目次と前回の記事
Python のバージョンとこれまでに作成したモジュール
本記事のプログラムは Python のバージョン 3.13 で実行しています。また、numpy のバージョンは 2.3.5 です。
| リンク | 説明 |
|---|---|
| marubatsu.py | Marubatsu、Marubatsu_GUI クラスの定義 |
| ai.py | AI に関する関数 |
| mbtest.py | テストに関する関数 |
| util.py | ユーティリティ関数の定義 |
| tree.py | ゲーム木に関する Node、Mbtree クラスなどの定義 |
| gui.py | GUI に関する処理を行う基底クラスとなる GUI クラスの定義 |
AI の一覧とこれまでに作成したデータファイルについては、下記の記事を参照して下さい。
今回の記事の内容
前回の記事で証明した大数の弱法則は、おおざっぱにいうと以前の記事で説明したように、無作為復元抽出によって得られた標本の標本サイズを大きくすると、標本平均が母平均に近くなる確率が1に近づく(確率収束する)という法則です。
これまでの記事に倣い、以後は大数の弱法則を単に大数の法則と表記します。
大数の法則が非常に便利である理由の一つが、「独立同分布から抽出された標本であること」と、「期待値が有限であること」という条件さえ満たせば、元の確率分布がどのような形であっても大数の法則が成り立つということにあります。そのため、サイコロの特定の出目が出る確率の近似値の計算、モンテカルロ法による円周率の近似値の計算、今後の記事で紹介する原始モンテカルロ法による AI の計算など、様々な場面で大数の法則を利用することができます。今回の記事では大数の法則が頻繁に用いられる、指示関数によって定義される確率変数について説明し、上記の近似値の計算が正しいことを大数の法則によって証明できることを示します。
前回の記事では確率分布が有限な期待値と分散を持つという条件で大数の法則の証明を行いましたが、大数の法則が満たされる条件は有限な期待値を持つことだけで、有限な分散を持たない場合でも大数の法則は満たされます。有限な分散を持たない場合でも大数の法則が満たされる具体例については次回の記事で紹介する予定です。
指示関数と集合の記法
最初に今回の記事で扱う指示関数と集合の記法について説明します。
指示関数の定義
指示関数とは、ある値が集合 $A$ の要素である場合に 1 を、そうでない場合に 0 を返す関数の事です。指示関数は $\mathbf{1}_A$ のように表記し、下記のように定義されます。なお、$x \in A$ は $x$ が集合 $A$ の要素に含まれることを表し、$x$ が $A$ の元(げん)であると呼びます。
$\mathbf{1}_A (x) = \begin{cases}
1 & x \in A \\
0 & x \notin A
\end{cases}$
別の言葉で説明すると、指示関数は特定の条件を満たす値を 1、そうでない値を 0 に変換する関数で、統計学や確率論の様々な場面で用いられます。本記事では、サイコロの出目やモンテカルロ法での座標など、様々な対象の「条件の成立・不成立」を判定するためにこの関数を使用します。
$x$ の値や集合 $A$ の要素としては実数だけでなく、$1 + 2i$ のような複素数、$(1, 2)$ のような複数の数値の組、コインの表と裏のような文字列などの様々な値が考えられますが、本記事では説明を簡単にするために最初は $x$ の値や集合 $A$ の要素が実数であるものとします。
参考までに Wikipedia の指示関数の項目のリンクを下記に紹介します。
指示関数は、定義関数や特性関数とも呼ばれます。ただし、特性関数という用語は確率論で用いられる特性関数とは全く異なる意味を持つ点に注意が必要です。
集合の記法
指示関数は集合を元に定義されるので、集合の記法について説明します。集合の記法には集合の要素を列挙する外延的記法と、集合の要素の条件を記述する内包的記法があります。
外延的記法では $\{ \}$ の中に集合の要素をカンマで区切って列挙することで表記します。例えば、集合 $A$ の要素が 1、2、3 の場合は $A = \{1, 2, 3\}$ と表記します。
外延的記法は集合の要素を具体的に列挙する点がわかりやすいという利点がありますが、要素の数が多い場合の記述が大変であったり、偶数の集合のような無限個の要素を持つ集合を記述することができないという欠点があり、そのような集合は内包的記法で記述します。
内包的記法では下記のように $\{ \}$ の中を $|$ で区切り、左に集合の要素を表す記号を、右にその記号が満たす条件を記述します。
$\{x \mid x が満たす条件\}$
内包的記法のいくつかの具体例を挙げます。下記のように条件を言葉で記述する場合や、式で記述する場合があります。
| 集合 | 意味 |
|---|---|
| $\{x \mid x は偶数 \}$ | 偶数の集合 |
| $\{x \mid x > 0 \}$ | 正の実数の集合 |
| $\{x \mid |x| ≦ 1 \}$ | 絶対値が 1 以下(-1 以上 1 以下)の実数の集合 |
具体例を後で示しますが、文字列のような実数以外の値を要素とする集合を考えることもできます。
Python の list 内包表記は list の要素という集合を、要素の条件を表すプログラムで記述した内包的記法の一種です。
集合の内包表記を $\{ x : x が満たす条件\}$ のように間を : (コロン)で区切って記述する場合もあるようです。
本記事ではここまでの内容では集合の要素が実数であるものとしたので省略しましたが、$x$ が実数であることを明記する場合は、下記のように $\mathbb{R}$ という実数(real number)を表す記号を用いて $x$ が実数の元であることを $\mid$ の前に記述します。
$\{x \in \mathbb{R} \mid x > 0 \}$
参考までに Wikipedia の集合の記法の項目のリンクを下記に紹介します。
複数の値の組を持つ集合の記法と指示関数
ここまでの説明では集合の要素が 1 つの実数でしたが、2 つ以上の実数を要素とする集合を考えることもできます。下記にいくつかの具体例を挙げます。なお、$|$ の左に記述する記号は一般的に複数の値の組であることを明確にするために $()$ で囲って表記します。
| 集合 | 意味 |
|---|---|
| $\{(x, y) \mid x と y は偶数 \}$ | 共に偶数となる 2 つの実数の組の集合 |
| $\{(x, y) \mid x < y \}$ | $x < y$ を満たす 2 つの実数の組の集合 |
| $\{(x, y, z) \mid x + y = z\}$ | $x + y = z$ となる 3 つの実数の組の集合 |
また、集合の要素が 2 つの実数の組の場合の指示関数は下記のように定義されます。
$\mathbf{1}_A (x, y) = \begin{cases}
1 & (x, y) \in A\\
0 & (x, y) \notin A
\end{cases}$
3 つ以上の場合も同様に指示関数を $\mathbf{1}_A(x, y, z)$ のように記述します。
上記では集合の要素を実数の組としましたが、実数以外の値を組とする集合を考えることもできます。
指示関数の定義の $x, y$ を下記のように $()$ で囲わずに記述すると、数学的には「$x \in A$ かつ $y \in A$」という意味なります。そのため、「$(x, y)$ という 2 つの値の組が集合 $A$ に属している」という意図を正しく伝えるためにも $()$ は省略しないほうが良いでしょう。
$\mathbf{1}_A (x, y) = \begin{cases}
1 & x, y \in A\\
0 & x, y \notin A
\end{cases}$
様々な指示関数の記述方法
$\mathbf{1}_A(x)$ のように指示関数を記述すると、集合 $A$ の内容が具体的ではないためどのような指示関数であるかがわかりづらいという問題があります。集合 $A$ の要素が具体的に決まっている場合は、$\mathbf{1}$ の添字に集合 $A$ の具体的な内容を直接記述することが良くあります。本記事ではわかりやすさを重視してそのように指示関数を記述することにします。
下記は集合を $A = \{1, 2, 3\}$ という外延的表記で記述する場合の指示関数で、$\mathbf{1}$ の添字に集合の外延的表記をそのまま記述します。
$1_{\{1, 2, 3\}} (x) $
下記は $A = \{x \mid x > 0\}$ という内包的表記で記述する場合の指示関数で、$\mathbf{1}$ の添字には $\{\}$ の中に $x$ が満たす条件だけを記述します。その理由は $|$ の前に記述される $x$ が指示関数の最後に $(x)$ という形で記述されるからです。
$1_{\{x > 0\}} (x) $
集合の要素が 2 つ実数の場合は下記のようになります。3 つ以上の実数の場合も同様です。
$1_{\{x < y\}} (x, y)$
また、本記事では採用しませんが、$\mathbf{1}$ の添字に記述されている記号の数から集合の要素がいくつの値の組で構成されているかが明確なので、下記のように指示関数の後ろの $()$ を省略して記述することが良くあります。
$1_{\{x < y\}}$
指示関数は他にも以下のような記号で表記されることあります。数学では下記の一番上の白抜きの数字の 1 の記号が良く用いられるようですが、残念ながら本記事を執筆している Qiita ではその記号は表記できない1ので $\mathbf{1}_A$ を用いることにします。
- 白抜きの数字 1 を用いた

- ギリシャ文字の小文字のカイを用いた $χ_A$
- 大文字の I を用いた $I_A$
- [] 内に 1 となる条件を記述した $[x \in A]$(アイバーソンの記法と呼びます)
他にもいくつかの記号が使われる場合もあるようなので、興味がある方は下記の Wikipedia のリンク先などを参照して下さい。
指示関数によって定義された確率変数の性質
サイコロの特定の出目が出る確率の近似値を計算する方法として、サイコロを何度も振ってその目が出た割合で近似するという方法が良く知られていますが、この方法で正しく近似できることは指示関数によって定義された確率変数に対して大数の法則を適用することによって証明できます。
サイコロ出目が 1 の場合の大数の法則による証明
具体例として、偏りのないサイコロを振った時に 1 の出目がでる割合が、サイコロを振った回数が大きくなるほど 1/6 に近づくことを指示関数と大数の法則を用いて証明します。
指示関数を利用した確率変数の定義
偏りのないサイコロの出目を表す確率変数を $X$ とし、下記の指示関数を用いた式で新しい確率変数 $I_{\{1\}}$ を定義します。
$I_{\{1\}} = \mathbf{1}_{\{1\}}(X)$
指示関数によって定義された確率変数の名前は、指示関数(indicator function)の英語表記の頭文字を取って大文字の $I$ で表記されることが多いようです。
この確率変数 $I_{\{1\}}$ の実現値を $i_{\{1\}}$ と表記すると、$i_{\{1\}}$ は確率変数 $X$ の実現値 $x$ から下記の式で計算されます。
$i_{\{1\}} = \mathbf{1}_{\{1\}}(x)$
また、指示関数 $\mathbf{1}_{\{1\}}(x)$ の定義から、上記の式は下記のように書き換えることができます。
$i_{\{1\}} = \begin{cases}
1 & x \in \{1\} \\
0 & x \notin \{1\}
\end{cases}$
このことから、確率変数 $I_{\{1\}}$ の実現値 $i_{\{1\}}$ は、$X$ の実現値が 1 の場合に 1 が、そうでない場合に 0 となることがわかります。$X$ はサイコロの出目を表す確率変数なので、$i_{\{1\}}$ は下記のような性質を持ちます。
$i_{\{1\}}$ はサイコロを振って 1 が出た時に 1 に、それ以外の出目が出た時に 0 となる。
指示関数の確率質量関数と期待値
確率変数 $I_{\{1\}}$ がとる値は 0 または 1 のいずれかの値なので離散型確率変数であり、上記で説明した $i_{\{1\}}$ の性質からその確率質量関数は下記のようになります。
$P(I_{\{1\}}=1) = P(X=1) = 1/6$
$P(I_{\{1\}}=0) = 1 - P(I_{\{1\}}=1) = 5/6$
また、この確率変数 $I_{\{1\}}$ の期待値 $E[I_{\{1\}}]$ は下記の式で計算されます。
$E[I_{\{1\}}] = 1 × P(I_{\{1\}}=1) + 0 × P(I_{\{1\}}=0)$
$ = P(I_{\{1\}}=1)$
$ = P(X=1) = 1/6$
上記から $E[I_{\{1\}}]$ が以下の重要な性質を持つことがわかります。
- サイコロを振った出目が 1 である確率を表す $P(X=1)$ と等しい
- $1/6$ という有限の値である
大数の法則を利用した証明
確率変数 $I_{\{1\}}$ が従う確率分布から無作為復元抽出を行うことで得られた標本平均を表す確率変数を $\bar{I_{\{1\}}}$ と表記すると、下記の理由からその実現値である $\bar{i_{\{1\}}}$ はサイコロを振った時の 1 の出目の割合を表します。
- $I_{\{1\}}$ の実現値が 1 であることは確率変数 $X$ の実現値が 1 であることを表し、確率変数 $X$ はサイコロの出目を表すので、これはサイコロの出目が 1 であることを表す
- $I_{\{1\}}$ の実現値は 0 または 1 なので、標本の要素の値の合計は 1 の要素の個数を表す
- 標本平均 $\bar{i_{\{1\}}}$ は 1 の要素の個数を標本サイズで割った値で計算され、これは標本の中の 1 の割合、すなわちサイコロを振った時の 1 の出目の割合を表す
先程示したように $I_{\{1\}}$ の期待値である $E[I_{\{1\}}]$ は有限な値であることから確率変数 $I_{\{1\}}$ は大数の法則に従い、標本サイズを大きくすると標本平均 $\bar{i_{\{1\}}}$ が $E[I_{\{1\}}] = P(X=1) = 1/6$ に近づきます。この数学的な性質と下記の事実からサイコロを振る回数を多くすると 1 が出る割合が 1/6 に近づく(確率収束する)ことが証明されます。
- 上記で示したように標本平均はサイコロを振った時の 1 の出目の割合を表す
- $P(X=1) = 1/6$ はサイコロを振った時に 1 が出る確率を表す
- 標本サイズはサイコロを振った回数を表される
任意の指示関数の場合
上記では指示関数の集合が $\{1\}$ の場合で説明しましたが、任意の集合の指示関数に対しても上記と同様の下記の性質が満されます。
任意の確率変数 $X$ と集合 $A$ に対して下記が成り立つ。
確率変数 $X$ が従う確率分布から無作為復元抽出によって得られた標本は、標本サイズが大きくなると、標本の中の集合 $A$ に含まれる要素の割合が、$A$ に含まれる事象が発生する確率に近づく。
以下にそのことを証明しますが、下記の証明の大部分は先ほどの証明の $\{1\}$ を $A$ に置き換えたものとほぼ同じです。
最初に任意の確率変数 $X$ と任意の集合 $A$ に対して下記の式で定義される新しい確率変数 $I_{A}$ を定義します。
$I_{A} = \mathbf{1}_{A}(X)$
この確率変数 $I_{A}$ の実現値を $i_{A}$ と表記すると、$i_{A}$ は確率変数 $X$ の実現値 $x$ から下記の式で計算されます。
$i_{A} = \mathbf{1}_{A}(x)$
また、指示関数 $\mathbf{1}_{A}(x)$ の定義から、上記の式は下記のように書き換えることができます。
$i_{A} = \begin{cases}
1 & x \in A \\
0 & x \notin A
\end{cases}$
このことから、確率変数 $I_{A}$ の実現値 $i_{A}$ は、$X$ の実現値が $A$ に含まれる場合に 1 に、そうでない場合に 0 となることがわかります。
また、このことから指示関数によって定義された確率変数は、元の確率変数 $X$ の性質に関わらず常に 0 と 1 のみの値をとる離散型確率変数になり、その確率質量関数は下記のようになります。
$P(I_{A}=1) = P(X \in A)$
$P(I_{A}=0) = 1 -P(I_{A}=1)$
上記の $P(X \in A)$ は $X$ の値が集合 $A$ に含まれる確率を表し、離散型確率変数の場合は $\sum_{x \in A}P(X=x)$ という式で表されます。詳細は省略しますが連続型確率変数の場合はその確率分布を表す確率密度関数に対して積分を使った式で表されます。興味がある方は下記の Wikipedia の確率密度関数の項目などを調べてみると良いでしょう。
また、この確率変数 $I_{A}$ の期待値 $E[I_{A}]$ は下記の式で計算されます。
$E[I_{A}] = 1 × P(I_{A}=1) + 0 × P(I_{A}=0)$
$ = P(I_{A}=1) = P(X \in A)$
この $E[I_{A}]$ は 0 以上 1 以下になるという確率の性質から、常に 0 以上 1 以下の有限な値を取ります。
従って、確率変数 $I_{A}$ は大数の法則に従うので下記が成り立ちます。
確率変数 $I_{A}$ から無作為復元抽出を行うことで得られた標本平均を $\bar{i_{A}}$ とすると、標本サイズを大きくすると $\bar{i_{A}}$ は $P(X \in A)$ に近づく。
また、先程の $A = \{1\}$ の場合と同様の理由から、下記が成り立ちます。
- $\bar{i_{A}}$ は標本の中の 1 の割合、すなわち確率変数 $X$ から無作為復元抽出を行った標本の中の $A$ に含まれる要素の割合を表す
- $P(X \in A)$ は確率変数 $X$ が表す事象のうち、$A$ に含まれる事象が発生する確率を表す
従って、先程説明した下記が成り立つことが証明されます。
任意の確率変数 $X$ と集合 $A$ に対して下記が成り立つ。
確率変数 $X$ が従う確率分布から無作為復元抽出によって得られた標本は、標本サイズが大きくなると、標本の中の集合 $A$ に含まれる要素の割合が、$A$ に含まれる事象が発生する確率に近づく。
良く用いられる「大数の法則を用いた近似値の計算」が上記で証明できることを、具体例をいくつか挙げて示します。
- 偶数の出る確率:$X$ を偏りのないサイコロの出目を表す確率変数、$A = \{2, 4, 6\}$ とすれば、サイコロを振る回数を増やすと偶数の出る割合が 1/2 に近づく
- 偏りのある確率の推定:$X$ を偏りのあるサイコロの出目を表す確率変数、$A = \{1\}$ とすれば、サイコロを多く振った場合の出目の 1 の割合から 1 が出る確率を近似(推定)できる
- コインの表の確率の推定:$X$ をコインを投げた時の表と裏を表す確率変数、$A = \{表\}$ とすれば、コインを多く投げた時に表が出る割合から表が出る確率を近似(推定)できる
上記の 3 つ目の例では確率変数や集合の要素の値が実数ではありませんが、そのような場合でも問題がないことを次に説明します。
実数以外の値をとる確率変数や集合の場合
上記の 3 つ目の例のように確率変数 $X$ がとる値や、集合 $A$ の要素が表と裏のような数値ではない文字列である場合でも下記のように指示関数を定義することができます。
$\mathbf{1}_{\{表\}}(x) = \begin{cases}
1 & x \in \{表\}\\
0 & x \notin \{表\}
\end{cases}$
また、この指示関数を用いた下記の式で新しい確率変数 $I_{\{表\}}$ を定義することができます。
$I_{\{表\}} = \mathbf{1}_{\{表\}}(X)$
このように、指示関数は集合 $A$ の要素や $x$ がどのような値を取っても「条件を満たすか・満たさないか」を判定して必ず 0 と 1 を返すという性質を持ちます。
従って、上記の確率変数 $I_{\{表\}}$ の実現値も必ず 0 または 1 になり、その確率質量関数や期待値は下記の式で先ほどと全く同じように計算できます。
$P(I_{\{表\}}=1) = P(X \in \{表\}) = P(X=表)$
$P(I_{\{表\}}=0) = 1 -P(I_{\{表\}}=1)$
$E[I_{\{表\}}] = P(I_{\{表\}}=1)= P(X=表)$
従って、指示関数によって定義された確率変数は、元の確率変数 $X$ がとる値や集合 $A$ の要素が実数ではなくても必ず大数の法則の要件を満たすため、先程と同様の理由から下記を証明することができます。
- コインの表の確率の推定:$X$ をコインを投げた時の表と裏を表す確率変数、$A = \{表\}$ とすれば、コインを多く投げた時に表が出る割合から出る確率を近似(推定)できる
モンテカルロ法を利用した円周率の近似値の計算方法の証明
上記では、確率変数 $X$ がとる値や集合 $A$ の要素が文字列の場合でしたが、複数の値の組であっても同様です。以前の記事で紹介した、モンテカルロ法を利用した円周率の近似値の計算方法が正しいことも指示関数と大数の法則で証明することができます。
指示関数
この場合の指示関数の集合 $A$ は下記のように 2 つの実数の組を要素として持つ集合になります。集合 $A$ は 2 つの実数 $(x, y)$ の組を 2 次元の平面上の点とみなした場合に、原点を中心とする半径が 1 の円の内部にあることを表す集合です。
$A = \{(x, y) \mid x^2 + y^2 ≦ 1\}$
また、指示関数は下記のように $x$ と $y$ の 2 つの引数を持つ関数として定義します。
$\mathbf{1}_A(x, y) = \begin{cases}
1 & (x, y) \in A\\
0 & (x, y) \notin A
\end{cases}$
上記の指示関数を $\mathbf{1}_{x^2+y^2≦1}(x, y)$ のように記述することもできますが、表記が長くなるので $\mathbf{1}_A(x, y)$ のように集合を $A$ という記号で短く表記することにします。
確率変数の定義とその証明
次に、-1 以上 1 未満2の範囲の一様乱数を表す、互いに独立した連続型確率変数 $X$、$Y$ に対して下記の指示関数を用いた式で新しい確率変数 $I_{A}$ を定義します。なお、確率変数 $X$ と $Y$ は連続型確率変数ですが、先程説明したように指示関数によって定義された確率変数 $I_A$ は実現値が 0 と 1 のみの値を取る離散型確率変数になります。
$I_{A} = 1_{A}(X, Y)$
この確率変数 $I_A$ の実現値 $i_A$ は、確率変数 $X$ と $Y$ の実現値である $(x, y)$ を 2 次元平面上の座標とみなした場合に、原点を中心とする半径が 1 の円の内部にある場合は 1、そうでない場合は 0 となります。
$x$ と $y$ は一様乱数によって抽出されるので、$(x, y)$ を 2 次元平面上の点と考えると $-1 ≦ x < 1$、$-1 ≦ y < 1$ の範囲の一辺が 2 の正方形の内部の点がどこでも等しい確率で抽出されます。
従って、$i_A$ が 1 となる確率は「円の面積 ÷ 正方形の面積」で計算されます。円の面積は $π × 1^2 = π$、正方形の面積は $2 × 2 = 4$ なので、$I_A$ の確率分布を表す確率質量関数は下記のようになります。
$P(I_A=i_A) = \begin{cases}
π/4 & i_A = 1\\
1 - π/4 & i_A = 0
\end{cases}$
この確率変数 $I_A$ の期待値 $E[I_A]$ は下記の式から $π/4$ となることから有限の値であることがわかります。
$E[I_A] = 1 × π / 4 + 0 × (1 - π/4) = π / 4$
確率変数 $I_A$ から無作為復元抽出を行うことで得られた標本平均を $\bar{i_A}$ と表記すると、$\bar{i_A}$ は標本の中で $(x, y)$ が円の内部に配置される割合を表し、大数の法則から標本サイズを大きくすると $\bar{i_A}$ は $E[I_A] = π / 4$ に近づき(確率収束)ます。
上記から以前の記事で説明したモンテカルロ法によって円周率の近似値を計算できることが大数の法則によって証明されました。
このように、指示関数の集合が複数の値の組であり、複数の確率変数から指示関数を利用して定義された確率変数に対しても同様の性質が成り立つことがわかります。
標本の個々の値の割合
指示関数によって定義された確率変数と大数の法則から、確率変数 $X$ から無作為復元抽出した標本の個々の値の割合が、標本サイズを大きくすると大数の法則によりその値が発生する理論上の確率に近づく(確率収束する)ことが証明できます。
具体的には確率変数 $X$ がとりうる任意の 1 つの値だけを要素として持つ集合 $A$ に対して指示関数 $1_{A}$ と確率変数 $I_{A}$ を定義すると下記の性質が成り立つことから証明できます。
確率変数 $I_{A}$ が従う確率分布から無作為復元抽出で得られた標本の標本平均を表す確率変数 $\bar{I_{A}}$ の実現値 $\bar{i_{A}}$ は、標本サイズを大きくすると $E[I_{A}]$ に確率収束する。
先程示したように指示関数を利用して定義された確率変数 $I_A$ の期待値は必ず 0 以上 1 以下の有限な値になるため、元の確率変数 $X$ が以前の記事で紹介したような有限な期待値を持たない確率分布であってもこの性質(個々の値の出現割合が大数の法則に従うこと)は問題なく成り立ちます。
上記が正しいことの具体例として、偏りのないサイコロの出目を表す確率分布と、前回の記事で定義したランダムな確率分布を作成する create_pd で作成された確率分布で確認することにします。
また、確認の方法として確率分布の「個々の値の理論上の確率」と、無作為復元抽出を行うことで得られた「標本の個々の値の実際の割合」を棒グラフで並べて描画し、標本サイズを大きくするほど並べた 2 つの棒グラフの高さが一致していく様子を視覚的に確認することにします。
サイコロの出目を表す確率分布の作成
最初に偏りのないサイコロの出目を表す確率分布を下記のプログラムで作成します。確率分布を表すデータは 前回の記事 で定義した create_pd が作成するデータと同様で、X に確率変数がとる値の一覧を、P に対応する確率を表す 1 次元の ndarray を代入しています。
import numpy as np
X = np.array([1, 2, 3, 4, 5, 6])
P = np.array([1/6] * 6)
print(P)
実行結果
[0.16666667 0.16666667 0.16666667 0.16666667 0.16666667 0.16666667]
P の計算は以下のように、6 つの 1 を要素として持つ ndarray を np.ones で計算し、6 で割っても良いでしょう。
P = np.ones(6) / 6
print(P)
実行結果
[0.16666667 0.16666667 0.16666667 0.16666667 0.16666667 0.16666667]
np.ones の詳細については下記のリンク先を参照して下さい。
無作為復元抽出を行う関数の定義
上記で作成した確率分布からの無作為復元抽出は numpy で定義された np.random.choice という関数で計算することできます。この関数は以前の記事で説明した list からランダムに要素を 1 つ抽出する random モジュールの choice に似ていますが下記の点が異なります。
- 一度に複数個の標本を抽出できる
- それぞれの要素が抽出される確率を個別に設定できる
- list ではなく ndarray が計算される
random モジュールには choices という np.random.choice と同様の処理を行う関数がありますが、返り値が list である点などが異なるので本記事では np.random.choice を利用することにします。
random モジュールの choices の詳細については下記のリンク先を参照して下さい。
np.random.choice の主な仮引数は以下の通りです。
| 仮引数 | 意味 |
|---|---|
a |
抽出元の 1 次元の ndarray(list でも良い)。整数を代入した場合は 0 以上その値未満の整数を要素とする ndarray が設定されたものとみなされる |
size |
作成する標本の個数。整数を代入した場合はその個数の要素を持つ 1 次元の ndarray が計算される。tuple を代入した場合はその shape の ndarray が計算される |
replace |
True を代入した場合は復元抽出が、False を代入した場合は非復元抽出が行われる。デフォルト値は True
|
p |
a の各要素が抽出される確率を表す 1 次元の list または ndarray。省略した場合は a のすべての要素が等確率で抽出される |
np.random.choice の詳細は下記のリンク先を参照して下さい。
下記は X から P の確率で 10 個の要素を無作為復元抽出するプログラムです。なお、標本の英語は sample なので sample という名前の変数に結果を代入しました。
sample = np.random.choice(a=X, size=10, p=P)
print(sample)
実行結果
[4 5 4 4 3 4 3 6 6 3]
得られた標本を表す 1 次元の ndarray の中に「どの出目が何個含まれているか」という実現値のカウント(数え上げ)は np.unique という関数で計算することができます。
np.unique は指定した ndarray の要素から重複する要素を取り除いたユニークな(重複のない)要素の一覧を表す ndarray を返す関数で、その主な仮引数は以下の通りです。
| 仮引数 | 意味 |
|---|---|
ar |
重複のない要素を計算する ndarray(list でも良い) |
return_counts |
True を代入した場合は、各要素が何個存在するか(個数)も同時に計算して返り値として返す。デフォルト値は False
|
np.unique の詳細は下記のリンク先を参照して下さい。
下記は先ほど計算した sample 内の各要素(element)の個数(count)を計算して表示するプログラムで、実行結果の element は 3、4、5、6 が抽出されたことを、count は 3、4、5、6 がそれぞれ 3、4、1、2 個抽出されたことを表します。
element, count = np.unique(sample, return_counts=True)
print(element)
print(count)
実行結果
[3 4 5 6]
[3 4 1 2]
次に、X と P によって表される確率変数から無作為復元抽出によって指定した標本サイズの標本を抽出し、「標本」と「出現した要素の一覧」と「各要素の個数」を返り値として返す sampling3 という関数を定義することにします。sampling の仮引数は確率分布のデータを代入する X、P と標本サイズを代入する size で、下記のプログラムのように定義します。上記で説明した通りの処理を行っているだけなので説明は省略します。
1 def sampling(X, P, size):
2 sample = np.random.choice(X, p=P, size=size)
3 element, count = np.unique(sample, return_counts=True)
4 return sample, element, count
行番号のないプログラム
def sampling(X, P, size):
sample = np.random.choice(X, p=P, size=size)
element, count = np.unique(sample, return_counts=True)
return sample, element, count
下記は sampling を利用して標本サイズが 10 の標本を抽出するプログラムで、実行結果を見て正しい処理が行われていることを確認してみて下さい。
size = 10
sample, element, count = sampling(X, P, size)
print(sample)
print(element)
print(count)
実行結果
[5 4 4 6 1 1 1 5 5 6]
[1 4 5 6]
[3 2 3 2]
グラフの描画方法
要素の一覧と個数のデータから、それぞれの要素の実際の割合を表すグラフは下記のプログラムで描画することができます。なお、割合は個数を標本サイズで割り算した count / size で計算することができます。
import matplotlib.pyplot as plt
import japanize_matplotlib
plt.bar(element, count / size)
plt.xlabel("x")
plt.ylabel("割合")
plt.show()
実行結果

次に、この「実際の要素の割合のグラフ」と「各要素の理論上の確率を表すグラフ」を並べて描画することにします。各要素の理論上の確率を表すグラフは plt.bar(X, P) で描画できますが、下記のプログラムのように 2 つの棒グラフを続けて描画すると 2 つの棒グラフが同じ場所に重なって描画されてしまうため、比較が困難になるという問題が発生します。
plt.bar(element, count / size, label="x の割合")
plt.bar(X, P, label="P(X=x)")
plt.xlabel("x")
plt.ylabel("割合・確率")
plt.legend()
plt.show()
実行結果

2 つの棒グラフを並べて描画する場合は以下のように棒グラフを描画します。
-
plt.barの仮引数widthに棒グラフの幅を表す値を代入する -
Xの各値を棒グラフの幅だけ増やすことで右にずらして描画する
下記は上記の方法でグラフを描画するプログラムです。上記の場合は X の値が 1 ずつ増えるので、2 つの棒グラフを並べて描画する場合は棒グラフの幅をその半分の 0.5 以下にする必要があるので 0.4 としました。
width = 0.4
plt.bar(element, count / size, width=width, label="x の割合")
plt.bar(X + width, P, width=width, label="P(X=x)")
plt.xlabel("x")
plt.ylabel("割合・確率")
plt.legend()
plt.show()
実行結果

上記の実行結果を見ると、青い棒グラフの中心が X の値である 1、2、3、・・・ にぴったりあっていることがわかります。青い棒グラフとオレンジの棒グラフの境目が X の値にあったほうがわかりやすいので、下記のプログラムでは 2 つのグラフの表示位置を棒グラフの幅の半分だけ左にずらすことでそのようにグラフを描画するようにしました。
width = 0.4
plt.bar(element - width / 2, count / size, width=width, label="x の割合")
plt.bar(X + width / 2, P, width=width, label="P(X=x)")
plt.xlabel("x")
plt.ylabel("割合・確率")
plt.legend()
plt.show()
実行結果

非常に大きな標本サイズへの対応
先程定義した sampling は、例えば 10 億(=1 ギガ)のような非常に大きな標本サイズの標本を作成しようとすると数ギガバイトものメモリが必要になるため、コンピューターのメモリが足りなくなってコンピューターの処理速度が著しく遅くなったり、コンピューター全体の処理が止まってしまうという問題があります。実際に筆者のコンピューターで 10 億の標本サイズの標本を計算しようとしたところ、コンピューターが完全に固まってしまい、電源を強制的に切ることになってしまいました。
グラフの描画に必要な情報は element と count だけなので、下記のプログラムのように一度に作成する標本の標本サイズの最大値を 100 万に減らすことで必要なコンピューターのメモリを減らし、必要な数だけ標本を繰り返して作成する「分割処理」を行うように修正することにします。
先程のプログラムと異なり下記のプログラムでは np.unique(sample, return_counts=True) を何度も繰り返して呼び出す可能性があり、その場合に抽出された要素の一覧を表す element が毎回異なってしまう可能性があります。そのため、要素と要素の個数の対応を dict の key と value で表現することにしました。また、その際に list 内包表記に良く似た dict 内包表記(辞書内包表記)を用いて X の要素と同じキーを持つすべてのキーの値が 0 の dict を作成しました。
dict 内包表記は { key: value の計算式 for key in 反復可能オブジェクト } のように記述します。list 内包表記との違いは以下の通りです。
- 全体を
{}で囲う - 先頭に
key: value の計算式を記述する
dict 内包表記の詳細は下記のリンク先を参照して下さい。
なお、今回の修正により標本全体を記録しなくなったので返り値から sample を削除した点に注意して下さい。
-
2 行目:要素と要素の個数の対応を表す
resultをXの要素と同じ key を持ち、すべての value が 0 である dict で初期化する -
3 行目:抽出する必要がある残りの標本の数を表す
sizeleftをsizeで初期化する -
4 ~ 10 行目:
sizeleftが 0 になるまで繰り返し処理を行う -
5 行目:次に抽出する標本の数を表す
sに最小値を計算する組み込み関数minを利用してsizeleftと 100 万のうちの小さいほうの値を代入する -
6、7 行目:サイズが
sの標本を無作為復元抽出し、得られた標本のそれぞれの要素の値と個数を計算する -
8、10 行目:得られたそれぞれの標本の個数を
resultの対応する key の値に加算して反映させる -
10 行目:
sizeleftから抽出した標本サイズを表すsを引き算する -
11 ~ 13 行目:要素の一覧とその個数は
resultの key と value に記録されているので、それらを表すresult.keys()とresult.values()を組み込み関数listの実引数に記述することで list に変換し、それをnp.arrayで 1 次元の ndarray に変換した値を返り値として返す。一度 list に変換してから ndarray を作成する理由は、result.keys()のままだとnp.arrayでうまく 1 次元の ndarray に変換できないためである。また、標本全体を記録しなくなったので返り値からsampleを削除した
1 def sampling(X, P, size):
2 result = {e: 0 for e in X}
3 sizeleft = size
4 while sizeleft > 0:
5 s = min(sizeleft, 1000000)
6 sample = np.random.choice(X, p=P, size=s)
7 element, count = np.unique(sample, return_counts=True)
8 for e, c in zip(element, count):
9 result[e] += c
10 sizeleft -= s
11 element = np.array(list(result.keys()))
12 count = np.array(list(result.values()))
13 return element, count
行番号のないプログラム
def sampling(X, P, size):
result = {e: 0 for e in X}
sizeleft = size
while sizeleft > 0:
s = min(sizeleft, 1000000)
sample = np.random.choice(X, p=P, size=s)
element, count = np.unique(sample, return_counts=True)
for e, c in zip(element, count):
result[e] += c
sizeleft -= s
element = np.array(list(result.keys()))
count = np.array(list(result.values()))
return element, count
下記は上記で修正した sampling を利用してサンプルサイズが 10 億(= $10^9$)の標本を抽出し、標本のそれぞれの要素の個数を表示するプログラムです。標本サイズが 10 億であることを確認できるように最後にそれぞれの要素の個数の合計を計算しました。筆者のパソコンでは約 30 秒ほどかかりましたが、修正前と異なりパソコンが固まることはありませんでした。また、実行結果から 1 から 6 までのそれぞれの要素がそれぞれ 10 億の 1/6 の約 1.6 億個であり、それらの合計が 10 億になることから正しい計算が行われたことが確認できます。
element, count = sampling(X, P, 10 ** 9)
print(element)
print(count)
print(sum(count))
実行結果
[1 2 3 4 5 6]
[166671420 166673749 166664171 166670700 166662566 166657394]
1000000000
グラフの描画処理の実装
次に、下記のプログラムのように先程定義した sampling という関数にグラフを描画する処理を追加することにします。標本抽出に加えてグラフを描画する処理が加わった点が気になる人は関数の名前を自由に変えて下さい。
- 14 行目:この後でグラフを並べて描画するのでグラフの描画サイズを少し小さくした
-
20 行目:
xの割合の最大値が小さくなると凡例がグラフと重なってしまうことがわかったので、グラフの y 軸の最大値をxの割合の最大値であるmax(count / size)より 0.07 だけ大きくするようにした -
21 行目:
plt.titleでグラフのタイトルを表示するようにした
1 def sampling(X, P, size):
2 result = {e: 0 for e in X}
3 sizeleft = size
4 while sizeleft > 0:
5 s = min(sizeleft, 1000000)
6 sample = np.random.choice(X, p=P, size=s)
7 element, count = np.unique(sample, return_counts=True)
8 for e, c in zip(element, count):
9 result[e] += c
10 sizeleft -= s
11 element = np.array(list(result.keys()))
12 count = np.array(list(result.values()))
13
14 plt.figure(figsize=(4, 3))
15 width = 0.4
16 plt.bar(element - width / 2, count / size, width=width, label="x の割合")
17 plt.bar(X + width / 2 , P, width=width, label="P(X=x)")
18 plt.xlabel("x")
19 plt.ylabel("割合・確率")
20 plt.ylim(0, max(count/size) + 0.07)
21 plt.title(f"size = {size}")
22 plt.legend()
23 plt.show()
24 return element, count
行番号のないプログラム
def sampling(X, P, size):
result = {e: 0 for e in X}
sizeleft = size
while sizeleft > 0:
s = min(sizeleft, 1000000)
sample = np.random.choice(X, p=P, size=s)
element, count = np.unique(sample, return_counts=True)
for e, c in zip(element, count):
result[e] += c
sizeleft -= s
element = np.array(list(result.keys()))
count = np.array(list(result.values()))
plt.figure(figsize=(4, 3))
width = 0.4
plt.bar(element - width / 2, count / size, width=width, label="x の割合")
plt.bar(X + width / 2 , P, width=width, label="P(X=x)")
plt.xlabel("x")
plt.ylabel("割合・確率")
plt.ylim(0, max(count/size) + 0.07)
plt.title(f"size = {size}")
plt.legend()
plt.show()
return element, count
plt.title の詳細については下記のリンク先を参照して下さい。
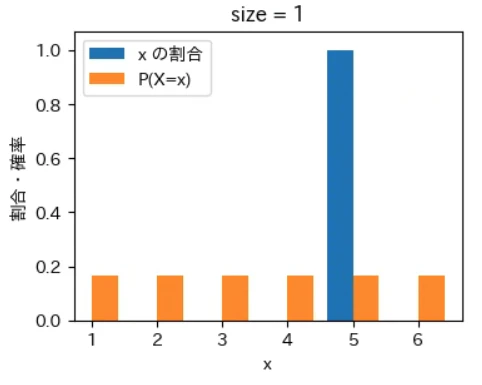
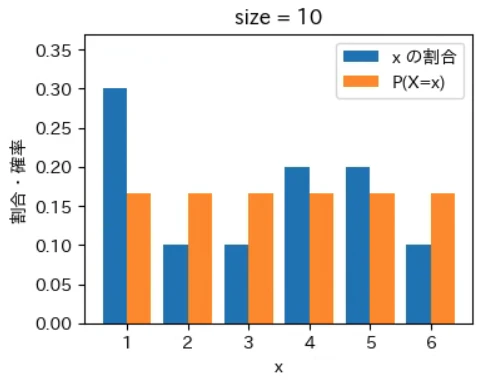
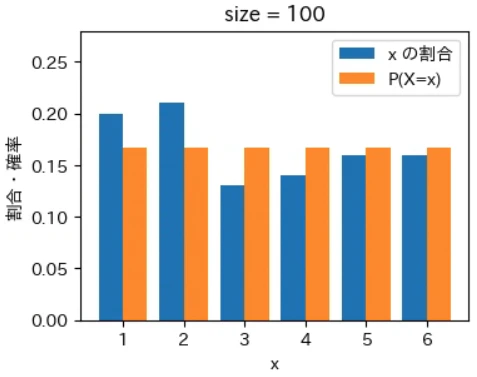
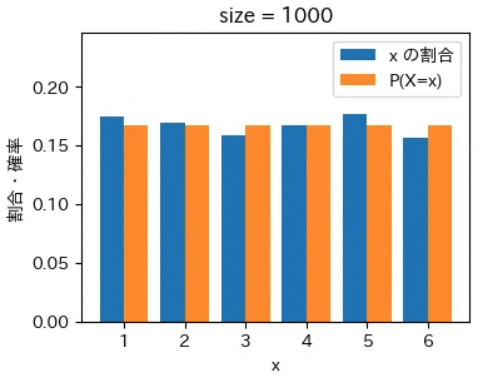
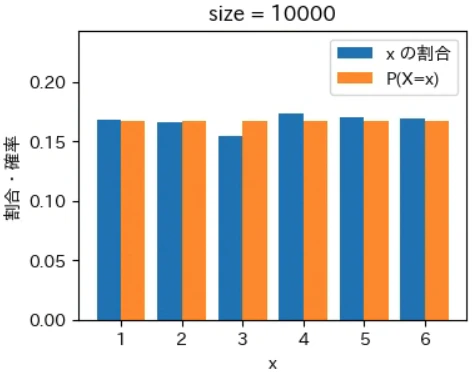
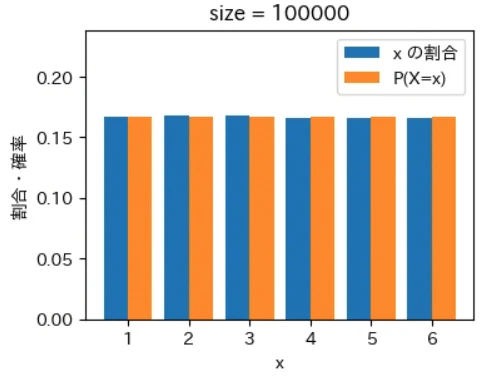
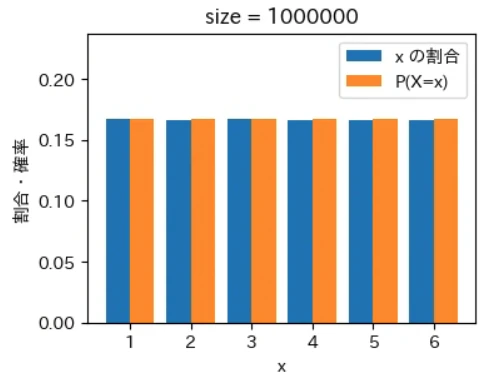
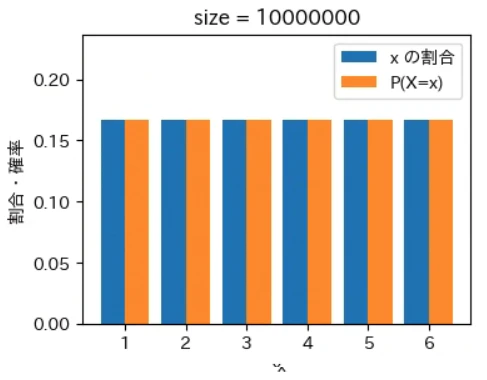
下記は標本サイズが $10^0$ = 1 から $10^7$ = 1000 万 まで 10 倍ずつ増やしながら上記の sampling でグラフを描画するプログラムです。実行結果から標本サイズが大きくなるほど青とオレンジのグラフが近くなっていき、標本サイズが 1000 万の場合はほぼ同一のグラフになることが確認できました。なお、もっと大きな数の標本サイズの標本を作成することもできますが、1000 万でほぼ同一のグラフになるのでそこで止めることにしました。興味がある方は 10 億くらいまでであれば 30 秒ほどで描画できるので増やしてみて下さい。
for size in range(8):
sampling(X, P, 10 ** size)
実行結果
下記は前回の記事で定義した create_pd で作成した、偏りのあるサイコロに相当する確率分布のデータで同様のグラフを描画するプログラムで、このような場合でも同様の結果になることが確認できました。興味がある方は、様々な確率分布を作成して同様の結果が得られることを確認してみて下さい。
from util import create_pd
X, P = create_pd(minx=1, maxx=6)
print(P)
print(X)
print(np.sum(P))
for size in range(8):
sampling(X, P, 10 ** size)
実行結果
[0.09855378 0.13992523 0.30101556 0.16594175 0.17671272 0.11785096]
[1 2 3 4 5 6]
0.9999999999999999
実行結果
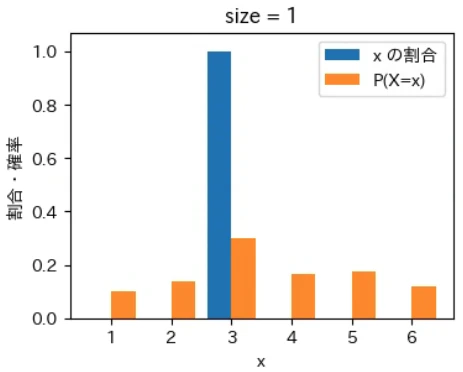
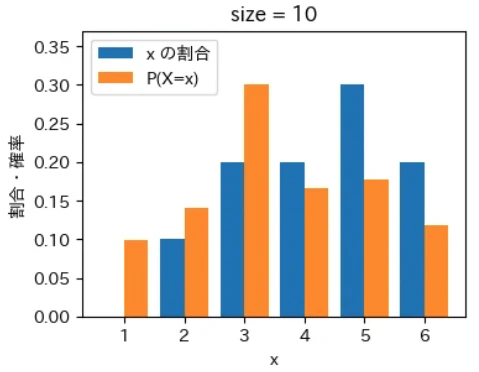
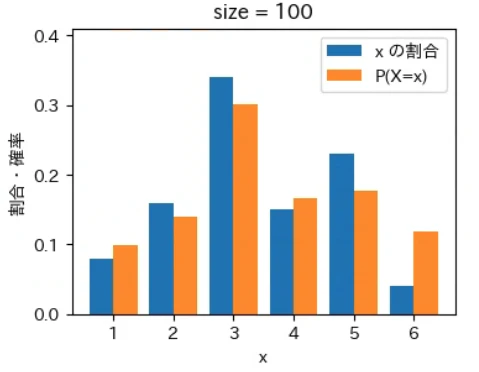
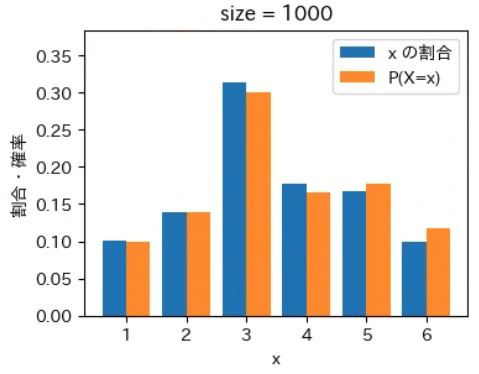
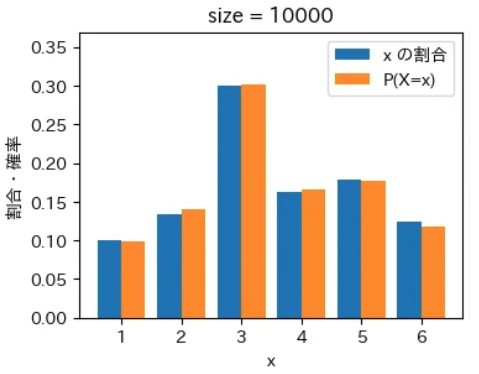
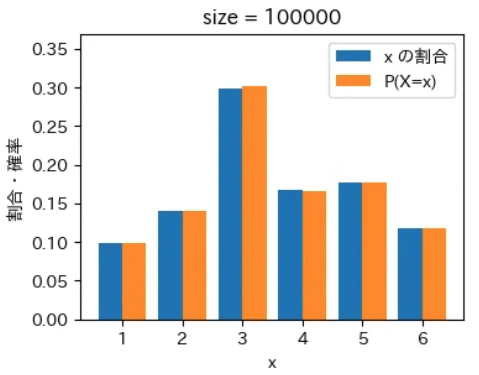
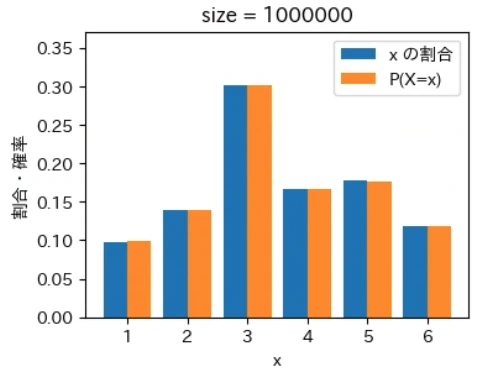
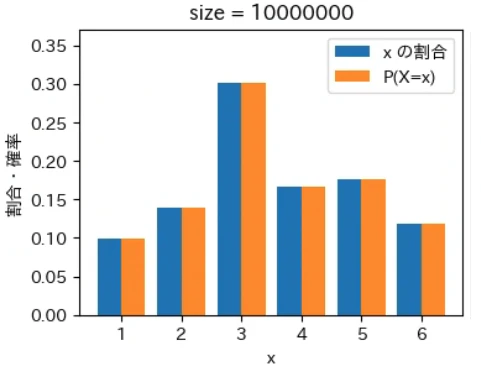
標本平均は上記の青いグラフから計算され、確率分布の期待値は上記のオレンジ色のグラフから同様の計算式で計算されます。そのため、青色とオレンジ色のグラフが近づくということは、それらのデータから計算される標本平均と確率分布の期待値(母平均)も必然的に近づくことを意味します。
大数の法則は平均値が近づく法則であるというマクロな性質に注目が集まりがちですが、その裏側ではこのように「標本サイズが大きくなると確率変数の個々の値が占める割合そのものが発生確率に地道に近づいている」というミクロな現象が起きているからこそ成り立つという構造が、上記のグラフから視覚的にも深く理解できるのではないでしょうか。
今回の記事のまとめ
今回の記事では統計学や確率論の様々な場面で活躍する指示関数(定義関数)の定義と、指示関数によって定義される確率変数の重要な性質について詳しく説明しました。
また、大量のデータを扱う際に、コンピューターのメモリの枯渇を防ぐための分割処理の実装の工夫についても紹介しました。
指示関数というフィルターを通すことで、以下のような一見すると異なるように見える問題に対しても、大数の法則を適用することができることを示しました。
- 要素の出現割合:標本サイズを増やすと個々の要素の出現割合が理論上の確率に収束する
- モンテカルロ法:連続的な領域のシミュレーションによる円周率の近似値の計算
- 文字列の扱い:コインの裏表のような数値ではない対象の確率の推定
このように、元の確率分布がどのような形であっても指示関数を利用することで大数の法則が成り立つことが様々な場面で活用されています。
本記事で入力したプログラム
今回の記事で定義した関数は util.py に保存することにします。
| リンク | 説明 |
|---|---|
| marubatsu.ipynb | 本記事で入力して実行した JupyterLab のファイル |
| util.py | 本記事で更新した util_new.py |
次回の記事
近日公開予定です