はじめに
Go歴=GOPATHを通してからの年月(独断と偏見による定義)はおよそ1年半になった。
GoはRubyの次に学習したい言語、Googleが開発しているモダンな言語(2009年に設計された。Go歴が10年を超えたとかいってる輩がいたら鼻で笑ってあげましょう)、MercariやCyberAgentなど国内のメガベンチャーを筆頭に使われている言語であったりと、1年半前は非常に話題性に富む言語だった。
一方で、GoでHello Worldをすることは以下の5行で済むが、Effective Goを初めから読むには難易度が高かったり、Tour of goはやってみたがしっくりこない感じがする人も多いのではないか。特に初心者のフェーズの次の段階で知りたい知識を体系的にまとめた文献はない気がする。
package main
import "fmt"
func main() {
fmt.Println("Hello World")
}
自分自身は、実務でコードを書きながらレビューをされることで知見を得て、Goの書き方を理解してきた。
また、プログラミングを始めてからおよそ1年半の間にRuby,Python,Java,Node×Typescriptを書いてきたが、他言語と比較をすることでもGo独自の書き方や思想について考えてきた。
今回は、主に僕が約1年のGoでの実務の中でレビューされたことを中心に、初心者を抜けて自分的には動くコードだがGoの先輩は許してくれない、レビュー時に指摘されるであろう点についてまとめた。
まだまだ完全に地雷を踏み切ってはいないと思っているので、指摘点があれば編集リクエストをお願いします。
Goroutine
Goを語る上で、外せないのがGoroutineである。
Goの良さを聞かれた時に、並行処理が書きやすいと非Gopherエンジニアに言っていたが、ここ最近まであまり理解していなかった。
CyberAgentのインターンに行った際に、Goroutineを意地でも書かないといけない機会に遭遇し、メンターさんに教えてもらいながら理解を深めていった。
そもそも並行処理と並列処理の違いもわかっていなかったので、詳細をまとめた記事が以下
並行処理と並列処理の違い
基本的にコードは上から下に向かってコードが実行される。
しかし、各行での実行にかかる時間には全く異なる。
例えば、
num++
client.DB.CreateUser(user)
変数の加算とDBへのデータの永続化にかかる時間が異なるのは明確だろう。
例えば、DBへの処理が複数ある場合、各々の処理が完了するまでコードの実行が止まってしまうと、全体としてのコードの実行時間は長くなってしまう。
独立した永続化の処理を並行して行うことができれば、実行時間を短縮できる。
一方で、同じメモリを複数のプロセスで扱うには、デッドロックや値の同期に関しての問題が発生する。
Goでは、書き方さえミスしなければ、並行処理が比較的容易に書けて、並列に処理が実行されることが期待できる。
単純な並行処理のコードサンプル
package main
import (
"time"
"fmt"
)
func main() {
// 無名関数。又の名をクロージャ
go func() {
time.Sleep(3 * time.Second)
fmt.Println("実行おわた!!")
}()
fmt.Println("実行はよ")
time.Sleep(10 * time.Second)
}
実行はよ
実行おわた!!
実行される順番
無名関数の実行開始
↓
実行はよ出力
↓
time.Sleep(10 * time.Second)実行開始
↓
実行おわた!!出力
↓
無名関数の実行終了
↓
time.Sleep(10 * time.Second)実行終了
↓
main関数終了
である。まあ、有名な話だ。
今回は一つのGroutineだが、複数のGoroutineを思うがままに使いたい時がある。
週2ぐらいである。
その際にどうしたら良いか。
実行中のGoroutineの数をカウントして、全てのGoroutineの実行が終了したら次のコードに進めるようにしたい。
そんな時は、"sync" パッケージのwaitGroupを使う。
func main() {
wg := &sync.WaitGroup{}
for i := 0; i < 10; i++ {
wg.Add(1) // wgをインクリメント Goroutineの動かす前にするのが大事
go func() {
fmt.Println(i)
wg.Done() // wgをデクリメント
}()
}
wg.Wait() // wgがゼロになるまで待つ。
}
余談
余談なのだが
上のコードではiの値を使ってないから良いが、
無名関数の中でiを出力したら面白いことがおきる。
func main() {
wg := &sync.WaitGroup{}
for i := 0; i < 10; i++ {
wg.Add(1) // wgをインクリメント Goroutineの動かす前にするのが大事
go func() {
fmt.Println(i)
wg.Done() // wgをデクリメント
}()
}
wg.Wait() // wgがゼロになるまで待つ。
}
./prog.go:19:16: loop variable i captured by func literal
Go vet exited.
10
10
10
10
10
10
10
10
10
10
出力したい値が全部10になってしまう。
なぜこのような結果になるかというと、goroutineの実行より先に、forのループが回ってしまうからだ。
対応策は何個かあるが、自分が一番綺麗だと思うのが以下。
func main() {
wg := &sync.WaitGroup{}
for i := 0; i < 10; i++ {
wg.Add(1) // wgをインクリメント Goroutineを動かす前にするのが大事
go func(i int) {
fmt.Println(i)
wg.Done() // wgをデクリメント
}(i)
}
wg.Wait() // wgがゼロになるまで待つ。
}
9
0
1
2
3
4
5
6
7
8
無名関数に引数を追加することで、forのループごとのiで無名関数を実行できるようにしたことで、実行より先にforのloopが終わることを防ぐことができる。
1~9の順番にならないのは、Goroutineの処理が完了する順番はこちらでユーザ側で制御できないからお愛想。特に今回は問題ないので。
関連し合う複数の処理単位で、Waitすることで、独立した処理の実行を並行に書くことができる。
他の関数でも使われるデータを扱う関数を上に書くべきである。
var user *User
var room *Room
var message *Message
user = getUser()
wg := &sync.WaitGroup{}
wg.Add(1)
go func() {
defer wg.Done()
room = getRoomFromUserID(user.ID)
}
wg.Add(1)
go func() {
defer wg.Done()
message = getMessageFromRoom(room.ID)
}
wg.Wait()
UserRoomUpdate(user, room, message) // ユーザとルームとメッセージを使う処理
syncMapや、デッドロックについての知見も共有したいが、長くなりそうなので別の機会に記事を書こうと思う。
引数
before
func hoge(hoge string, fuga string, num int) error
after
func hoge(hoge, fuga string, num int) error
確かに。こっちの方がわかりやすい。(これはなんとかしてPRのレビューで先輩のアラを探そうとした時に、「引数名抜けてまっせ」と指摘したが返り討ちにあった苦い思い出。ダサい。)
before
// これ以降も使う構造体
type User struct {
ID string
}
interface (
func hoge(ctx context.Context, user *User) error
)
after
interface (
func hoge(context.Context, *User) error
)
インターフェイス内の引数がプリミティブな型(intとかstringとか)を含まなかったら、引数名を省略しても良い。
命名に関して追加の情報はないので。
戻り値
before
func hoge() error {
_, err := fuga()
if err != nil {
return err
}
}
after
func hoge() (err error) {
_, err = fuga()
if err != nil {
return
}
}
戻り値を命名しないこともできるが、命名することで
return err→ return
だけで書くことでき、関数内のerrハンドリングが多くなった時にコード量が減って嬉しい。
余談
Effective Go曰く
関数の戻り値が複数ってのはGo言語の特徴で、使われ方としては正常値とエラーが返されることが多い。
最近、TypeScript×Nodeでコードを書く機会があり、try-throw-catchを書くことがあったが、Goには例外機構がない。多値返却の理由と例外機構がないことは密接に関わり合っている。
↓の記事がなぜGoにtry-throw-catchがないのか、Go言語の仕様を元にかなり詳細に記載してあるので、興味がある人はぜひ読んで欲しい。
「例外」がないからGo言語はイケてないとかって言ってるヤツが本当にイケてない件
スライス
プログラミングを初心者を抜け出したら、メモリ領域とか気にしなくてはならない。
扱うデータ量が多くなればなるほど、使用するメモリは想像以上に大きくなる。
以下は自分が踏んだ地雷。
type AdminUser struct {
ID int
UserID string
}
func (users []*User) {
// サンプル用の意味のない処理
au := make([]*AdminUser, 0) // 容量を0にしてsliceを定義
for i, user := range {
au = append(au, &AdminUser{
ID: i, // 急にIDがintで謎だがスルーしてくれ
UserID: user.ID,
})
}
fmt.Println(au)
}
おわかりいただけただろうか。
goではarrayとsliceが存在し、arrayの容量は固定で、sliceの容量は動的だ。
sliceには、要素数と容量が存在し、要素数はsliceに実際に入っている値の個数で、容量は確保できる要素数である。
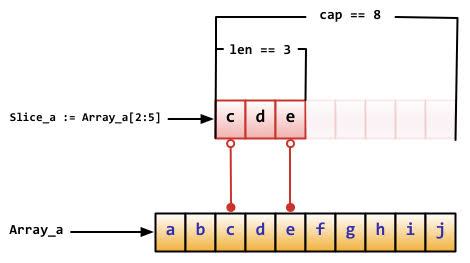
上のコードでは、makeを行っているが、この際に容量のパラメータを設定していない。その場合にどうなるかと言うとauの容量は初めてのappendが行われるまで0になっている状態だ。
容量が0のsliceに要素を一つ追加するので、容量を超えたappendになる。
容量を確保するために、auを別のメモリにコピーすることを容量を超えたappendが行われ度に繰り返される。
容量が2以上になると、既存の容量の倍の容量を確保するようにgoは書かれているぽい。
一応以下が確認のためのコードである。
func main() {
sl := make([]string, 0)
fmt.Println(cap(sl)) // capでsliceの容量がわかる
sl = append(sl, "1")
fmt.Println(cap(sl))
sl = append(sl, "2")
fmt.Println(cap(sl))
sl = append(sl, "3")
fmt.Println(cap(sl))
sl = append(sl, "4")
fmt.Println(cap(sl))
sl = append(sl, "5")
fmt.Println(cap(sl))
}
0
1
2
4
4
8
何がいいたいかというと、sliceは初期化のタイミングで長さがわかっていたら、容量を書きましょうということ。
これによって、コピーにかかる時間とメモリ量が少なくなり実行が早くなる。
自分自身そこまで、メモリ量は大切ではないと思っていたが、pythonのpandasのDataFrameに数十万件のデータをappendする際に、書き方を間違えて変数がコピーされまくりGCの回収が間に合わなくなりループの実行が絶望的に遅くなってしまった😱ので、メモリ量を気にするようにしている。
GoのGCについてMediumに簡単にまとめたので、よかったらこちらもどうぞ。
GoのGCについて
sliceの容量を確保したコードは以下の通り!!!
func (users []*User) {
au := make([]*AdminUser, 0, len(users)) // 要素数を0、容量をusersの要素数に!
...
}
マップ
ヌルポは恥。しかし実行して見ないとわからないものである。
Goのmapでは、空のkeyに値をいれる可能性があるコードでもbuildが通ってしまう。
サンプルコード
var hogeMap map[int]string
func hoge() {
hogeMap[1] = "hoge"
fmt.Println(hogeMap[1])
}
panic: assignment to entry in nil map
mapでのruntimeエラーの予防策は以下である。
var hogeMap map[int]string
func hoge() {
if _, ok := hogeMap[1]; ok {
hogeMap[1] = "hoge"
fmt.Println(hogeMap[1])
}
}
nilチェックを代入前にすることでruntimeエラーを防ぐことができる。
上記のようなシンプルなコードだと、nilチェックをしないとという気持ちになるのだが、複雑なコードになってくると忘れてしまうこともあるので、気を付けないといけぬ。
ポインタ
引数に構造体を含める場合、以下の書き方が使われる。
書き方①
func hoge(user User) error {}
書き方②
func hoge(user *User) error {}
書き方①②の違いは、Userに*がつくかつかないかである。
①の場合は、Userの値が引数で渡される(値渡し)
②の場合は、Userのメモリのアドレスが引数で渡される(ポインタ渡し)
主な違いは、①の場合は、引数の値を関数内で変更した場合に、呼び出し元の関数でのUserの値は変わることはないが、②の場合は、引数の値を関数内で変更した場合に、呼び出し元の関数でのUserの値は変わる。
以下例である。
書き方①
type User struct {
ID string
}
func hoge() {
user := User{
ID: "id",
}
fuga(user)
fmt.Println(user)
}
func fuga(user User) {
user.ID = "idddd"
}
&{id}
書き方②
type User struct {
ID string
}
func hoge() {
user := &User{
ID: "id",
}
fuga(user)
fmt.Println(user)
}
func fuga(user *User) {
user.ID = "idddd"
}
&{idddd}
経験則だが、構造体には特別な理由がない限り、ポインタ渡しで書くべきだと思う。
(理由があり、納得させられる自信があるならok)
構造体とメソッド
GoにはRubyやJavaなどのオブジェクト指向言語とは異なりクラスが予約語にはない。
しかし、構造体とメソッドに関係性を持たせることはできる。
type User struct {
ID string
Name string
}
func (u *User) Name() string {
return u.Name + "さん"
}
関数名の前に紐付けたい構造体を書くことで、構造体にフィールドにアクセスすることができる。
まとめ
かなり長くなってしまったが、PRで指摘された点から始まり、Goの書き方について、1年前の自分に教えたいことを詰め込んだ。
かなり厳選しているので、まだまだ書きたいことはあるが、これくらいにしておこうと思う。
まだまだ絶賛参加受付中なので、気になった方はぜひ参加して欲しい。
千葉大学 Advent Calender
参考
https://qiita.com/Maki-Daisuke/items/80cbc26ca43cca3de4e4
https://qiita.com/tenntenn/items/e04441a40aeb9c31dbaf
https://qiita.com/sudix/items/67d4cad08fe88dcb9a6dhttps://golang.org/doc/effective_go.html
https://qiita.com/ruiu/items/dba58f7b03a9a2ffad65