はじめに
Google I/O 2025 で発表されていたものの 1つ、Gemini API を使った音声合成(TTS)を試してみます。
●音声生成(テキスト読み上げ) | Gemini API | Google AI for Developers
https://ai.google.dev/gemini-api/docs/speech-generation?hl=ja#javascript
直近で試したこと: Google I/O 2025関連
Google I/O 2025 で発表されていたものは、直近で他にも試しています。具体的には以下になりますが、今回もそれらと同様 Node.js を使って試します。
●Gemini API & SDK が MCP 対応したので試す(Node.js を利用)【Google I/O 2025】 - Qiita
https://qiita.com/youtoy/items/fd1b123c3f7fc3516264
●【Google I/O 2025】 API の無料枠で Gemini・Gemma の新モデルを試す(Node.js を利用) - Qiita
https://qiita.com/youtoy/items/714a1bd58a80f856663c
あと、まだ記事にはできてないですが、以下の音楽生成も Node.js で試しました。
サクッと試す
それでは実際に試していきます。
下準備
下準備として、パッケージのインストールと APIキーの設定を行います。
パッケージのインストール
公式ドキュメントの最初のサンプルを見てみたところ、以下 2つのパッケージを使うようです。
●wav - npm
https://www.npmjs.com/package/wav
●@google/genai - npm
https://www.npmjs.com/package/@google/genai
これらを以下のコマンドでインストールします。
npm i @google/genai wav
APIキーの設定
次に APIキーの設定です。環境変数 GEMINI_API_KEY に Gemini の APIキーをセットしておきます。
コードと処理の実行
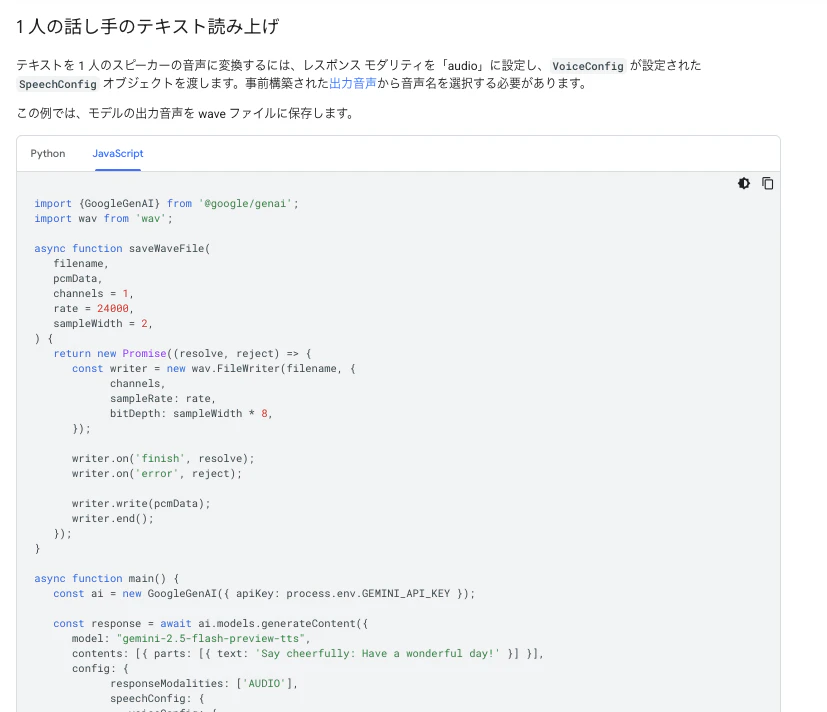
公式ドキュメントに掲載されている、以下のコードを試してみます。
import { GoogleGenAI } from "@google/genai";
import wav from "wav";
async function saveWaveFile(
filename,
pcmData,
channels = 1,
rate = 24000,
sampleWidth = 2
) {
return new Promise((resolve, reject) => {
const writer = new wav.FileWriter(filename, {
channels,
sampleRate: rate,
bitDepth: sampleWidth * 8,
});
writer.on("finish", resolve);
writer.on("error", reject);
writer.write(pcmData);
writer.end();
});
}
async function main() {
const ai = new GoogleGenAI({ apiKey: process.env.GEMINI_API_KEY });
const response = await ai.models.generateContent({
model: "gemini-2.5-flash-preview-tts",
contents: [{ parts: [{ text: "Say cheerfully: Have a wonderful day!" }] }],
config: {
responseModalities: ["AUDIO"],
speechConfig: {
voiceConfig: {
prebuiltVoiceConfig: { voiceName: "Kore" },
},
},
},
});
const data = response.candidates?.[0]?.content?.parts?.[0]?.inlineData?.data;
const audioBuffer = Buffer.from(data, "base64");
const fileName = "out.wav";
await saveWaveFile(fileName, audioBuffer);
}
await main();
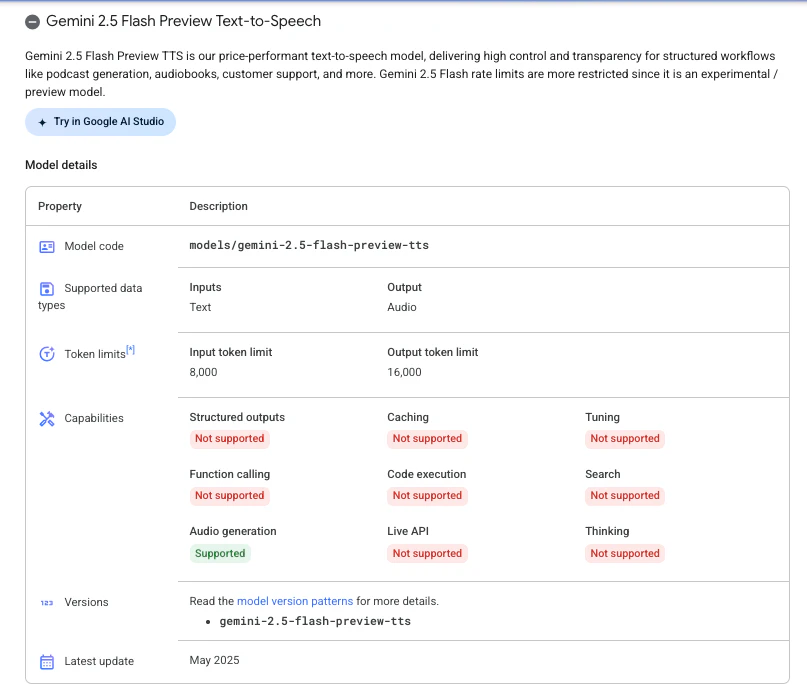
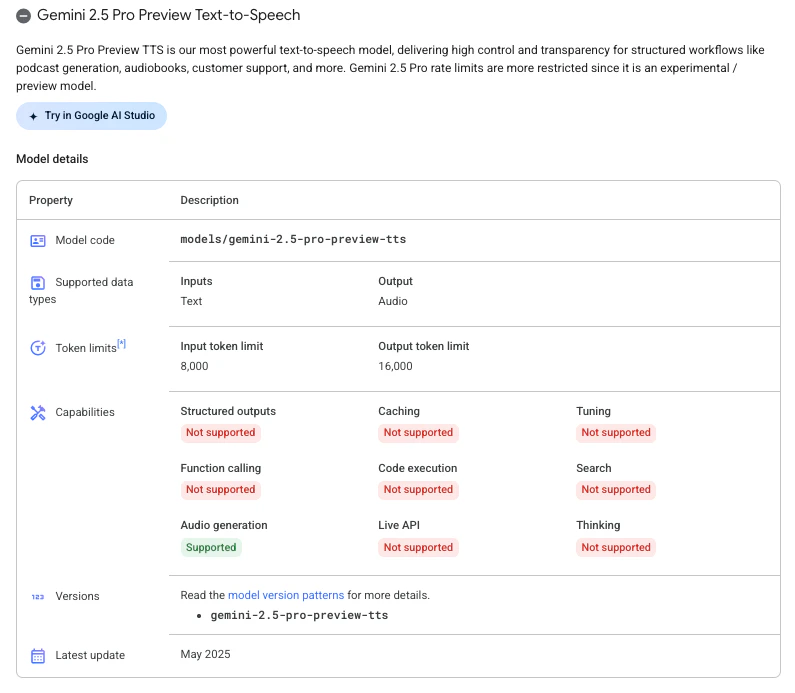
音声合成用のモデル
モデルは「gemini-2.5-flash-preview-tts」が使われています。ちなみに、もう 1つ「gemini-2.5-pro-preview-tts」というモデルも使えるようです。
処理結果
上記を実行してみたところ、「out.wav」というファイルが生成されました。それを再生すると「Have a wonderful day!」という明るい声を聞くことができました。
2つ目のお試し
別のサンプル(複数のスピーカーによるテキスト読み上げ)を少し書きかえて試してみます。
下準備(パッケージのインストールと APIキーの設定)は、先ほどと同じです。
声の種類
この後試す音声合成の声の種類を、公式サンプルで使われているもの(voiceName:「Kore」「Puck」)とは別のものに変えてみることにします。
その部分を変える際の候補の参照先として、公式ドキュメント上に書かれている声の種類を見てみます。また、それと重複しますが、Google AI Studio上で選べる声の種類の一部を、以下に合わせて掲載してみます。
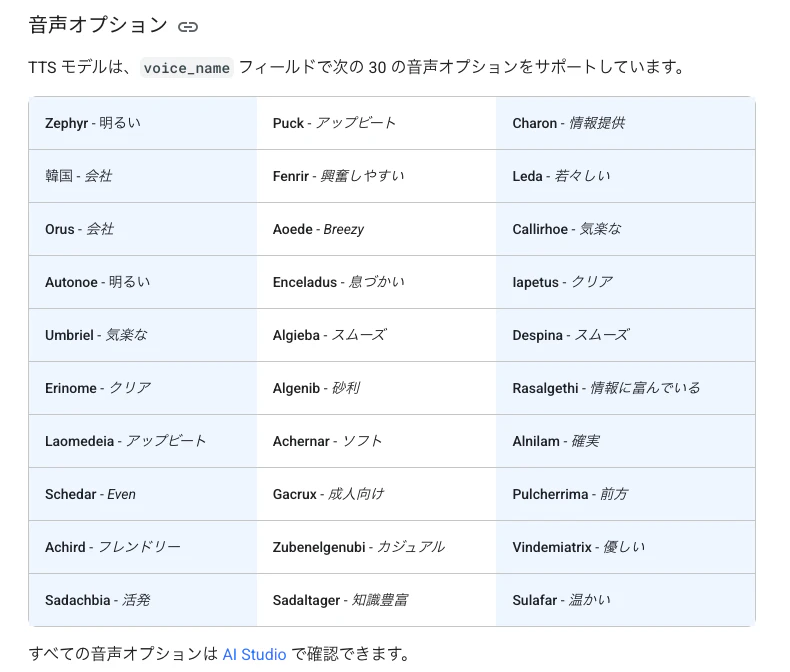
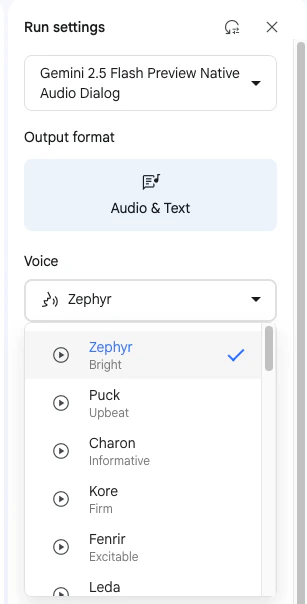
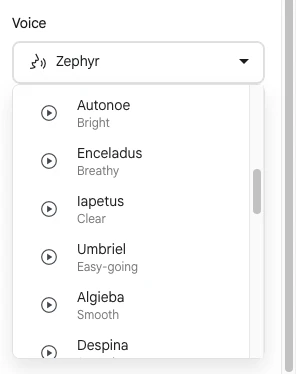
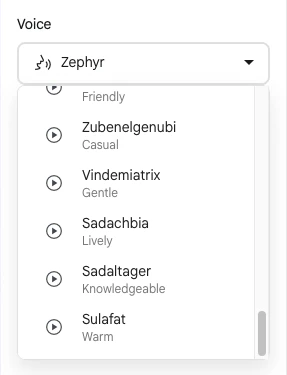
この中から 2種類の声を選ぶことにします。
プロンプトでの音声スタイルを制御
プロンプトでの音声スタイルを制御についても、情報を見てみます。
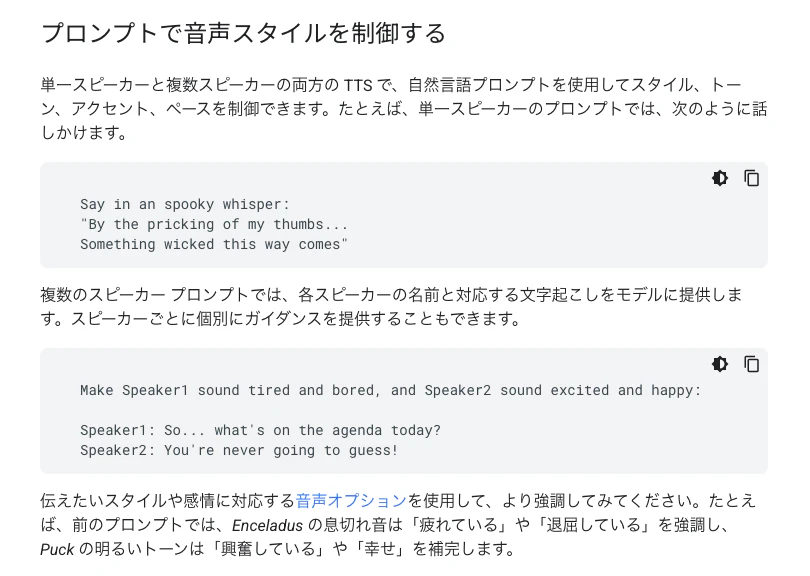
これもこの後に使ってみます。
コード
試すコードは以下のとおりです。
声の種類、しゃべる内容を変えていて、さらに音声スタイルを制御するプロンプトを加えています。
import { GoogleGenAI } from "@google/genai";
import wav from "wav";
async function saveWaveFile(
filename,
pcmData,
channels = 1,
rate = 24000,
sampleWidth = 2
) {
return new Promise((resolve, reject) => {
const writer = new wav.FileWriter(filename, {
channels,
sampleRate: rate,
bitDepth: sampleWidth * 8,
});
writer.on("finish", resolve);
writer.on("error", reject);
writer.write(pcmData);
writer.end();
});
}
async function main() {
const ai = new GoogleGenAI({ apiKey: process.env.GEMINI_API_KEY });
const prompt = `話し声がすごくゆっくりなスピーカー1と、退屈そうで声が小さいスピーカー2の、2人の会話の音声合成を行ってください:
スピーカー1: 今日は良い天気ですね。元気にしてますか?
スピーカー2: 悪くはないかな。あなたこそどうですか?`;
const response = await ai.models.generateContent({
model: "gemini-2.5-flash-preview-tts",
contents: [{ parts: [{ text: prompt }] }],
config: {
responseModalities: ["AUDIO"],
speechConfig: {
multiSpeakerVoiceConfig: {
speakerVoiceConfigs: [
{
speaker: "スピーカー1",
voiceConfig: {
prebuiltVoiceConfig: { voiceName: "Autonoe" },
},
},
{
speaker: "スピーカー2",
voiceConfig: {
prebuiltVoiceConfig: { voiceName: "Umbriel" },
},
},
],
},
},
},
});
const data = response.candidates?.[0]?.content?.parts?.[0]?.inlineData?.data;
const audioBuffer = Buffer.from(data, "base64");
const fileName = "out02.wav";
await saveWaveFile(fileName, audioBuffer);
}
await main();
wavファイルを生成して再生
上記を実行して wavファイルを生成し、それを再生します。wavファイルを再生している時の音を、キャプチャして動画にしてみました。
こんな感じの合成された音声を得ることができました。
【追記】 別サンプルでのお試し
記事を公開した後、Google AI Studio で別のサンプルが出てきたので、それも試してみました。具体的には、以下の部分をクリックすると表示されるサンプルです。
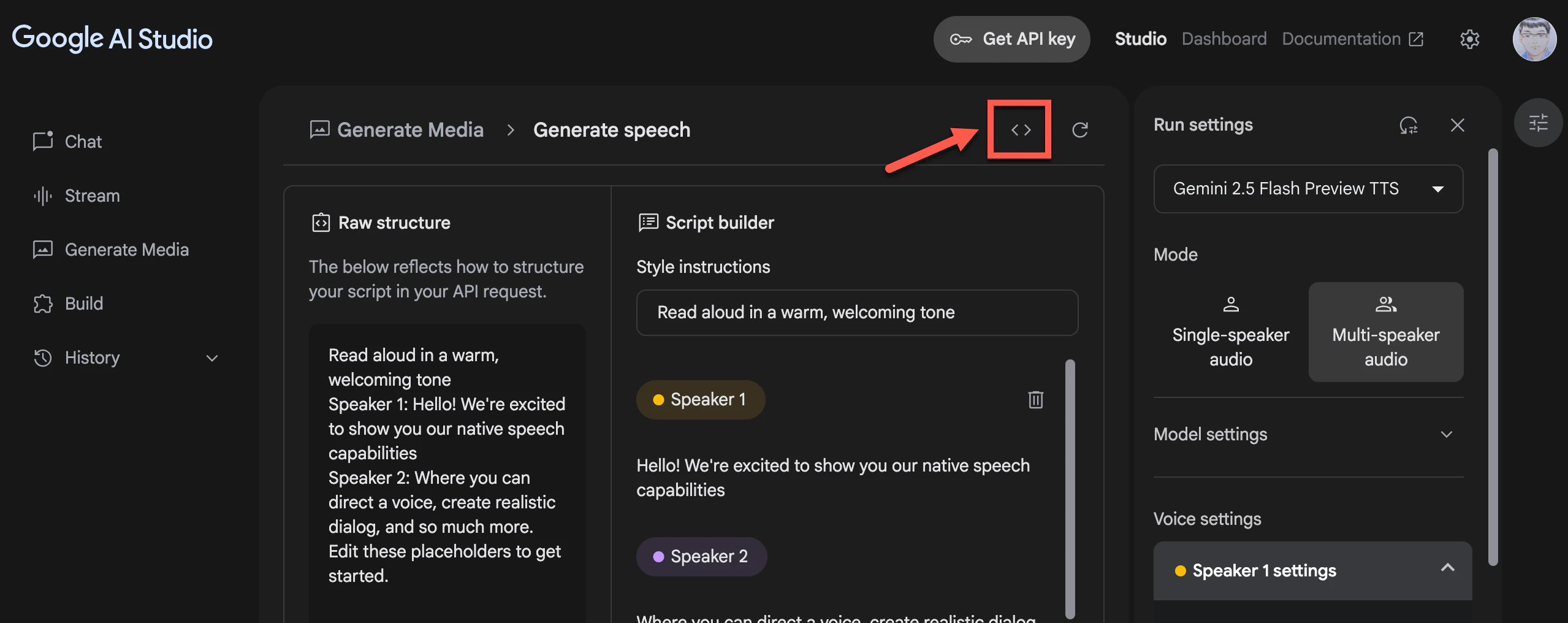
選べる言語などは、以下となっています。
下準備
この後のコードを実行する前の下準備についてふれておきます。
以下はパッケージのインストールです。
npm i @google/genai mime
あとは APIキーの設定です。環境変数 GEMINI_API_KEY に Gemini の APIキーをセットしておきます。
実装したコード: JavaScript
実装したコードは以下で、TypeScript のサンプルコードを JavaScript に変更しています。
import { GoogleGenAI } from "@google/genai";
import mime from "mime";
import { writeFile } from "fs";
function saveBinaryFile(fileName, content) {
writeFile(fileName, content, "utf8", (err) => {
if (err) {
console.error(`Error writing file ${fileName}:`, err);
return;
}
console.log(`File ${fileName} saved to file system.`);
});
}
async function main() {
const ai = new GoogleGenAI({
apiKey: process.env.GEMINI_API_KEY,
});
const config = {
temperature: 1,
responseModalities: ["audio"],
multiSpeakerVoiceConfig: {
speakerVoiceConfigs: [
{
speaker: "Speaker 1",
voiceConfig: { prebuiltVoiceConfig: { voiceName: "Zephyr" } },
},
{
speaker: "Speaker 2",
voiceConfig: { prebuiltVoiceConfig: { voiceName: "Puck" } },
},
],
},
};
const model = "gemini-2.5-flash-preview-tts";
const contents = [
{
role: "user",
parts: [
{
text: `Read aloud in a warm, welcoming tone
Speaker 1: Hello! We're excited to show you our native speech capabilities
Speaker 2: Where you can direct a voice, create realistic dialog, and so much more. Edit these placeholders to get started.`,
},
],
},
];
const response = await ai.models.generateContentStream({
model,
config,
contents,
});
for await (const chunk of response) {
const cand = chunk.candidates?.[0]?.content;
if (!cand?.parts) continue;
const part = cand.parts[0];
if (part.inlineData) {
const fileName = "test";
const { mimeType, data } = part.inlineData;
let fileExtension = mime.getExtension(mimeType || "");
let buffer = Buffer.from(data || "", "base64");
if (!fileExtension) {
fileExtension = "wav";
buffer = convertToWav(data || "", mimeType || "");
}
saveBinaryFile(`${fileName}.${fileExtension}`, buffer);
} else if (chunk.text) {
console.log(chunk.text);
}
}
}
main();
function convertToWav(rawData, mimeType) {
const options = parseMimeType(mimeType);
const wavHeader = createWavHeader(rawData.length, options);
const audioBuffer = Buffer.from(rawData, "base64");
return Buffer.concat([wavHeader, audioBuffer]);
}
function parseMimeType(mimeType) {
const [fileType, ...params] = mimeType.split(";").map((s) => s.trim());
const [, format] = fileType.split("/");
const options = { numChannels: 1 };
if (format && format.startsWith("L")) {
const bits = parseInt(format.slice(1), 10);
if (!isNaN(bits)) options.bitsPerSample = bits;
}
for (const param of params) {
const [key, value] = param.split("=").map((s) => s.trim());
if (key === "rate") options.sampleRate = parseInt(value, 10);
}
return options;
}
function createWavHeader(dataLength, options) {
const { numChannels, sampleRate, bitsPerSample } = options;
const byteRate = (sampleRate * numChannels * bitsPerSample) / 8;
const blockAlign = (numChannels * bitsPerSample) / 8;
const buffer = Buffer.alloc(44);
buffer.write("RIFF", 0);
buffer.writeUInt32LE(36 + dataLength, 4);
buffer.write("WAVE", 8);
buffer.write("fmt ", 12);
buffer.writeUInt32LE(16, 16);
buffer.writeUInt16LE(1, 20);
buffer.writeUInt16LE(numChannels, 22);
buffer.writeUInt32LE(sampleRate, 24);
buffer.writeUInt32LE(byteRate, 28);
buffer.writeUInt16LE(blockAlign, 32);
buffer.writeUInt16LE(bitsPerSample, 34);
buffer.write("data", 36);
buffer.writeUInt32LE(dataLength, 40);
return buffer;
}
これを実行して、合成された音声の wavファイルが生成されたのを確認できました。
curl を使ったサンプル
ちなみに、先ほどの選択肢で REST を選んだ場合、以下の内容が提示されました。
#!/bin/bash
set -e -E
GEMINI_API_KEY="$GEMINI_API_KEY"
MODEL_ID="gemini-2.5-flash-preview-tts"
GENERATE_CONTENT_API="streamGenerateContent"
cat << EOF > request.json
{
"contents": [
{
"role": "user",
"parts": [
{
"text": "Read aloud in a warm, welcoming tone\nSpeaker 1: Hello! We're excited to show you our native speech capabilities\nSpeaker 2: Where you can direct a voice, create realistic dialog, and so much more. Edit these placeholders to get started."
},
]
},
],
"generationConfig": {
"responseModalities": ["audio", ],
"temperature": 1,
"speech_config": {
"multi_speaker_voice_config": {
"speaker_voice_configs": [
{
"speaker": "Speaker 1",
"voice_config": {
"prebuilt_voice_config": {
"voice_name": "Zephyr"
}
}
},
{
"speaker": "Speaker 2",
"voice_config": {
"prebuilt_voice_config": {
"voice_name": "Puck"
}
}
},
]
},
},
},
}
EOF
curl \
-X POST \
-H "Content-Type: application/json" \
"https://generativelanguage.googleapis.com/v1beta/models/${MODEL_ID}:${GENERATE_CONTENT_API}?key=${GEMINI_API_KEY}" -d '@request.json'