この問題は修正されました。
v4.7.0.0 にて「台本ファイル読み込み時、カスタムボイスの字幕が読み込まれない問題を修正」が行われたため
必要なくなりました!やったね!!
便利なゆっくりMovieMaker4のちょっとした「落とし穴」
動画を作るのに、ゆっくりMovieMaker4の台本機能を使わせてもらってるのですが。
ちょっとした不便が生じるようになってしまいました。
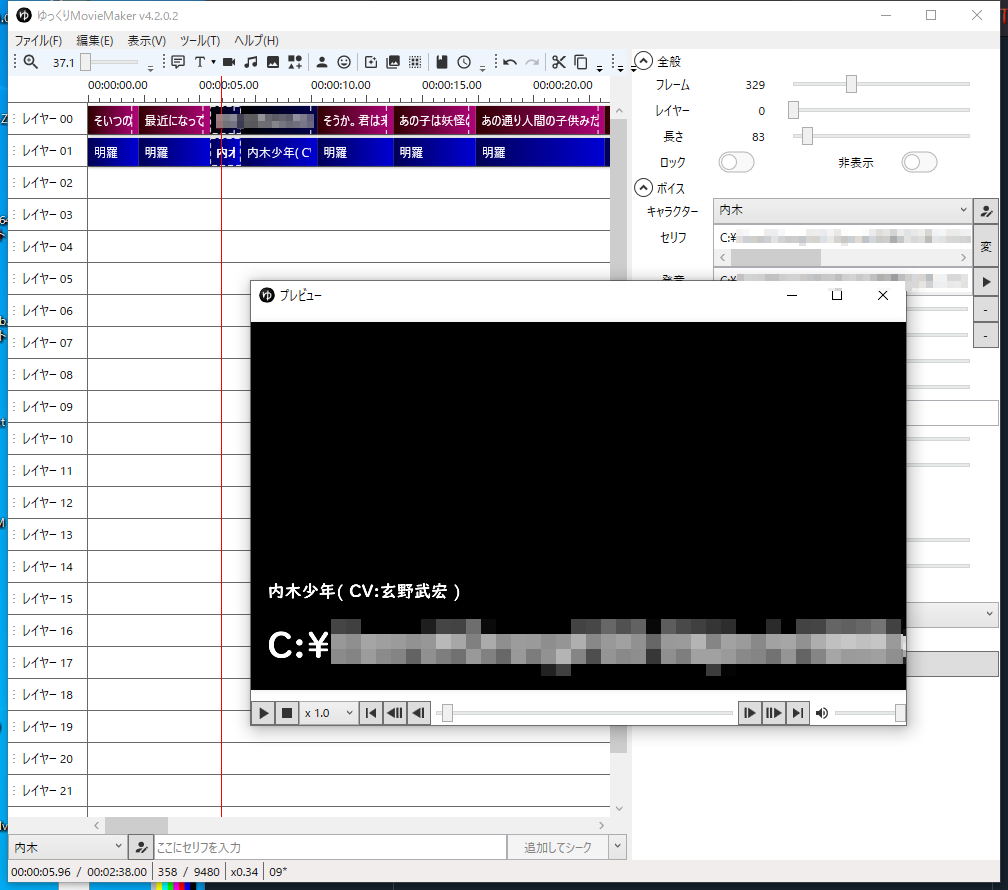
音声付属のセリフテキストを読み込んでくれない...
例えばこういう状況の時...
example ┳ Voice ┳ hoge.wav
┃ ┗ hoge.txt
┗ hoge.csv
ほげに効く薬
hoge,./example/Voice/hoge.wav
今まで台本機能からhoge.csvを読み込みタイムラインに追加すると
音声ファイルのパス(./example/Voice/hoge.wav)を検出
↓
./example/Voice/hoge.txt の有無を確認( 無ければパス名を表示 )
↓
./example/Voice/hoge.txt から、テキストデータ「ほげに効く薬」を取得。
↓
「ほげに効く薬」をセリフとして設定( 発音欄は ./example/Voice/hoge.wav のままで音声を読み込む )
という処理が行われていたのですが。
この機能そのものがなくなったか、あるいは不具合なのか、
パスをそのままセリフ欄に表示するようになってしまいました。
ゆっくりMovieMakerプロジェクトファイル(.ymmp)を弄って不具合を解消する。
そこでPythonコードを使い、この処理の代用を行う仕組みを考えました。
台本をタイムラインに読み込んだ状態で.ymmpファイルを出力しておき。
この.ymmpファイルに手を加えます。
標準のpythonモジュールの他に chardet urllib3 のモジュールが必要なので、
pythonコードを使う前にインストールしておいてください。
-m pip install chardet
-m pip install urllib3
import re
import os
from chardet import detect
import urllib
fromPath = "C://xxx/???.ymmp" #ここに「変換したいファイルの絶対パス」を入力する。
toPath = "./result.ymmp" #ここに「出力先ファイル」の 絶対パス|相対パス を入力する
NG = {
"enc":[ #誤判定しそうなエンコードを置き換える
[
["MacCyrillic","Windows-1252"]
],
[
"Shift_JIS"
]
]
}
#################################################################
#################################################################
fp = open(fromPath,mode="r",encoding='utf_8_sig')
data = fp.read()
fp.close()
Serif = re.findall(r'"Serif": ".*.wav"',data)
Hatsuon = re.findall(r'"Hatsuon": ".*.wav"',data)
for i in Serif:
tamp = i.replace('"Serif": ','"Hatsuon": ')
if tamp in Hatsuon:
m = re.search(r'[^"][A-Z:].*.wav',tamp)
path = m.group()
t_path = path.replace(".wav",".txt")
if os.path.isfile(t_path):
text = False
with open(t_path,mode="rb") as fp:
e = fp.read()
enc = detect(e)
if(enc['encoding'] in NG["enc"][0][0]):
enc['encoding'] = NG["enc"][1][0]
with open(t_path,mode="r",encoding=enc['encoding']) as fp:
text = fp.read()
if text != False:
text = text.strip()
text = i.replace(path,text)
data = data.replace(i,text)
print(text,enc)
fp = open(toPath,mode="w",encoding='utf_8_sig')
fp.write(data)
fp.close()
セリフ欄と発音欄が同じ「音声ファイルパス(.wav)」である場合に、同じディレクトリの同じ名前の.txtを読み込んでセリフ欄に適用します。
音声合成サービス毎にテキストファイルの文字エンコードが異なるため。
エンコードを確認してから、再度、テキストを読み込んでいます。