はじめに
学習済みのモデルを使ってサクッと物体検出をするということと、自分で任意の内容を学習させて物体検出をするということには心理的にまあまあなハードルがあると思っています。
学習データの準備が面倒そう、学習させること自体もめんどそうだなと思います。
自分が触っていた物体検出の仕組みが用意している学習済みモデルで検出できないものを検出しないといけないことになり、重い腰を上げて一番楽そうな方法を模索したのでその結果を記事にまとめました。
学習させないといけなくなったけど、楽したいぜ、という人には意味のある内容かと思います。詳しい人は読まなくていい内容です。
使用する物体検出のアルゴリズム、モデル
日本語のドキュメントがあったりPyTorchでサクッと動かせたりと準備が楽そうだったのでYOLOv8を使うことにしました。(実際楽でした)
手順
クイックスタートに従い準備を進めていきます。と言ってもpip一回ですが。
1. パッケージのインストール
Python>=3.8,PyTorch>=1.8.である必要があります。
# Install the ultralytics package from PyPI
pip install ultralytics
環境準備が面倒という人はGoogle Colabからどぞ。
余談ですがYOLOはバージョンごとに作者がバラバラなので全部YOLOって言っていいのかみたいな議論もあるのですが、v8についてはUltralyticsという会社がリリースしたのでパッケージ名もこれになってます。
2. 早速使ってみる
とりあえず動くか試してみましょう。
yolo predict model=yolov8n.pt source='https://ultralytics.com/images/zidane.jpg' imgsz=320
前述のコマンドを実行するとこんな画像が保存されます。ちゃんと動きました。

ちなみにこちらが学習済みの内容(80個のオブジェクトがあります)です。検出したいものがこの中にあるなら追加で学習させる作業はやらなくてOKです。
学習済みオブジェクト一覧を開く
0: person
1: bicycle
2: car
3: motorcycle
4: airplane
5: bus
6: train
7: truck
8: boat
9: traffic light
10: fire hydrant
11: stop sign
12: parking meter
13: bench
14: bird
15: cat
16: dog
17: horse
18: sheep
19: cow
20: elephant
21: bear
22: zebra
23: giraffe
24: backpack
25: umbrella
26: handbag
27: tie
28: suitcase
29: frisbee
30: skis
31: snowboard
32: sports ball
33: kite
34: baseball bat
35: baseball glove
36: skateboard
37: surfboard
38: tennis racket
39: bottle
40: wine glass
41: cup
42: fork
43: knife
44: spoon
45: bowl
46: banana
47: apple
48: sandwich
49: orange
50: broccoli
51: carrot
52: hot dog
53: pizza
54: donut
55: cake
56: chair
57: couch
58: potted plant
59: bed
60: dining table
61: toilet
62: tv
63: laptop
64: mouse
65: remote
66: keyboard
67: cell phone
68: microwave
69: oven
70: toaster
71: sink
72: refrigerator
73: book
74: clock
75: vase
76: scissors
77: teddy bear
78: hair drier
79: toothbrush
3. 学習させる
今回諸事情によりバーコードを検出させる必要がありました。これは事前学習されていませんので自分でどうにかする必要があります。この記事の説明はバーコードで進みますがこちらを自身の検出したいものに置き換えて進めてください。
ちなみに、学習に関するドキュメントはこちら→Model Training with Ultralytics YOLO
3.1. 学習方法の確認
ドキュメントを見るとわかりますが、1つのCPU or GPUを使うのか、複数GPUを使うのかなど、どんなハードウェアを使うかで微妙にやり方が変わります。私はM1のMacbookを使っているのでその例を書きます。
from ultralytics import YOLO
# ベースとするモデル
model = YOLO('yolov8n.pt')
# M1 macのGPUを使ってモデルを学習
results = model.train(
data='datasets/barcode_detection_one/data.yaml',
epochs=3,
imgsz=640,
device='mps'
)
trainの引数を説明します。
data: これは学習に使用するデータセットの設定ファイルへのパスです。あとで出てきます。
epochs: エポック数です。要は学習を何回繰り返すか指定します。
imgsz: 入力画像のサイズの指定です。640x640ピクセルの画像サイズを使うということです。
device: 学習に使用するデバイスの指定です。mps、つまりAppleのMetal Performance Shaderフレームワークを使うぞ、という指定をしています。M1使うぞーということです。
このプログラムを動かせば学習開始できるわけですがその前に学習用のデータを準備しないとです。
3.2 学習データの調達
通常学習データを準備するとなると、3種類の画像のセットを用意する必要があるかと思います。
※割合はイメージです
-
Train(学習用データセット):
全データセットの大部分を占める(70-80%程度)。モデルはこの画像群からパターンを学習する。 -
Valid(検証用データセット):
全体の一部を占める(10-20%程度)。トレーニング中にモデルの性能を評価するための画像群、モデルのトレーニングが適切に進行してるか確認する。 -
Test(テスト用データセット):
全体の一部を占める(10-20%程度)。トレーニング中には使用されず、モデルの最終評価に使用する。未知のデータに対してうまく動作するか確認する。
これらを何百枚、何千枚と自分で用意してひたすらラベリングを…というのは、ちょっと大変なので公開されているものを使うことにしました。
roboFlowというモデル構築のプラットフォームがあるのですが、その中にRoboflow Universeという、オープンソースのデータセットを公開してくれている大変便利なページがあります。
ここで検出したいものを探してみてください。
私はバーコードを検出する必要があるのでバーコードのデータセットを探してみました。
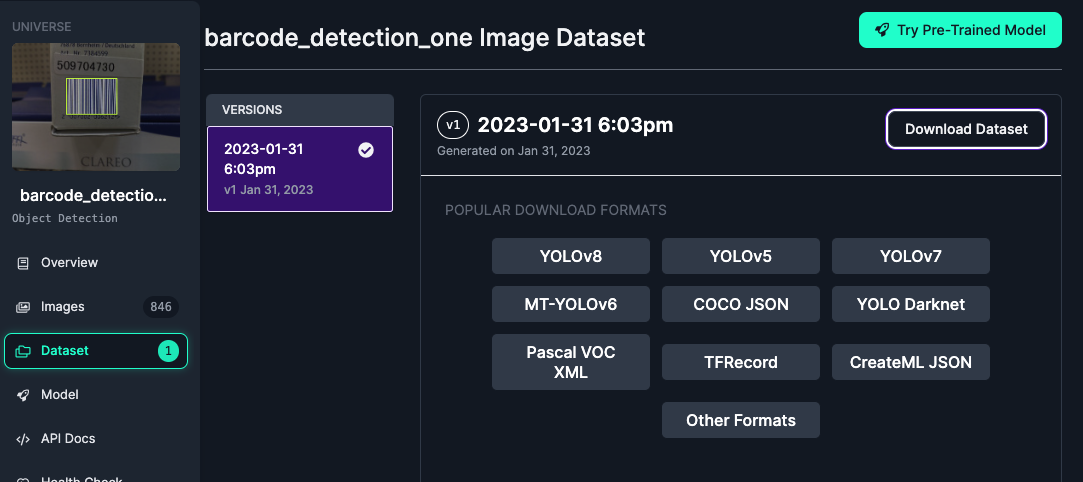
便利なのはフォーマットも選べることですね。今回はYOLOv8ですがそれ以外にも色々な形式を選択できます。(ダウンロードにはアカウント登録が必要です)
ちなみにTry Pre-Trained Modelという選択肢もあり…
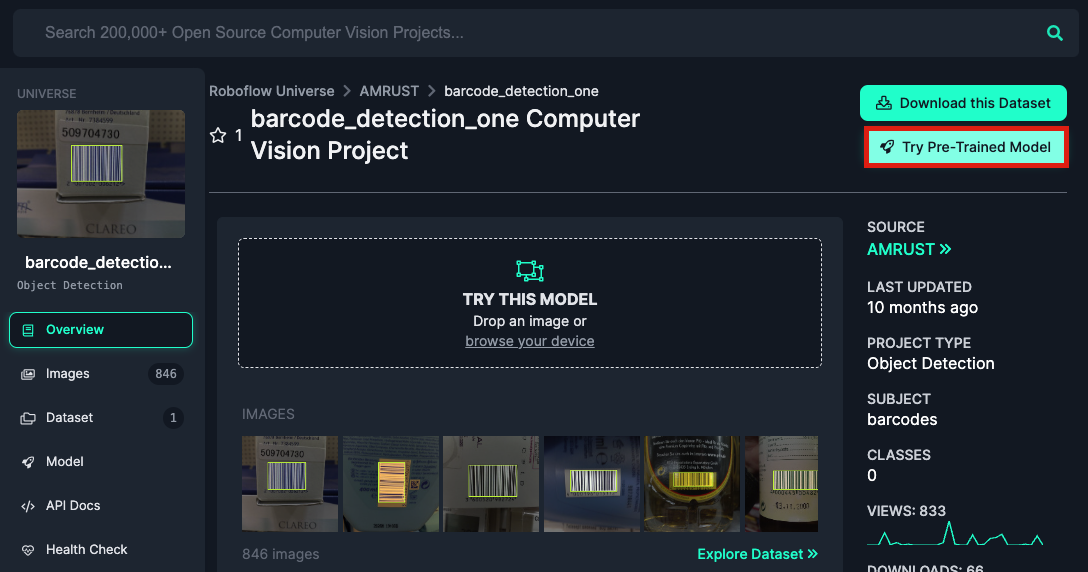
↓こんな感じでソースコードのサンプルもあり、API経由で学習済みのモデルをすぐ使うことができます。使いたいだけで学習方法興味ないです、という人はこの記事はここまでで良いと思います。笑
from roboflow import Roboflow
rf = Roboflow(api_key="API_KEY")
project = rf.workspace().project("barcode_detection_one")
model = project.version(1).model
# infer on a local image
print(model.predict("your_image.jpg", confidence=40, overlap=30).json())
# visualize your prediction
# model.predict("your_image.jpg", confidence=40, overlap=30).save("prediction.jpg")
# infer on an image hosted elsewhere
# print(model.predict("URL_OF_YOUR_IMAGE", hosted=True, confidence=40, overlap=30).json())
学習させてみるぞ、という方はYOLOv8のフォーマットを選んでダウンロードしましょう。
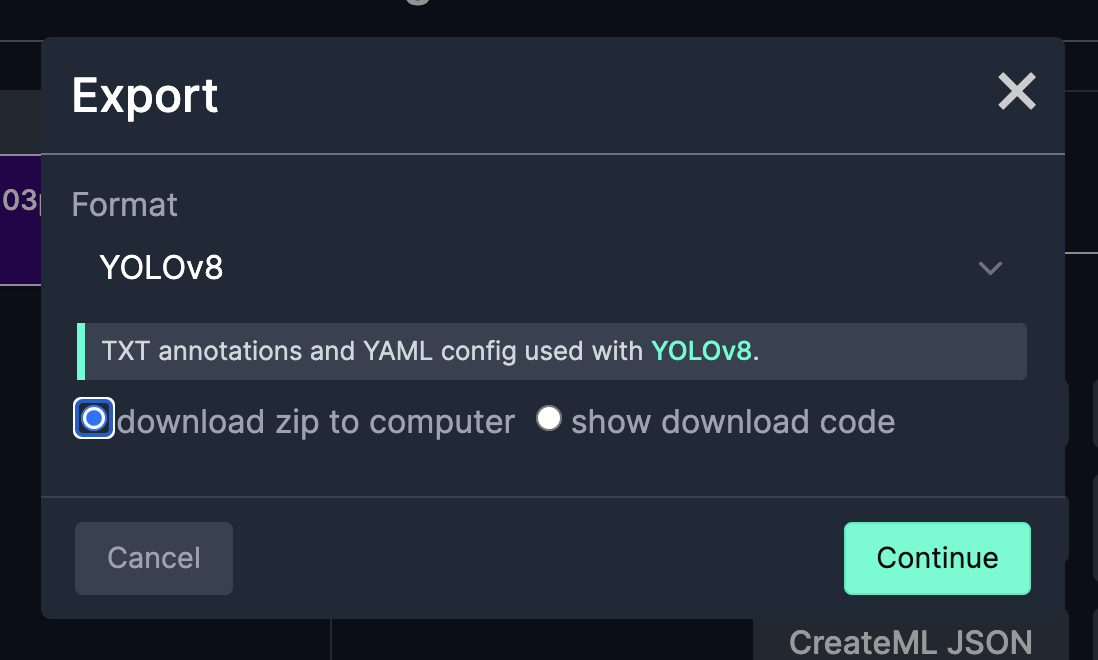
ダウンロードしてみた中身です。data.yamlが先ほどちょっと出てきたデータセットの設定ファイルです。
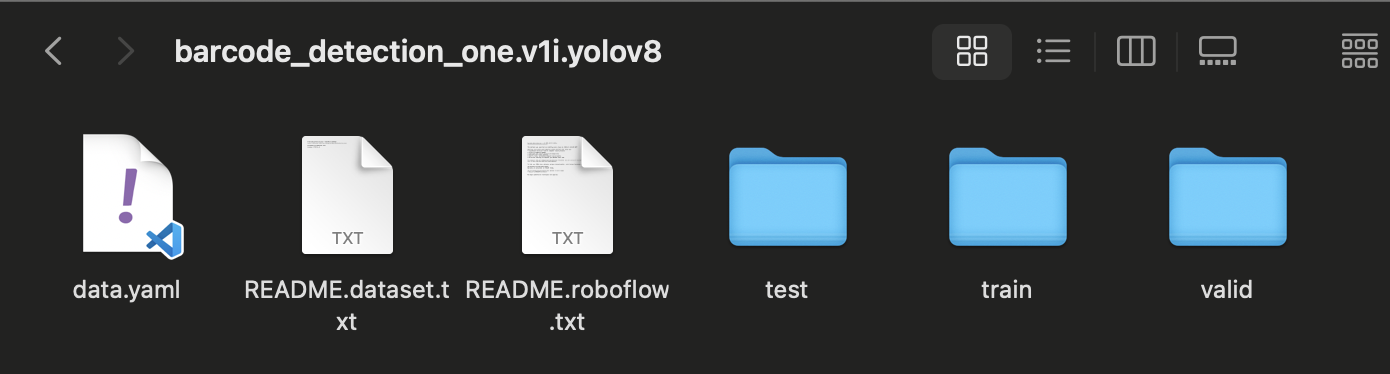
test,train,validそれぞれのフォルダに画像ファイルとラベルのファイル(矩形領域を表したもの)が格納されてます。
3.3 学習の実行
データセットが調達できたとので学習を実行してみましょう。
data='datasets/barcode_detection_one/data.yaml', の部分はご自身のdata.yamlのパスに書き換えて実行してください。
from ultralytics import YOLO
# ベースとするモデル
model = YOLO('yolov8n.pt')
# M1 macのGPUを使ってモデルを学習
results = model.train(
data='datasets/barcode_detection_one/data.yaml',
epochs=3,
imgsz=640,
device='mps'
)
学習が終わると、runs/runs/detect/train/weights/というフォルダにlast.ptとbest.ptという二つのファイルが生成されます。これらが学習を終えたモデルになります。
last.ptは学習の最後に保存されたモデルの重み、best.ptは学習中、最もパフォーマンスが良かった重みのファイルです。
4. 動作確認
早速動かしてみます!
from ultralytics import YOLO
model = YOLO('runs/detect/train/weights/last.pt')
# Predict the model
model.predict('test.png', save=True, conf=0.1)
机の上にあった本の写真で推論させてみたところ無事バーコードが検出されました。

まとめ
データセットの準備が大変そうでとっつきにくかったのですが、公開されているデータセットが世の中にはroboFlowに限らず色々とあるためそこまでハードルを感じる必要もないなと思いました。そもそも自分で学習させなくても、APIが結構ありますが。