注意事項の追記(2022年5月時点)
最初に作成したときから既に7年とか経ちそうな割に、未だにLGTMとかされているため、念のために追記します。
本稿記載のAPIは、現時点で既に存在しないAPI(2018/08に廃止)です。
代替として、「/statuses/filter」を用いる手段がありましたが、こちらも2020年10月末の廃止が宣言されました。
API 2.0の「/2/tweets/search/stream」が使えるようですが、こちらについては調べていません。
私自身は、「/search/tweets」を使って遡って取得する方向に逃げました。詳細はこちら。
前回まで
- Twitterまわりは何となくそれっぽくなった、んじゃないかな?
-
じゃあ次はMongoDB。
- 簡単なプログラムから始めよう
やらないといけないこと
今回のプログラムにおけるMongoDBの側の最優先事項は「受信したデータのMongoDBへの格納」です。
仕様を踏まえて言い換えると、「受信したデータは欠けなく保存し、3か月分ため込めること」になるでしょうか。
とりあえずありそうな事態を列挙してみる
DBへの入力で、失敗する事態はどんなことがあるでしょうか?
- DB・プログラム間の接続が切れて死亡
- DBそのもののプログラムエラーで死亡
- データの書式のエラーで取り込む前に死亡
- 大量にデータが流れすぎて処理が追いつかなくなって死亡
ぱっと思いついたのはこのくらいでしょうか(へっぽこなので専門的なあたりは勘弁)。
- 接続が切れるほうは、Localhost間なのであんまり気にしなくて良い、んじゃないかな、たぶん。
- DBそのものが落ちるほうは、何か別の対処手段を考えないといけないので今回パス。
- 書式エラーは、加工ゼロでぶち込む以上、まがりなりにもTwitterから送られてくるデータなのだから、信用してよいよね、と思うんですが。
- 処理が追いつかなくて死亡、怖い。
流量的には大丈夫だと信じているのですが、比較的CPUもディスク速度も潤沢な開発機とは違い、実行環境はCeleron 2.41GHz、メモリは増強して8GBという環境(増強済み)。NASとしても利用するので環境としてはかなり厳しいんじゃないかなー、と思うわけです。
先の実験をもとにして考えると1日当たり2GBは押し寄せる想定となっています。
1時間平均に直すと33MB/hで、さらに最大ピーク時は倍、つまり66MB/hをさばく必要があります。
……ん?思ったよりも少ない?? またどこかで計算間違ってる??
検算は後にするとして。わかりやすく数値を均すとして70MB/hと計算。Sqliteに保存したJSONデータの平均長さが7000byteなので、10,000ツイート/hということに。
……ホントか? どっかしらに穴がある気がしてならないのだけど……
とりあえずプログラムしてみる
とりあえず検算とか置いておいて、PyMongo使ったプログラムを書いてみることに。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from pymongo import MongoClient
Client = MongoClient() # Localhost,既定ポートなら設定不要
db = Client.testdb # DB名:testdb(自動で作成される)
Collection = db.testCollection # コレクション(テーブル)名:testCollection
Collection.insert({"test": "てすと"})
……えっ、これでいいの?
と思いつつ、pymongoをインストールしたうえで実行。結果もGUI上で見たいなーと思ったら、Robomongoというツールが。普通に使う分にはタダなので、さくっとインストール&実行。
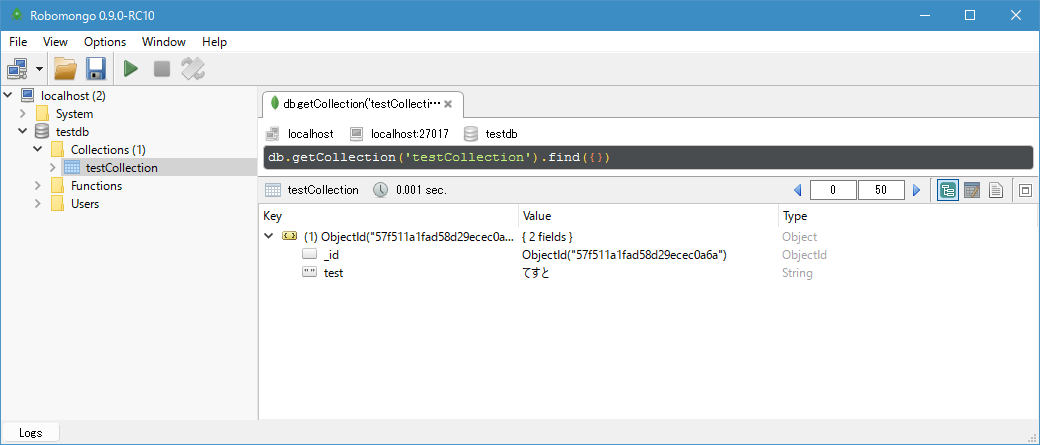
登録したデータが入ってます。 "_id"ってのは自動で振られるみたいですね。
次は複数登録してみるか……
for i in range(0, 10):
Collection.insert({"test": "てすと"})
登録できました。想像以上に楽です。
次はTwitterのツイートJSONを入れてみます。元データは初回のチェック時にSQLiteに格納していたツイートを適当にピックアップ。
Collection.insert({"created_at":"Sat Sep 24 15:35:21 +0000 2016", ...(長いので略)... })
NameError: name 'false' is not defined
なんかエラーが出ました。 素のままで読むと、falseは未定義……という意味になるんですが、なんじゃそりゃ。生JSONのはずなんですが。
ググってみたら同じことで悩んでる人が即見つかりました。
import json
#(略)
raw_string = r'''{"created_at":"Sat Sep 24 15:35:21 +0000 2016", ...(長いので略)... }'''
json_object = json.loads(raw_string)
Collection.insert(json_object)
こんな感じにすればよいとな。なるほど、登録できます。
じゃあ次は複数。
raw_string = r'''{"created_at":"Sat Sep 24 15:35:21 +0000 2016", ...(長いので略)... }'''
json_object = json.loads(raw_string)
for i in range(0, 10):
Collection.insert(json_object)
エラーになりました。「pymongo.errors.DuplicateKeyError: E11000 duplicate key error collection:」だそうなので、全く同じものを連打でぶち込むことはできない、ということでしょうか。
for i in range(0, 10):
raw_string = r'''{"created_at":"Sat Sep 24 15:35:21 +0000 2016", ...(長いので略)... }'''
json_object = json.loads(raw_string)
Collection.insert(json_object)
こんな風にやったらうまくいきました。json.loads()の段階でidが振られている、という感じ……なんだと思う。
速度計測
では、実際どの程度の速度が出るか試してみます。
速度チェックのコードは以下の通り。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from pymongo import MongoClient
import json
import time # 時間計測
Client = MongoClient()
db = Client.testdb
Collection = db.testCollection
start = time.time() # 計測開始
for i in range(0, 10000): # 10,000回ループ
aw_string = r'''{"created_at":"Sat Sep 24 15:35:21 +0000 2016", ...(長いので略)... }'''
json_object = json.loads(raw_string)
Collection.insert(json_object)
elapsed_time = time.time() - start # 計測終了、開始時を引いて経過時間計算
print('実行時間:', elapsed_time * 1000 ,' [ms]')
JSONデータは10KB程度のちょっと長めのもの。画像URLが4つ分、ハッシュタグなども入ったものです。
前回取得したデータで一番大きかったのが25KB、小さいほうでは2KB。平均7KBからするとちょっと大きい?位のデータ。
つまりこれの実行時間が1時間以内なら、だいたい問題ない。
(Python) >Python .\MongoSpeed.py
実行時間: 11719.62308883667 [ms]
(Python) >
は?
(つづく。)