目次と前回の記事
Python のバージョンとこれまでに作成したモジュール
本記事のプログラムは Python のバージョン 3.13 で実行しています。また、numpy のバージョンは 2.3.5 です。
| リンク | 説明 |
|---|---|
| marubatsu.py | Marubatsu、Marubatsu_GUI クラスの定義 |
| ai.py | AI に関する関数 |
| mbtest.py | テストに関する関数 |
| util.py | ユーティリティ関数の定義 |
| tree.py | ゲーム木に関する Node、Mbtree クラスなどの定義 |
| gui.py | GUI に関する処理を行う基底クラスとなる GUI クラスの定義 |
AI の一覧とこれまでに作成したデータファイルについては、下記の記事を参照して下さい。
強調表記について
以前も同様の指摘されたのですが、強調を控えたほうが良いという意見がありました。そこで、しばらく強調表記をなしにしてみようと思います。強調があったほうが良い、もしくは少しはあったほうが良いという意見があればコメントなどでお願いします。
大数の弱法則の証明
前回の記事で説明したように、大数の弱法則は下記の大数の法則の定義 1、2 の条件に対して、定義 3 の式が成り立つことを示すことで証明できます。
- 独立同分布に従う可積分な確率変数の無限列 $X_1$、 $X_2$、… が与えられたとき、その平均を $μ$ とおく
- 標本サイズが $n ≧ 1$ の標本平均を表す確率変数 $\bar{X_n}$ を $\bar{X_n} = \frac{1}{n}\sum_{i=1}^n X_i$ で定義すると下記の式が成り立つ
- $\lim_{n \to \infty} P(|\bar{X_n} - μ|> ε) = 0$、($\forall ε > 0$)
ただし、上記の大数の弱法則の証明は少し難しいので、本記事では下記のように確率分布が有限な値の分散 $σ^2$を持つという条件を加えた場合の証明を行うことにします。なお、下記の二乗可積分とは確率変数が有限な値の分散を持つということを意味します。また、以後は確率変数が有限な値の分散を持つことを、単に分散を持つのように表記することにします。平均に関しても同様です。
- 独立同分布に従う可積分かつ二乗可積分な確率変数の無限列 $X_1$、 $X_2$、… が与えられたとき、その平均を $μ$、分散を $σ^2$ とおく
- 標本サイズが $n ≧ 1$ の標本平均を表す確率変数 $\bar{X_n}$ を $\bar{X_n} = \frac{1}{n}\sum_{i=1}^n X_i$ で定義すると下記の式が成り立つ
- $\lim_{n \to \infty} P(|\bar{X_n} - μ|> ε) = 0$、($\forall ε > 0$)
二乗可積分の定義は前回の記事で説明した可積分の定義と似ており、下記のように定義されます。
確率変数 $X$ に対して $E[X^2] < ∞$ を満たす状態
確率分布が有限な値の分散を持たない場合の大数の弱法則の証明は、確率変数の切断と特性関数という高度な数学を用います。
マルコフの不等式
分散を持つ確率変数に対する大数の法則の証明ではチェビシェフの不等式を利用します。また、チェビシェフの不等式はマルコフの不等式から証明することができるので、最初にマルコフの不等式の説明と証明を行います。
下記はマルコフの不等式の説明です。
期待値 $E[X]$ を持つ任意の確率変数 $X$ と、任意の正の実数 $a > 0$ に対して下記の不等式が成り立つ。$|X|$ は確率変数 $X$ の絶対値を表す確率変数で $E[|X|]$ はその期待値を表す。
$P(|X|≧ a)≦\frac{1}{a}E[|X|]$、($\forall a > 0$)1
参考までにマルコフの不等式の Wikipedia のリンクを下記に記します。
確率分布をランダムに作成する関数の定義
マルコフの不等式の中の確率変数 $|X|$ の意味がわかりづらいのではないかと思いますので説明します。
最初に確率分布をランダムに作成する下記のような関数を定義し、その関数で作成した確率分布に従う確率変数 $X$ から確率変数 $|X|$ がどのような確率分布になるかを説明します。
-
名前:確率分布(probability distribution)を作成するので
create_pdと命名する - 処理:指定した範囲の整数が発生する確率をランダムに計算した確率分布を計算して返り値として返す
-
入力:仮引数
minxとmaxxに確率変数の最小値と最大値を表す整数を代入する - 出力:確率変数がとる値の一覧を表す 1 次元の ndarray と、対応する値を取る確率の一覧を表す ndarray を要素として持つ tuple を返り値として返す
下記は create_pd を定義するプログラムです。
-
3 行目:
minxとmaxxを仮引数として持つ関数create_pdを定義する -
4 行目:確率変数が取る値の個数を計算して
xnumに代入する -
5 行目:この後で説明する
np.arangeを利用してminx以上maxx以下の整数を要素として持つ 1 次元の ndarray を作成してXに代入する -
6 行目:以前の記事 で説明した
np.random.uniformでxnum個の 0 以上 1 未満の範囲の一様乱数を要素として持つ 1 次元の ndarray を計算してPに代入する -
7 行目:確率を表す
Pの合計を 1 とするために、Pの各要素の値をPの要素の合計であるnp.sum(P)で割り算する -
8 行目:
(X, P)を返り値として返す
1 import numpy as np
2
3 def create_pd(minx, maxx):
4 xnum = maxx - minx + 1
5 X = np.arange(minx, maxx + 1)
6 P = np.random.uniform(size=xnum)
7 P /= np.sum(P)
8 return X, P
行番号のないプログラム
import numpy as np
def create_pd(minx, maxx):
xnum = maxx - minx + 1
X = np.arange(minx, maxx + 1)
P = np.random.uniform(size=xnum)
P /= np.sum(P)
return X, P
np.arange は組み込み関数 range と同様の実引数を記述することで、指定した範囲の等間隔な値を持つ 1 次元の ndarray を計算する numpy の関数です。range との大きな違いは整数以外の値にも対応しているという点です。詳細は下記のリンク先を参照して下さい。
同様の numpy の関数として、指定した範囲の数値を、指定した個数で等分した 1 次元の ndarray を計算する np.linspace があります。整数以外の等間隔な要素を持つ 1 次元の ndarray を作成したい場合は、誤差の関係から np.linspace を利用したほうが良いでしょう。詳細は下記のリンク先を参照して下さい。
下記は create_pd で -10 以上 10 以下の整数をとる確率分布を計算し、確率質量関数と確率の合計を表示するプログラムです。確率の合計が 1 にならないのは割り算による誤差が発生するためですが、誤差は極めて小さいので大きな問題はないでしょう。
X, P = create_pd(-10, 10)
for x, p in zip(X, P):
print(f"P(X = {x:3d}) = {p:.5f}")
print(f"確率の合計 = {np.sum(P)}")
実行結果
P(X = -10) = 0.04352
P(X = -9) = 0.05672
P(X = -8) = 0.04780
P(X = -7) = 0.04321
P(X = -6) = 0.03360
P(X = -5) = 0.05122
P(X = -4) = 0.03470
P(X = -3) = 0.07072
P(X = -2) = 0.07642
P(X = -1) = 0.03041
P(X = 0) = 0.06279
P(X = 1) = 0.04194
P(X = 2) = 0.04505
P(X = 3) = 0.07340
P(X = 4) = 0.00563
P(X = 5) = 0.00691
P(X = 6) = 0.00160
P(X = 7) = 0.06603
P(X = 8) = 0.06171
P(X = 9) = 0.06900
P(X = 10) = 0.07761
確率の合計 = 0.9999999999999998
上記のプログラムでは確率変数 $X$ がとる値を -10 以上 10 以下の整数としましたが、他の範囲の値や、整数でない値をとっても以後の説明の内容は変わりません。
割り算の誤差とは、割り切れない数を扱う際に小数点以下の値を特定の桁数で四捨五入などによって捨てることによって発生する誤差の事で、丸め誤差とよばれます。参考までに Wikipedia の誤差の項目のリンクを下記に示します。
確率変数の期待値と分散とグラフを描画する関数の定義
次に、確率変数を表すデータを実引数に記述して呼び出すと、期待値と分散を表示し、確率分布を表すグラフを描画する、下記の show_pd という関数を定義することにします。なお、後で確率変数 $|X|$ のグラフをこの関数で描画する予定なのでグラフの x 軸のラベルを表す仮引数 xlabel を用意しました。
-
4 行目:確率変数の値の一覧と対応する確率を代入する
X、Pとグラフの x 軸のラベルに表示する文字を代入するxlabelを仮引数として持つshow_pdを定義する。なお、xlabelのデフォルト値は"X"とした -
5 行目:
X * Pでそれぞれの確率変数の値とその確率を乗算した 1 次元の ndarray を計算し、その合計をnp.sumで計算することで確率分布の期待値を計算することができる - 6 行目:以前の記事で説明したように、確率変数 $X$ の分散 $V[X]$ は $V[X] = E[X^2] - E[X]^2$ で計算できるので、その計算を行う
- 7、8 行目:上記で計算した期待値と分散を表示する
-
9 ~ 11 行目:棒グラフを描画する
plt.barで確率分布を表すグラフを描画する
1 import matplotlib.pyplot as plt
2 import japanize_matplotlib
3
4 def show_pd(X, P, xlabel="X"):
5 E = np.sum(X * P)
6 V = np.sum(X * X * P) - E ** 2
7 print(f"期待値 = {E:6.3f}")
8 print(f"分散 = {V:6.3f}")
9 plt.bar(X, P)
10 plt.xlabel(xlabel)
11 plt.ylabel("確率")
12 plt.show()
行番号のないプログラム
import matplotlib.pyplot as plt
import japanize_matplotlib
def show_pd(X, P, xlabel="X"):
E = np.sum(X * P)
V = np.sum(X * X * P) - E ** 2
print(f"期待値 = {E:6.3f}")
print(f"分散 = {V:6.3f}")
plt.bar(X, P)
plt.xlabel(xlabel)
plt.ylabel("確率")
plt.show()
下記は先ほど作成した確率分布を show_pd で描画するプログラムです。実行結果から期待値と分散と確率分布のグラフが描画されることが確認できます。
show_pd(X, P)
実行結果
期待値 = 0.149
分散 = 39.856

minx や maxx に $10 ^ {1000}$ のような非常に大きな数値を代入すると 5 行目の X * P の計算で計算結果を float型 に変換できないためエラーが発生します。これは float 型表現できる数値に限界があるためです。なお、数億程度の値であればこのようなエラーが発生することはありません。
確率変数 |X| の性質
確率変数 $|X|$ の実現値は、確率変数 $X$ の実現値 $x$ の絶対値を表す $|x|$ です。
また、$|x|$ は以下のような値になります。
- $x = 0$ の場合は $|x| = 0$
- $x ≠ 0$ の場合は $|x| = x$ または $|x| = -x$
従って、確率変数 $|X|$ の確率質量関数は下記のようになります。
$P(|X| = 0) = P(X=0)$
$P(|X| = |x|) = P(X=x) + P(X=-x)$、ただし $x ≠ 0$
このことから、確率変数 $|X|$ の確率分布を表すグラフは、以下のようになります。
- 確率変数 $X$ の確率分布を表すグラフのうち、$x < 0$ の範囲を $x = 0$ で左右に反転する
- 反転した棒グラフの値を $x > 0$ の範囲の棒グラフの値に加える
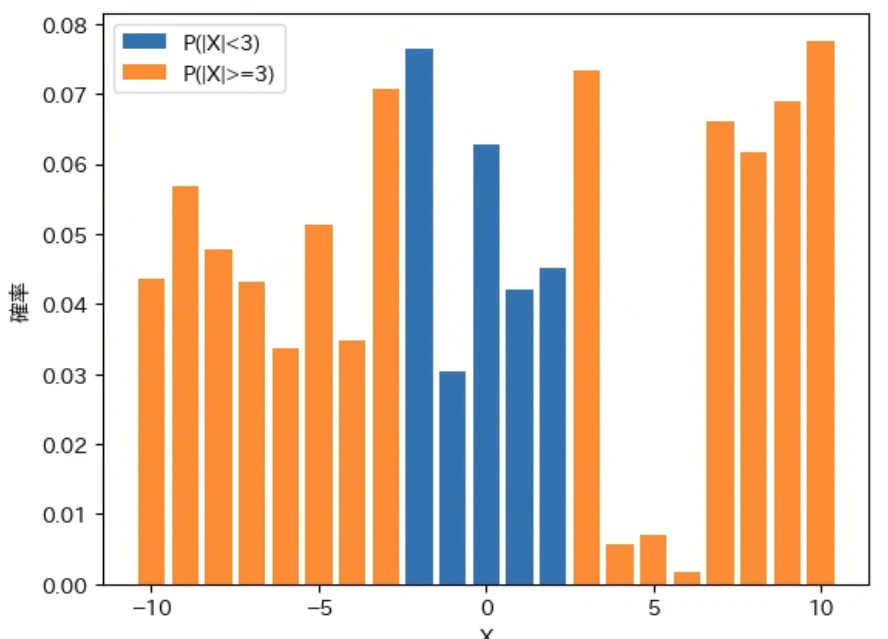
そのことを表すグラフを描画します。下記は、確率変数 $X$ の確率分布を表すグラフのうち、$X < 0$ の部分をオレンジ色で、$X ≧ 0$ の部分を青色で描画するプログラムです。
-
1、2 行目:以前の記事で説明した ndarray の特定の要素だけを処理の対象とする masked array を利用して、
Pの中のX<0の範囲の確率をマスク(隠す)してX>=0の範囲の確率を処理の対象とするPpos2 と、X<0の負(negative)の範囲の確率を処理の対象とするPnegを計算する -
3、4 行目:
PposとPnegの棒グラフを描画することで、$P(X≧0)$ の範囲と $P(X<0)$ の棒グラフを別の色で描画する
1 Ppos = np.ma.array(P, mask=X<0)
2 Pneg = np.ma.array(P, mask=X>=0)
3 plt.bar(X, Ppos, label="P(X ≧ 0)")
4 plt.bar(X, Pneg, label="P(X < 0)")
5 plt.xlabel("X")
6 plt.ylabel("確率")
7 plt.legend()
8 plt.show()
行番号のないプログラム
Ppos = np.ma.array(P, mask=X<0)
Pneg = np.ma.array(P, mask=X>=0)
plt.bar(X, Ppos, label="P(X ≧ 0)")
plt.bar(X, Pneg, label="P(X < 0)")
plt.xlabel("X")
plt.ylabel("確率")
plt.legend()
plt.show()
実行結果

下記は上記のグラフのオレンジ色の部分を $x = 0$ で反転して、青色の棒グラフに加えた確率変数 $|X|$ のグラフを描画するプログラムです。このような棒グラフの上に別の棒グラフを載せたグラフの事を積み上げ棒グラフと呼び、積み上げたグラフの描画は plt.bar の仮引数 bottom にその下のグラフの値を代入することで描画することができます。
-
1 行目:1 次元の ndarray に対しても list と同様に
[::-1]というスライス表記で要素の順番を反転した 1 次元の ndarray を計算できる。Pnegの要素の順番を反転することで、0 以下の確率を $x$ の最大値と最小値の中間である $x=0$ で反転した確率が計算される -
2 行目:
x ≧ 0の範囲の棒グラフを描画する -
3 行目:
plt.barの実引数にbottom=Pposを記述して上記で計算したPreversenegを描画することで、x < 0の範囲の確率を $x = 0$ で反転した値を積み上げた棒グラフを描画する
1 Preverseneg = Pneg[::-1]
2 plt.bar(X, Ppos)
3 plt.bar(X, Preverseneg, bottom=Ppos)
4 plt.xlabel("|X|")
5 plt.ylabel("確率")
行番号のないプログラム
Preverseneg = Pneg[::-1]
plt.bar(X, Ppos)
plt.bar(X, Preverseneg, bottom=Ppos)
plt.xlabel("|X|")
plt.ylabel("確率")
実行結果

実行結果のグラフからわかるように確率変数 $|X|$ の確率分布のグラフは、必ず 0 以上の範囲の値の確率だけが正の値になります。下記は、確率変数 $|X|$ の性質のまとめです。
- 任意の確率分布の負の範囲を正の範囲に反転させて加えるという確率分布を計算する
- 任意の確率分布から、確率変数が 0 以上の場合のみ確率が正となる確率分布を計算する
plt.bar の詳細については下記のリンク先を参照して下さい。
上記のプログラムを実行すると警告(warning)メッセージが表示されますが、masked array の処理を行ったことによるものなので気にする必要はありません。
確率変数 |X| を計算する関数の定義
次に、確率変数 $X$ を表すデータから確率変数 $|X|$ を表すデータを計算して返す calc_abs_pd を定義することにします。なお abs は絶対値を表す absolute value の略です。下記はその定義を行うプログラムです。
-
2 行目:$|X|$ がとる値の最大値は「$X$ の最大値」と「$-X$ の最大値」の最大値なので、その値を計算して
maxxに代入する -
3 行目:0 以上
maxx以下の整数の要素を持つ 1 次元の ndarray を計算する -
4 行目:
Xabsと同じ数の要素を持ち、すべての要素が 0 である 1 次元の ndarray を後述のnp.zeros_likeで計算する -
5、6 行目:すべての
Xの要素に対してPabs[abs(x)]にP[x]を加算するという繰り返し処理を行う。xの絶対値は組み込み関数absを利用して計算することができる -
7 行目:
(Xabs, Pabs)を返り値として返す
1 def calc_abs_pd(X, P):
2 maxx = max(max(X), max(-X))
3 Xabs = np.arange(0, maxx + 1)
4 Pabs = np.zeros_like(Xabs, dtype=np.float32)
5 for x, p in zip(X, P):
6 Pabs[abs(x)] += p
7 return Xabs, Pabs
行番号のないプログラム
def calc_abs_pd(X, P):
maxx = max(max(X), max(-X))
Xabs = np.arange(0, maxx + 1)
Pabs = np.zeros_like(Xabs, dtype=np.float32)
for x, p in zip(X, P):
Pabs[abs(x)] += p
return Xabs, Pabs
上記の np.zeros_like は最初の実引数に記述した ndarray と同じ(like な)shape とデータ型を持つ、すべての要素が 0 である ndarray を作成して返り値として返す関数です。異なるデータ型の ndarray を作成する必要がある場合は上記のようにキーワード引数 dtype にそのデータ型を代入します。Pabs には確率を代入するので float 型にする必要がありますが Xabs のデータ型が int 型なので、上記の場合は仮引数 dtype に np.float32 を代入しないと、整数しか代入できない 1 次元の ndarray が計算されてしまう点に注意が必要です。
np.zeros_like の詳細については下記のリンク先を参照して下さい。
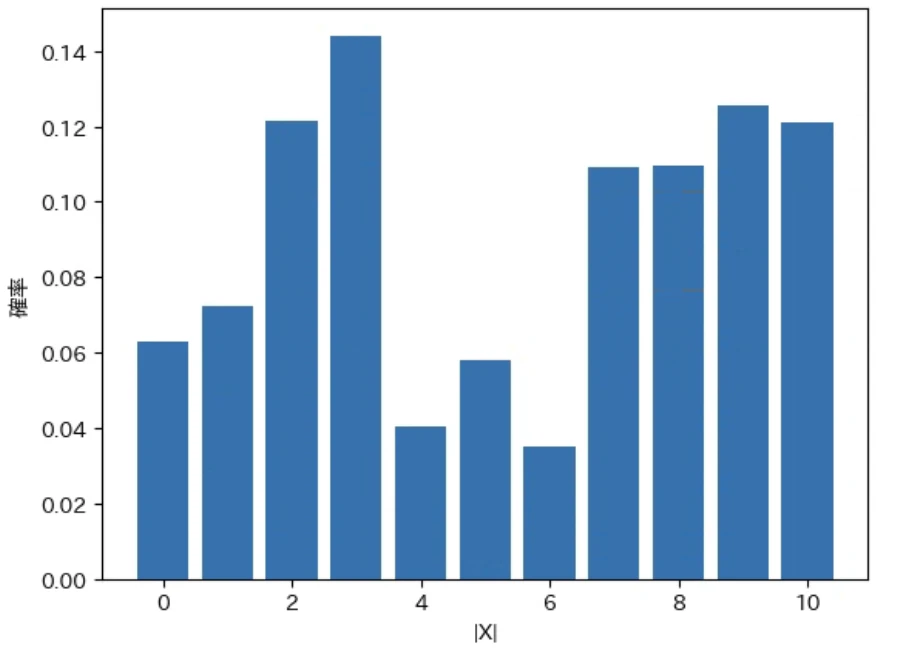
下記は上記で定義した calc_abs_pd で先程の確率変数 $X$ から $|X|$ を計算してその確率変数のグラフを描画するプログラムです。実行結果のグラフがその右に再掲した先程のグラフと同じになることから、正しい計算が行われることが確認できます。なお、キーワード引数に xlabel="|X|" を記述することでグラフの x 軸に "X" を表示するようにしました。
Xabs, Pabs = calc_abs_pd(X, P)
show_pd(Xabs, Pabs, xlabel="|X|")
実行結果
期待値 = 5.394
分散 = 10.779
マルコフの不等式の意味
次に、マルコフの不等式の左辺の $P(|X| ≧ a)$ の意味をグラフで説明します。そのために、show_pd で描画するグラフを $P(|X| ≧ a)$ とそうでない範囲で色分けして描画できるように改良することにします。
具体的にはグラフを色分けして描画する確率変数の条件(condition)を代入する仮引数 cond と、条件が真(true)の場合と偽(false)の場合のグラフのラベルを代入する仮引数 labelt、labelf を追加することにします。下記はそのように show_pd を修正したプログラムです。
-
1 行目:デフォルト値を
Noneとする仮引数condとデフォルト値を""とする仮引数labelt、labelfを追加する -
6、7 行目:
condがNoneの場合はこれまで通りのグラフを描画する -
9 ~ 12 行目:
condの条件がTrueの場合とFalseの場合のPの masked array を計算し、それぞれのグラフを描画する。なお、~は ndarray の各要素のTrueとFalseを反転する NOT 演算子である - 13 行目:グラフの凡例を描画する
1 def show_pd(X, P, xlabel="X", cond=None, labelt="", labelf=""):
2 E = np.sum(X * P)
3 V = np.sum(X * X * P) - E ** 2
4 print(f"期待値 = {E:6.3f}")
5 print(f"分散 = {V:6.3f}")
6 if cond is None:
7 plt.bar(X, P)
8 else:
9 Pfalse = np.ma.array(P, mask=cond)
10 Ptrue = np.ma.array(P, mask=~cond)
11 plt.bar(X, Pfalse, label=labelf)
12 plt.bar(X, Ptrue, label=labelt)
13 plt.legend()
14 plt.xlabel(xlabel)
15 plt.ylabel("確率")
16 plt.show()
行番号のないプログラム
def show_pd(X, P, xlabel="X", cond=None, labelt="", labelf=""):
E = np.sum(X * P)
V = np.sum(X * X * P) - E ** 2
print(f"期待値 = {E:6.3f}")
print(f"分散 = {V:6.3f}")
if cond is None:
plt.bar(X, P)
else:
Pfalse = np.ma.array(P, mask=cond)
Ptrue = np.ma.array(P, mask=~cond)
plt.bar(X, Pfalse, label=labelf)
plt.bar(X, Ptrue, label=labelt)
plt.legend()
plt.xlabel(xlabel)
plt.ylabel("確率")
plt.show()
修正箇所
-def show_pd(X, P, xlabel="X"):
+def show_pd(X, P, xlabel="X", cond=None, labelt="", labelf=""):
E = np.sum(X * P)
V = np.sum(X * X * P) - E ** 2
print(f"期待値 = {E:6.3f}")
print(f"分散 = {V:6.3f}")
- plt.bar(X, P)
+ if cond is None:
+ plt.bar(X, P)
+ else:
+ Pfalse = np.ma.array(P, mask=cond)
+ Ptrue = np.ma.array(P, mask=~cond)
+ plt.bar(X, Pfalse, label=labelf)
+ plt.bar(X, Ptrue, label=labelt)
+ plt.legend()
plt.xlabel(xlabel)
plt.ylabel("確率")
plt.show()
下記は上記で修正した show_pd で、先程計算した確率変数 $X$ と $|X|$ に対する $P(|X| ≧ 3)$、$P(|X| ≧ 5)$、$P(|X| ≧ 7)$ を色分けして描画するプログラムです。np.abs は ndarray の各要素の絶対値を要素として持つ ndarray を計算する関数です。なお、実行結果の期待値と分散は先ほどと同じなので省略してグラフのみを示します。
for a in [3, 5, 7]:
labelt = f"P(|X|>={a})"
labelf = f"P(|X|<{a})"
show_pd(X, P, cond=np.abs(X)>=a, labelt=labelt, labelf=labelf)
show_pd(Xabs, Pabs, xlabel="|X|", cond=Xabs>=a, labelt=labelt, labelf=labelf)
実行結果
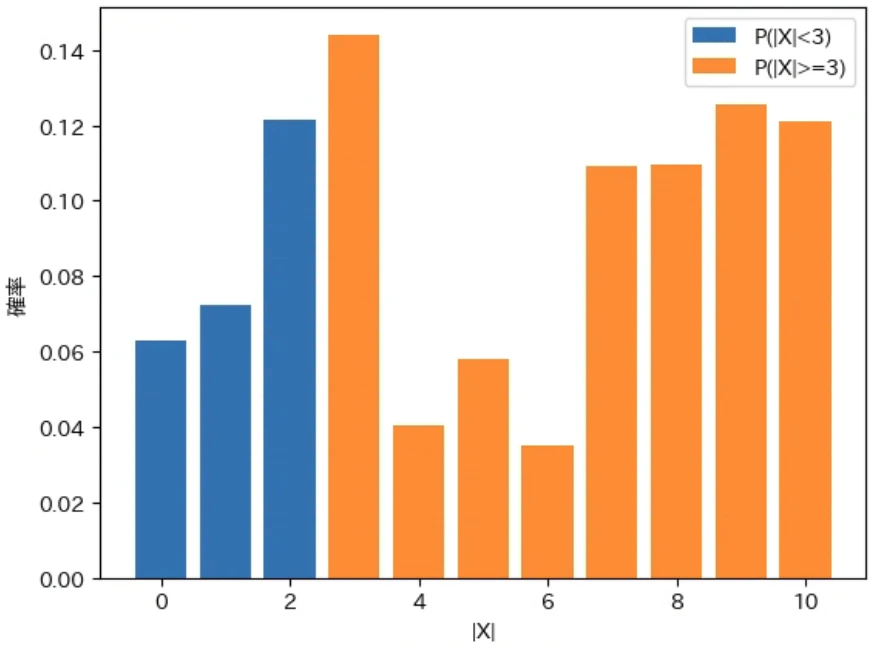
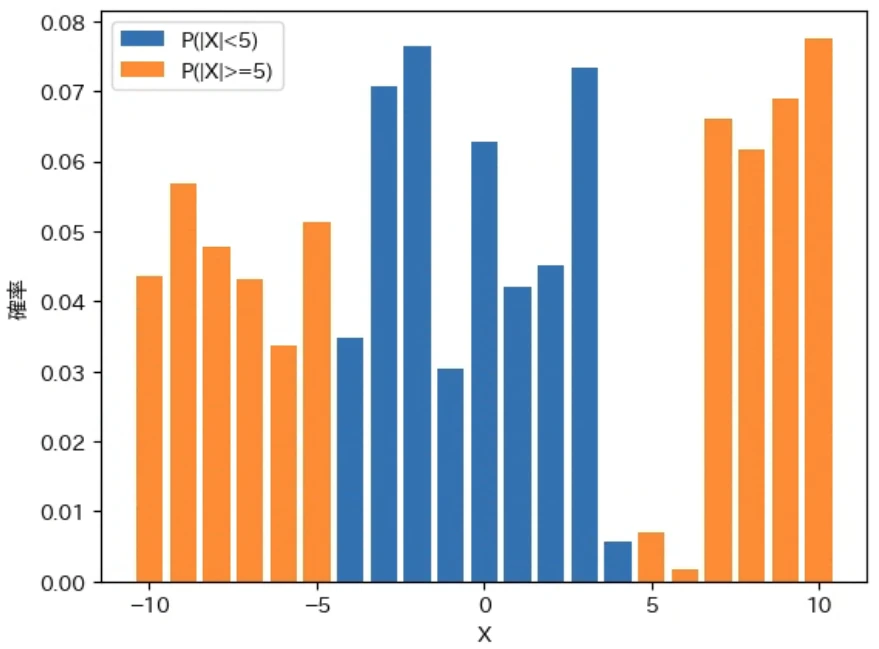
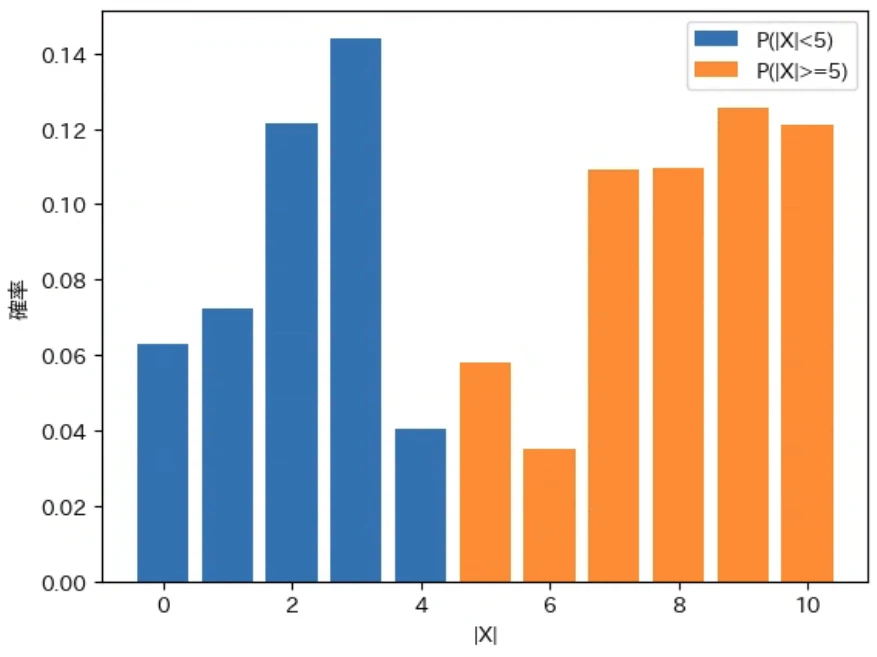
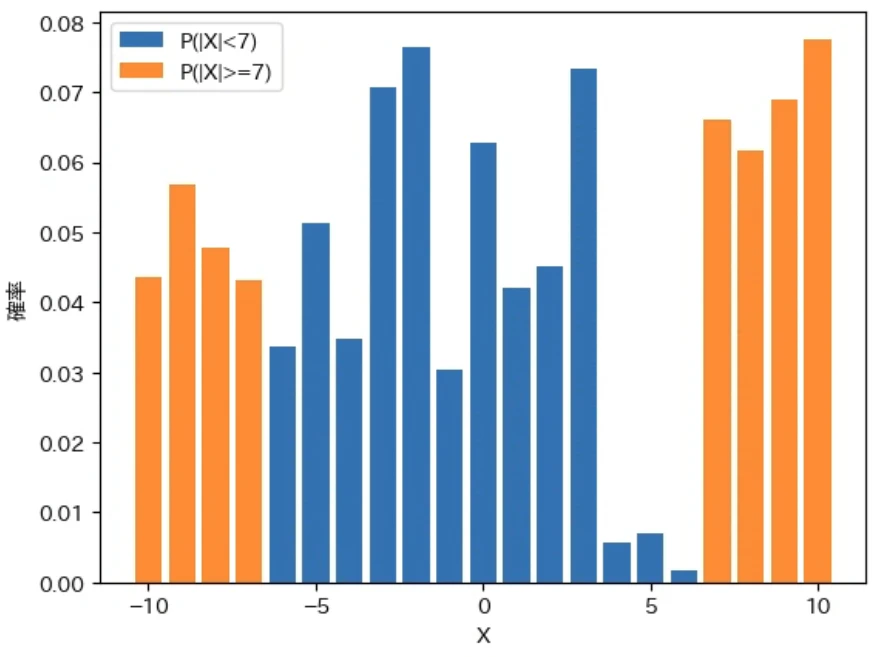
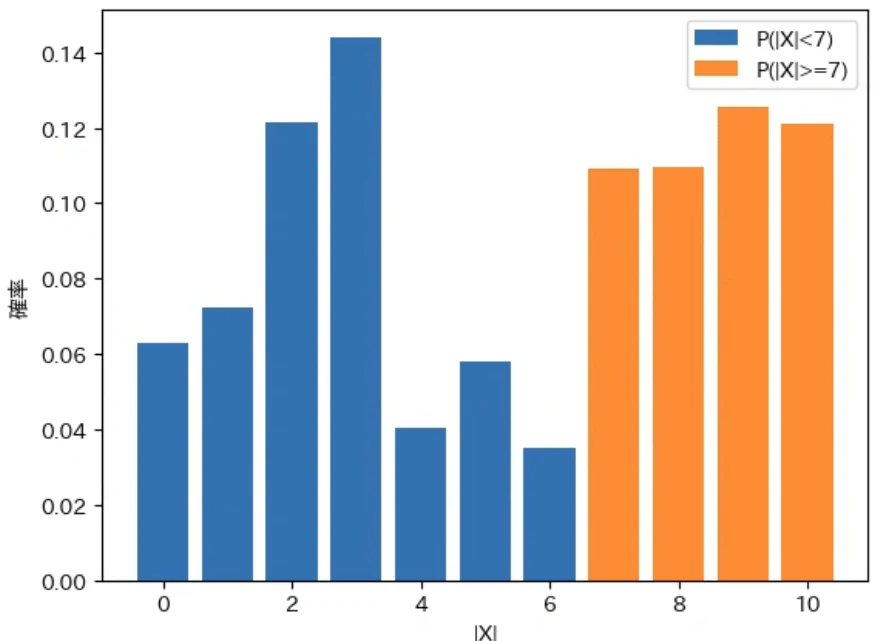
上記の図から、$P(|X| ≧ a)$ の $a$ を大きくすると、その範囲を表すオレンジ色の部分が減っていくことがわかるのではないかと思います。また、$P(|X| ≧ a)$ が以下のような範囲の確率の合計を表すことがわかります。
- 確率変数 $X$ を元に考えると、0 から左右に $a$ 以上離れた値の確率の合計
- 確率変数 $|X|$ を元に考えると、0 から右に $a$ 以上離れた値の確率の合計
従って、下記のマルコフの不等式は、上図のオレンジ色の部分の確率の合計が確率変数 $|X|$ の期待値である $E[|X|]$ の $\frac{1}{a}$ 以下になるということを意味します。
$P(|X|≧ a)≦\frac{1}{a}E[|X|]$、($\forall a > 0$)
np.abs は np.absolute の名前を短縮したもので、詳細については下記のリンク先を参照して下さい。
マルコフの不等式の証明の手順 1
次に、マルコフの不等式の証明を行います。$|X|$ の表記のままではわかりづらいと思いますので、以下の説明では $Y = |X|$ という式で定義された、実現値が 0 以上の値となる確率変数 $Y$ を用いて表した、下記のマルコフの不等式を証明することにします。
$P(Y ≧ a)≦\frac{1}{a}E[Y]$、($\forall a > 0$)、確率変数 $Y$ の実現値 $y$ は $y ≧ 0$
上記のマルコフの不等式の右辺の $E[Y]$ は以前の記事で説明した下記の確率変数の期待値の計算式で計算されます。
$E[Y] = \sum_{y} yP(Y=y)$
$y$ がとりうる値は 0 以上の実数なので、任意の実数 $a > 0$ に対して、$y$ がとりうる値を $0 ≦ y < a$ と $a ≦ y$ に分けることができます。上記の式をそのように分けると下記の式になります。
$E[Y] = \sum_{0 ≦ y < a} yP(Y=y) + \sum_{a ≦ y} yP(Y=y)$、($\forall a > 0$)
なお、$\sum_{0 ≦ y < a} yP(Y=y)$ は先ほどの青色のグラフの $Y < a$ の範囲の確率変数から計算した期待値の一部を表し、$\sum_{a ≦ y} yP(Y=y)$ はオレンジ色のグラフの $Y ≧ a$ の範囲の確率変数から計算した期待値の残りを表します。
$P(Y=y)$ は確率を表すのですべての $y$ に対して $P(Y=y) ≧ 0$ が成り立ちます。また、$y ≧ 0$ から $\sum_{0 ≦ y < a} yP(Y=y) ≧ 0$ が成り立つことから、下記の式が成り立ちます。
$E[Y] = \sum_{0 ≦ y < a} yP(Y=y) + \sum_{a ≦ y} yP(Y=y) ≧ \sum_{a ≦ y} yP(Y=y)$、($\forall a > 0$)
従って、下記の式が成り立ち、この式は $Y$ の期待値である $E[Y]$ がオレンジ色のグラフの $Y ≧ a$ の範囲の確率変数から計算された期待値の一部以上になることを意味します。
$E[Y] ≧ \sum_{a ≦ y} yP(Y=y)$、($\forall a > 0$)
マルコフの不等式の証明の手順 2
次に、上記の式の右辺の $\sum_{a ≦ y} yP(Y=y)$ について考えます。
この式を計算する際の $y$ は常に $a ≦ y$ なので下記の式が成り立ちます。
$\sum_{a ≦ y} yP(Y=y) ≧ \sum_{a ≦ y} aP(Y=y)$
また、$a$ は $y$ に影響されない独立した値であることから下記の式が成り立ちます。
$\sum_{a ≦ y} aP(Y=y) = a\sum_{a ≦ y} P(Y=y)$
$\sum_{a ≦ y} P(Y=y)$ は確率変数 $Y$ の実現値 $y$ が $a ≦ y$ となる場合の確率の合計なので下記の式が成り立ちます。
$\sum_{a ≦ y} P(Y=y) = P(Y ≧ a)$
従って、下記の式が成り立ちます。
$\sum_{a ≦ y} aP(Y=y) = a\sum_{a ≦ y} P(Y=y) = aP(Y ≧ a)$
マルコフの不等式の証明の手順 3
上記の式をマルコフの不等式の証明の手順 1 の式に当てはめると下記の式が成り立ちます。
$E[Y] ≧ aP(Y ≧ a)$、($\forall a > 0$)
$a > 0$ なので両辺を $a$ で割っても不等号の向きは変わらないので下記の式が成り立ちます。
$\frac{1}{a}E[Y] ≧ P(Y ≧ a)$、($\forall a > 0$)
式の左右を入れ替え(その際に不等号の向きが反対になります)、$Y$ を $|X|$ で置き換えると下記のマルコフの不等式になります。
$P(|X|≧ a)≦\frac{1}{a}E[|X|]$、($\forall a > 0$)
以上でマルコフの不等式が証明されました。
マルコフの不等式の言葉での説明
マルコフの不等式を言葉で説明すると以下のようになります。マルコフの不等式の意味がわかれば式の見た目に反して難しいことを表していないことがわかるのではないでしょうか。
- $P(|X|≧ a)$ は確率変数 $X$ が 0 から $a$ 以上離れた値になる確率を表すので、先程のグラフで示したように $a$ が大きくなると $|X|≧ a$ となる $X$ の範囲は小さくなり、 $P(|X|≧ a)$ は小さくなる
- $|X|$ が大きい値になる確率が高ければ高い程 $|X|$ の期待値である $E[|X|]$ は大きくなる。そのため、$E[|X|]$ が大きくなるとオレンジ色の部分の面積が増えるので、$|X|$ の期待値が大きい程 $P(|X|≧ a)$ は大きくなる
マルコフの不等式の右辺の $\frac{1}{a}E[|X|]$ はそのことを表しており、$P(|X|≧ a)$ の最大値(上限)が以下のようになることを表しています。
- $a$ に反比例する
- $|X|$ の期待値 $E[|X|]$ に比例する
マルコフの不等式が成り立つことの確認
具体例として、下記の確率分布に従う確率変数 $X$ に対してマルコフの不等式が成り立つことを示します。
| 確率変数 $X$ | -3 | -2 | -1 | 0 | 1 | 2 | 3 |
|---|---|---|---|---|---|---|---|
| 確率 | 0.2 | 0.1 | 0.25 | 0.15 | 0.05 | 0.1 | 0.15 |
確率変数 $|X|$ の確率分布は下記のようになります。
| 確率変数 $|X|$ | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| 対応する確率変数 $X$ の実現値 | 0 | -1 と 1 | -2 と 2 | -3 と 3 |
| 確率 | 0.15 | 0.25 + 0.05 = 0.3 |
0.1 + 0.1 = 0.2 |
0.2 + 0.15 = 0.35 |
下記はそのことを確認するプログラムです。今回の記事の最初で作成した X と P と区別できるように変数名は X2 と P2、Xabs2、Pabs2 にしました。
X2 = np.array([-3, -2, -1, 0, 1, 2, 3])
P2 = np.array([0.2, 0.1, 0.25, 0.15, 0.05, 0.1, 0.15])
Xabs2, Pabs2 = calc_abs_pd(X2, P2)
for x, p in zip(Xabs2, Pabs2):
print(f"P(|X| = {x}) = {p:.2f}")
実行結果
P(|X| = 0) = 0.15
P(|X| = 1) = 0.30
P(|X| = 2) = 0.20
P(|X| = 3) = 0.35
$a = 1$ の場合の $P(|X| ≧ a)$ は $P(|X|=1) + P(|X| = 2) + P(|X|=3) = 0.3+0.2+0.35 = 0.85$ になります。
また、$E[|X|] = 0 × 0.15 + 1 × 0.3 + 2 × 0.2 + 3 × 0.35 = 1.75$ となるので $a = 1$ の場合の $\frac{1}{a}E[|X|] = 1.75$ となります。
従って、下記のマルコフの不等式が成り立つことが確認できました。
$P(|X| ≧ a) = 0.85 ≦ \frac{1}{a}E[|X|] = 1.75$
上記は手作業で確認を行いましたが、手作業の計算は面倒なので 1 から特定の整数までの $a$ に対してマルコフの不等式が成り立つことを確認する下記の check_markov という関数を定義することにします。
-
1 行目:確率変数の値の一覧と対応する確率を代入する
X、Pと $a$ の最大値を代入するmaxaを仮引数として持つcheck_markovを定義する。 -
2 ~ 6 行目:
XとPから確率変数 $|X|$ の確率分布のデータと、その期待値と分散を計算して表示する -
7 ~ 10 行目:
1からmaxaまでのそれぞれの値に対してマルコフの不等式の左辺と右辺の計算結果とマルコフの不等式の真偽(True/False)を表示する
1 def check_markov(X, P, maxa):
2 Xabs, Pabs = calc_abs_pd(X, P)
3 Eabs = np.sum(Xabs * Pabs)
4 Vabs = np.sum(Xabs * Xabs * Pabs) - Eabs ** 2
5 print(f"E[|X|] = {Eabs:6.3f}")
6 print(f"V[|X|] = {Vabs:6.3f}")
7 for a in range(1, maxa + 1):
8 Pgta = np.ma.array(Pabs, mask=Xabs<a)
9 p = np.sum(Pgta)
10 print(f"P(|X| ≧ {a:2d}) = {p:.3f} E[|X|]/{a:2d} = {Eabs/a:4.3f} {p <= Eabs/a}")
行番号のないプログラム
def check_markov(X, P, maxa):
Xabs, Pabs = calc_abs_pd(X, P)
Eabs = np.sum(Xabs * Pabs)
Vabs = np.sum(Xabs * Xabs * Pabs) - Eabs ** 2
print(f"E[|X|] = {Eabs:6.3f}")
print(f"V[|X|] = {Vabs:6.3f}")
for a in range(1, maxa + 1):
Pgta = np.ma.array(Pabs, mask=Xabs<a)
p = np.sum(Pgta)
print(f"P(|X| ≧ {a:2d}) = {p:.3f} E[|X|]/{a:2d} = {Eabs/a:4.3f} {p <= Eabs/a}")
下記は上記のプログラムで $a = 1、2、3$ の場合の先程の確率変数に対してマルコフの不等式が成り立つことを確認するプログラムで、すべての場合で True が表示されることが確認されました。
check_markov(X2, P2, 3)
実行結果
E[|X|] = 1.750
V[|X|] = 1.187
P(|X| ≧ 1) = 0.850 E[|X|]/ 1 = 1.750 True
P(|X| ≧ 2) = 0.550 E[|X|]/ 2 = 0.875 True
P(|X| ≧ 3) = 0.350 E[|X|]/ 3 = 0.583 True
下記は今回の記事で最初に作成した確率変数に対して $a$ が 1 以上 10 以下の場合にマルコフの不等式が成り立つことを確認するプログラムで、すべての場合で True が表示されることが確認されました。興味がある方は他の確率変数でも確認してみて下さい。
check_markov(X, P, 10)
E[|X|] = 5.394
V[|X|] = 10.779
P(|X| ≧ 1) = 0.937 E[|X|]/ 1 = 5.394 True
P(|X| ≧ 2) = 0.865 E[|X|]/ 2 = 2.697 True
P(|X| ≧ 3) = 0.743 E[|X|]/ 3 = 1.798 True
P(|X| ≧ 4) = 0.599 E[|X|]/ 4 = 1.349 True
P(|X| ≧ 5) = 0.559 E[|X|]/ 5 = 1.079 True
P(|X| ≧ 6) = 0.501 E[|X|]/ 6 = 0.899 True
P(|X| ≧ 7) = 0.466 E[|X|]/ 7 = 0.771 True
P(|X| ≧ 8) = 0.356 E[|X|]/ 8 = 0.674 True
P(|X| ≧ 9) = 0.247 E[|X|]/ 9 = 0.599 True
P(|X| ≧ 10) = 0.121 E[|X|]/10 = 0.539 True
チェビシェフの不等式
下記はチェビシェフの不等式の説明です。
期待値 $μ = E[X]$ と分散 $σ^2 = V[X]$ が存在する任意の確率変数 $X$ と任意の正の実数 $a > 0$ に対して下記の不等式が成り立つ。
$P(|X - μ|≧ a)≦\frac{σ^2}{a^2}$、($\forall a > 0$)
チェビシェフの不等式は、マルコフの不等式の左辺の確率変数を $|X|$ から $|X - μ|$ に置き換えた場合の $P(|X - μ|≧ a)$ の最大値を表す不等式です。下記は期待値が約 3 の確率変数の $P(|X - μ|≧ 5)$ をオレンジ色で表示するグラフを描画するプログラムです。今回の記事の最初で作成した確率分布の期待値は約 0 なので、期待値が約 3 になるように確率変数の最小値と最大値の平均が (-7 + 13) ÷ 2 = 3 となるような確率分布を create_pd で作成しました。
X3, P3 = create_pd(minx=-7, maxx=13)
E = np.sum(X3 * P3)
labelt = f"P(|X - μ|>={5})"
labelf = f"P(|X - μ|<{5})"
show_pd(X3, P3, cond=np.abs(X3 - E)>=5, labelt=labelt, labelf=labelf)
実行結果
期待値 = 3.030
分散 = 38.872

実行結果からわかるように上記のグラフの期待値は約 3 で、グラフの青い部分の中心が 3 でその範囲が 3 ± 5 の範囲になることが確認できます。このことから、$P(|X - μ|≧ a)$ は $P(|X|≧ a)$ 中心となる場所が 0 と期待値であるかの違いを除けば同様の性質を持つことがわかります。
参考までにチェビシェフの不等式の Wikipedia のリンクを下記に記します。
チェビシェフの不等式の証明の手順 1
チェビシェフの不等式の証明は以下のように行うことができます。
確率変数 $Y$ を $Y = X - μ$、確率変数 $Z$ を $Z = Y^2 = (X - μ) ^ 2$ という式で定義すると、マルコフの不等式から下記の式が成り立ちます。
$P(|Z| ≧ a) ≦ \frac{1}{a}E[|Z|]$、($\forall a > 0$)
確率変数 $Z$ の実現値は確率変数 $X$ の実現値 $x$ に対して $(x - μ) ^ 2$ を計算したものなので、その値は必ず 0 以上の値になります。従って、確率変数 $|Z|$ の絶対値を外すことができるので $|Z| = Z = Y ^2$ が成り立ちます。これを上記の式に当てはめると下記のようになります。
$P(Y^2 ≧ a) ≦ \frac{1}{a}E[Y^2]$、($\forall a > 0$)
また、上記の式には $a > 0$ という条件があるので、$\sqrt{a}$ を計算することができます。$b = \sqrt{a}$3 のように $a$ の平方根の正の値のほうと定義すると $a = b^2$ となります。また、$a > 0$ から $b = \sqrt{a} > 0$ となるので上記の式に当てはめると下記のようになります。
$P(Y^2 ≧ b^2) ≦ \frac{1}{b^2}E[Y^2]$、($\forall b > 0$)
$b$ は 0 より大きな数値を表す記号なので、別の記号に置き換えても上記の式は成り立ちます。そこで、上記の $b$ を $a$ で置き換えると下記のようになります。
$P(Y^2 ≧ a^2) ≦ \frac{1}{a^2}E[Y^2]$、($\forall a > 0$)
チェビシェフの不等式の証明の手順 2
次に、上記の不等式の左辺の $P(Y^2 ≧ a^2)$ について考えることにします。
この式は確率変数 $Y$ の実現値である $y$ が $y ^ 2 ≧ a^ 2$ となる場合の確率を表します。$y^2 ≧ a ^2$ が成り立つとき、両辺の正の平方根を計算すると $y^2$ の正の平方根は $|y|$、$a ^ 2$ の正の平方根は $a > 0$ なので $a$ となります。正の平方根を計算した場合は不等号の向きは変わらないので下記の式が成り立ちます。なお、$a > 0$ なので $y = 0$ になることはありません。
$|y| ≧ a$
$y^2$ の平方根は $y ≠ 0$ の場合は正と負の 2 種類の値がありますが、どちらの場合でもその絶対値を表す $|y|$ が正の平方根になります。
逆に $|y| ≧ a$ かつ $a > 0$ が成り立つときに両辺を 2 乗した $y ^ 2 ≧ a ^ 2$ が成り立ちます。従って、確率変数 $Y ^ 2$ の実現値である $y^2$ が $y^2 ≧ a ^2$ を満たすことと、確率変数 $Y$ の実現値である $y$ が $|y| ≧ a$ を満たすことは一対一に対応するので、下記の式が成り立ちます。
$P(Y^2 ≧ a^2) = P(|Y| ≧ a)$、($\forall a > 0$)
これをチェビシェフの不等式の証明の手順 1 で示した式の左辺に当てはめると下記の式が成り立ちます。
$P(|Y| ≧ a) ≦ \frac{1}{a^2}E[Y^2]$
チェビシェフの不等式の証明の手順 3
上記の式の $Y$ を $Y = (X - μ)$ で置き換えると、下記の式になります。
$P(|X - μ|≧ a)≦\frac{1}{a^2}E[(X - μ)^2]$、($\forall a > 0$)
分散の定義から $σ^2 = V[X] = E[(X - μ)^2]$ なので上記の式は下記のチェビシェフの不等式になります。従って、チェビシェフの不等式が証明されたことになります。
$P(|X - μ|≧ a)≦\frac{σ^2}{a^2}$、($\forall a > 0$)
チェビシェフの不等式の意味
チェビシェフの不等式の左辺の $P(|X - μ|≧ a)$ を前回の記事で説明した $ε$ 近傍という用語で説明すると、確率変数 $X$ の実現値が期待値の $a$ 近傍から外れる確率を表します。
また、右辺の確率変数の分散を表す $σ^2$ は以前の記事で説明したように確率分布のばらつきを表す値で、$σ^2 = V[X] = E[(X - E[X])^2]$ という、「期待値からの差の 2 乗」の平均によって計算されるため、期待値に近い値の確率が高く、期待値から離れた値の確率が低い程小さな値になります。
このことから、確率変数 $X$ の実現値が期待値の $a$ 近傍から外れる確率を表す $P(|X - μ|≧ a)$ は分散が大きくなるほど高くなることがわかります。また、$a$ 近傍の $a$ を大きくするとその確率は低くなります。
チェビシェフの不等式の右辺の $\frac{σ^2}{a^2}$ はそのことを表しており、$P(|X - μ|≧ a)$ の最大値(上限)が以下のようになることを表しています。
- $X$ の分散 $V[X]$ に比例する
- $a^2$ に反比例する
チェビシェフの不等式が成り立つことの確認
マルコフの不等式の場合と同様に 1 から特定の整数までの $a$ に対してチェビシェフの不等式が成り立つことを確認する下記の check_chebyshev という関数を定義することにします。
-
2 ~ 6 行目:
XとPから期待値と分散を計算して表示する -
6 ~ 9 行目:
1からmaxaまでのそれぞれの値に対してチェビシェフの不等式の左辺と右辺の計算結果とチェビシェフの不等式の真偽(True/False)を表示する
1 def check_chebyshev(X, P, maxa):
2 E = np.sum(X * P)
3 V = np.sum(X * X * P) - E ** 2
4 print(f"E[X] = {E:6.3f}")
5 print(f"V[X] = {V:6.3f}")
6 for a in range(1, maxa + 1):
7 Pgta = np.ma.array(P, mask=np.abs(X - E)<a)
8 p = np.sum(Pgta)
9 print(f"P(|X - E[X]| ≧ {a:2d}) = {p:.3f} V[X]/{(a ** 2):3d} = {V/(a ** 2):6.3f} {p <= V/a/a}")
行番号のないプログラム
def check_chebyshev(X, P, maxa):
E = np.sum(X * P)
V = np.sum(X * X * P) - E ** 2
print(f"E[X] = {E:6.3f}")
print(f"V[X] = {V:6.3f}")
for a in range(1, maxa + 1):
Pgta = np.ma.array(P, mask=np.abs(X - E)<a)
p = np.sum(Pgta)
print(f"P(|X - E[X]| ≧ {a:2d}) = {p:.3f} V[X]/{(a ** 2):3d} = {V/(a ** 2):6.3f} {p <= V/a/a}")
下記は、先程計算した確率分布に対して $a$ が 1 以上 10 以下のそれぞれの整数の場合に対するチェビシェフの不等式が成り立つかどうかを計算するプログラムです。実行結果からすべての場合でチェビシェフの不等式が成り立つことが示されました。
check_chebyshev(X3, P3, 10)
実行結果
E[X] = 3.030
V[X] = 38.872
P(|X - E[X]| ≧ 1) = 0.890 V[X]/ 1 = 38.872 True
P(|X - E[X]| ≧ 2) = 0.815 V[X]/ 4 = 9.718 True
P(|X - E[X]| ≧ 3) = 0.777 V[X]/ 9 = 4.319 True
P(|X - E[X]| ≧ 4) = 0.675 V[X]/ 16 = 2.429 True
P(|X - E[X]| ≧ 5) = 0.535 V[X]/ 25 = 1.555 True
P(|X - E[X]| ≧ 6) = 0.467 V[X]/ 36 = 1.080 True
P(|X - E[X]| ≧ 7) = 0.326 V[X]/ 49 = 0.793 True
P(|X - E[X]| ≧ 8) = 0.254 V[X]/ 64 = 0.607 True
P(|X - E[X]| ≧ 9) = 0.152 V[X]/ 81 = 0.480 True
P(|X - E[X]| ≧ 10) = 0.072 V[X]/100 = 0.389 True
大数の法則の証明
最後にチェビシェフの不等式を利用して大数の法則を証明します。
標本サイズが $n$ の標本平均を表す確率変数 $\bar{X_n}$ に対してチェビシェフの不等式を当てはめると下記のようになります。
$P(|\bar{X_n} - μ|≧ a)≦\frac{1}{a^2}V[\bar{X_n}]$、($\forall a > 0$)
以前の記事で説明したように、標本平均の分散は下記の式のように母分散 $σ^2 = V[X]$ を標本サイズ $n$ で割った値になります。
$V[\bar{X_n}] = \frac{1}{n}V[X] = \frac{σ^2}{n}$
従って、先程の式は下記のようになります。
$P(|\bar{X_n} - μ|≧ a)≦\frac{1}{a^2}\frac{σ^2}{n}$、($\forall a > 0$)
$n → ∞$ とした場合の右辺の極限値は $a$ と $σ$ は有限な値なので 0 になります。従って、上記の式の両辺に対して $n$ を大きくした場合の極限値を計算すると以下の式になります。
$\lim_{n \to \infty} P(|\bar{X_n} - μ|≧ a) ≦ \lim_{n \to \infty} \frac{1}{a^2}\frac{σ^2}{n} = 0$、($\forall a > 0$)
確率の最低値は 0 なので上記の式は下記のようになります。
$0 ≦ \lim_{n \to \infty} P(|\bar{X_n} - μ|≧ a) ≦ 0$、($\forall a > 0$)
0 以上かつ 0 以下ということは 0 なので、上記の式は下記のようになります。
$\lim_{n \to \infty} P(|\bar{X_n} - μ|≧ a) = 0$、($\forall a > 0$)
上記の $a$ を $ε$ で置き換え、不等式を $≧$ から $>$ に置き換えると下記の大数の弱法則を表す式になるので、大数の法則が証明されました。なお、不等式を置き換えても良い理由についてはこの後で補足します。
$\lim_{n \to \infty} P(|\bar{X_n} - μ| > ε) = 0$、($\forall ε > 0$)
不等式に関する補足
上記で不等号を置き換えても良い理由は、前回の記事で説明したように、大数の法則での $ε$ 近傍から外れる確率を表す式を $P(|\bar{X_n} - μ|≧ ε)$ と $P(|\bar{X_n} - μ| > ε)$ のどちらで記述しても構わないからです。
そのどちらでも構わない理由について補足します。離散型確率変数 $X$ から無作為抽出を行った標本サイズ $n$ の標本平均を表す確率変数 $\bar{X_n}$ の実現値は $n$ を大きくすると実質的に連続した値のように細かくなっていきます。例えば、元の確率変数 $X$ の実現値が 0 と 1 の場合の $\bar{X_n}$ の実現値は $\frac{0}{n} = 0$、$\frac{1}{n}$、$\frac{2}{n}$、・・・、$\frac{n}{n} = 1$ となるので、$n$ を大きくすると実現値がとる値の間隔($\frac{1}{n}$)が極めて小さくなります。
大数の法則の文脈において $n$ を十分に大きくすると標本平均 $\bar{X}$ が特定の値をとる確率は無視できるほど小さくなります。従って、大数の法則の定義 3 の式の $P(|\bar{X_n} - μ|≧ ε)$ を $P(|\bar{X_n} - μ| > ε)$ に置き換えても極限値の値は変わりません。
一般的に連続型確率変数では、確率変数が特定の値を取る確率を 0 と考えます。そのため、連続型確率分布の場合は、例えば 0 以上 1 以下のように範囲を決めることで初めて 0 より大きい確率が定まります。
なお、連続型確率変数の確率分布を表す関数のことを確率質量関数ではなく、確率密度関数と呼びます。
大数の法則の他の性質や確認については次回の記事で行う予定です。
今回の記事のまとめ
今回の記事では大数の弱法則の証明をおこないました。
また、今回の記事で定義した関数は util.py に保存することにします。
本記事で入力したプログラム
| リンク | 説明 |
|---|---|
| marubatsu.ipynb | 本記事で入力して実行した JupyterLab のファイル |
| util.py | 本記事で更新した util_new.py |
次回の記事