概要

会社で開催されるクリスマスパーティーで何かおもろいことやろうぜ、ってことで有志で作った物についてのメモです。
データ分析の会社ということで、何かデータを貯めてごにょごにょするそれっぽいもの&有志メンバーにインタラクティブアート的なものが好きな人が多かったので何かそれっぽいものを目指そうぜというモチベーションでした。
で、結局作ったものはRaspberryPi3+OpenCVでクリスマスツリーに自動セルフィー(自撮り)機能を付ける、というものです。
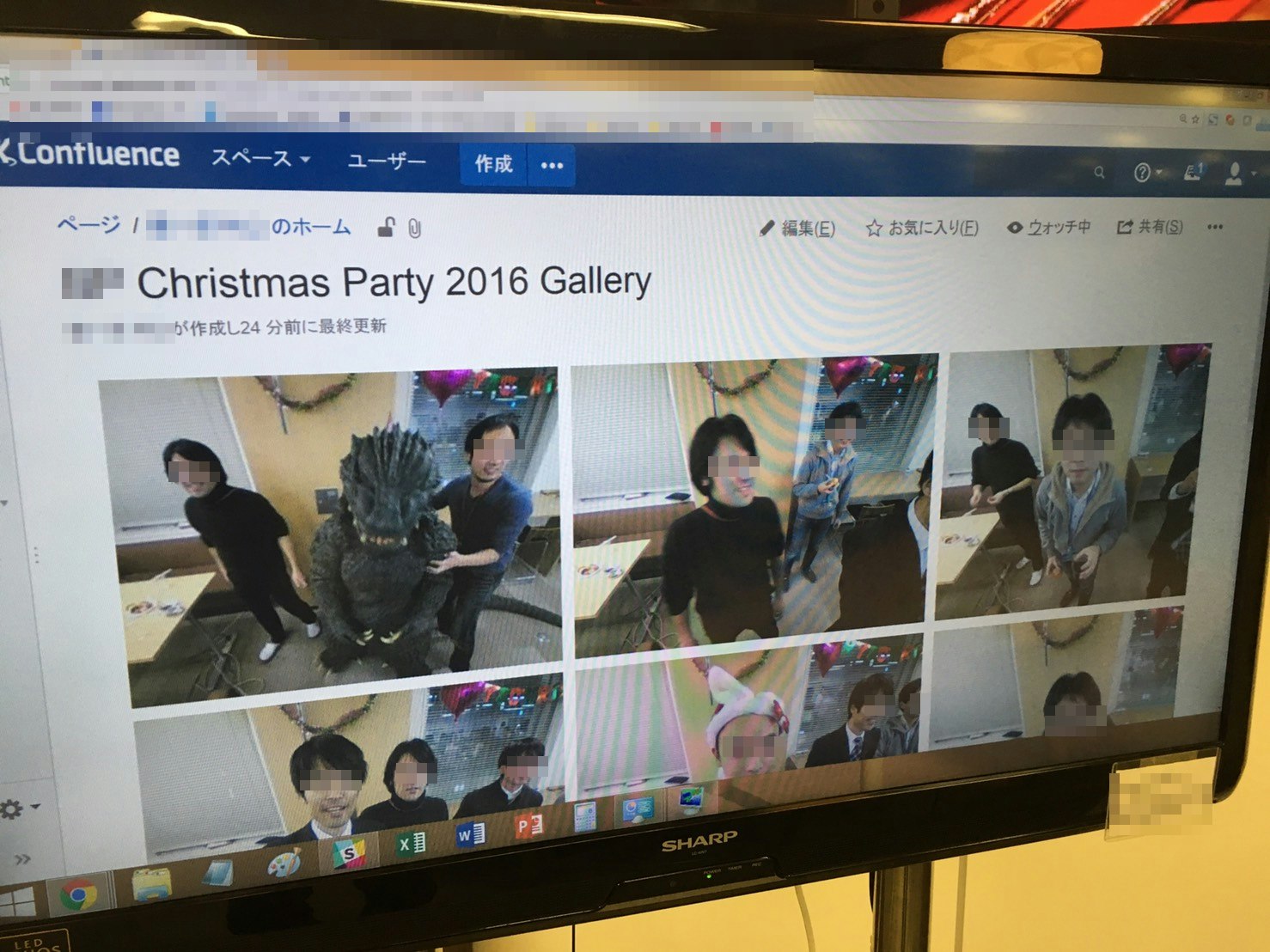
ツリーの前に立つとリアルタイムで顔検出を行って自動で撮影し、撮影した画像を社内SNS(今回はConfluence)に投稿して自動でアルバムを作成していきます(カメラ映像は隣に置いたディスプレイに表示しています)。見た目はツリーのお星様におもむろにカメラが載せただけの雑なものです。
コンセプトは、
お前がクリスマスツリーを眺める時、ツリーもまたお前を眺めているのだ - ニーチェっぽい誰か
モノとしては非常にシンプルですが、パーティーに参加中のほろ酔いな方々にはなかなかウケた印象です。ほろ酔いで楽しそうな記念写真が社内SNSにアルバムとして記録されて良い思い出になったのではないでしょうか。



ちなみにリアルタイム顔検出の様子はこちらです
使用した道具など
-
Raspberry Pi
- 3を使いました。外付けのwebカメラの電源もラズパイから供給するため、使用電力量もupした3を使っとけば安定的に起動するだろうという魂胆です。2でも普通に動くかもしれません(未確認)。
-
webカメラ
-
顔検出の特徴量
- OpenCVにデフォルトで入っている
haarcascade_frontalface_defaultを使いました(通常はOpenCVをインストールした時に、OpenCV下のディレクトリに格納されているのでそこのパスを指定します)
- OpenCVにデフォルトで入っている
スクリプト
RaspberryPi3で実行したスクリプトです(GitHubにも同内容のスクリプトあり)
# -*- coding: utf-8 -*-
import cv2
import sys
import logging as log
import datetime as dt
import time
from time import sleep
import subprocess
# RaspberryPi用GPIOピン制御のモジュール
import RPi.GPIO as GPIO
GPIO.setmode(GPIO.BOARD)
GPIO.setup(11,GPIO.OUT)
# 顔検出に使う特徴量ファイルの指定
cascPath = '/home/pi/face_detect/haarcascade_frontalface_default.xml'
faceCascade = cv2.CascadeClassifier(cascPath)
# ログの出力
log.basicConfig(filename='webcam.log',level=log.INFO)
# もろもろ初期化
video_capture = cv2.VideoCapture(0)
anterior = 0
shot_dense = 0.5
considerable_frames = 20
prev_faces = []
prev_shot = None
while True:
# 動画の読み込みに失敗した場合
if not video_capture.isOpened():
print('Unable to load camera.')
sleep(5)
pass
# 動画の読み込みに成功した場合
# 読み込んだ動画を1フレームづつ読み込む
ret, org_frame = video_capture.read()
shape = org_frame.shape
# 画像サイズを小さくするための割合を設定(後述:詳細1)
ratio = 3
# 処理高速化のために画像サイズを小さくする(後述:詳細1)
frame = cv2.resize(org_frame, (shape[1]/ratio,shape[0]/ratio))
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 顔の検出
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.1,
minNeighbors=5,
#画像サイズの小さくしたので走査するwindowも同様の割合で小さくする(後述:詳細1)
minSize=(30/ratio, 30/ratio)
)
print prev_faces, prev_shot
# 顔が検出されるたびに連続で撮影されないための工夫(後述:詳細2)
# prev_shot is None -> 初回のデータ格納 seconds>3 -> 顔検出不感タイムの指定(2週目以降の処理)
if prev_shot is None or (dt.datetime.now() - prev_shot).seconds > 3:
prev_faces.append(len(faces))
if len(prev_faces) > considerable_frames:
drops = len(prev_faces) - considerable_frames
# prev_facesのリストの先頭からdrops分だけ要素を削除したlistを返す(20を超えた要素で古いものから削除していく)
# prev_facesは常に20の要素数を保つ
prev_faces = prev_faces[drops:]
# その20の要素数のうち、0以上の数が全要素数(=20)のどれくらいの割合を占めるかチェック
dense = sum([1 for i in prev_faces if i > 0]) / float(len(prev_faces))
# prev_facesに20よりも多くの要素が格納されようとしたとき
if len(prev_faces) >= considerable_frames and dense >= shot_dense:
print 'shot',str(dt.datetime.now())
save_fig_name = '/home/pi/face_detect/save_fig/{}.jpg'.format(dt.datetime.now())
cv2.imwrite(save_fig_name,org_frame)
# システムコマンドでConfluence APIを叩いて指定のページに保存した画像を投稿する(後述:詳細3)
curl_cmd = "curl -D- -u ユーザ名:ドメイン名# -X POST -H \"X-Atlassian-Token: nocheck\" -F \"file=@{0}\"\ \"https://ドメイン.atlassian.net/wiki/rest/api/content/コンテンツID/child/attachment\"".format(save_fig_name)
subprocess.call(curl_cmd,shell=True)
# 画像がAPIに渡されたら目印としてラズパイにくっつけたLEDを明滅させる(後述:詳細4)
# ここでは適当に3回分明滅させる
n = 0
while n <3:
GPIO.output(11,True)
time.sleep(0.3)
GPIO.output(11,False)
time.sleep(0.3)
n += 1
prev_faces = []
prev_shot = dt.datetime.now()
# 顔検出領域を四角で囲む
for (x, y, w, h) in faces:
x_ = x*ratio
y_ = y*ratio
x_w_ = (x+w)*ratio
y_h_ = (y+h)*ratio
cv2.rectangle(org_frame, (x_, y_), (x_w_, y_h_), (0, 255, 0), 2)
# 'q'を押したら検出処理を終える
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 接続しているモニターにリアルタイムで画像を描写する(カメラで撮っている動画を表示する)
cv2.imshow('Video', org_frame)
# 全てが完了したらプロセスを終了
video_capture.release()
cv2.destroyAllWindows()
スクリプト詳細
1. openCVを非力なマシンでも動かす工夫
RaspberryPi3はマイコンのわりにはパワーがあるのですが、OpenCVでリアルタイムに(フレームごとに)顔検出し続けるとさすがに処理が重いらしく動画がカクカクしてきます。
そこで、以下の様に実際に処理する画像は縦横の画像サイズを1/3にしています
shape= org_frame.shape
# 画像サイズを小さくするための割合を設定
ratio = 3
# 処理高速化のために画像サイズを小さくする(後述)
frame = cv2.resize(org_frame, (shape[1]/ratio,shape[0]/ratio))
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
1/3というのは適当な数字ですが、これ以上サイズを大きくすると処理が重くなり、小さくするとディスプレイでリアルタイムに表示する画像が小さすぎて見えないという感じだったので1/3にしました。1/3だとギリギリストレス無く動画の描写が行えます。
2. 撮影するタイミングをちょうどいい感じにする
このカメラでは、顔が検出された瞬間の画像を撮影し保存しているのではなく、一定時間内に一定の頻度で顔が検出され続ければ撮影するようにしています。(そうしないとカメラエリア内に入った瞬間に撮影されてしまうor顔以外のものが誤検出されたときも撮影され続けてしまう)
considerable_frame = 20というところで、要素が20個入る配列を想定します。
この配列には、1フレームごとに顔が検出されれば1が、検出されなければ0の要素が格納されます。
この配列は直近の20フレーム分が考慮されていて、フレームが進むごとに20を超えた要素で、時間的に古い要素が削除されていく、というイメージです。
そして直近の20個の要素(20フレーム)のうち、半分の要素が1であれば(dense=0.5)その段階で初めてそのフレームの画像を保存する、という仕組みです。
撮影タイミングをこのようにすることでカメラを見続けてキメ顔を作る時間ができるという感じです。
3. API経由で外部SNSへ自動投稿する
社内のクローズドSNSにConfluenceが使われているため、今回は撮影した画像を指定したConfluenceページに自動投稿して蓄積していくスタイルにしました。(Confluence APIについてはこちら)
APIを叩くcurlコマンドをPythonのsubprocessモジュールから呼び出して実行しているだけです。
# APIを叩いて指定のConfluenceページに、保存した画像を投稿する
curl_cmd = "curl -D- -u ユーザ名:ドメイン名# -X POST -H \"X-Atlassian-Token: nocheck\" -F \"file=@{0}\"\ \"https://ドメイン.atlassian.net/wiki/rest/api/content/コンテンツID/child/attachment\"".format(save_fig_name)
subprocess.call(curl_cmd,shell=True)
Confluenceのページ側では、"Gallary"という、投稿された画像を指定した行・列だけ整列して表示してくれるプラグインを使用しました。
ブラウザー側では、chromeのプラグインを使い3秒に一回画面更新を行って、撮影した写真がリアルタイムで正しく投稿されているか確認できるようにしていました。
ここで叩くAPIをTwitterなどにすればセルフィー画像がツイートされつづけるようにも出来ます。
4. 撮影したタイミングをLチカで明示的に知らせる
# 撮影して、画像がAPIに渡されたら目印としてLEDを明滅させる
# ここでは適当に3回分明滅させる
n = 0
while n <3:
GPIO.output(11,True)
time.sleep(0.3)
GPIO.output(11,False)
time.sleep(0.3)
n += 1
という箇所です。
0.3秒間LEDを光らせて0.3秒間消します。それを3ループさせることで明滅させています。
RaspberryPiはGPIOモジュールをimportするだけで、本体に接続したLEDやセンサー類の入出力を簡単にコードに組み込めるところが秀逸です
問題点としては、このループで0.3秒とはいえsleepを入れてしまうので、ディスプレイに描写する動画が一瞬固まってしまう点です。
例えば1秒間sleepだと体感的には完全にフリーズしたように見えてしまうので、0.3秒まで削ってみました。これでも撮影の瞬間に一瞬だけ画面が固まったように見えますがギリギリ許容できるレベルだと思います。
実際にクリスマスパーティー会場に設置してみての反省点としては、酔っぱらい&明るい会場ではLEDのほのかな光は確認しにくいということ。LEDをフラッシュさせるのではなく、ブザーなどで音を出したほうが撮影したタイミングが分かりやすかったかもしれません。
問題(面倒だった)点
ssh/VPN接続して開発出来ない問題
普段はMacからラズパイにssh/VPN接続してコードなど書くのですが、自分がやったときはカメラが取得している動画を表示するウィンドウがVPN接続経由では開けず苦戦しました。同じ問題に会った方々のブログ曰く、X11VNCやtightvncserverをつかってVPN接続すれば良いよとのことですがうまく解決できず...。しかたなく毎回ラズパイにモニター/キーボード/マウスにつないでコーディング作業を行いました。誰が解決方法教えてください。
まとめ
-
ほろ酔いの人にとって「顔検出」というおもちゃはなかなか楽しいらしい
- 「なんでお前の顔ばっかり検出されておれの顔は検出されないんだ!!!」みたいな感じで賑やかでした
-
比較的お手軽に作れて、社内SNSにアルバムが出来たのが良い
- Raspberry Piを触ったことある人なら比較的簡単に作れると思います。3時間ほどずっと稼働しっぱなしでしたが一度も誤作動すること無く仕事してくれました。ラズパイ偉い。
- 撮った写真が全員が見れる場所に形として残るのがやはり良かったです(酔っぱらいの勢いで変顔で撮っちゃってもご愛嬌)
-
もうちょっと綺麗に作りたかった&工夫したかった
- カメラもラズパイもモロ見えでしたし。。。本当はこんな感じにキレイな見た目で、そして撮影した画像に何か処理する(フィルタをかける)感じにしたかったです。
ソースコード
以下のリポジトリからソースコードをダウンロードできます。