この記事の要約
やったこと
- オンプレ環境でAIモデルの開発やデプロイができる環境を作るために、NVIDIA DeepOpsというツールを使ってk8sクラスタごとデプロイしてみた
感想
- GPUクラスタを構成する上で色々と必要になるコンポーネントは多いので、1つのツールでインストールが完結できる点が便利
- ただ一部コンポーネントはDeepOpsにソースコードごと組み込まれているので、新しいバージョンを使いたい場合は個別にインストールが必要かも(今回のケースではKubeflowがそうでした)
- 「色々あってオンプレで開発したい(しないといけない)」、「貴重なGPUノードをチーム/プロジェクトで効率よく使いまわしたい」といったシーンで役立ちそう
NVIDIA DeepOpsとは
本記事はDeepOps 22.08時点の情報です
ざっくり言えばGPUクラスタをお手軽に構築するためのツールです。
GPUクラスタは近年ではAI/MLの分野をはじめ、高い計算能力を求められるITインフラにて利用されることが多くなっていますね。
ツールそのものはGitHubにて公開されています。
DeepOpsの特徴
- Linuxサーバ群を束ねて、KubernetesまたはSlurmといったクラスタシステムを構成できる
- GPUを扱うためのプラグインやAI/MLツールキットであるKubeflowなど、機械学習基盤にまつわる多種多様なコンポーネント群をインストールできる
- 詳細はDeepOpsでデプロイできるコンポーネントの項を参照
- 各コンポーネントはモジュールとして提供されている。その恩恵として…
- 必要なコンポーネントに絞ってインストールすることができる
- 既存のk8sクラスタに追加コンポーネントだけインストールする、といった使い方もできる
- 自動化のエンジンとしては主にAnsibleが使われている
DeepOpsでデプロイできるコンポーネント
以下ではk8sに関連するコンポーネントのみ記載します
基本コンポーネント
DeepOpsでk8sクラスタをインストールした際にデフォルトで含まれているコンポーネント群です。
etcdやコンテナランタイムなど基本的なk8sスタックに加えて、k8s環境でGPUを扱うためのnvidia gpu operatorが含まれているのがこのツールの特徴ですね。
- kubernetes
- etcd
- docker
- containerd
- cri-o
- calico
- dashboard
- dashboard metrics scraper
- nvidia gpu operator
追加コンポーネント
k8sクラスタのデプロイ後、以下のコンポーネントを取捨選択してインストールできます。
Prometheusといったk8sで広く使われているものから、Kubeflowといった機械学習に特化したものまで様々あります。
- Kubernetes Dashboard
- ストレージプラグイン
- NFS Client Provisioner
- Ceph Cluster (deprecated)
- NetApp Astra Trident
- 監視
- Grafana
- Prometheus
- Alertmanager
- ロギング
- Centralized syslog(マスタノードへのログ集約)
- ELK logging
- コンテナレジストリ
- ロードバランサとIngress
- MetalLB
- Ingress controller
- Kubeflow
- NVIDIA Network Operator
システム要件
Provisioning System
Provisioning SystemとはAnsible playbookなどを実行するサーバです。
いわば構築用の踏み台なので、スペックに関しては必要最小限で良いかと思います。
- NVIDIA DGX OS 4, 51
- Ubuntu 18.04 LTS, 20.04 LTS
- CentOS 7, 8
Cluster System
Cluster SystemとはKubernetesもしくはSlurmのノードとして使用するサーバ群です。
こちらは実際にモデルのトレーニングや推論に使っていくリソースになりますので、自身のやりたいことを踏まえて必要十分なスペックのマシンを用意する必要があります。
ちなみにProvisioning Systemとして使ったサーバをCluster Systemの一部として構成することもできます。
- NVIDIA DGX OS 4, 51
- Ubuntu 18.04 LTS, 20.04 LTS
- CentOS 7, 8
今回構築する環境について
今回は自分なりに、機械学習モデルを作って動かすための最小限のインフラというテーマを設定して環境構築していきます。
完成形のイメージはこんな感じ。
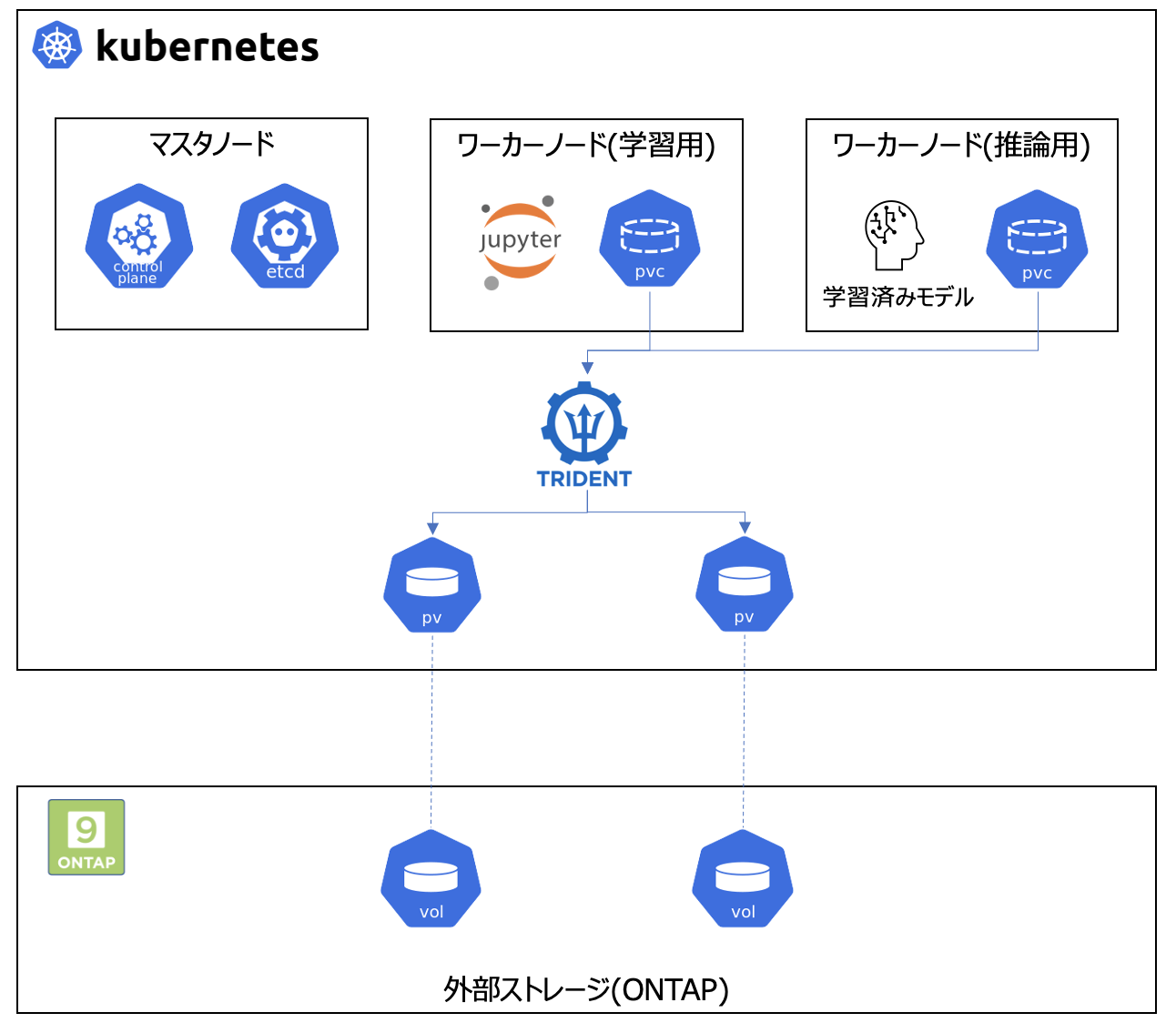
基本コンポーネント(Kubernetes)
今回は以下3つのサーバからなるk8sクラスタを構築します。
機械学習基盤と言いつつGPU載ってるマシンがありませんが、以下で説明する作業内容には影響ありません。
| ホスト名 | OS | スペック(CPU/MEM) | 用途 |
|---|---|---|---|
| master-01 | Ubuntu 20.04 | 4コア/8GB | マスタノードとして使用 |
| train-node-01 | Ubuntu 20.04 | 4コア/8GB | ワーカーノードとして使用 後々、taintsを設定してモデルトレーニング専用のノードとして使いたい |
| inference-node-01 | Ubuntu 20.04 | 4コア/8GB | ワーカーノードとして使用 後々、taintsを設定して推論専用のノードとして使いたい |
全て構築し終わった後に気づきましたが、TridentとかKubeflowとかを載せるインフラノード的なものも用意しておけば良かったですね…。
追加コンポーネント
上で挙げた追加コンポーネントの中から今回の目的に沿って必要そうなものに絞って導入します
| 分類 | 名称 | 導入目的 |
|---|---|---|
| ストレージプラグイン | NetApp Astra Trident | KubeflowインスタンスやKubeflowから払い出すJupyter Notebook Serverのデータを永続化するために使用。バックエンドのストレージは弊社環境内に導入済みのONTAPを使用。 |
| ロードバランサ/Ingress | Ingress controller | 機械学習モデルをデプロイし、WebアプリやAPIとしてクラスタ外部に公開する際に使用する想定 |
| 機械学習プラットフォーム | Kubeflow | 機械学習モデルの開発・デプロイに使用 |
DeepOpsを使って機械学習基盤をデプロイしてみる
初期セットアップ
ここから実際に手を動かしていきます。まずはDeepOpsを使うための下準備から。
SSH公開鍵認証の設定
DeepOpsを実行する上で、構築用のサーバ(Provisioning System)からCluster Systemを構成する各サーバへのSSH接続が必要となります。
Provisioning Systemにてキーペアを作成し、公開鍵を設定対象の各サーバにコピーします。
設定時のポイント
- キーペアはパスフレーズなしで作成する
- 各サーバにSSHログインする際のユーザ名は同じものに揃える
# キーペア作成
$ ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/home/netapp/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/netapp/.ssh/id_rsa
Your public key has been saved in /home/netapp/.ssh/id_rsa.pub
# 公開鍵を接続先のサーバにコピー(Cluster Systemを構成する全サーバに対して実施)
$ ssh-copy-id netapp@10.128.214.221
$ ssh-copy-id netapp@10.128.214.222
$ ssh-copy-id netapp@10.128.214.225
設定後、Provisioning Systemからssh <USER>@<HOSTNAME>を実行し、パスフレーズなしで各サーバにログインできるようになっていればOKです。
DeepOpsの初回セットアップ
GitHubからDeepOpsをダウンロードして、初回セットアップ用のシェルを叩きます。
セットアップ用シェルが完了すると自動的にvenvに切り替わります。
$ git clone https://github.com/NVIDIA/deepops
$ cd deepops
$ ./scripts/setup.sh
~~~中略~~~
*** Setup complete ***
To use Ansible, run: source /opt/deepops/env/bin/activate
Kubernetesのインストール
公式ドキュメントはこちら。
DeepOpsではkubesprayを利用してk8sのデプロイを自動化する仕組みとなっています。
設定ファイルの編集
k8sデプロイに使用する設定ファイル群を、実環境やデプロイしたいコンポーネントに合わせて更新していきます。
config/inventoryにはCluster Systemを構成する各サーバの接続先情報を記載します。
【設定例】config/inventory
#
# Server Inventory File
#
# Uncomment and change the IP addresses in this file to match your environment
# Define per-group or per-host configuration in group_vars/*.yml
######
# ALL NODES
# NOTE: Use existing hostnames here, DeepOps will configure server hostnames to match these values
######
[all]
#mgmt01 ansible_host=10.0.0.1
#mgmt02 ansible_host=10.0.0.2
#mgmt03 ansible_host=10.0.0.3
#login01 ansible_host=10.0.1.1
#gpu01 ansible_host=10.0.2.1
#gpu02 ansible_host=10.0.2.2
+ master-01 ansible_host=10.128.214.221
+ train-node-01 ansible_host=10.128.214.222
+ inference-node-01 ansible_host=10.128.214.225
######
# KUBERNETES
######
[kube-master]
#mgmt01
#mgmt02
#mgmt03
+ master-01
# Odd number of nodes required
[etcd]
#mgmt01
#mgmt02
#mgmt03
+ master-01
# Also add mgmt/master nodes here if they will run non-control plane jobs
[kube-node]
#gpu01
#gpu02
+ train-node-01
+ inference-node-01
[k8s-cluster:children]
kube-master
kube-node
######
# SLURM
######
[slurm-master]
#login01
[slurm-nfs]
#login01
[slurm-node]
#gpu01
#gpu02
# The following groups are used to break out individual cluster services onto
# different nodes. By default, we put all these functions on the cluster head
# node. To break these out into different nodes, replace the
# [group:children] section with [group], and list individual nodes.
[slurm-cache:children]
slurm-master
[slurm-nfs-client:children]
slurm-node
[slurm-metric:children]
slurm-master
[slurm-login:children]
slurm-master
# Single group for the whole cluster
[slurm-cluster:children]
slurm-master
slurm-node
slurm-cache
slurm-nfs
slurm-metric
slurm-login
######
# SSH connection configuration
######
[all:vars]
# SSH User
#ansible_user=ubuntu
#ansible_ssh_private_key_file='~/.ssh/id_rsa'
+ ansible_user=netapp
+ ansible_ssh_private_key_file='~/.ssh/id_rsa'
# SSH bastion/jumpbox
#ansible_ssh_common_args='-o ProxyCommand="ssh -W %h:%p -q ubuntu@10.0.0.1"'
config/group_vars/k8s-cluster.ymlではk8sクラスタのデプロイ構成をカスタマイズできます。
今回はデフォルトの設定から以下のカスタマイズを加えています。
- k8sバージョンを"v1.23.7"に指定
- NFS client provisionerを無効に設定(以降の手順で代替のストレージプロビジョナーであるAstra Tridentを導入するため)
【設定例】config/group_vars/k8s-cluster.yml
ansible_become: true
+ kube_version: "v1.23.7"
kubeadm_enabled: true
kube_api_anonymous_auth: true
kube_kubeadm_apiserver_extra_args:
service-account-issuer: "kubernetes.default.svc"
service-account-signing-key-file: "/etc/kubernetes/ssl/sa.key"
# Set to false due to kubespray bug: https://github.com/kubernetes-sigs/kubespray/issues/5059
kubectl_localhost: false
kubeconfig_localhost: true
helm_enabled: true
tiller_node_selectors: "node-role.kubernetes.io/master=''"
## Container runtime
## docker for docker, crio for cri-o and containerd for containerd.
container_manager: containerd
artifacts_dir: "{{ inventory_dir }}/artifacts"
# Reset Flex Volume path to the default. Kubespray changes the path, which breaks Rook
# see: https://github.com/kubernetes/community/blob/master/contributors/devel/sig-storage/flexvolume.md
kubelet_flexvolumes_plugins_dir: /usr/libexec/kubernetes/kubelet-plugins/volume/exec
# Provide option to use GPU Operator instead of setting up NVIDIA driver and
# Docker configuration.
deepops_gpu_operator_enabled: true
# Install NVIDIA Driver and nvidia-docker on node (true), not as part of GPU Operator (driver container, nvidia-toolkit) (false)
gpu_operator_preinstalled_nvidia_software: true
# Set the MIG labeling and use strategy to none, single, or mixed. See https://github.com/NVIDIA/k8s-device-plugin
k8s_gpu_mig_strategy: "mixed"
# When set to true, enables the PodSecurityPolicy admission controller and
# defines two policies: privileged (applying to all resources in kube-system
# namespace and kubelet) and restricted (applying all other namespaces).
# Addons deployed in kube-system namespaces are handled.
#podsecuritypolicy_enabled: false
# Pin the version of kubespray dashboard https://github.com/kubernetes/dashboard/releases/tag/v2.0.3
dashboard_enabled: true
dashboard_image_tag: "v2.0.3"
dashboard_image_repo: "kubernetesui/dashboard"
dashboard_metrics_scrape_tagr: "v1.0.4"
dashboard_metrics_scraper_repo: "kubernetesui/metrics-scraper"
# Ensure hosts file generation only runs across k8s cluster
hosts_add_ansible_managed_hosts_groups: ["k8s-cluster"]
# NFS Client Provisioner
# Playbook: nfs-client-provisioner.yml
- k8s_nfs_client_provisioner: true
+ k8s_nfs_client_provisioner: false
k8s_deploy_nfs_server: true
k8s_nfs_mkdir: true # Set to false if an export dir is already configured with proper permissions
k8s_nfs_server: '{{ groups["kube-master"][0] }}'
k8s_nfs_export_path: '/export/deepops_nfs'
# NFS Server
# This config will create an NFS server and share the given exports
# Playbook: nfs-server.yml, nfs-provisioner-client.yml
nfs_exports:
- path: '{{ k8s_nfs_export_path }}'
options: "*(rw,sync,no_root_squash)"
################################################################################
# Container registry #
################################################################################
kube_enable_container_registry: false
docker_insecure_registries: "{{ groups['kube-master']|map('regex_replace', '^(.*)$', '\\1:5000')|list + ['registry.local:31500']}}"
crio_insecure_registries: "{{ groups['kube-master']|map('regex_replace', '^(.*)$', '\\1:5000')|list + ['registry.local:31500']}}"
docker_registry_mirrors: "{{ groups['kube-master'] | map('regex_replace', '^(.*)$', 'http://\\1:5000') | list }}"
# TODO: Add support in containerd for automatically setting up registry
# mirrors, not just the k8s-local registry
containerd_insecure_registries:
"registry.local:31500": "http://registry.local:31500"
# Work-around for https://github.com/kubernetes-sigs/kubespray/issues/8529
nerdctl_extra_flags: " --insecure-registry"
image_command_tool: "crictl"
################################################################################
# Logging with rsyslog #
################################################################################
kube_enable_rsyslog_server: true
kube_enable_rsyslog_client: true
rsyslog_server_hostname: "{{ groups['kube-master'][0] }}"
rsyslog_client_tcp_host: "{{ rsyslog_server_hostname }}"
rsyslog_client_group: "k8s-cluster"
接続テスト
上記で更新したインベントリファイルの設定をもとにAnsible経由で各サーバへ接続確認を行います。
BECOME passwordにはsudo時のパスワードを入力します。
PLAY RECAPの欄で全サーバにOKのフラグが立っていればここまでの設定はOKです。
$ ansible all -m raw -a "hostname" -K
BECOME password:
PLAY [Ansible Ad-Hoc] ******************************************************************************************************************************************************
TASK [raw] *****************************************************************************************************************************************************************
changed: [master-01]
changed: [train-node-01]
changed: [inference-node-01]
PLAY RECAP *****************************************************************************************************************************************************************
inference-node-01 : ok=1 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
master-01 : ok=1 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
train-node-01 : ok=1 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
Ansible Playbookの実行
Ansible Playbookを実行して、k8sクラスタをデプロイします。
完了まで結構時間がかかります(今回の環境では15分くらい?)
PLAY RECAPの欄にunreachableやfailedのフラグが立っているサーバが無ければOKです。
$ ansible-playbook -l k8s-cluster playbooks/k8s-cluster.yml -K
~~~中略~~~
PLAY RECAP *****************************************************************************************************************************************************************
inference-node-01 : ok=550 changed=115 unreachable=0 failed=0 skipped=819 rescued=0 ignored=2
master-01 : ok=909 changed=200 unreachable=0 failed=0 skipped=1502 rescued=0 ignored=9
train-node-01 : ok=550 changed=115 unreachable=0 failed=0 skipped=820 rescued=0 ignored=2
デフォルト設定ではProvisioning System上にデプロイしたk8sクラスタに対するkubeconfigが自動でセットアップされます。
念の為、kubectlでAPIサーバへの接続確認しておきましょう。
$ kubectl get node
NAME STATUS ROLES AGE VERSION
inference-node-01 Ready <none> 46m v1.23.7
master-01 Ready control-plane,master 47m v1.23.7
train-node-01 Ready <none> 46m v1.23.7
また今回はGPUノードがないので実機で試せませんが、以下のシェルスクリプトを実行して、k8s上でGPUワークロードがちゃんと実行できるかテストできます。
export CLUSTER_VERIFY_EXPECTED_PODS=1 # Expected number of GPUs in the cluster
./scripts/k8s/verify_gpu.sh
ストレージプラグイン(Astra Trident)のインストール
つぎにk8sで永続ストレージ(PV)を扱うためのストレージプラグインをインストールします。公式ドキュメントはこちら
今回の環境では弊社NetAppのストレージを永続ストレージとして使用するため、NetAppストレージに対応したプラグインであるAstra Tridentを導入します。
設定ファイルの編集
まずはk8sデプロイ時と同様に、Ansible Playbook向けの設定ファイルを編集します。
managementLIF, dataLIF, svm, username, passwordといったONTAP SVMに関するパラメータは各環境に合わせて更新が必要になります。
その他はAstra Tridentの動作に関するパラメータですので詳細はAstra Tridentの公式ドキュメントをご覧ください。
今回は導入バージョンのみカスタマイズを加えて、最新版のv22.10を導入する設定にしました。
【設定例】config/group_vars/netapp-trident.yml
---
# vars file for netapp-trident playbook
# URL of the Trident installer package that you wish to download and use
- trident_version: "22.01.0"
+ trident_version: "22.10.0"
trident_installer_url: "https://github.com/NetApp/trident/releases/download/v{{ trident_version }}/trident-installer-{{ trident_version }}.tar.gz"
# Namespace to install Trident in
trident_namespace: deepops-trident
# Denotes whether or not to create new backends after deploying trident
# For more info, refer to: https://netapp-trident.readthedocs.io/en/stable-v20.04/kubernetes/operator-install.html#creating-a-trident-backend
create_backends: true
# List of backends to create
# For more info on parameter values, refer to: https://netapp-trident.readthedocs.io/en/stable-v20.04/kubernetes/operations/tasks/backends/ontap.html
# Note: Parameters other than those listed below are not avaible when creating a backend via DeepOps
# If you wish to use other parameter values, you must create your backend manually.
backends_to_create:
- backendName: ontap-flexvol
storageDriverName: ontap-nas # only 'ontap-nas' and 'ontap-nas-flexgroup' are supported when creating a backend via DeepOps
- managementLIF: 10.61.188.40
+ managementLIF: 10.128.214.80
- dataLIF: 192.168.200.41
+ dataLIF: 10.128.214.226
- svm: ai221_data
+ svm: ai_control_plane
username: admin
- password: NetApp!23
+ password: P@ssw0rd
storagePrefix: trident
limitAggregateUsage: ""
limitVolumeSize: ""
nfsMountOptions: ""
defaults:
spaceReserve: none
snapshotPolicy: none
snapshotReserve: 0
splitOnClone: false
encryption: false
unixPermissions: 777
snapshotDir: false
exportPolicy: default
securityStyle: unix
tieringPolicy: none
- backendName: ontap-flexgroup
storageDriverName: ontap-nas-flexgroup # only 'ontap-nas' and 'ontap-nas-flexgroup' are supported when creating a backend via DeepOps1
- managementLIF: 10.61.188.40
+ managementLIF: 10.128.214.80
- dataLIF: 192.168.200.41
+ dataLIF: 10.128.214.226
- svm: ai221_data
+ svm: ai_control_plane
username: admin
- password: NetApp!23
+ password: P@ssw0rd
storagePrefix: trident
limitAggregateUsage: ""
limitVolumeSize: ""
nfsMountOptions: ""
defaults:
spaceReserve: none
snapshotPolicy: none
snapshotReserve: 0
splitOnClone: false
encryption: false
unixPermissions: 777
snapshotDir: true
exportPolicy: default
securityStyle: unix
tieringPolicy: none
# Add additional backends as needed
# Denotes whether or not to create new StorageClasses for your NetApp storage
# For more info, refer to: https://netapp-trident.readthedocs.io/en/stable-v20.04/kubernetes/operator-install.html#creating-a-storage-class
create_StorageClasses: true
# List of StorageClasses to create
# Note: Each item in the list should be an actual K8s StorageClass definition in yaml format
# For more info on StorageClass definitions, refer to https://netapp-trident.readthedocs.io/en/stable-v20.04/kubernetes/concepts/objects.html#kubernetes-storageclass-objects.
storageClasses_to_create:
- apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: ontap-flexvol
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: csi.trident.netapp.io
parameters:
backendType: "ontap-nas"
- apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: ontap-flexgroup
provisioner: csi.trident.netapp.io
parameters:
backendType: "ontap-nas-flexgroup"
# Add additional StorageClasses as needed
# Denotes whether or not to enable volume snapshots in your Kubernetes cluster
# For more info, refer to: https://netapp-trident.readthedocs.io/en/stable-v21.01/kubernetes/operations/tasks/volumes/snapshots.html
enable_volume_snapshots: true
# List of volume snapshot CRDs to create
volume_snapshot_CRD_manifest_URLs:
- https://raw.githubusercontent.com/kubernetes-csi/external-snapshotter/release-3.0/client/config/crd/snapshot.storage.k8s.io_volumesnapshotclasses.yaml
- https://raw.githubusercontent.com/kubernetes-csi/external-snapshotter/release-3.0/client/config/crd/snapshot.storage.k8s.io_volumesnapshotcontents.yaml
- https://raw.githubusercontent.com/kubernetes-csi/external-snapshotter/release-3.0/client/config/crd/snapshot.storage.k8s.io_volumesnapshots.yaml
# List of snapshot controller manifest URLs
snapshot_controller_manifest_URLs:
- https://raw.githubusercontent.com/kubernetes-csi/external-snapshotter/release-3.0/deploy/kubernetes/snapshot-controller/rbac-snapshot-controller.yaml
- https://raw.githubusercontent.com/kubernetes-csi/external-snapshotter/release-3.0/deploy/kubernetes/snapshot-controller/setup-snapshot-controller.yaml
# List of volume snapshot classes to create
volume_snapshot_classes_to_create:
- apiVersion: snapshot.storage.k8s.io/v1beta1
kind: VolumeSnapshotClass
metadata:
name: csi-snapclass
driver: csi.trident.netapp.io
deletionPolicy: Delete
# Denotes whether or not to copy tridenctl binary to localhost
copy_tridentctl_to_localhost: true
# Directory that tridentctl will be copied to on localhost
tridentctl_copy_to_directory: ../../ # will be copied to 'deepops/' directory
Ansible Playbookの実行
Ansible Playbookをキックして、Astra Tridentをセットアップします。
例によってunreachableやfailedのタスクがなければOKです。
$ ansible-playbook -l k8s-cluster playbooks/k8s-cluster/netapp-trident.yml -K
~~~中略~~~
PLAY RECAP *****************************************************************************************************************************************************************
inference-node-01 : ok=1 changed=0 unreachable=0 failed=0 skipped=1 rescued=0 ignored=0
master-01 : ok=14 changed=5 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
train-node-01 : ok=1 changed=0 unreachable=0 failed=0 skipped=1 rescued=0 ignored=0
デフォルトの構成ではストレージクラスとそれらに紐づくTridentバックエンドが各2つずつ作成されます。
2つのストレージクラスにはざっくりと以下の様な違いがあります。
- ontap-flexgroup: ペタバイト級の大容量ボリュームをサポートするストレージクラス(ONTAPのFlexGroupに由来)
- ontap-flexvol: 汎用的な用途に適した多機能なストレージクラス(ONTAPのFlexVolumeに由来)
これらのストレージクラスから払い出されたPVはKubeflow上で実行するJupyter NotebookやPipelineから利用できますので、「このPVには画像データたくさん格納したいからontap-flexgroupの方を使おう」といった感じでPVの用途に応じて使い分け頂くと良いかと思います。
# ストレージクラスの一覧確認
$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
ontap-flexgroup csi.trident.netapp.io Delete Immediate false 3m58s
ontap-flexvol (default) csi.trident.netapp.io Delete Immediate false 3m58s
# Tridentバックエンドの一覧確認
$ ./tridentctl get backend -n deepops-trident
+-----------------+---------------------+--------------------------------------+--------+---------+
| NAME | STORAGE DRIVER | UUID | STATE | VOLUMES |
+-----------------+---------------------+--------------------------------------+--------+---------+
| ontap-flexvol | ontap-nas | 2e06767f-b4b4-458e-ab17-de52678154a4 | online | 0 |
| ontap-flexgroup | ontap-nas-flexgroup | e87381d8-5e0a-490e-aa1b-4c4c4771caae | online | 0 |
+-----------------+---------------------+--------------------------------------+--------+---------+
Kubeflowのインストール
最後にKubeflowをデプロイします。
Kubeflowは機械学習システムにまつわる様々な機能を備えたツールキットという位置付けのオープンソースなソフトウェアになります。
Kubeflowもこれまで同様、DeepOpsによりインストールする事ができます。
ただしこのKubeflow、k8sやAstra Tridentとは異なり、どうやらバージョンを指定してインストールすることができないようです。
その証拠にconfig/kubeflow-install/manifestsディレクトリ配下を見てみると、ある時点のKubeflowのソースコードがまるごと格納されています。
# DeepOpsに組み込まれているKubeflowのソースコード
$ ls -l config/kubeflow-install/manifests/
total 88
drwxrwxr-x 15 netapp netapp 4096 Nov 18 07:46 apps
drwxrwxr-x 11 netapp netapp 4096 Nov 18 07:46 common
drwxrwxr-x 15 netapp netapp 4096 Nov 18 07:46 contrib
drwxrwxr-x 4 netapp netapp 4096 Nov 18 07:46 docs
drwxrwxr-x 2 netapp netapp 4096 Nov 18 07:46 example
-rw-rw-r-- 1 netapp netapp 97 Nov 18 07:46 go.mod
-rw-rw-r-- 1 netapp netapp 16249 Nov 18 07:46 go.sum
drwxrwxr-x 3 netapp netapp 4096 Nov 18 07:46 hack
-rw-rw-r-- 1 netapp netapp 11357 Nov 18 07:46 LICENSE
-rw-rw-r-- 1 netapp netapp 184 Nov 18 07:46 OWNERS
-rw-rw-r-- 1 netapp netapp 3083 Nov 18 07:46 prow_config.yaml
-rw-rw-r-- 1 netapp netapp 18301 Nov 18 07:46 README.md
drwxrwxr-x 9 netapp netapp 4096 Nov 18 07:46 tests
# DeepOps v22.08にはKubeflow v1.4が組み込まれている(記載時点の最新バージョンはv1.6)
$ ls -l config/kubeflow-install/manifests/docs/releases/
total 32
-rw-rw-r-- 1 netapp netapp 18585 Nov 18 07:46 handbook.md
-rw-rw-r-- 1 netapp netapp 144 Nov 18 07:46 OWNERS
drwxrwxr-x 2 netapp netapp 4096 Nov 18 07:46 release-1.4
drwxrwxr-x 2 netapp netapp 4096 Nov 18 07:46 retrospectives
Kubeflowに関しては比較的新しいソフトウェアであり、極力新しいバージョンを使いたいという思いもあったので今回はDeepOpsを使わずに最新版をインストールしてみたいと思います。
「多少古いバージョンでも気にしないよ」という方はDeepOpsを使ったインストール手順も参考として記載しておきますので、そちらをご参照ください。
Kubeflowのインストール(DeepOps非使用)
GitHubからソースコードをダウンロードします。
今回は記載時点で最新のリリースであるv1.6.1を使います。
$ wget https://github.com/kubeflow/manifests/archive/refs/tags/v1.6.1.tar.gz
$ tar -xvf v1.6.1.tar.gz
$ cd manifests-1.6.1
あとはKubeflowのドキュメントに従ってインストールします。
以下のワンライナーでKubeflowの全てのコンポーネントが一括デプロイできます。
$ while ! kustomize build example | kubectl apply -f -; do echo "Retrying to apply resources"; sleep 10; done
コマンドが完了したらデプロイされたpodの状態を確認します。全てRunnningであればOKです。
$ kubectl get pod -n auth
NAME READY STATUS RESTARTS AGE
dex-64775f9cf6-vn9s8 1/1 Running 0 18h
$ kubectl get pod -n cert-manager
NAME READY STATUS RESTARTS AGE
cert-manager-cainjector-66594d5d8c-glv68 1/1 Running 0 18h
cert-manager-f55458d74-nnnq2 1/1 Running 0 18h
cert-manager-webhook-6c466dbcbb-8np8q 1/1 Running 0 18h
$ kubectl get pod -n istio-system
NAME READY STATUS RESTARTS AGE
authservice-0 1/1 Running 0 18h
cluster-local-gateway-5df89bdbd9-6jq4s 1/1 Running 0 18h
istio-ingressgateway-55b6cffcbc-hhtmx 1/1 Running 0 18h
istiod-644b7bfb89-zg6h9 1/1 Running 0 18h
$ kubectl get pod -n knative-eventing
NAME READY STATUS RESTARTS AGE
eventing-controller-5d6dfd85b5-j67kv 1/1 Running 0 18h
eventing-webhook-75959f4464-nqx2w 1/1 Running 0 18h
$ kubectl get pod -n knative-serving
NAME READY STATUS RESTARTS AGE
activator-f5cdf9f6d-t27tb 2/2 Running 0 18h
autoscaler-65bcbf6566-j888w 2/2 Running 0 18h
controller-6499dc4b45-qqc8n 2/2 Running 0 18h
domain-mapping-5d5b7ffbfb-znd8k 2/2 Running 0 18h
domainmapping-webhook-648dd7c8df-cx5ww 2/2 Running 0 18h
net-istio-controller-74f56df67f-268xt 2/2 Running 0 18h
net-istio-webhook-77d6667445-stfcz 2/2 Running 0 18h
webhook-5bccc5c886-tl5xl 2/2 Running 0 18h
$ kubectl get pod -n kubeflow
NAME READY STATUS RESTARTS AGE
admission-webhook-deployment-bb7c6b4d6-vdvbd 1/1 Running 0 18h
cache-server-5bc96cdc6b-frm9v 2/2 Running 0 18h
centraldashboard-8dc67db66-4x52j 2/2 Running 0 18h
jupyter-web-app-deployment-574dfdc9d-k4cqv 1/1 Running 0 18h
katib-controller-6478fbd64c-gwxtk 1/1 Running 0 18h
katib-db-manager-78fc8b7895-6lmdd 1/1 Running 0 18h
katib-mysql-6975d6c6c4-676fk 1/1 Running 0 18h
katib-ui-5cb6cc4d97-fdj56 1/1 Running 0 18h
kserve-controller-manager-0 2/2 Running 0 18h
kserve-models-web-app-76484bdb5d-wkvb4 2/2 Running 0 18h
kubeflow-pipelines-profile-controller-6dc4ff7ffd-62hgc 1/1 Running 0 18h
metacontroller-0 1/1 Running 0 18h
metadata-envoy-deployment-6c6f8c6c59-nnhcz 1/1 Running 0 18h
metadata-grpc-deployment-679b49cc95-cxdb8 2/2 Running 3 (18h ago) 18h
metadata-writer-d6567ddf6-n2jvk 2/2 Running 0 18h
minio-7955cfc9fc-2qh42 2/2 Running 0 18h
ml-pipeline-7f465cd8fd-wvmvk 2/2 Running 0 18h
ml-pipeline-persistenceagent-6bc6c96dd8-9nfzq 2/2 Running 0 18h
ml-pipeline-scheduledworkflow-7d464d85bf-6xqwp 2/2 Running 0 18h
ml-pipeline-ui-6576d6ddcb-z4zfv 2/2 Running 0 18h
ml-pipeline-viewer-crd-59b9f99f9b-n98c4 2/2 Running 1 (18h ago) 18h
ml-pipeline-visualizationserver-7c7464896f-mp2lp 2/2 Running 0 18h
mysql-75f4964b48-27vtk 2/2 Running 0 18h
notebook-controller-deployment-84856d878f-4xzcm 2/2 Running 1 (18h ago) 18h
profiles-deployment-7bd6b5f9f5-h6vnr 3/3 Running 1 (18h ago) 18h
tensorboard-controller-deployment-c5f96cd5f-qvwq7 3/3 Running 1 (18h ago) 18h
tensorboards-web-app-deployment-8446c8f5b5-kq84j 1/1 Running 0 18h
training-operator-5cc8cdfdd6-rjdp6 1/1 Running 0 18h
volumes-web-app-deployment-b579747b4-jqg7g 1/1 Running 0 18h
workflow-controller-555f64865-gg8m7 2/2 Running 1 (18h ago) 18h
【参考】DeepOpsを使ったインストール
基本的には公式ドキュメントの通りインストール用のシェルを叩いてしばし待つだけです。
Kubeflowの認証機能(Dex)を有効にする場合はシェルの実行時に-xオプションを付与します。
# インストールオプションを確認
$ ./scripts/k8s/deploy_kubeflow.sh -h
Starting './scripts/k8s/deploy_kubeflow.sh'; DeepOps version ''
Usage:
-h This message.
-p Print out the connection info for Kubeflow.
-c Only clone the Kubeflow manifests repo, but do not deploy Kubeflow.
-d Delete Kubeflow from your system (skipping the CRDs and istio-system namespace that may have been installed with Kubeflow.
-D Deprecated, same as -d. Previously 'Fully Delete Kubeflow from your system along with all Kubeflow CRDs the istio-system namespace. WARNING, do not use this option if other components depend on istio.'
-x Deprecated, multi-user auth is now the default.
-w Wait for Kubeflow homepage to respond (also polls for various Kubeflow Deployments to have an available status).
# 認証/マルチテナントの機能を有効にしてインストール
$ ./scripts/k8s/deploy_kubeflow.sh -x
~~~中略~~~
インストール後の動作確認
上記コマンドでインストールが完了した時点でNodePortでKubeflowのGUIにアクセスできるようになっています。
istio-ingressgatewayというサービスを探して、80番ポートに割り振られたポート番号を確認しましょう(今回の例では31537番)
$ kubectl get svc -n istio-system istio-ingressgateway
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
istio-ingressgateway NodePort 10.233.37.132 <none> 15021:31033/TCP,80:31537/TCP,443:30393/TCP,31400:30564/TCP,15443:30856/TCP 20h
http://<ノードのIP>:<上記で確認したポート番号>にアクセスするとログイン画面が表示されます。
初期ユーザのIDはuser@example.comでパスワードは12341234です。
ログインするとこんな感じ。
これでひとまず完成です。長くなっちゃったので具体的な使用例はまたの機会に…。
おわりに(宣伝)
ということで(ほぼ)DeepOpsだけでAI/MLなインフラを構築できました。
ちなみに今回デプロイした様なk8s + NetAppストレージ + KubeflowなAI/MLインフラを、弊社ではNetApp AI Control Planeという名称でソリューション化しています。
会社の名前は付いていますが特にライセンス費用などを取るわけでもなく、ソフトウェアスタックは全てオープンソースなので「NetAppストレージをAIの分野で広く活用していただくための一つの構成例」ぐらいに思っていただければOKです。
NetAppストレージさえご準備できれば比較的簡単に、ローコストで使い始められると思いますので是非お試しください!