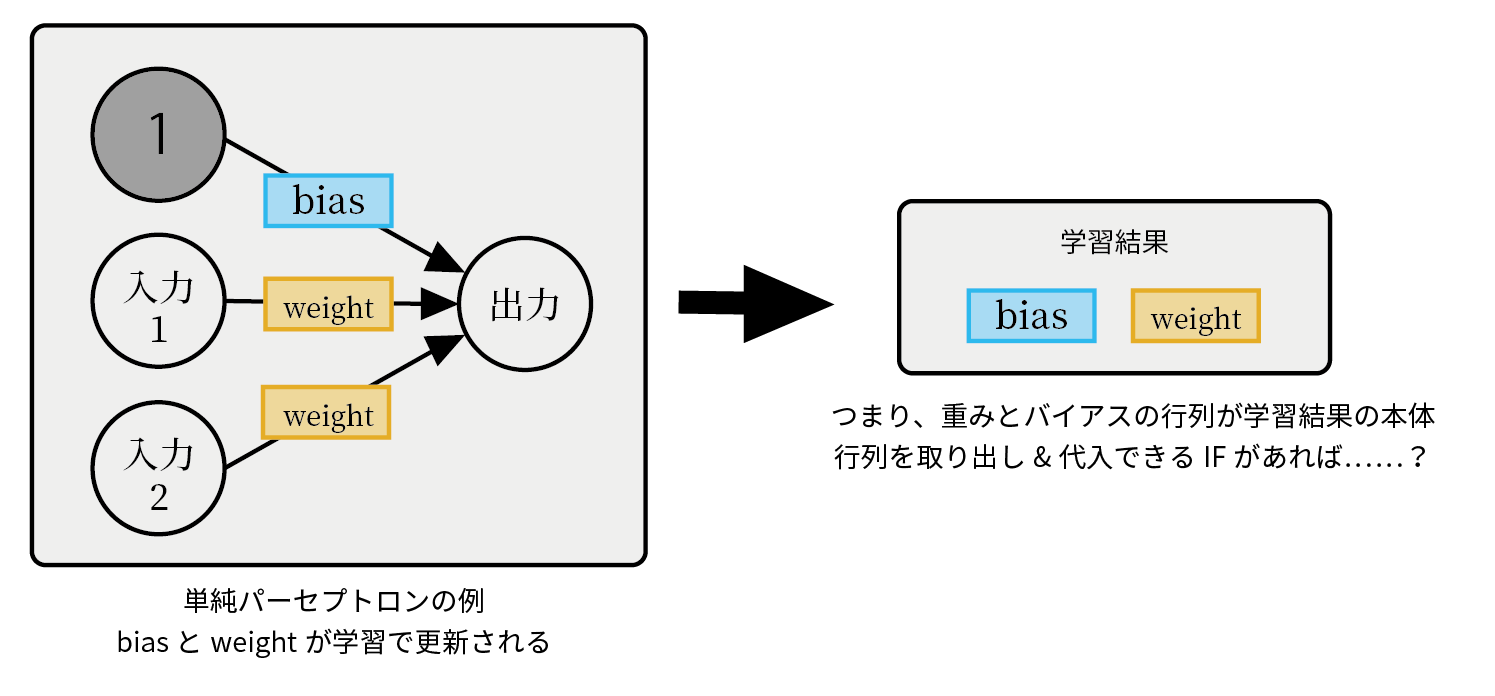
レイヤーが保持するパラメータは大きく2つ。重みとバイアスです。
この重みとバイアスは一体何なんだというと、要は行列とベクトルで表されるパラメータでしか無いわけです。
下の式で言うところのwとbですね。
z = \sum_{i=0}^n w_ix_i+b_i
↓こんなイメージです。このwとbを表す行列が取り出せれば上手くいくのではないでしょうか。
早速試してみる
1. Pytorchのレイヤーから行列を取り出す
まずは、Pytorchのレイヤーから重みとバイアスを行列として取り出してみましょう。
今回始めてPytorchに触りますが、TensorFlow(keras)でいうところのget_weightsの様な関数が用意されていれば完璧です。

.weightと.biasで取り出せそうです。
出力されるtorchのTensor型を調べると.numpy()でndarrayが取り出せると書いてあったのでやってみましょう。
torch_conv2d = torch.nn.Conv2d(in_channels=5, out_channels=64, kernel_size=3)
print(torch_conv2d.weight.numpy())
> "RuntimeError: Can't call numpy() on Tensor that requires grad. Use tensor.detach().numpy() instead."
一発じゃうまくいきません……。detachしてくれとのことなのでしてみましょう。
print(torch_conv2d.weight.detach().numpy().shape)
> (64, 5, 3, 3)
上手にできました。
初めてPytorchAPIリファレンスを見てみましたが、数学的な解説がしっかり載っていて凄いですね。
ディープラーニングを理論で理解するための教科書になりそうです。
2. TensorFlowのレイヤーに行列を突っ込む
続いて、TensorFlowのレイヤーに行列を突っ込めるか確認です。
こちらはset_weights関数があるので、何を入れればよいか分かればOKです。
https://www.tensorflow.org/api_docs/python/tf/keras/layers/Layer#set_weights
tf.keras.layers.Layer.set_weights(weights)
weights
a list of Numpy arrays.
The number of arrays and their shape must match number of the dimensions of the weights of the layer
(i.e. it should match the output of get_weights).
APIリファレンスをチェックするとNumpy配列でいいようですね。
get_weights関数の出力と一致する必要があるようなので、get_weights関数を叩いてみましょう。
inputs = tf.keras.Input(shape=(28, 28, 5),)
tf_conv2d = tf.keras.layers.Conv2D(filters=64, kernel_size=3)(inputs)
model = tf.keras.Model(inputs=inputs, outputs=tf_conv2d)
print(model.layers[1].get_weights())
>[array([[[[-1.39296055e-02, -2.36416906e-02, -4.50647622e-03, 省略,
> dtype=float32), array([0., 0.,省略 dtype=float32)]
print(model.layers[1].get_weights()[0].shape)
> (3, 3, 5, 64)
print(model.layers[1].get_weights()[1].shape)
> (64,)
サイズが2のリスト、要素はそれぞれnumpy配列で、weightsとbiasの順番で入力されることが期待されていることがわかりました。
2.1 channel lastとchannel first
どうやら、PytorchとTensorFlowでは重みを表す行列の並びが違うようです。
Pytorchは(64, 5, 3, 3)、TensorFlowでは(3, 3, 5, 64)でしたので、TensorFlowに合わせて変換してあげましょう。
lastとfirstの違いはhttps://keras.io/ja/backend/ に↓の様に解説されています。
"channels_last" は (rows, cols, channels) とみなし,"channels_first" は (channels, rows, cols)とみなします.
torch_np = torch_conv2d.weight.detach().numpy()
print(torch_np.transpose((2, 3, 1, 0)).shape)
> (3, 3, 5, 64)
3. パラメータをコピーして推論結果を確認
3.1 まずは全層結合層だけのモデル
なんとなく行けそうな感触をつかめたので、早速試してみましょう。
TensorFlowモデルの各レイヤーが持っているset_weights関数に、Pytrochから取り出した行列を流し込んでいきます。
Pytorchにはstate_dict関数というものがあるようなので使ってみましょう。
用意したモデルは全層結合層2層だけのモデルなので簡単です。
torch_model = TorchSimpleNet()
tf_model = TFSimpleNet()
tf_model.layers[1].set_weights(
[
torch_model .state_dict()["fc1.weight"].numpy().transpose((1, 0)),
torch_model .state_dict()["fc1.bias"].numpy()
])
tf_model.layers[2].set_weights(
[
torch_model .state_dict()["fc2.weight"].numpy().transpose((1, 0)),
torch_model .state_dict()["fc2.bias"].numpy()
])
3.2 全層結合モデルで出力確認
2モデル間の出力から、要素ごとの差の最大を取って確認していきます。
非常に小さい誤差となったので、狙い通りの結果になっているようですね。
# tfの出力
tf_output = tf_model.predict(image)
# eval関数を使用後torchのTensorに変換して入力
torch_model.eval()
torch_output = torch_model(img_torch)
# 出力ベクトルの差の最大を取得
print(np.max(np.abs(tf_output - torch_output.detach().numpy())))
> 2.9802322e-08
# コピーしない場合の出力
> 0.23395675
3.3 畳み込み層を追加
続いて畳み込み層を追加しています。よくあるMNISTですね。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 28, 28, 1)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
conv2d_1 (Conv2D) (None, 24, 24, 64) 18496
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 12, 12, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 9216) 0
_________________________________________________________________
dense (Dense) (None, 128) 1179776
_________________________________________________________________
dense_1 (Dense) (None, 10) 1290
=================================================================
Total params: 1,199,882
Trainable params: 1,199,882
Non-trainable params: 0
_________________________________________________________________
collected 1 item
パラメータのコピーも手順は変わりません。
Transposeで与える次元数が増えるので、それに合わせて増えている程度の変化ですね。
さぁ、早速動かしましょう❗
tf_model.layers[1].set_weights(
[
torch_model .state_dict()["conv1.weight"].numpy().transpose((2, 3, 0, 1)),
torch_model .state_dict()["conv1.bias"].numpy()
])
3.4 畳み込み層を追加して動作確認
確認手順は変わりません。最終出力の要素ごとの差の最大を取っていきます。
print(np.max(np.abs(tf_output - torch_output)))
# 出力
> 0.6776662
おや???????
結果が一致しません……。
いったい何が起きているんでしょう?
4. なぜうまくいかない?
全層結合モデルの結果は、すでに実験によってほぼ等しいことが分かっています。
では、畳み込み層だけのNWの場合はどうでしょう。確認してみます。
4.1 畳み込み層だけのNWの出力は?
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 28, 28, 1)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
conv2d_1 (Conv2D) (None, 24, 24, 64) 18496
=================================================================
Total params: 18,816
Trainable params: 18,816
Non-trainable params: 0
channel-firstとlastで結果と比較するために、出力をTransposeしています。
出力は畳み込み層にも問題はなさそうですね。
tf_output = tf_model.predict(inp_keras)
torch_output = np.transpose(model(inp_pyt).data.numpy(), (0, 2, 3, 1))
print(np.max(np.abs(tf_output - torch_output)))
> 4.5776367e-05
4.2 何がいけなかったのか
結論としては畳み込み層のあとにFlattenレイヤーを置いたことが原因でした。
Pytorchで学習した結果を流し込んでいるので、全層結合層が期待する特徴量はNCHWの並びを1次元化したものを期待しています。
それに対してTensorFlowはNHWCの並びで一次元化するので、期待する並びと変わってしまい識別がうまくいかなくなっていたようです。

確認のために1層だけの畳み込み層のあとにFlattenをおいて出力してみましたが、先頭は同じですが後ろの並びが一致していません。
# TensorFlowの出力
> 8.3867350e+00 -1.5191419e+01 2.6989546e+01 ...
# Pytorchの出力(TFでもこうなってほしい)
> 8.3867, 8.4628, 8.5389 ...
畳み込み層を挿入しないでFlattenを入れた場合は問題なし。
畳み込み層のパラメータをNCWHのものに置き換えたことで、Flattenの結果が意図しないものとなっていると推測できます。
# TensorFlowの出力
[[ 0. 1. 2. 3. 4. 5. ...
# Pytorchの出力
[[ 0. 1. 2. 3. 4. 5. ...
4.3 解決策
いろいろ試してみた結果、Convの後Flattenする前に順番を入れ替えてあげることで解決しました。
先程に比べて誤差も小さくなっているので、成功したようですね。
x = tf.keras.layers.Conv2D(64, 3, activation="relu")(x)
x = tf.keras.layers.MaxPool2D(2)(x)
# Flattenの前に入れ替えている
x = tf.keras.layers.Flatten()(tf.keras.layers.Permute((3,1,2))(x))
x = tf.keras.layers.Dense(128, activation="relu")(x)
print(np.max(np.abs(tf_output - torch_output)))
> 1.1920929e-07
5. VGGで動作確認
では、TensorFlowで実装したVGG11にTorochVisionのパラメータを流し込んで推論してみましょう。
テスト画像は我が家の同居人です🐰
Model: "functional_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 56, 56, 128) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
conv2d_3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 28, 28, 256) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
conv2d_5 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 14, 14, 512) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
conv2d_7 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 7, 7, 512) 0
_________________________________________________________________
permute (Permute) (None, 512, 7, 7) 0
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
dense (Dense) (None, 4096) 102764544
_________________________________________________________________
dense_1 (Dense) (None, 4096) 16781312
_________________________________________________________________
dense_2 (Dense) (None, 1000) 4097000
=================================================================
Total params: 132,863,336
Trainable params: 132,863,336
Non-trainable params: 0
| デフォルトパラメータ | パラメータコピー後 |
|---|---|
 |
 |
ハンミョウ(Tiger Beetle)からノウサギ(Hare)になっているので、正解ですね。
ハンミョウってなんとかの森でしか見たこと無いんですが、ImageNetの1000カテゴリに採用されているんですね……。
さて、これで問題なく重みのコピーが出来ましたし、TensorFlow版のモデルのソースも手元にあるので遊び放題ですね。
あとはCheckPointでもSavedModelでもHDF5でも好きなように保存することが出来るでしょう。
完成
さて、長くなりましたが完成です。
フレームワーク間の仕様の違いで少しハマりましたが、なんとか最初のイメージ通り行列を取り出してフレームワーク間のやり取りができそうなことがつかめました。
もう少しフレームワークの完成度が高まってきて、こういった事も容易にできるようになればなと期待します。
ここまで動作確認してきたソースコードを公開していますので、お手元でも試してみてください。
参考ソースではPoetryを使って環境を提供していますので、興味を持った方は別記事も参照いただければと思います。
おわりに
ネットで調べてもツールを使ったやり方ばかりが引っかかって出来るのか半信半疑だったんですが、やってみたらそこそこ簡単にできました。
ディープラーニングはブラックボックスというワードが独り歩きしてしまい、とっつくにくいイメージを持たれている方も多いと思いますが、既存のモデルに対して手を加える程度であればそんなに難易度が高いものではなさそうだと感じて頂けたでしょうか。
TensorFlow0.xxの頃から比べると格段にフレームワークも使いやすくなってます。
Gitからcloneしてサンプルを動かしたりファインチューニングしてみるだけではなく、もう一歩進んだ改良を加えるのもそんなに難しくないので、是非チャレンジしてみてください。
さて、いよいよ明日が最終日です!昨年の記事もとても勉強になったので、今年も期待したいと思います。
それでは、締めの記事となるNTTテクノクロス アドベントカレンダー 2020 25日目をお楽しみください。
-
普段は高精細VR配信エンジンや、深層学習を使った映像/画像処理エンジンの開発をしています。 ↩
-
Torchからonnxに変換して、onnxからtfにというのは王道パターン。流れをまとめたpytorch2kerasなんてものも。 ↩
-
↓は私が感じている制約なので、解決策はあるかもしれません。
- 変換後のモデルをガチャガチャ動かしたい時にソースがないので不自由を感じてしまう
- NCHW→NHWC変換の関係でTransposeレイヤーが至るところに挟まってパフォーマンスが下がる