研究室GPUサーバー利用時の備忘録
研究室のGPUサーバーを利用する際の接続, 監視, トラブルシューティング, データ管理に関するメモである.
以下の図が研究室で利用している環境を表したものである.
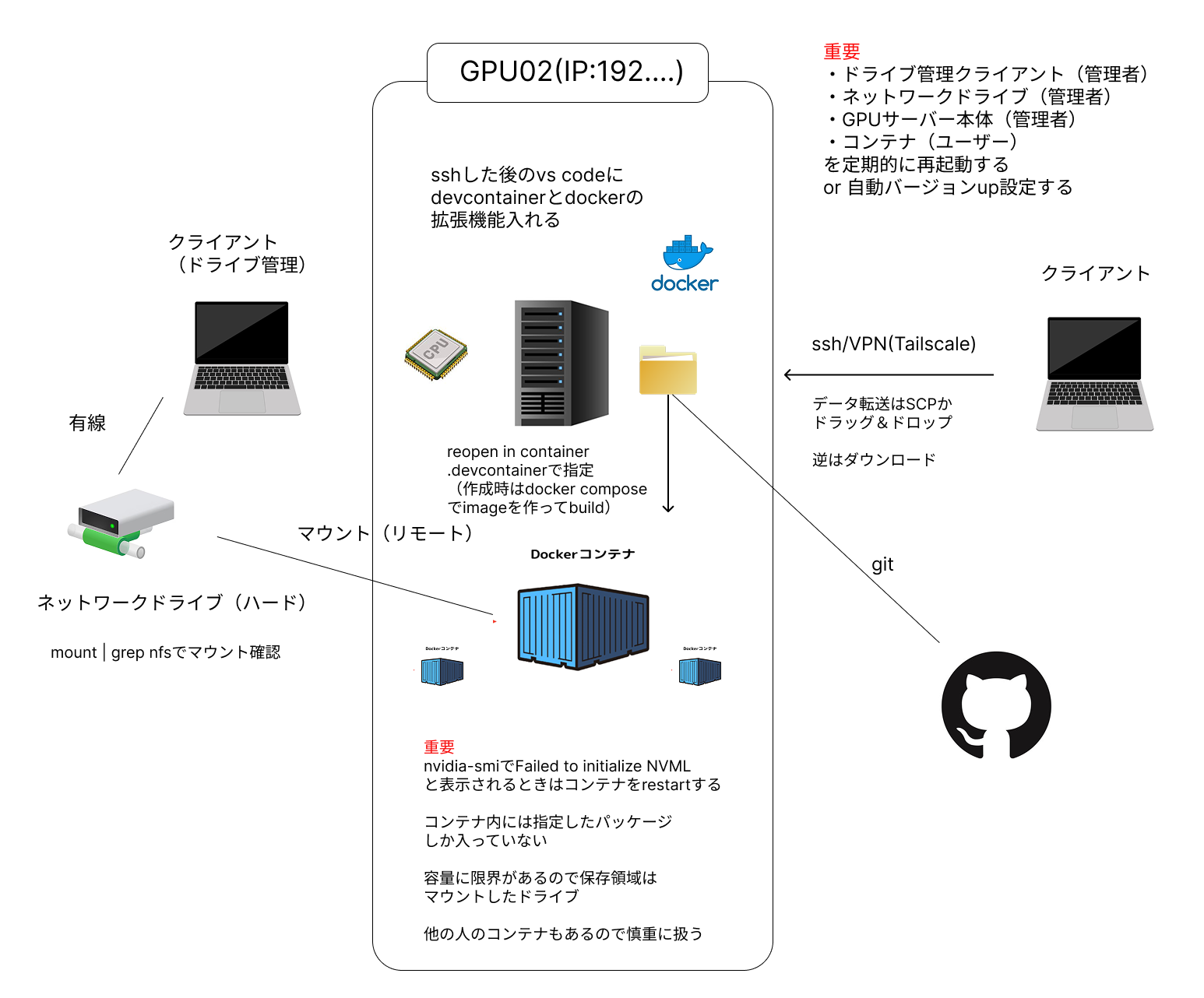
1. 接続と監視
GPUサーバーへの接続
- SSH接続: 研究室のGPUサーバーにはSSHで接続する.
- VPN (Tailscale): Tailscaleを利用することで, どこからでも研究室のGPUサーバーにSSH接続が可能である.
GPUの監視
-
watch nvidia-smiコマンドで, GPUの使用状況をリアルタイムで監視する.
watch nvidia-smi
2. トラブルシューティング
ケース1: GPUセッション切れ (コンテナ放置)
症状:
コンテナを立てっぱなしにするとGPU接続が切れる.
解決策:
- VSCodeの "Reopen Container" を実行する.
- コンテナ一覧から対象のコンテナを右クリックして "Restart" する.
- 再度 "Reopen Container" を実行する.
ケース2: GPU謎の接続切れ (バージョン不整合)
症状:
nvidia-smi 実行時に Failed to initialize NVML と表示される.
原因:
サーバー本体(ハード)のGPUドライバが自動更新され, コンテナ内のバージョンと不整合を起こしている可能性がある.
解決策:
- SSHで接続しているコンテナを
restartする. - それでもダメならGPUサーバー本体を再起動する.
ケース3: git/pip コマンドエラー
症状1: コンテナ内で git が使えない.
解決策: Dockerfileがあるホスト側で実行する.
症状2: pip がないと表示される.
確認: コンテナの外(ホストOS)で実行していないか確認する.
ケース4: SSH接続不可 (データが見れない)
症状:
データが見れない.
確認事項:
- データはSSHの外(ドライブなど)にも保存する.
- マウント元のMac miniがスリープ/電源オフになっていないか確認する(再起動で解決することが多い).
ケース5: SSH接続不可 (workフォルダが空)
症状:
/work フォルダが空になっている.
原因:
マウント元のドライブの電源が落ちている, またはマウントが切れている可能性がある.
対処法:
- SSH先で以下のコマンドを実行し, マウント状況を確認する.
mount | grep nfs - マウントが切れていたら管理者に再マウントを依頼する.
3. データ管理とパフォーマンス
コンテナ容量制限
-
/workディレクトリの容量制限(例: 200GB)を認識する.
GPUメモリ不足
- "Out of Memory" エラーへの対処法を調査しておく.