目次と前回の記事
これまでに作成したモジュール
以下のリンクから、これまでに作成したモジュールを見ることができます。
| リンク | 説明 |
|---|---|
| marubatsu.py | Marubatsu、Marubatsu_GUI クラスの定義 |
| ai.py | AI に関する関数 |
| test.py | テストに関する関数 |
| util.py | ユーティリティ関数の定義。現在は gui_play のみ定義されている |
| tree.py | ゲーム木に関する Node、Mbtree クラスの定義 |
| gui.py | GUI に関する処理を行う基底クラスとなる GUI クラスの定義 |
AI の一覧とこれまでに作成したデータファイルについては、下記の記事を参照して下さい。
用語の定義
最初に、今回の記事で扱う αβ 法 に関するいくつかの用語の定義を行うことにします。
αβ 法 ではゲーム木の中の 特定の局面のノードを指定 してその評価値の計算を行います。また、そのノードの評価値を計算するために、その 子孫ノードの評価値の計算を行う 必要があります1。例えば、下図の 赤枠のノードの評価値を αβ 法で計算 するためには、紫枠で囲われたノードの評価値を計算 する必要があります2。

上図の 紫枠のノード は、赤枠のノード を ルートノード とする 〇× ゲームのゲーム木の 部分木 です。αβ 法で評価値を計算するノードの深さが 深いほど 計算にかかる 時間が減る のは、部分木に含まれるノードの数 がノードの深さが 深いほど減るから です。
そこで、本記事では αβ 法に関する説明を行う際 に、αβ 法で評価値を計算する上図の赤枠のノードのことを αβ のルートノード、αβ のルートノードの評価値を計算するために評価値の計算を行う必要があるノードのことを αβ の子孫ノード と表記することにします。また、上図の紫枠の部分木のことを αβ の部分木 と表記することにします。αβ のルートノードは、αβ の部分木のルートノードです。
αβ 法の評価値の計算の手順の視覚化
今回の記事では、Mbtree_Anim クラスを利用して、αβ 法の評価値の計算の手順の視覚化 を行います。そのためには、Mbtree クラスで幅優先アルゴリズムで評価値を計算する calc_score_by_bf メソッドや、深さ優先アルゴリズムで評価値を計算する calc_score_by_df と同様の方法 で、Mbtree_Anim クラスで 評価値の計算の手順を表示するために必要なデータを計算 する必要があります。
視覚化に必要なデータの計算方法の復習
視覚化に必要なデータの計算方法 について忘れた方が多いと思いますので、復習します。以前の記事で説明したように、Mbtree_Anim では以下のような方法で視覚化を行います。
- 評価値の計算の過程で 処理を行うノードの移り変わりがわかる ようにする
- 評価値を計算 する タイミングがわかる ようにする
処理を行うノードの処理の移り変わり については、Mbtree クラスの nodelist_by_score という名前の属性にノードのデータを list で記録 します。評価値を計算するタイミング についてはノードの score_index 属性に、そのノードの評価値が計算されたタイミング を表す nodelist_by_score の要素の インデックスを記録 します。
calc_score_by_df の処理の復習
具体例として、calc_score_by_df での上記の処理を復習することにします。なお、calc_score_by_df の方を復習するのは、αβ 法が深さ優先アルゴリズムの一種 だからです。
calc_score_by_df は、実引数に algo="df" を記述して Mbtree クラスのインスタンスを作成 した場合に、__init__ メソッド内の下記のプログラムで 呼び出されます。この中の 3 行目 で nodelist_by_score の初期化処理 を行っています。
-
2 行目:深さ優先アルゴリズムでゲーム木を作成する
create_tree_by_dfを呼び出す -
3 行目:評価値を計算する際に辿ったノードの一覧を表す
nodelist_by_score属性を空の list で初期化する -
4 行目:実引数にゲーム木のルートノードを記述して
calc_score_by_dfを呼び出す
1 def __init__(self, algo="bf", 略):
略
2 self.create_tree_by_df(self.root)
3 self.nodelist_by_score = []
4 self.calc_score_by_df(self.root)
略
下記は、calc_score_by_df の定義です。このプログラムでは、深さ優先アルゴリズム で 各ノードの評価値、最大の評価値、最小の評価値3を 計算しています が、その際に nodelist_by_score と scorelist 属性に対して以下のような処理を行っています。
-
2 行目:
calc_score_by_dfの処理が 開始された時点で処理が 仮引数nodeに代入された ノードに移り変わる のでnodelist_by_scoreの要素にnodeを 追加する -
14 行目:子ノードに対する評価値の計算処理を行うための 10 行目の
calc_score_by_dfの処理が終了した時点 で、子ノードの処理からnodeのノードの処理に移り変わる のでnodelist_by_scoreの要素にnodeを 追加する -
23、24 行目:全ての子ノードの評価値を計算する処理が終了した時点で、
nodeの評価値が確定する のでnodelist_by_scoreの要素にnodeを 追加し、nodeのscore_index属性に追加したnodelist_by_scoreのインデックスを代入 する
1 def calc_score_by_df(self, node):
2 self.nodelist_by_score.append(node)
3 if node.mb.status != Marubatsu.PLAYING:
4 self.calc_score_of_node(node)
5 else:
6 score_list = []
7 max_score_list = []
8 min_score_list = []
9 for childnode in node.children:
10 score, max_score, min_score = self.calc_score_by_df(childnode)
11 score_list.append(score)
12 max_score_list.append(max_score)
13 min_score_list.append(min_score)
14 self.nodelist_by_score.append(node)
15 if node.mb.move_count % 2 == 0:
16 score = max(score_list)
17 else:
18 score = min(score_list)
19 node.score = score
20 node.max_score = max(max_score_list)
21 node.min_score = min(min_score_list)
22
23 self.nodelist_by_score.append(node)
24 node.score_index = len(self.nodelist_by_score) - 1
25 return node.score, node.max_score, node.min_score
calc_score_by_ab の定義
下記は、αβ 法 で評価値の計算を行う ai_by_abs の定義 です4。この関数 を上記の calc_score_by_df を参考にしながら修正していく ことで、αβ 法での評価値の計算の手順の 視覚化に必要なデータを計算しながら ゲーム木のノードの評価値を計算する calc_score_by_ab という Mbtree クラスのメソッドを定義 する事にします。
def ai_abs(mb, debug=False):
count = 0
def ab_search(mborig, alpha=float("-inf"), beta=float("inf")):
nonlocal count
count += 1
if mborig.status == Marubatsu.CIRCLE:
return 1
elif mborig.status == Marubatsu.CROSS:
return -1
elif mborig.status == Marubatsu.DRAW:
return 0
legal_moves = mborig.calc_legal_moves()
if mborig.turn == Marubatsu.CIRCLE:
for x, y in legal_moves:
mb = deepcopy(mborig)
mb.move(x, y)
score = ab_search(mb, alpha, beta)
if score >= beta:
return score
alpha = max(alpha, score)
return alpha
else:
for x, y in legal_moves:
mb = deepcopy(mborig)
mb.move(x, y)
score = ab_search(mb, alpha, beta)
if score <= alpha:
return score
beta = min(beta, score)
return beta
score = ab_search(mb)
dprint(debug, "count =", count)
if mb.turn == Marubatsu.CIRCLE:
score *= -1
return score
関数名と仮引数の変更
まず、calc_score_by_ab は Mbtree クラスの メソッドとして定義 するので、calc_score_by_ab には 仮引数 self を追加 する必要があります。
ai_abs はゲーム木の ノードを作成せず に処理を行うので、仮引数 mb に αβ のルートノードの 局面を表すデータを代入 して評価値の計算を行います。一方、calc_score_by_ab では、評価値の計算の手順を記録するために、αβ の部分木のノード に αβ 法の 計算過程で計算した評価値 を score 属性に代入して記録 する必要があるため、αβ のルートノード を表すデータを 代入する仮引数が必要 になります。そこで、ai_abs の仮引数 mb を、αβ のルートノードを代入 する abroot5という名前の仮引数に変更することにします。。
ai_abs 内で定義されている ローカル関数 ab_search に対しては、下記のような修正を行う必要があります。
- ノードの評価値を計算して
score属性に代入する処理を行うため、関数の名前をcalc_ab_scoreに修正 する - ノードのデータが必要となるので 仮引数
mborigをnodeに変更 する。nodeorigに変更しない理由はこの後で説明する - 局面を表すデータは、ノードを表す
nodeのmb属性に代入されているので、プログラム内のmborigをnode.mbに変更 する - 元のプログラムではゲーム木を作成せずに計算を行っているため、子ノードの局面の計算を行う際に、「合法手の一覧の計算」、「
mborigのコピー」、「コピーしたmbに対する合法手の着手」という処理を行う必要がある。一方、calc_score_by_abではcalc_score_by_dfと同様に ゲーム木の全てのノードは計算済 なので、ノードのコピーの処理を行う 必要はない。mborigをnodeorigに変更しないのはそのためである
下記は上記のように calc_score_by_ab を定義したプログラムです。
-
5 行目:メソッドの名前を
calc_score_by_abに修正し、仮引数selfを追加し、仮引数mbをabrootに修正する -
6、9、34 行目:元のプログラムでは、ローカル変数
countを利用してローカル関数ab_searchを呼び出した回数を数えていたため、ローカル関数ab_search内 でクロージャー変数countの値を変更するため にnonlocal countを記述する必要 があった。countを Mbtree クラスの インスタンスの属性であるself.countに修正する ことで、nonlocalという わかりづらい記述を行う必要がなくなる -
8 行目:ローカル関数の名前を
calc_ab_scoreに、仮引数mborigをnodeに修正する -
10、11 行目:元のプログラムでは、決着がついている局面の評価値 を if 文で計算していたが、その処理は Mbtree クラスの
calc_score_of_nodeメソッドで定義 されているので、決着がついている場合はcalc_score_of_nodeを呼び出す処理に修正する。この部分は先ほどのcalc_score_by_dfの 3、4 行目に相当する -
12 行目:
calc_score_of_nodeでは、計算した 評価値 をノードのscore属性に代入 する処理を行うので、node.scoreを返り値として返す ように修正する -
14 行目:
mborigをnode.mbに修正する -
15 行目:
nodeの子ノードの一覧のデータは、children属性に代入されているので、children属性に対する繰り返し処理を行う。元のプログラムのように それぞれの合法手に対してmborigをコピーしてその合法手を着手するという処理を行う必要はない。先ほどのcalc_score_by_dfの 9 行目に相当する -
16 行目:
childnodeを実引数に記述してcalc_ab_scoreを再帰呼び出しすることで、子ノードの評価値を計算する処理を行う。先ほどのcalc_score_by_dfの 10 行目に相当 -
18 行目:β 枝狩りによって、評価値が
scoreと計算されたので、ノードのscore属性にscoreを代入する -
21 行目:全ての子ノードの評価値が計算されたことで、ノードの評価値が
alphaと計算されたので、ノードのscore属性にalphaを代入する - 23 ~ 31 行目:14 ~ 22 行目と同様の修正を行う
-
33 行目:
calc_score_by_abが行う処理として、abrootを実引数に記述してcalc_ab_scoreを呼び出して、abrootの評価値を計算する - 35 行目の後に記述していた、〇 の手番の場合に評価値の正負を反転させる処理は、評価値の計算過程を表示する際には必要がない処理なので削除した
1 from marubatsu import Marubatsu
2 from tree import Mbtree
3 from ai import dprint
4
5 def calc_score_by_ab(self, abroot, debug=False):
6 self.count = 0
7
8 def calc_ab_score(node, alpha=float("-inf"), beta=float("inf")):
9 self.count += 1
10 if node.mb.status != Marubatsu.PLAYING:
11 self.calc_score_of_node(node)
12 return node.score
13 else:
14 if node.mb.turn == Marubatsu.CIRCLE:
15 for childnode in node.children:
16 score = calc_ab_score(childnode, alpha, beta)
17 if score >= beta:
18 node.score = score
19 return score
20 alpha = max(alpha, score)
21 node.score = alpha
22 return alpha
23 else:
24 for childnode in node.children:
25 score = calc_ab_score(childnode, alpha, beta)
26 if score <= alpha:
27 node.score = score
28 return score
29 beta = min(beta, score)
30 node.score = beta
31 return beta
32
33 calc_ab_score(abroot)
34 dprint(debug, "count =", self.count)
35
36 Mbtree.calc_score_by_ab = calc_score_by_ab
行番号のないプログラム
from marubatsu import Marubatsu
from tree import Mbtree
from ai import dprint
def calc_score_by_ab(self, abroot, debug=False):
self.count = 0
def calc_ab_score(node, alpha=float("-inf"), beta=float("inf")):
self.count += 1
if node.mb.status != Marubatsu.PLAYING:
self.calc_score_of_node(node)
return node.score
else:
if node.mb.turn == Marubatsu.CIRCLE:
for childnode in node.children:
score = calc_ab_score(childnode, alpha, beta)
if score >= beta:
node.score = score
return score
alpha = max(alpha, score)
node.score = alpha
return alpha
else:
for childnode in node.children:
score = calc_ab_score(childnode, alpha, beta)
if score <= alpha:
node.score = score
return score
beta = min(beta, score)
node.score = beta
return beta
calc_ab_score(abroot)
dprint(debug, "count =", self.count)
Mbtree.calc_score_by_ab = calc_score_by_ab
修正箇所(14 ~ 32 行目のインデントに関する修正の表示は省略しました)
from marubatsu import Marubatsu
from tree import Mbtree
from ai import dprint
-def ai_abs(mb, debug=False):
+def calc_score_by_ab(self, abroot, debug=False):
- count = 0
+ self.count = 0
- def ab_search(mborig, alpha=float("-inf"), beta=float("inf")):
+ def calc_ab_score(node, alpha=float("-inf"), beta=float("inf")):
- nonlocal count
- count += 1
+ self.count += 1
- if mborig.status == Marubatsu.CIRCLE:
- return 1
- elif mborig.status == Marubatsu.CROSS:
- return -1
- elif mborig.status == Marubatsu.DRAW:
- return 0
+ if node.mb.status != Marubatsu.PLAYING:
+ self.calc_score_of_node(node)
+ return node.score
+ else:
- legal_moves = mborig.calc_legal_moves()
- if mborig.turn == Marubatsu.CIRCLE:
+ if node.mb.turn == Marubatsu.CIRCLE:
- for x, y in legal_moves:
+ for childnode in node.children:
- mb = deepcopy(mborig)
- mb.move(x, y)
- score = ab_search(mb, alpha, beta)
+ score = calc_ab_score(childnode, alpha, beta)
if score >= beta:
+ node.score = score
return score
alpha = max(alpha, score)
+ node.score = alpha
return alpha
else:
- for x, y in legal_moves:
+ for childnode in node.children:
- mb = deepcopy(mborig)
- mb.move(x, y)
- score = ab_search(mb, alpha, beta)
+ score = calc_ab_score(childnode, alpha, beta)
if score <= alpha:
+ node.score = score
return score
beta = min(beta, score)
+ node.score = beta
return beta
- score = ab_search(mb)
+ calc_ab_score(abroot)
- dprint(debug, "count =", count)
+ dprint(debug, "count =", self.count)
- if mb.turn == Marubatsu.CIRCLE:
- score *= -1
- return score
Mbtree.calc_score_by_ab = calc_score_by_ab
上記のプログラムが正しく動作するかを確認するために、下記のプログラムの 1 行目で 深さ優先アルゴリズムで Mbtree クラスのインスタンスを作成 し、それに対してキーワード引数 debug=True を記述して calc_score_by_ab メソッドを呼び出して ルートノードの評価値 を αβ 法で計算 すると、実行結果のように 評価値を計算したノードの数 を表す、ローカル関数 calc_ab_score が呼び出された回数として 18297 が表示されます。これは、以前の記事で ai_abs(mb, debug=True) を実行した場合と 同じ であることが確認できます。また、3 行目で ルートノードの評価値を表示 すると、正しい 0 が計算されている ことが確認できます。
mbtree = Mbtree(algo="df")
mbtree.calc_score_by_ab(mbtree.root, debug=True)
print(mbtree.root.score)
実行結果
count = 18297
0
上記の 1 行目でゲーム木を新しく作成するのではなく、下記のプログラムのように深さ優先アルゴリズムで評価値を計算したゲーム木のデータが保存されている dfscore.mbtree をファイルから読み込めばよいのではないかと思った人がいるかもしれません。筆者も最初はそのようにしたのですが、下記のプログラムを実行すると、実行結果のようにエラーが発生します。
mbtree2 = Mbtree.load("../data/dfscore")
mbtree2.calc_score_by_ab(mbtree.root, debug=True)
実行結果
略
--> 355 node.score = (11 - node.depth) / 2 if self.shortest_victory else 1
356 elif node.mb.status == Marubatsu.DRAW:
357 node.score = 0
AttributeError: 'Mbtree' object has no attribute 'shortest_victory'
このエラーは、以下のような理由で発生します。そのため、ゲーム木を新しく作成する必要があります。
-
dfscore.mbtreeは 105 回目の記事でファイルに保存したデータである - Mbtree クラスの
shortest_victory属性は、118 回目の記事で追加したので、dftree.mbtree から読み込んだゲーム木のデータにはshortest_victory属性は存在しない -
calc_score_of_nodeメソッド内でshortest_victory属性を参照する処理が記述されている ので、dfscore.mbtreeから読み込んだゲーム木のデータに対してcalc_score_by_abを呼び出すとshortest_victory属性が存在しない というエラーが発生する
nodelist_by_score と score_index に関する処理の記述
次に、nodelist_by_by_score と score_index に関する処理を記述します。その際に行う処理は、下記の calc_score_by_df とほぼ同様 です。
1 def calc_score_by_df(self, node):
2 self.nodelist_by_score.append(node)
3 if node.mb.status != Marubatsu.PLAYING:
4 self.calc_score_of_node(node)
5 else:
6 score_list = []
7 max_score_list = []
8 min_score_list = []
9 for childnode in node.children:
10 score, max_score, min_score = self.calc_score_by_df(childnode)
11 score_list.append(score)
12 max_score_list.append(max_score)
13 min_score_list.append(min_score)
14 self.nodelist_by_score.append(node)
15 if node.mb.move_count % 2 == 0:
16 score = max(score_list)
17 else:
18 score = min(score_list)
19 node.score = score
20 node.max_score = max(max_score_list)
21 node.min_score = min(min_score_list)
22
23 self.nodelist_by_score.append(node)
24 node.score_index = len(self.nodelist_by_score) - 1
25 return node.score, node.max_score, node.min_score
下記は、上記のプログラムを参考 にして calc_score_by_ab を修正 したプログラムです。元のプログラムでは、ノードの評価値が確定 した下記の 8 行目の後、15 行目の後、18 行目の後、24 行目の後、27 行目の後で return 文を記述して ノードの評価値を返す処理 を行っていましたが、上記のプログラムの 23、24 行目のように 評価値の確定後 に nodelist_by_score の要素に node を追加 し、score_index 属性に 値を代入 する処理を行う必要があります。そこで return 文を削除 し、評価値の確定後の処理 を下記のプログラムの 29、30 行目でまとめて行う ように修正しました。
-
5 行目:
calc_ab_scoreを呼び出した直後に、nodelist_by_scoreの要素にnodeを追加する。上記の 2 行目と対応する -
13、22 行目:
calc_ab_scoreを呼び出して子ノードの評価値の計算の処理が終了した直後に、nodelist_by_scoreの要素にnodeを追加する。上記の 14 行目と対応する - 8 行目で呼び出された
calc_score_of_nodeの処理によって評価値がnodeのscore属性に代入される。その後の return 文を削除し、次に 29 行目の処理が行われるようにする -
15、16 行目:β 狩りが行われた際に
alphaにnodeの評価値であるscoreを代入し、break 文によって子ノードに対する繰り返し処理を終了する。その結果、次に 18 行目のnode.score = alphaによってnodeのscore属性に評価値が代入され、次に 29 行目の処理が行われるようになる - 18 行目で評価値を
score属性に代入した後の return 文を削除し、次に 29 行目の処理が行われるようにする。26 行目の次の return 文も同様の理由で削除する - 24、25 行目:α 狩りが行われた際に、上記の 15、16 行目と同様の処理を行う
-
29、30 行目:ノードの評価値が計算されたので
nodelist_by_scoreの要素にnodeを追加し、score_index属性にそのインデックスを代入する。上記の 23、24 行目に対応する -
31 行目:
nodeの評価値を表すnode.scoreを返り値として返すようにする -
33 行目:
calc_score_by_abが行う処理として、nodelist_by_scoreを空の list で初期化する処理を追加する
1 def calc_score_by_ab(self, abroot, debug=False):
2 self.count = 0
3
4 def calc_ab_score(node, alpha=float("-inf"), beta=float("inf")):
5 self.nodelist_by_score.append(node)
6 self.count += 1
7 if node.mb.status != Marubatsu.PLAYING:
8 self.calc_score_of_node(node)
9 else:
10 if node.mb.turn == Marubatsu.CIRCLE:
11 for childnode in node.children:
12 score = calc_ab_score(childnode, alpha, beta)
13 self.nodelist_by_score.append(node)
14 if score >= beta:
15 alpha = score
16 break
17 alpha = max(alpha, score)
18 node.score = alpha
19 else:
20 for childnode in node.children:
21 score = calc_ab_score(childnode, alpha, beta)
22 self.nodelist_by_score.append(node)
23 if score <= alpha:
24 beta = score
25 break
26 beta = min(beta, score)
27 node.score = beta
28
29 self.nodelist_by_score.append(node)
30 node.score_index = len(self.nodelist_by_score) - 1
31 return node.score
32
33 self.nodelist_by_score = []
34 calc_ab_score(abroot)
35 dprint(debug, "count =", self.count)
36
37 Mbtree.calc_score_by_ab = calc_score_by_ab
行番号のないプログラム
def calc_score_by_ab(self, abroot, debug=False):
self.count = 0
def calc_ab_score(node, alpha=float("-inf"), beta=float("inf")):
self.nodelist_by_score.append(node)
self.count += 1
if node.mb.status != Marubatsu.PLAYING:
self.calc_score_of_node(node)
else:
if node.mb.turn == Marubatsu.CIRCLE:
for childnode in node.children:
score = calc_ab_score(childnode, alpha, beta)
self.nodelist_by_score.append(node)
if score >= beta:
alpha = score
break
alpha = max(alpha, score)
node.score = alpha
else:
for childnode in node.children:
score = calc_ab_score(childnode, alpha, beta)
self.nodelist_by_score.append(node)
if score <= alpha:
beta = score
break
beta = min(beta, score)
node.score = beta
self.nodelist_by_score.append(node)
node.score_index = len(self.nodelist_by_score) - 1
return node.score
self.nodelist_by_score = []
calc_ab_score(abroot)
dprint(debug, "count =", self.count)
Mbtree.calc_score_by_ab = calc_score_by_ab
修正箇所
def calc_score_by_ab(self, abroot, debug=False):
self.count = 0
def calc_ab_score(node, alpha=float("-inf"), beta=float("inf")):
+ self.nodelist_by_score.append(node)
self.count += 1
if node.mb.status != Marubatsu.PLAYING:
self.calc_score_of_node(node)
- return node.score
else:
if node.mb.turn == Marubatsu.CIRCLE:
for childnode in node.children:
score = calc_ab_score(childnode, alpha, beta)
+ self.nodelist_by_score.append(node)
if score >= beta:
- node.score = score
- return
+ alpha = score
+ break
alpha = max(alpha, score)
node.score = alpha
- return alpha
else:
for childnode in node.children:
score = calc_ab_score(childnode, alpha, beta)
+ self.nodelist_by_score.append(node)
if score <= alpha:
- node.score = score
- return
+ beta = score
+ break
beta = min(beta, score)
node.score = beta
- return beta
+ self.nodelist_by_score.append(node)
+ node.score_index = len(self.nodelist_by_score) - 1
+ return node.score
+ self.nodelist_by_score = []
calc_ab_score(abroot)
dprint(debug, "count =", self.count)
Mbtree.calc_score_by_ab = calc_score_by_ab
上記のプログラムでは calc_score_by_ab で行われる処理が、2 行目、33 ~ 35 行目の順で行われます。そのことがわかりづらいと思った方は self.count = 0 を 33 行目の前に移動して下さい。
上記の修正後に下記のプログラムを実行すると、実行結果のように先程と同じ表示が行われることが確認できます。
mbtree.calc_score_by_ab(mbtree.root, debug=True)
print(mbtree.root.score)
実行結果
count = 18297
0
また、下記のプログラムを実行する事で、nodelist_by_score の 要素の数が 54890 であることが確認できます。また、αβ 法では αβ のルートノードの評価値 は 最後に計算される ので、ルートノードの score_index 属性の値が nodelist_by_score の 最後の要素のインデックス である 54889 に 正しく計算されている ことが確認できます。
print(len(mbtree.nodelist_by_score))
print(mbtree.root.score_index)
実行結果
54890
54889
Mbtree_Anim でのアニメーションの確認
次に、下記のプログラムで αβ 法で評価値が計算された mbtree の 評価値の計算の手順 を Mbtree_Anim で表示して 確認する ことにします。
from tree import Mbtree_Anim
Mbtree_Anim(mbtree, isscore=True)
下図はアニメーションの 15 フレーム目の部分木の図です。このフレームで 赤枠の局面の評価値が 1 であることが 計算されました。

下図はその次の 16 フレーム目の部分木の図で、上図の赤枠のノードから 下図の赤枠の子ノードに処理が移動 したことを表します。

上図の 赤枠のノード は × の手番 のノードなので min ノード です。前回の記事で説明したように、min ノードでは下記の条件が満たされた場合に α 狩り を行います。
- それまでに計算された 兄弟ノード の 評価値の最大値を α とする
- 子ノードの中 で α 以下 の評価値が 計算された時点 で 残りの子ノードの評価値の計算を省略 する
上図では赤枠の 兄弟ノードの評価値の最大値は 1 なので α は 1 です、子ノードの中 で α 以下の 1 という評価値が 計算された ので、α 狩り を行って 残りの子ノード の評価値の 計算が省略 され、赤枠のノードの評価値が 1 で確定 します。そのことは、その次の下図の 17 フレーム目の部分木の図で、上図の赤枠の次の子ノードが赤枠のノードにならず に、上図の赤枠のノードの評価値が 1 と表示 されたことで 確認できます。下図の 紫枠の中のノード が、α 狩り によって評価値の 計算が省略されたノード です。

ここまでで、α 狩り の計算の手順が 正しく表示 されることが確認できました。
calc_score_by_ab で評価値を計算した mbtree のデータのバグ
上記から、αβ 法の評価値の計算の手順の表示がうまく行われるように見えるかもしれませんが、実際には mbtree のデータにはバグが存在 します。そのことは上記の後のフレームを見ることで確認することができます。
下図は次の 18 フレームの図で、17 フレームの 上図の赤枠のノードの評価値が確定 したので、下図のようにその 親ノードが赤枠のノード になります。この図には問題はありません。

下図は、その次の 19 フレームの図です。下図の 赤枠のノード は上図の赤枠のノードの 次の子ノード になっているので 正しい ですが、図の 赤丸のノードの評価値が表示されてしまう というおかしな現象が発生しています。このバグの原因について少し考えてみて下さい。
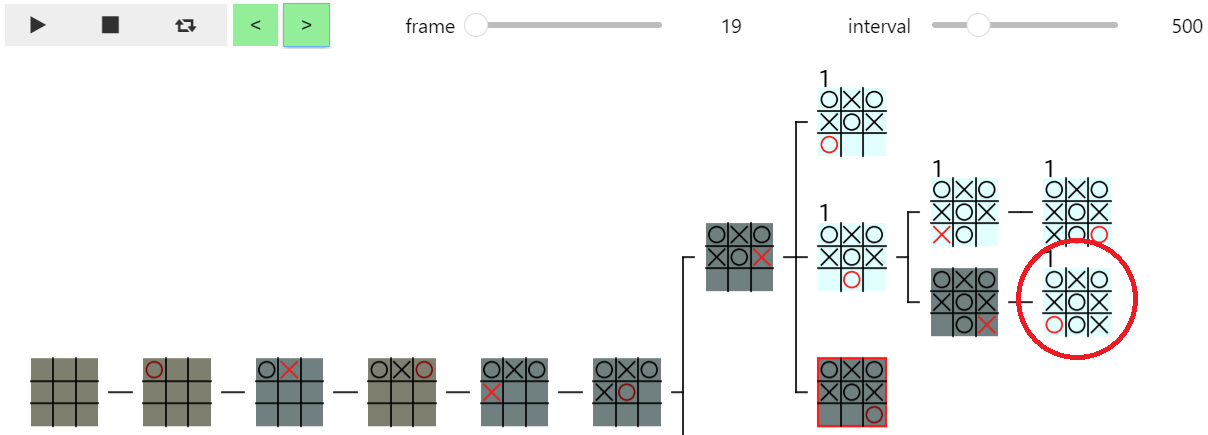
バグの原因の検証
mbtree は最初は Mbtree(algo="df") によって、幅優先アルゴリズム で ゲーム木の作成 と ノードの評価値を計算 したデータです。その後で calc_score_by_ab を呼び出して ゲーム木のルートノードの評価値 を αβ 法で計算 する処理を行っています。
αβ 法 では α 狩りと β 狩り によって、一部のノードに対する処理が省略 されてしまうため、それらの 省略されたノードの score_index 属性の値 は、calc_score_by_ab の処理によって 変化しません。そのため、それらのノードの score_index 属性の値 は、calc_score_by_df で計算された値 が calc_score_by_ab の処理によって上書きされずに そのまま代入されて残っている ことになります。
上図の赤丸のノード は、α 狩り によって calc_score_by_ab での 計算が省略されたノード なので、score_index 属性には calc_score_by_df によって計算された値が代入されています。また、上図では 19 フレーム目 で赤丸のノードの 評価値が表示された ことから、赤丸のノードの score_index 属性には 19 が代入されている ことがわかります。
そのことは、下図のプログラムで calc_score_by_df によって 評価値を計算したゲーム木 のデータに対して Mbtree_Anim で 19 フレーム目を表示 すると、実行結果のように 19 フレーム目で上図の赤丸のノードの評価値が表示される ことから確認できます。
mbtree_df = Mbtree(algo="df")
Mbtree_Anim(mbtree_df, isscore=True)
実行結果

バグの原因がわかったので、バグを修正する方法について少し考えてみて下さい。
バグの修正
バグの原因は、calc_score_by_ab の処理によって score_index 属性の値が 計算されないノードが存在する 事なので、calc_score_by_ab の処理の中で、αβ 法の処理を行う前に 全てのノードの score_index 属性の値を 何らかの値で初期化する という方法が考えられます。どのような値で初期化すればよいかについて少し考えてみて下さい。
Mbtree_Anim では、アニメーションの フレームが score_index 属性の値以上 になった場合に、その ノードを明るく表示して上に評価値を表示 します。αβ 法で 枝狩りされるノード は 評価値が計算されることがない ので、正の無限大 を表す float("inf") を 全ての score_index 属性に最初に代入する ことでフレームが score_index 属性の値以上に 絶対にならなくなる ので、枝狩りされたノードの評価値 が 表示されることが無くなります。
下記は、そのように calc_score_by_ab を修正したプログラムです。
-
2、3 行目:ゲーム木のノードの一覧は、
nodelist属性に代入されているので、それを利用して全てのノードのscore_index属性を正の無限大で初期化する
1 def calc_score_by_ab(self, abroot, debug=False):
元と同じなので省略
2 for node in self.nodelist:
3 node.score_index = float("inf")
4 self.nodelist_by_score = []
5 calc_ab_score(abroot)
6 dprint(debug, "count =", self.count)
7
8 Mbtree.calc_score_by_ab = calc_score_by_ab
行番号のないプログラム
def calc_score_by_ab(self, abroot, debug=False):
self.count = 0
def calc_ab_score(node, alpha=float("-inf"), beta=float("inf")):
self.nodelist_by_score.append(node)
self.count += 1
if node.mb.status != Marubatsu.PLAYING:
self.calc_score_of_node(node)
else:
if node.mb.turn == Marubatsu.CIRCLE:
for childnode in node.children:
score = calc_ab_score(childnode, alpha, beta)
self.nodelist_by_score.append(node)
if score >= beta:
alpha = score
break
alpha = max(alpha, score)
node.score = alpha
else:
for childnode in node.children:
score = calc_ab_score(childnode, alpha, beta)
self.nodelist_by_score.append(node)
if score <= alpha:
beta = score
break
beta = min(beta, score)
node.score = beta
self.nodelist_by_score.append(node)
node.score_index = len(self.nodelist_by_score) - 1
return node.score
for node in self.nodelist:
node.score_index = float("inf")
self.nodelist_by_score = []
calc_ab_score(abroot)
dprint(debug, "count =", self.count)
Mbtree.calc_score_by_ab = calc_score_by_ab
修正箇所
def calc_score_by_ab(self, abroot, debug=False):
元と同じなので省略
+ for node in self.nodelist:
+ node.score_index = float("inf")
self.nodelist_by_score = []
calc_ab_score(abroot)
dprint(debug, "count =", self.count)
Mbtree.calc_score_by_ab = calc_score_by_ab
上記の修正後に、下記のプログラムで calc_score_by_ab で評価値を計算し直してから Mbtree_Anim を実行すると、実行結果のように 19 フレームのゲーム木の部分木の表示が、正しく行われるようになったことが確認できます。
mbtree.calc_score_by_ab(mbtree.root, debug=True)
Mbtree_Anim(mbtree, isscore=True)
実行結果
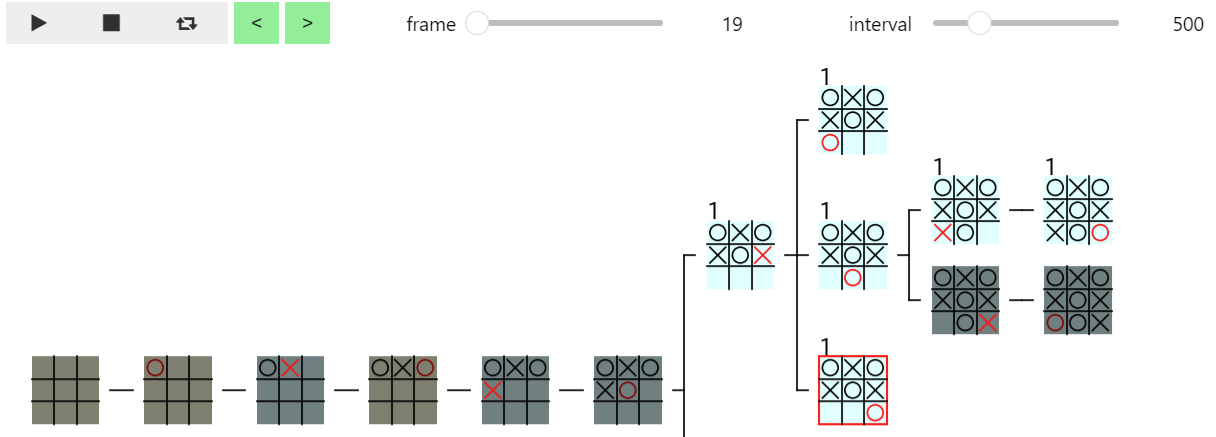
ルートノード以外のノードの αβ 法での計算手順の表示
calc_score_by_ab では、任意のノードに対して αβ 法で評価値を計算することができます。そこで、念のため ルートノード以外のノード の αβ 法での評価値の計算手順の表示が 正しく行われるか どうかを確認することにします。
下記のプログラムは、深さ 6 のノードの評価値 を αβ 法で計算しています。実行結果から 6 つのノードの評価値が計算 された結果、ノードの 評価値が 1 である ことがわかります。
mbtree.calc_score_by_ab(mbtree.nodelist_by_depth[6][0], debug=True)
print(mbtree.nodelist_by_depth[6][0].score)
実行結果
count = 6
1
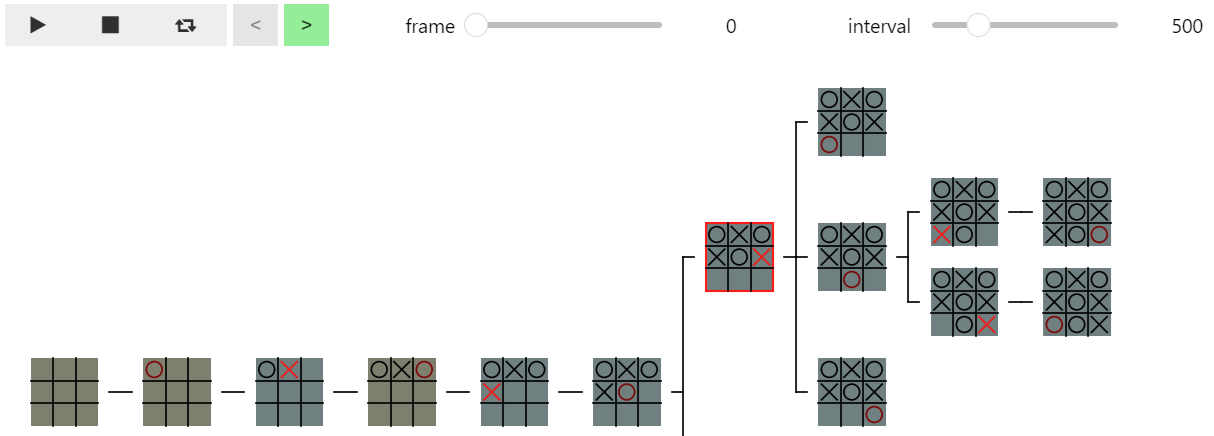
この mbtree に対して下記のプログラムで Mbtree_Anim で評価値の計算の手順を表示すると、実行結果のように 最初のフレーム では、深さ 6 のノードが赤枠で表示される ことが確認できます。
Mbtree_Anim(mbtree, isscore=True)
実行結果
また、途中経過のフレームは省略しますが、最後のフレーム は下図のように表示されます。

上図から、下記の事が確認でき、ルートノード以外のノードに対する αβ 法による評価値の計算手順が正しく表示されることが確認できます。
- 赤枠の αβ のルートノード の 評価値が 1 と計算 された
- 明るい色の 評価値が計算 された ノードの数は 6 である
- 赤枠の αβ の子孫ノードの中の 暗く表示される 2 つのノード は 枝狩り が行われて 計算されなかったノード である
下図は、上記の 0 ~ 16フレームまでのアニメーションの繰り返しです。

dprint をインポートする場所の修正
上記の calc_score_by_ab をそのまま mbtree.py に記述し、from ai import dprint を mbtree.py の先頭に記述 すると、循環インポート のエラーが発生することがわかりました。そこで、下記のプログラムの 2 行目のように from ai import dprint を calc_score_by_ab の中に記述して ローカルなインポート を行うようにすることで循環参照が発生しないように修正することにします。
1 def calc_score_by_ab(self, abroot, debug=False):
元と同じなので省略
2 from ai import dprint
3 for node in self.nodelist:
4 node.score_index = float("inf")
5 self.nodelist_by_score = []
6 calc_ab_score(abroot)
7 dprint(debug, "count =", self.count)
8
9 Mbtree.calc_score_by_ab = calc_score_by_ab
行番号のないプログラム
def calc_score_by_ab(self, abroot, debug=False):
self.count = 0
def calc_ab_score(node, alpha=float("-inf"), beta=float("inf")):
self.nodelist_by_score.append(node)
self.count += 1
if node.mb.status != Marubatsu.PLAYING:
self.calc_score_of_node(node)
else:
if node.mb.turn == Marubatsu.CIRCLE:
for childnode in node.children:
score = calc_ab_score(childnode, alpha, beta)
self.nodelist_by_score.append(node)
if score >= beta:
alpha = score
break
alpha = max(alpha, score)
node.score = alpha
else:
for childnode in node.children:
score = calc_ab_score(childnode, alpha, beta)
self.nodelist_by_score.append(node)
if score <= alpha:
beta = score
break
beta = min(beta, score)
node.score = beta
self.nodelist_by_score.append(node)
node.score_index = len(self.nodelist_by_score) - 1
return node.score
from ai import dprint
for node in self.nodelist:
node.score_index = float("inf")
self.nodelist_by_score = []
calc_ab_score(abroot)
dprint(debug, "count =", self.count)
Mbtree.calc_score_by_ab = calc_score_by_ab
修正箇所
def calc_score_by_ab(self, abroot, debug=False):
元と同じなので省略
+ from ai import dprint
for node in self.nodelist:
node.score_index = float("inf")
self.nodelist_by_score = []
calc_ab_score(abroot)
dprint(debug, "count =", self.count)
Mbtree.calc_score_by_ab = calc_score_by_ab
今回の記事のまとめ
今回の記事では、αβ 法 での 評価値の計算の手順を表示 するために Mbtree クラスに calc_score_by_ab メソッドを定義しました。また、calc_score_by_ab によって計算されたゲーム木のデータを Mbtree_Anim クラスで表示 する事で、αβ 法での評価値の計算の手順の アニメーションが正しく表示される ことが確認できました。
ただし、現状での Mbtree_Anim での αβ 法の計算の手順の表示には いくつかわかりづらい 点があるので、次回の記事で 改良する ことにします。どのように改良すればよいかについて考えてみて下さい。
本記事で入力したプログラム
| リンク | 説明 |
|---|---|
| marubatsu.ipynb | 本記事で入力して実行した JupyterLab のファイル |
| tree.py | 本記事で更新した tree_new.py |
次回の記事
-
α 狩りと β 狩りによる枝狩りが行われる場合があるので、全ての子孫ノードの評価値の計算が行われるとは限りません ↩
-
ミニマックス法の場合も同様の性質を持ちます ↩
-
最大の評価値 と 最小の評価値 は αβ 法では計算しない ので、今回の記事では 以後は言及しません ↩
-
評価値を計算する関数として
ai_by_absを参考にしたいので、@ai_by_scoreのデコレータ式は記述していません ↩ -
nodeではなくabrootという名前にしたのは、calc_score_by_abの中で定義するローカル関数calc_ab_scoreの仮引数nodeと区別できるようにするためです。calc_score_by_abとcalc_ab_scoreの両方に同じnodeという名前の仮引数を定義しても、両者は異なる名前空間で管理されるため、異なる仮引数として区別されるのでプログラムは正しく動作します。ただし、そのように仮引数の名前を定義すると、両者が同じ仮引数であると混同されてしまう可能性が高いので、異なる名前にしました ↩