はじめに
ゼットラボ株式会社では、Yahoo! JAPAN向けにKubernetes as a Serviceを提供しています。
利用者がKubernetes as a Serviceを使用していると、利用者だけではわからないことが出てきて問い合わせが来るケースがあります。
今回は対応したサポートケースの内の1件の内容について、外部の方が見ても分かる形に情報を整理して記事にしました。
記事に記載されているバージョン等の情報はサンプルで記載されているもので、実際に起こった環境のものではありません。本事象はKubernetes v1.8以上であれば再現可能な事象になります。
利用者からの問い合わせ内容
利用者からは以下のような問い合わせを頂きました。
kubectl logs でログを取得しようとするとエラーメッセージが出力されます。
$ kubectl logs <Pod名> unable to retrieve container logs for containerd://4703b9db4177926a2c963fa9e635e5931587f6e0e3b7d7165e94c6f4689d5c35
unable to retrieve container logsの理由と対処方法を教えてください。
利用者の質問の意図としてはkubectl logs実行時に以下のようにログメッセージを取得できることを期待しているが、エラーが出るので原因と対策を知りたいという内容の問い合わせになります。
$ kubectl logs <Pod名>
Hello, Kubernetes!
初動
サポートのエスカレーションが来た時には、多くのケースで以下を実施します。
- 利用者へのヒアリング
- k8sのクラスタに残っている情報の収集
利用者へのヒアリング
実際にサポートにくるケースだと、端的な内容だけが書かれて調査に必要な情報が十分に足りていない状態であることが多いです。
そのため、調査範囲を絞り込むために以下にようなことをヒアリングします。
- Kubernetes上でどういったサービスを提供しているか (Webアプリケーション?バッチ処理?)
- サービスのアーキテクチャ
- 事象の発生時刻や発生頻度
- 事象の再現性の有無
- 事象発生前後での変更内容
- etc
状況に応じてヒアリングする内容は異なりますが、上記のようなことを利用者に確認します。
色々確認した情報の中で今回の件では利用者がKubernetesのJobを中心に利用しているというのが大事になってきます。
(実際の調査時にはこの時点ではこれが大事なことは不明です。)
この辺のやり方はOSSの方でも同じことがされていて、Issueの起票時には以下のテンプレートに必要事項を記載するようになっています。
参考:Issueの起票の際のOSSのテンプレート
k8sのクラスタに残っている情報の収集
今回はkubectl logs実行時に関する問い合わせなので、まずは対象のPodの情報を収集します。
$ kubectl logs <Pod名>
-
Podの情報を収集
kubectl get -oyamlkubectl describeetcPodの情報を確認すると
ownerReferencesからJobとCronJobを利用していることが分かったので合わせて情報を取集します。 -
Job,CronJobのの情報を収集
kubectl get -oyamlkubectl describeetc合わせて利用者がapplyしたマニフェストの情報も確認します。
-
利用者のGithub上のマニフェストの情報を収集
Podの情報から起動していたノードも確認できるので、Kuberntes上のノードオブジェクトの情報も収集します。
-
ノードの情報を収集
kubectl get -oyamlkubectl describeetc -
Control Planeのログの収集
kube-apiserverkubeletetc のログ -
Eventの情報を収集
kubectl get eventsEventrouteretcKubernetesのトラブルシュートの際にはよく取得する情報になります。
Kubernetesに関して何かわからないことがあると、大体上記あたりの情報を取得します。
利用者が自分でトラブルを解決できるようになることを考えると、利用者自身がそれぞれの必要性を理解して自分で情報収集できるようになるのが好ましいです。本当の理想は利用者自身で解決できることですが、いきなりそれは難しいのでまずは上記の内容が自分達だけでできるようにアドバイスしていきます。
また、発生頻度が少なく、すでにk8sクラスタ内に事象に関する情報がないケースもあります。そういう場合は情報の収集方法の説明をして、再発待ちになるケースもあります。
unable to retrieve container logsが出力される原因の調査
調査方法の説明
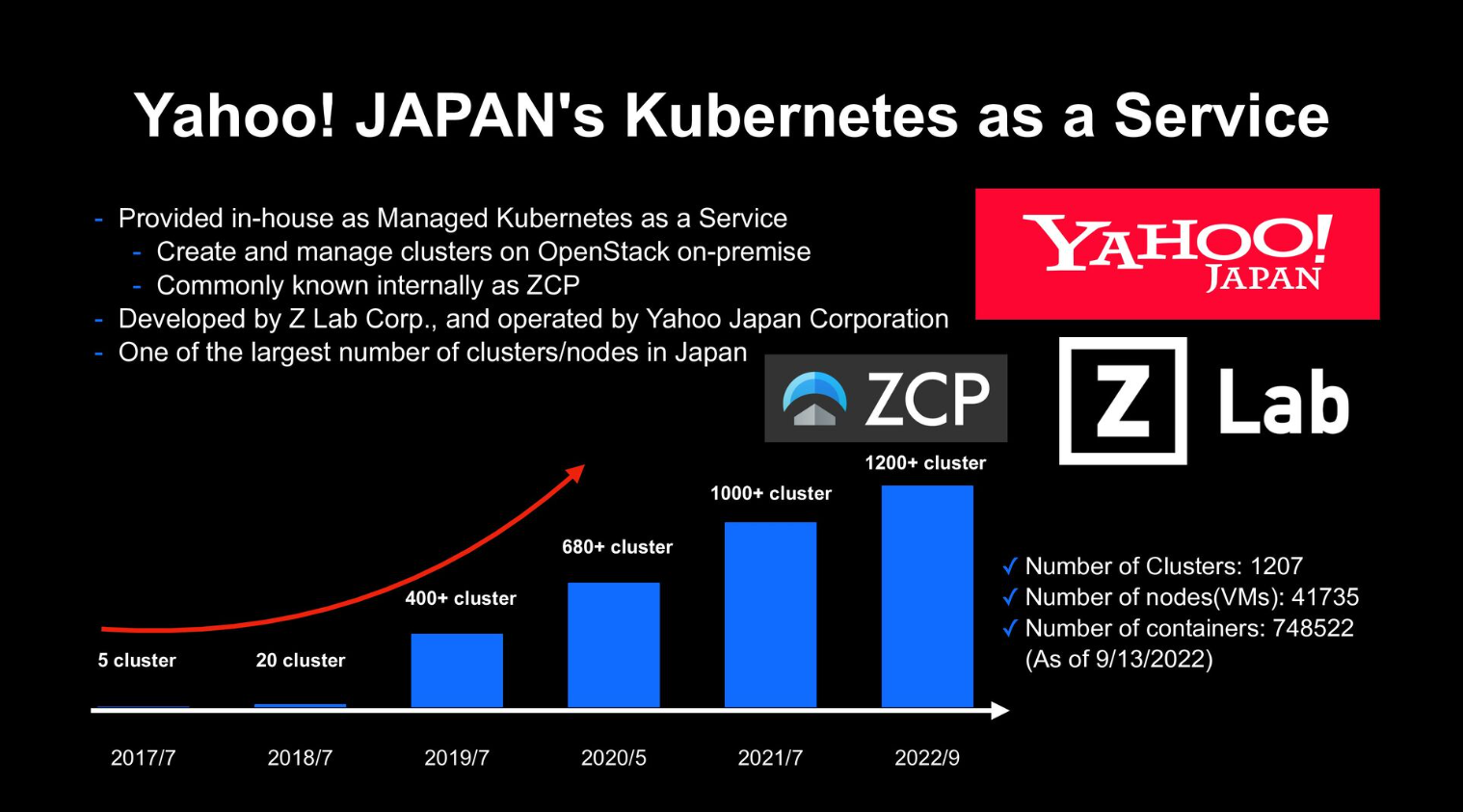
まず、kubectl logsを実行すると、各コンポーネントでどういう処理が行われるのかを知る必要があります。
引用:https://speakerdeck.com/yosshi_/getting-started-with-kubernetes-observability?slide=23
kubectl logsの処理が上記のようになっているのは事前に知っているので、関連する以下のコンポーネントを確認していくことになります。
- API Server
- Kubelet
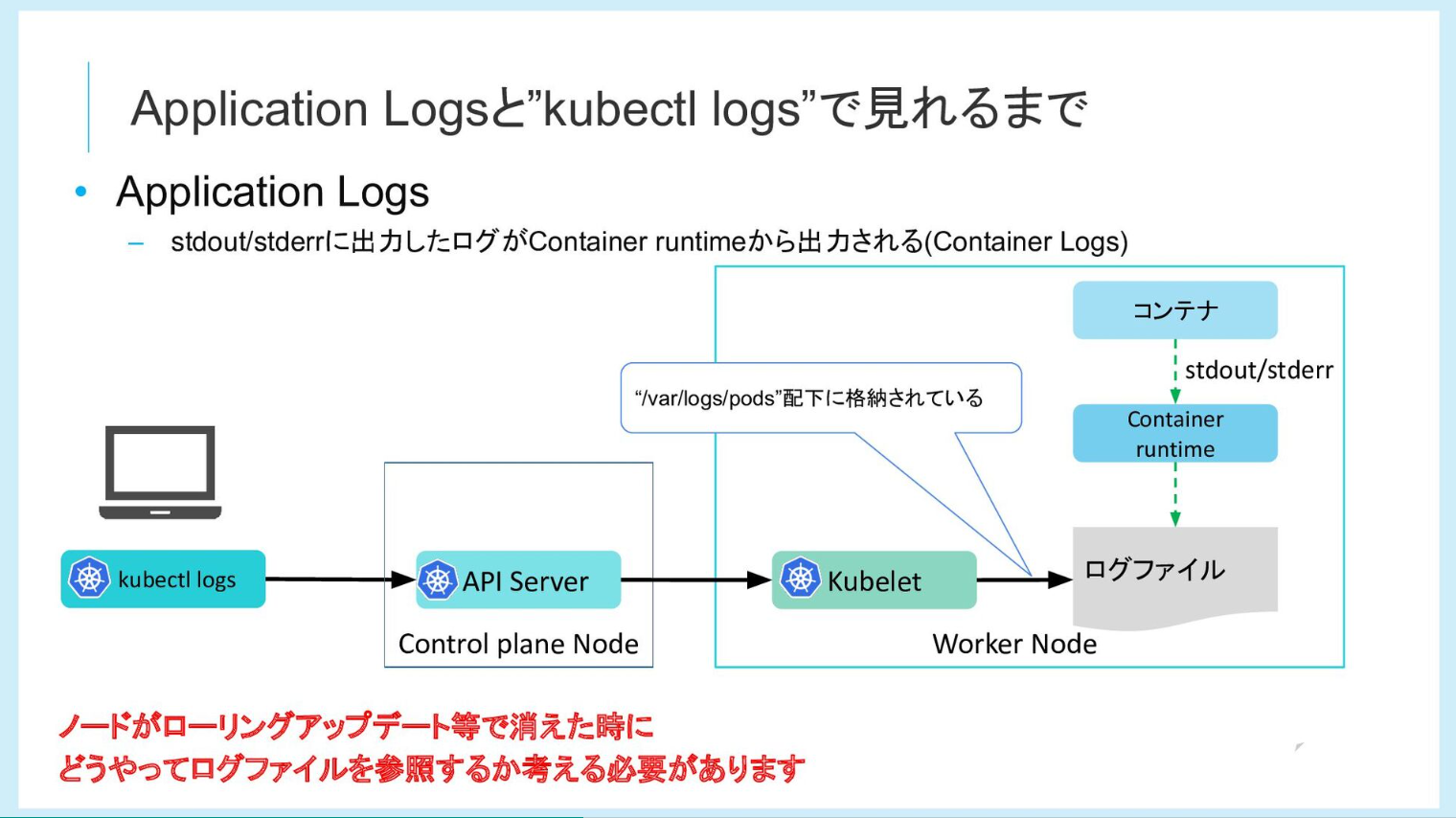
- Container runtime (今回のケースでは Containerdを使用)
上記を調べる際のアプローチ方法は大きく2つあります。
- ソースコード上で検索をかけて
unable to retrieve container logsの出力箇所を確認する - 事象発生時刻付近の該当ログを確認していく
上記の2つに関してはどちらか1つではなく、両方実施して事実を確認していきます。
調査結果の説明
ログ等を確認していくと、kubectl logs実行時に表示されているメッセージはkubeletの以下の箇所で出力されていることがわかりました。
// GetContainerLogs returns logs of a specific container.
func (m *kubeGenericRuntimeManager) GetContainerLogs(ctx context.Context, pod *v1.Pod, containerID kubecontainer.ContainerID, logOptions *v1.PodLogOptions, stdout, stderr io.Writer) (err error) {
status, err := m.runtimeService.ContainerStatus(containerID.ID)
if err != nil {
klog.V(4).InfoS("Failed to get container status", "containerID", containerID.String(), "err", err)
return fmt.Errorf("unable to retrieve container logs for %v", containerID.String())
}
return m.ReadLogs(ctx, status.GetLogPath(), containerID.ID, logOptions, stdout, stderr)
}
上記の処理を見ると、KubeletがContainerdに対して、<コンテナID>を元に問い合わせを行った時に、どうやらコンテナの情報が取れなかったからエラーになっているようだということがわかります。
実際に出力される各コンポーネントのログは以下のようになります。
-
kubectl logs実行時のkubeletログ
Apr 07 09:23:18 <ノード名> docker[5013]: E0407 09:23:18.813824 5126 remote_runtime.go:597] "ContainerStatus from runtime service failed" err="rpc error: code = NotFound desc = an error occurred when try to find container \"<コンテナID>\": not found" containerID="<コンテナID>"
Apr 07 09:23:18 <ノード名> docker[5013]: I0407 09:23:18.816897 5126 log.go:184] http: superfluous response.WriteHeader call from k8s.io/kubernetes/vendor/github.com/emicklei/go-restful.(*Response).WriteHeader (response.go:220)
-
kubectl logs実行時のcontainerdログ
Apr 07 09:23:18 <ノード名> containerd[4556]: time="2023-04-07T09:23:18.813255753Z" level=error msg="ContainerStatus for \"<コンテナID>\" failed" error="rpc error: code = NotFound desc = an error occurred when try to find container \"<コンテナID>\": not found"
上記の時に実際にContainerd上で該当のコンテナがどういう状態になっているかを確認します。
対象のコンテナIDが分かっていればnerdctl等のコマンドを使って確認することができます。
$ sudo nerdctl ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
:
上記の結果、該当のコンテナがないことがわかりました。
kubectl logsがunable to retrieve container logsのエラーメッセージを出力するのは「Containerd上に該当のコンテナIDのコンテナが存在しないからだ」ということが分かりました。
次に問題になるのは、なぜコンテナがないのか?ということになります。
Kubernetesの調査の難しさ
kubectl logsの処理を順番に追っていくことでunable to retrieve container logsがどこで出力されており、それが該当のコンテナが存在しないことに起因していることが分かりました。
ただ、これだけでは本当の原因である「該当のコンテナが消えている原因」が分かりません。
Kubernetesでは複数の処理が非同期に実行されるので、一部の処理を追いかけただけでは全体が把握できないケースが多々あります。
該当のコンテナが消えている原因の調査
調査方法
調査方法案
こういう場合に以下のような調査方法があるかなと思います。
-
過去の問い合わせ内容等のナレッジを確認する
自分達が過去にサポートした際のissueやKubernetes公式のGithubのissueや公式のSlack等の情報を確認することで、解決のヒントを得られることがあります。 -
ソースコードから処理を確認していく
ソースコードを読んでいって該当の処理が起こりそうな箇所を特定するというやり方もあるかと思います。ただこの方法はKubernetesに対するアプローチとしては難しいと思います。Kubernetesのコード量が多いのと、該当する処理を読んだとしてそれが今回の事象につながる箇所だと気付けるかというと難しいと思います。たまたま自分が知っているKubernetesのコードの箇所で該当しそうな箇所があったら読み直してみるぐらいが使い所で、安定して使える方法ではないと思います。
-
再現条件を特定する
事象の再現条件を特定して、再現した結果を元に原因を調査する方法もあります。多くの場合の調査としてはこの方法を実施します。
実際の調査方法
今回のケースで実際に行った調査方法は以下のようになります。
- 過去の問い合わせ内容等のナレッジを確認する
今回の件についてはKubernetesの公式のissue等を確認しても該当するものはありませんでした。 - 再現条件を特定する
利用者の環境や利用方法をヒアリングして、再現条件を特定して原因を調査したというのが今回の流れになります。
再現方法の特定
環境構築
実際の商用環境で色々と実験をするわけにはいかないので、手元で自由に操作できる環境を構築します。
事象の発生している利用者の環境におけるバージョンの情報を確認して、同じバージョンで環境を構築します。バージョンの組み合わせが異なると該当事象が発生しない可能性があるので大事な基本動作になります。
今回の事象は状況的にKubeletとContainerdが関連するバージョン情報を以下のようなコマンドで取得して同じ環境を作成します。
e.g.
$ kubectl get node -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
<ノード名> Ready <none> 41m v1.23.9 <IPアドレス> <none> Ubuntu 20.04.5 LTS 5.4.0-139-generic containerd://1.6.16
$ runc --version
runc version 1.1.4
commit: v1.1.4-0-g5fd4c4d
spec: 1.0.2-dev
go: go1.18.10
libseccomp: 2.5.1
再現に関する情報の絞り込み
ヒアリングした内容や取得した情報を元に、仮説を立てながら試行錯誤して事象の再現を試みます。
ただ漠然とKubernetes全体の情報を確認していくと範囲が広く、時間がかかるので確認すべき情報に優先順位をつけて絞り込んでいきます。
コンポーネントに関する絞り込み
コンテナに関する操作に関する話なので恐らくkubeletかcontainerdに関する何かが影響している可能性が高いので、これらのコンポーネントに関する情報を優先的に見ていく方針を立てました。
ただ、この時点でそれ以外の何かのプロセスがコンテナを削除した懸念は拭えないのですが、優先順をつけて情報を見ていかないと量が多いのでこういう方針を立てています.
時間帯での絞り込み
unable to retrieve container logsの詳細情報を見てみると以下のようなことがわかりました。
$ kubectl describe po <Pod名>
:
Status: Succeeded
Containers:
<コンテナ名>:
State: Terminated
Reason: Completed
Exit Code: 0
Started: Mon, 10 Apr 2023 18:27:25 +0900
Finished: Mon, 10 Apr 2023 18:27:25 +0900
該当のコンテナのプロセスがExit Codeの0を返してきて、それがPodの情報として記録されているということは、その時間帯までは該当のコンテナのプロセスが存在していたことを示しています。
そのことから以下の時間帯に何かがあったのだろうということが推測されるので、該当時間に絞って調査していく方針としました。
- 開始:Jobで管理するPodの
Finishedに記載されている時刻 - 終了:利用者が
kubectl logsを実行してunable to retrieve container logsを確認した時刻
仮説
該当時間のkubeletのログを1行ずつ確認していると気になるログを見つけました。
eviction_manager.go:338] "Eviction manager: attempting to reclaim" resourceName="ephemeral-storage"
上記のことからDiskPressureによるEvictionが発生したことにより、今回の事象が発生したのではないかという仮説を立てました。
検証
- nodeSelectorで対象ノードを固定してログを出力するJobを用意する
apiVersion: batch/v1
kind: Job
metadata:
name: hello
spec:
backoffLimit: 1
parallelism: 5
completions: 20
template:
spec:
nodeSelector:
kubernetes.io/hostname: <ノード名>
containers:
- name: hello
image: busybox
command: ["echo", "Hello, Kubernetes!"]
restartPolicy: Never
Disk Pressureがクラスタ全体で発生するとAPI Serverに接続しづらくなったり、確認すべき対象のノードが複数になったりして確認しにくいので、確認しやすくするために対象ノードの限定しています。
事象が発生しやすいように20個ほどPodをデプロイしてみます。
- ログが正常に取得できることを確認します。
$ kubectl logs -l job-name=hello
Hello, Kubernetes!
Hello, Kubernetes!
Hello, Kubernetes!
Hello, Kubernetes!
Hello, Kubernetes!
Hello, Kubernetes!
Hello, Kubernetes!
Hello, Kubernetes!
Hello, Kubernetes!
Hello, Kubernetes!
Hello, Kubernetes!
Hello, Kubernetes!
Hello, Kubernetes!
Hello, Kubernetes!
Hello, Kubernetes!
Hello, Kubernetes!
Hello, Kubernetes!
Hello, Kubernetes!
Hello, Kubernetes!
Hello, Kubernetes!
- 対象のノードが
Disk Pressureの状態になるように、ディスク容量を消費するJobを用意する
apiVersion: v1
kind: ConfigMap
metadata:
name: scripts
data:
test.sh: |
#!/bin/sh
dd if=/dev/zero of=5G.dummy bs=1M count=5000
---
apiVersion: batch/v1
kind: Job
metadata:
name: disk-pressure-test
spec:
backoffLimit: 3
parallelism: 1
completions: 15
template:
spec:
nodeSelector:
kubernetes.io/hostname: <ノード名>
containers:
- name: disk-pressure-test
image: busybox
command: ["/bin/sh", "/shell/test.sh"]
volumeMounts:
- name: config-volume
mountPath: /shell
volumes:
- name: config-volume
configMap:
name: scripts
items:
- key: test.sh
path: test.sh
restartPolicy: Never
- Evictedが発生することを確認
$ kubectl get po
NAME READY STATUS RESTARTS AGE
disk-pressure-test-4h6wj 0/1 Completed 0 36s
disk-pressure-test-6b684 0/1 Completed 0 57s
disk-pressure-test-g6j92 0/1 Completed 0 80s
disk-pressure-test-kf8k5 0/1 Completed 0 91s
disk-pressure-test-n4rgw 0/1 Evicted 0 20s
disk-pressure-test-pvms4 0/1 Pending 0 10s
disk-pressure-test-rdx8v 0/1 Completed 0 69s
disk-pressure-test-s9m2q 0/1 Evicted 0 20s
disk-pressure-test-z2zth 0/1 Completed 0 46s
hello-26fmz 0/1 Completed 0 6m7s
:
- Evictedの原因が
Disk Pressureであることを確認
$ kubectl describe po disk-pressure-test-n4rgw
Name: disk-pressure-test-n4rgw
:
Status: Failed
Reason: Evicted
Message: Pod The node had condition: [DiskPressure].
:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 29s default-scheduler Successfully assigned job-test/disk-pressure-test-n4rgw to demo-yosshi-cj-w-default-03a7f1b0-fqtj8
Warning Evicted 30s kubelet The node had condition: [DiskPressure].
- この状態で
kubectl logsを実行してログを取得できるか確認
$ kubectl logs -l job-name=hello
unable to retrieve container logs for containerd://a39e46811fd9cb371853d60f27a40321428a1d0dff2a6587a0e2207d225dfcba
unable to retrieve container logsのメッセージが取得でき、申告にあった状態を再現することに成功
再現結果からの深掘り
再現時のkubeletのログ確認
手元で再現ができるようになると、ノイズが少ない状態のログを取得できるようになります。
-
Disk Pressure発生時のkubeletのログ
I0214 08:38:39.199718 5148 eviction_manager.go:338] "Eviction manager: attempting to reclaim" resourceName="ephemeral-storage"
I0214 08:38:39.201508 5148 container_gc.go:85] "Attempting to delete unused containers"
I0214 08:38:39.203363 5148 scope.go:110] "RemoveContainer" containerID="aa176ae956aa102c5a65b83c9c21f95f5cb19adf77e1205b189663252fd859d7"
I0214 08:38:39.212115 5148 scope.go:110] "RemoveContainer" containerID="7a0531f9dea7aeac6d18eece63bc6127cabd744bbd993feade307dcd27ad5e87"
I0214 08:38:39.219660 5148 scope.go:110] "RemoveContainer" containerID="5f6f972e2110d22004f6d6cb65ef762b4263e53fa45a3fa34dd33dc393a5399e"
I0214 08:38:39.282208 5148 scope.go:110] "RemoveContainer" containerID="4471fe782da67ad8ac3871108b45eb9342d85a3156996534d55d7f450b5dd352"
I0214 08:38:39.301176 5148 scope.go:110] "RemoveContainer" containerID="095d21344362bda473daf55c9835a5252f21bd68934ba93b0ffe947f8a129c63"
I0214 08:38:39.315522 5148 scope.go:110] "RemoveContainer" containerID="48a095de20e37a4ad729eb15372dfd617fe6c0373b1cb67d6705f186a9cf08a6"
I0214 08:38:39.617581 5148 image_gc_manager.go:327] "Attempting to delete unused images"
I0214 08:38:39.722762 5148 eviction_manager.go:345] "Eviction manager: able to reduce resource pressure without evicting pods." resourceName="ephemeral-storage"
ログにはeviction_manager.go:338のように、ログを出力した該当のソースコードの情報が記載されているので、該当のソースコードを順番に読んでいくことで実際に起こった処理の内容を把握していくことができます。
ソースコードリーティング
ログに記載されていたソースコード確認していくと以下のようになります。
- eviction_manager.go:338
// rank the thresholds by eviction priority
sort.Sort(byEvictionPriority(thresholds))
thresholdToReclaim, resourceToReclaim, foundAny := getReclaimableThreshold(thresholds)
if !foundAny {
return nil
}
klog.InfoS("Eviction manager: attempting to reclaim", "resourceName", resourceToReclaim)
- container_gc.go:85
func (cgc *realContainerGC) DeleteAllUnusedContainers() error {
klog.InfoS("Attempting to delete unused containers")
return cgc.runtime.GarbageCollect(cgc.policy, cgc.sourcesReadyProvider.AllReady(), true)
}
どうやらDisk Pressure発生時terminatedのコンテナを削除するようになっていそうだということがわかります。
実装の経緯の確認
OSSなので分からないことも多いのですが、変更時のPRに参考になる情報が含まれていることも多いのでgit blame等を使って確認していきます。
git blame
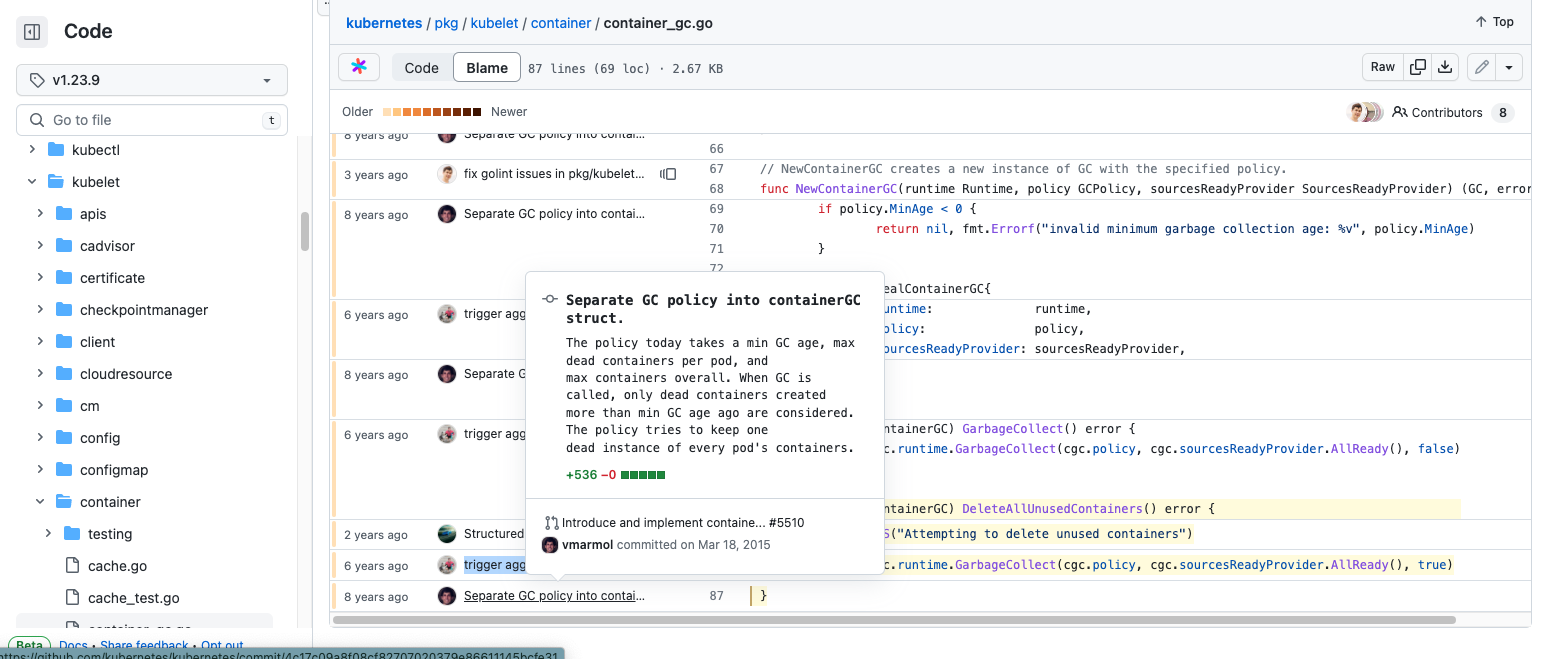
- 変更時のPR
ref https://github.com/kubernetes/kubernetes/pull/45896
変更時のPRを読んでいくと、Kubernetes v1.8からDisk Pressure発生時にterminatedのコンテナを削除する処理が実装されていることがわかります。変更理由がDisk Pressure発生時に使ってないコンテナを削除することでディスクの空き容量を増やすための実施しているということもわかりました。
原因の考察
Kubernetes v1.8からDisk Pressure発生時にterminatedのコンテナを削除する処理が実装されているため、以下の条件が重なった時にunable to retrieve container logsが出力されると考えられます。
- terminatedのコンテナが存在する
- ノードで
Disk PressureによるEvictionが発生する -
kubectl logsでPodのログを参照する
該当機能がKubernetes v1.8から実装されているにも関わらずに、新規のサポートケースとして問い合わせがきたのかについても少し考えてみます。(このサポートケースが他のユースケースでもよく起こるものなのか考える)
KubernetesのユースケースではWebアプリケーションを動かすケースが多く、Deploymentを使用するケースが多数を占めます。その場合はPodのステータスがRunningになっており、コンテナの状態もterminatedではないという場合が多くなります。
そのため、上記の条件を全部満たすというのがあまり多くないので、今回が初めてのサポートケースになったのだと考えられます。
事実確認
上記の内容は手元で確認した内容に基づく仮説なので、実際に起こっていた事実かどうかはまだ確証がないです。
そこで、手元でDisk Pressure発生させた時のkubeletのログに出力されていたのと同じ内容のログが利用者の環境から取得したkubeletに出力されていたかを確認します。
- 再掲:
Disk Pressure発生時のkubeletのログ
I0214 08:38:39.199718 5148 eviction_manager.go:338] "Eviction manager: attempting to reclaim" resourceName="ephemeral-storage"
I0214 08:38:39.201508 5148 container_gc.go:85] "Attempting to delete unused containers"
I0214 08:38:39.203363 5148 scope.go:110] "RemoveContainer" containerID="aa176ae956aa102c5a65b83c9c21f95f5cb19adf77e1205b189663252fd859d7"
I0214 08:38:39.212115 5148 scope.go:110] "RemoveContainer" containerID="7a0531f9dea7aeac6d18eece63bc6127cabd744bbd993feade307dcd27ad5e87"
I0214 08:38:39.219660 5148 scope.go:110] "RemoveContainer" containerID="5f6f972e2110d22004f6d6cb65ef762b4263e53fa45a3fa34dd33dc393a5399e"
I0214 08:38:39.282208 5148 scope.go:110] "RemoveContainer" containerID="4471fe782da67ad8ac3871108b45eb9342d85a3156996534d55d7f450b5dd352"
I0214 08:38:39.301176 5148 scope.go:110] "RemoveContainer" containerID="095d21344362bda473daf55c9835a5252f21bd68934ba93b0ffe947f8a129c63"
I0214 08:38:39.315522 5148 scope.go:110] "RemoveContainer" containerID="48a095de20e37a4ad729eb15372dfd617fe6c0373b1cb67d6705f186a9cf08a6"
I0214 08:38:39.617581 5148 image_gc_manager.go:327] "Attempting to delete unused images"
I0214 08:38:39.722762 5148 eviction_manager.go:345] "Eviction manager: able to reduce resource pressure without evicting pods." resourceName="ephemeral-storage"
問い合わせ時に十分に情報が取得できていない場合は、この工程は実施できない場合がありますが、できればやっておきたい内容になります。
原因に対する対処
unable to retrieve container logsの原因については分かりましたが、原因が分かっただけでは利用者としては以下に2つの課題が依然として存在します。
-
kubectl logsでコンテナのログが取得できない -
Disk Pressureが定期的に発生している
それぞれに対する対処方法を考えていきます。
「kubectl logsでコンテナのログが取得できない」件の対処
そもそもの話になってしまいますが、kubectl logsが該当のコンテナのログを必ず取得できることを保証するような設計になっていません。
コンテナのログについては各ノードに閉じたものになっているので、以下のようにローリングアップデート時に該当のサーバがなくなると取得できなくなります。
引用:https://speakerdeck.com/yosshi_/kubernetes-loggingru-men?slide=26

Jobが完了して、terminatedになっているコンテナについては、UnusedContainersとソースコード上で書かれたりしており、そもそも使用していないものとして扱われています。
そのため、ログが取得できることを期待する場合は以下のようにLogging Beckend(e.g. Grafana Loki)を使用する必要があります。
引用:https://speakerdeck.com/yosshi_/kubernetes-loggingru-men?slide=30
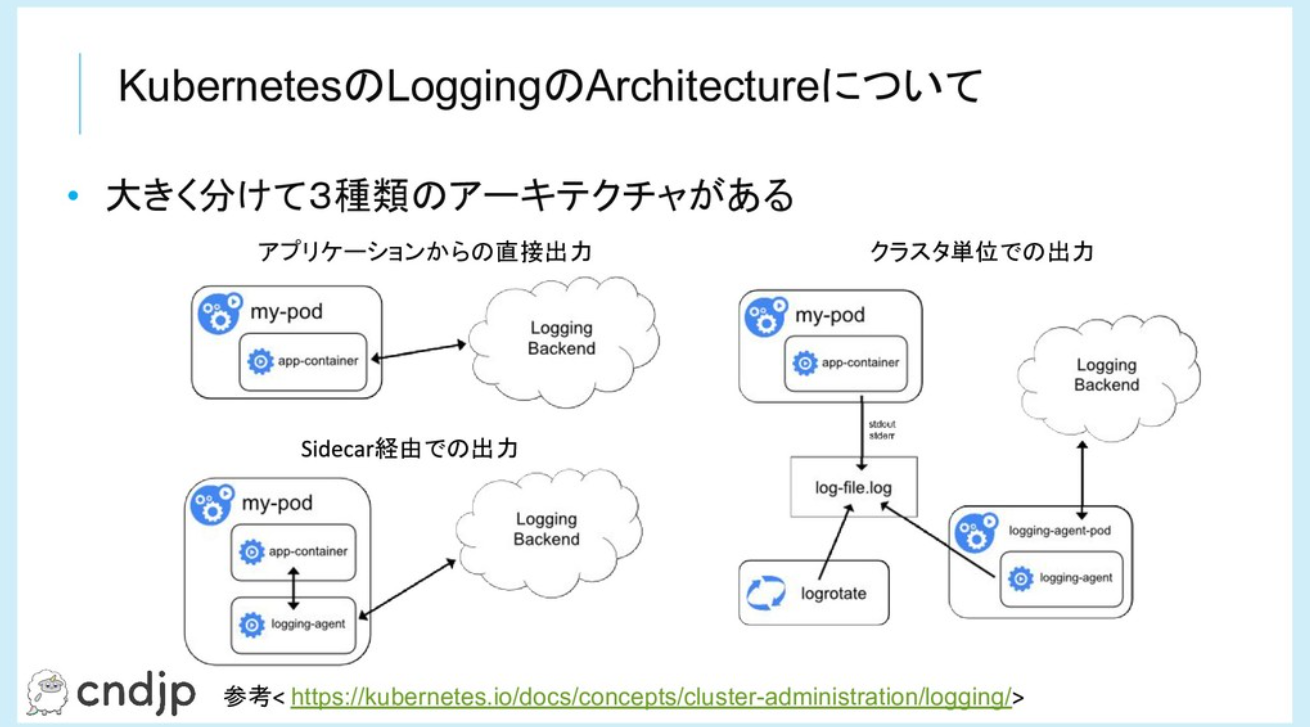
kubectl logsはあくまで補助的なコマンドであり、商用の運用にログの取得を組み込むのであればLogging Beckendの利用を検討してもらうように利用者に案内していきます。
「Disk Pressureが定期的に発生している」件の対処
Disk Pressureが指しているDiskは、kubernetes上ではnodefsとimagefsの2つになります。
それぞれ以下のようなものが含まれます。
- nodefs
- local disk volumes
- emptyDir
- log storage
- etc
- imagefs
- container images
- container writable layers
ref https://kubernetes.io/docs/concepts/scheduling-eviction/node-pressure-eviction/
もちろんクラスタ全体のディスク使用量を増やすというアプローチもありますが、原因に合わせて対策しないと効果があまり出ないケースもあるので注意してください。
nodefsの対策
nodefs起因によるDisk Pressureが発生している場合は以下の対策が考えられます。
- resource.requests/limitの設定見直し
- PVの利用の検討
resource.requests/limitsの設定見直し
ephemeral storageに対するrequests/limitsを設定するというものになります。
requests/limitを設定時には以下の2点に気を付けてください。
- requestsを設定する
ephemeral storageに関しては設定されていないケースが結構多く、設定していたら防げたなというケースを見ることも時々あります。 - 運用時に定期的にrequests/limitの見直しを行う
初回リリース時は設定したけど、機能追加等により使用するリソースが増えるケースが結構出てくると思います。その際にrequests/limitを修正しているケースは少ない印象を受けているので、できれば見直ししたほうが良いです。
参考:Kubernetes の ephemeral storage
PVの利用の検討
ノード上のディスクで足りない場合はPVを使って外部ストレージを使用する方法があります。
CPUやメモリの増加量としてディスクの増加量が多い場合は、外部ストレージの利用を検討するという選択肢があります。
通常のPV以外にもGeneric Ephemeral Volumeを使うという選択肢もあるので検討してみるという方法もあります。
参考:Kubernetes: CSI を使ったEphemeral Volumeの動作検証
imagefsの対策
imagefs起因によるDisk Pressureが発生している場合は以下の対策が考えられます。
- Image GCの設定の見直し
- emptyDirの利用の検討
Image GCの設定の見直し
kubeletではImage GCという仕組みがあって、以下の設定をもとにGCを実施しています。
- imageMinimumGCAge: デフォルト2min
- imageGCHighThresholdPercent : デフォルト 85%
- imageGCLowThresholdPercent: デフォルト 80%
if obj.ImageMinimumGCAge == zeroDuration {
obj.ImageMinimumGCAge = metav1.Duration{Duration: 2 * time.Minute}
}
if obj.ImageGCHighThresholdPercent == nil {
// default is below docker's default dm.min_free_space of 90%
obj.ImageGCHighThresholdPercent = utilpointer.Int32Ptr(85)
}
if obj.ImageGCLowThresholdPercent == nil {
obj.ImageGCLowThresholdPercent = utilpointer.Int32Ptr(80)
Image GCではディスク使用量がHighThresholdPercent以上になった時にLowThresholdPercent以下になるように古いイメージから順に削除します。
現在のデフォルトの設定ではディスク使用率が85%以上になった時にディスク使用率が80%以下になるように古いイメージから削除します。
Kubernetesの場合は3,4ヶ月に一回の頻度でマイナーバージョンがリリースされて、古いマイナーバージョンはEOLになります。それに追随する形で定期的のノードを使い捨てる形でローリングアップデートを実施すると、1台あたりのノードの寿命が最長で4ヶ月になるケースが多いと思います。
Webアプリケーションを主体で利用していると、4ヶ月の間にImageをそんなに大量にPullするケースがないのでデフォルト値でもそんなに問題になるケースはないかなと思います。
ただ、Jobを主体で利用しており、同じコンテナイメージを何度も実行するのではなく、新しいコンテナイメージをたくさんPullするような使い方をしているとコンテナイメージの使用量が肥大化するケースがあります。
今回のサポートケースだと、この要因が占める割合が高かったです。(単純にここだけ対応すれば大丈夫といえるわけでもないです。)
参考:Kubernetes の Garbage Collection
emptyDirの利用の検討
container writable layers利用する場合は、emptyDirを使用することを検討したほうがいいと思います。
emptyDirはPod単位に管理されるので、コンテナがクラッシュした場合にcontainer writable layersに書き込まれたデータはコンテナと共に消えますが、emptyDirはPod単位の管理なので引き継がれます。また、何らかの理由で古いコンテナが残っていた場合にcontainer writable layersに書き込まれていたデータも消えずにディスク容量を消費します。
emptyDirだとsizeLimit等も機能も使えるので、container writable layersを使用するよりはemptyDirの方が要件に合うケースの方が多いと思います。
おわりに
Kubernetesのトラブルシューティングがよく分からないという話を、自分もよく耳にするので外部向けにまとめて書いてみました。
今回はちょっと時間のかかったケースを記事にしてみたので長くはなりましたが、エスカレーションされた時に調査の流れについてはいつも同じようなことをしていると思います。
よかったらKubernetesのトラブルシューティング時に参考にしてみてください。