はじめに
このページではKubernetes v1.24 Stargazer における SIG-Apps に関連する変更内容をまとめています。
SIG-AppsはKubernetesのワークロードの扱いなどの変更を主に扱っているため、他のSIGと関係する変更が多くなっております。
- 直近での過去の変更内容は以下になります。
SIG / SIG-Apps とは?
-
SIGとは?
- Special Interest Groups の略称
- 各 SIG には Subproject が与えられていて、 Subproject に対して独立して開発できるようになっています。
- Kubernetes は巨大なプロジェクトなので、各SIG 毎に担当(Subproject)が割り当てられていて、各SIG は独立して開発をしています。
- SIG 間を跨って話し合いをする必要が生じた場合は Working Groups が一時的に作られ、その枠組みの中で話し合うことになります。
-
SIG-Appsとは?
- Apps Special Interest Group の略称
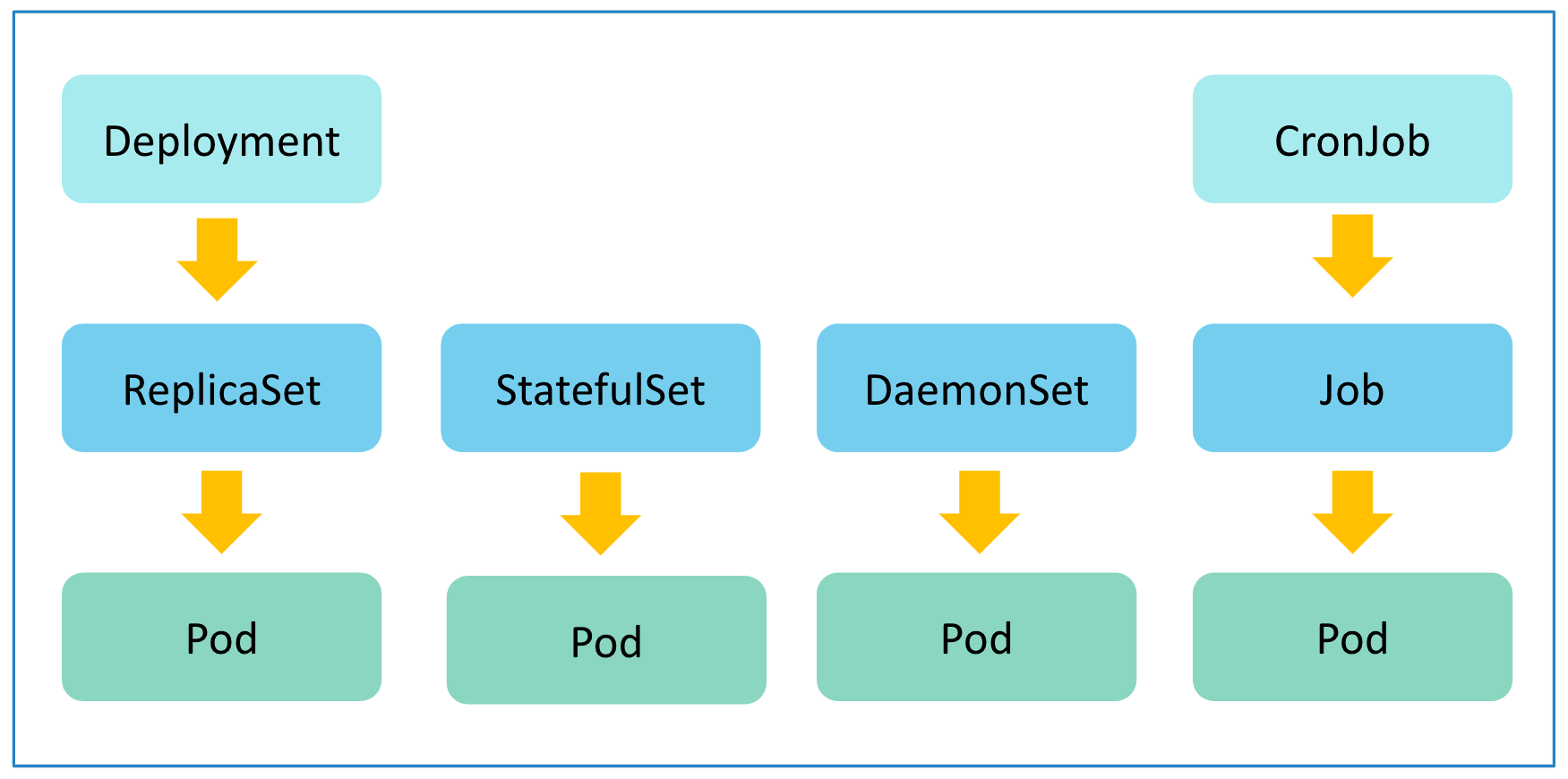
- Kubernetes に対して、application を deploy したりすることに関することが対象。具体的には Pod, ReplicaSet, Deployments, DaemonSet, StatefulSet, Jobs, CronJob が対象。
- 詳細について知りたい方はこちらをご参照ください。
SIG-Apps 以外の SIG に関する変更は以下にまとめてありますので、合わせてご参照下さい。
注目の変更
Feature Gatesの中で今回Stageに変更のあったSig-Appsに関連する機能は以下になります。
-
Job
-
CronJobTimeZone:Alphahttps://github.com/kubernetes/enhancements/issues/3140 -
JobReadyPods:Betahttps://github.com/kubernetes/enhancements/issues/2879 -
IndexedJob:Stablehttps://github.com/kubernetes/enhancements/issues/2214 -
SuspendJob:Stablehttps://github.com/kubernetes/enhancements/issues/2232
-
-
StatefulSet
-
MaxUnavailableStatefulSet:Alphahttps://github.com/kubernetes/enhancements/issues/961
-
注意点
JobTrackingWithFinalizersで k8s v1.23 で Beta となり、デフォルトで有効化されていましたが未解決のバグがあるため、Beta ですがデフォルトで無効化されました。
この変更については、k8s v1.23 に対してもバックポートが検討されていますが、2022/5/9時点ではまだ未対応になります。k8s v1.23 を利用する際には、--feature-gates=JobTrackingWithFinalizers=falseで無効化することを検討してください。詳細についてはこちらをご確認ください。
上記のうちで今回追加されたCronJobTimeZoneとMaxUnavailableStatefulSetについてもう少し詳しく記載します。その他の機能については、過去のSIG-Apps の変更内容をご確認下さい。
Job
TimeZone support in CronJob
Cornjob の spec.timeZone にタイムゾーンを指定することで、指定したタイムゾーンに基づき、Job を開始してくれる機能になります。
- 関連情報
| KEP | KEP-3140 |
|---|---|
| Feature stage | Alpha |
| Feature Gate | CronJobTimeZone |
| issue | #3140 |
| PR | #104915 |
| 参考 | 公式ドキュメント |
実際の使用イメージ (クリックすると開きます)
- explain で確認すると CronJob に
spec.timeZoneが追加されていることが確認できます。
$ kubectl explain cronJob.spec.timeZone
KIND: CronJob
VERSION: batch/v1
FIELD: timeZone <string>
DESCRIPTION:
The time zone for the given schedule, see
https://en.wikipedia.org/wiki/List_of_tz_database_time_zones. If not
specified, this will rely on the time zone of the kube-controller-manager
process. ALPHA: This field is in alpha and must be enabled via the
`CronJobTimeZone` feature gate.
spec.timeZone が未指定の場合は、 kube-controller-manager のプロセスの Timezone で動作します。
- 以下のように
spec.timeZoneを指定したマニフェストを作成
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "15 18 * * *"
timeZone: "Asia/Tokyo" <- timezoneを指定するフィールドが新たに追加されました
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
-
--feature-gates=CronJobTimeZone=trueのクラスタにマニフェストを適用
$ kubectl apply cronjob.yaml
cronjob.batch/hello created
-
timeZoneを指定したCronjobを作成できることが確認できます。
$ kubectl get cronjob hello -o yaml | kubectl neat
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
namespace: default
spec:
concurrencyPolicy: Allow
failedJobsHistoryLimit: 1
jobTemplate:
metadata:
creationTimestamp: null
spec:
template:
metadata:
creationTimestamp: null
spec:
containers:
- command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
image: busybox
imagePullPolicy: IfNotPresent
name: hello
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: OnFailure
schedulerName: default-scheduler
terminationGracePeriodSeconds: 30
schedule: 20 15 * * *
successfulJobsHistoryLimit: 3
suspend: false
+ timeZone: Asia/Tokyo
$ kubectl get cronjob,po
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
cronjob.batch/hello 20 15 * * * False 0 2m16s 3m28s
NAME READY STATUS RESTARTS AGE
pod/hello-27534620-njvpl 0/1 Completed 0 2m16s
- podの
Start Timeを確認すると、指定したtimeZoneでPodが起動したことを確認できます。
$ kubectl describe po hello-27534620-njvpl
Name: hello-27534620-njvpl
Namespace: default
Priority: 0
Node: kind-worker/172.18.0.3
+Start Time: Mon, 09 May 2022 15:20:00 +0900
Labels: controller-uid=64f8fcc8-236c-415c-8ee0-87a1c0449f50
job-name=hello-27534620
Annotations: <none>
Status: Succeeded
IP: 10.244.2.2
IPs:
IP: 10.244.2.2
Controlled By: Job/hello-27534620
Containers:
hello:
Container ID: containerd://60e2b1727b61cbfcf976ef3a8f1b23fea1cc26f5264a4d8b7beb71cc7d2dd18e
Image: busybox
Image ID: docker.io/library/busybox@sha256:d2b53584f580310186df7a2055ce3ff83cc0df6caacf1e3489bff8cf5d0af5d8
Port: <none>
Host Port: <none>
Command:
/bin/sh
-c
date; echo Hello from the Kubernetes cluster
State: Terminated
Reason: Completed
Exit Code: 0
+ Started: Mon, 09 May 2022 15:20:06 +0900
Finished: Mon, 09 May 2022 15:20:06 +0900
Ready: False
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-92hb8 (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
kube-api-access-92hb8:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 62s default-scheduler Successfully assigned default/hello-27534620-njvpl to kind-worker
Normal Pulling 62s kubelet Pulling image "busybox"
Normal Pulled 56s kubelet Successfully pulled image "busybox" in 6.019896602s
Normal Created 56s kubelet Created container hello
Normal Started 56s kubelet Started container hello
StatefulSet
Implement maxUnavailable in StatefulSet
StatefulSet で maxUnavailable を指定したローリングアップデートができるようになります。
複数の Pod が同時にダウンしても大丈夫なアプリケーションで maxUnavailable を使用することにより、ローリングアップデートにかかる時間の短縮が期待できます。(例えば一意のホスト名で動作させるためだけに StatefulSet を利用している場合など)
- 関連情報
| KEP | KEP-961 |
|---|---|
| Feature stage | Alpha |
| Feature Gate | MaxUnavailableStatefulSet |
| issue | #961 |
| PR | #82162 |
| 参考 | 公式ドキュメント |
実際の使用イメージ (クリックすると開きます)
- explain で確認すると StatefulSet に
spec.updateStrategy.rollingUpdate.maxUnavailableが追加されていることが確認できます。
$ kubectl explain statefulset.spec.updateStrategy.rollingUpdate
KIND: StatefulSet
VERSION: apps/v1
RESOURCE: rollingUpdate <Object>
DESCRIPTION:
RollingUpdate is used to communicate parameters when Type is
RollingUpdateStatefulSetStrategyType.
RollingUpdateStatefulSetStrategy is used to communicate parameter for
RollingUpdateStatefulSetStrategyType.
FIELDS:
maxUnavailable <string>
The maximum number of pods that can be unavailable during the update. Value
can be an absolute number (ex: 5) or a percentage of desired pods (ex:
10%). Absolute number is calculated from percentage by rounding up. This
can not be 0. Defaults to 1. This field is alpha-level and is only honored
by servers that enable the MaxUnavailableStatefulSet feature. The field
applies to all pods in the range 0 to Replicas-1. That means if there is
any unavailable pod in the range 0 to Replicas-1, it will be counted
towards MaxUnavailable.
partition <integer>
Partition indicates the ordinal at which the StatefulSet should be
partitioned for updates. During a rolling update, all pods from ordinal
Replicas-1 to Partition are updated. All pods from ordinal Partition-1 to 0
remain untouched. This is helpful in being able to do a canary based
deployment. The default value is 0.
上記のようにpartitionしかなかったところに、maxUnavailableが指定できるようになりました。
maxUnavailableには上記の説明にあるように、絶対値(ex: 5)かパーセント(ex: 10%)で値を指定でき、デフォルト値は1になります。
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
updateStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 3 <- maxUnavailableを指定するフィールドが新たに追加されました
serviceName: web
replicas: 10
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.20
lifecycle:
preStop:
exec:
command: ["sh", "-c", "sleep 30"] <- 確認しやすいように、presStopでsleepを追加
-
--feature-gates=MaxUnavailableStatefulSet=trueのクラスタにマニフェストを適用
$ kubectl apply statefulset.yaml
statefulset.apps/web created
-
maxUnavailableを指定したStatefulSetを作成できることが確認できます。
$ kubectl get sts web -o yaml | kubectl neat
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
namespace: default
spec:
podManagementPolicy: OrderedReady
replicas: 10
revisionHistoryLimit: 10
selector:
matchLabels:
app: nginx
serviceName: web
template:
metadata:
annotations:
kubectl.kubernetes.io/restartedAt: "2022-05-09T15:58:28+09:00"
creationTimestamp: null
labels:
app: nginx
spec:
containers:
- image: nginx:1.20
imagePullPolicy: IfNotPresent
lifecycle:
preStop:
exec:
command:
- sh
- -c
- sleep 30
name: nginx
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
terminationGracePeriodSeconds: 30
updateStrategy:
rollingUpdate:
+ maxUnavailable: 3
partition: 0
type: RollingUpdate
- Statefulset で指定した Pod が全て Running になっていることを確認
$ kubectl get sts,po
NAME READY AGE
statefulset.apps/web 10/10 13s
NAME READY STATUS RESTARTS AGE
pod/web-0 1/1 Running 0 11s
pod/web-1 1/1 Running 0 9s
pod/web-2 1/1 Running 0 8s
pod/web-3 1/1 Running 0 7s
pod/web-4 1/1 Running 0 6s
pod/web-5 1/1 Running 0 5s
pod/web-6 1/1 Running 0 4s
pod/web-7 1/1 Running 0 3s
pod/web-8 1/1 Running 0 2s
pod/web-9 1/1 Running 0 1s
-
kubectl rolloutを使ってローリングアップデートを実施します。
$ kubectl rollout restart StatefulSet web
statefulset.apps/web restarted
-
spec.updateStrategy.rollingUpdate.maxUnavailableで指定した数が同時にTerminatingになることを確認
$ kg po
NAME READY STATUS RESTARTS AGE
pod/web-0 1/1 Running 0 43s
pod/web-1 1/1 Running 0 41s
pod/web-2 1/1 Running 0 40s
pod/web-3 1/1 Running 0 39s
pod/web-4 1/1 Running 0 38s
pod/web-5 1/1 Running 0 37s
pod/web-6 1/1 Running 0 36s
pod/web-7 1/1 Terminating 0 35s
pod/web-8 1/1 Terminating 0 34s
pod/web-9 1/1 Terminating 0 33s
$ kg po
NAME READY STATUS RESTARTS AGE
pod/web-0 1/1 Running 0 90s
pod/web-1 1/1 Running 0 88s
pod/web-2 1/1 Running 0 87s
pod/web-3 1/1 Running 0 86s
pod/web-4 1/1 Terminating 0 85s
pod/web-5 1/1 Terminating 0 84s
pod/web-6 1/1 Terminating 0 83s
pod/web-7 1/1 Running 0 33s
pod/web-8 1/1 Running 0 32s
pod/web-9 1/1 Running 0 31s
- ローリングアップデートが完了
$ kubectl get po
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 5m1s
web-1 1/1 Running 0 5m35s
web-2 1/1 Running 0 5m34s
web-3 1/1 Running 0 5m33s
web-4 1/1 Running 0 6m9s
web-5 1/1 Running 0 6m8s
web-6 1/1 Running 0 6m7s
web-7 1/1 Running 0 6m43s
web-8 1/1 Running 0 6m42s
web-9 1/1 Running 0 6m41s
AGE の値を見ると、maxUnavailable で指定した 3 と同じ数の Pod が Terminating となり、 PreStop で sleep させた 30秒後に、次の3つの Pod が Terminating なっていることがわかる。
現時点の機能では、以下の条件全てに該当するときに利用すると効果的な機能かと思います。
- StatefulSet のローリングアップデートの時間を短縮したい
- 複数の Pod が同時にダウンしても大丈夫なアプリケーション。ローリングアップデート時の停止順がホスト名のインデックスの降順であることにも注意が必要
上記に以外のケースだとデータの整合性等の課題が考えられるので maxUnavailable の値はデフォルトの 1 で動作させて動作させておいたほうが良いかなと思います。
v1.24 Release Notes
v1.24 Release Notes の中で SIG-Apps に関するものについて以下に和訳したものを記載します。
がついた文章は、CHANGELOGの公式内容ではなく筆者の補足です。
 Deprecation(非推奨)
Deprecation(非推奨)
特になし
 API Changes(API変更)
API Changes(API変更)
-
STS の available replicas を再び optional にしました。 (#109241, @ravisantoshgudimetla) [SIG API Machinery and Apps]
-
StatefulSetに
minReadySecondsの機能を追加する際に追加されたavailableReplicasが必須になっていましたが、必須である必要がないのでoptionalに変更されました。
-
-
非推奨となっていた kube-controller-manager flag
--deployment-controller-sync-periodが削除されました。今後は deployment controller で使用できなくなります。 (#107178, @SataQiu) [SIG API Machinery and Apps] -
Indexed Jobs が stable となりました。(#107395, @alculquicondor) [SIG Apps, Architecture and Testing]
-
JobReadyPods が Beta となりデフォルトで有効となりました。(#107476, @alculquicondor) [SIG API Machinery, Apps and Testing]
-
StatefulSets で MaxUnavailable で許容することにより RollingUpdate 時に一度に1個以上の Pod の停止を許容することでより早く実行できるようになります。RollingUpdate に停止できる Pod の数は maxUnavailable のパラメータの設定します。 (#82162, @krmayankk) [SIG API Machinery and Apps]
-
IdentifyPodOS feature が beta になりました。 (#107859, @ravisantoshgudimetla) [SIG API Machinery, Apps, Node, Testing and Windows]
-
pod.Spec.OSに関する変更になります。クラスタ上のノードの OS に Linux と Windows が混在している場合に使用する機能になります。
-
-
gRPC probes のサポートが beta になりました。 GRPCContainerProbe feature gate はデフォルトで有効になります。 (#108522, @SergeyKanzhelev) [SIG API Machinery, Apps, Node and Testing]
-
gRPC のプローブが追加される話になります。この機能が導入される以前は以下のブログを見て grpc_health_probe を利用するなどの対応が必要だったのでだいぶ使いやすくなるかなと思います。
https://kubernetes.io/blog/2018/10/01/health-checking-grpc-servers-on-kubernetes/ -
blackbox_exporter の 0.20.0(2022/03/16 リリース) で以下の PR の grpc health check が追加されたので、gRPC を利用するための環境がここ1,2ヶ月でだいぶ改善されたのかなと思います。
https://github.com/prometheus/blackbox_exporter/pull/835
-
-
CronJob の spec に optional で
timeZoneがサポートされました。これにより cron job が特定の time zone で動作するようになります。(#108032, @deejross) [SIG API Machinery and Apps]-
紆余曲折ありましたが、Cron Job での Time zone の指定がコミュニティとして正式にサポートされました。まだ Alpha ですが今後、順調に Beta、Stable になっていくことを期待しています。
-
-
PodOverheadが GA になりました。 (#108441, @pacoxu) [SIG API Machinery, Apps, Node and Scheduling] -
v1beta1 PodDisruptionBudget での
selectorfield に対する "strategic merge patch" の API requests の動作を修正します。 1.21 より前ではこれらのリクエストはmatchLabelsの content をマージしmatchExpressionsの content を置き換えていました。1.21 ではselectorfield にアクセスする patch requests が全体の selector を置き換え始めました。これは v1 PodDisruptionBudget の server-side apply の動作としては遺憾性がありますが、 v1beta1 で入れるべき変更ではありませんでした。 (#108138, @liggitt) [SIG Apps, Auth and Testing] -
Suspend job が GA になりました。SuspendJob の feature gate はロックされ、1.26 で削除予定になります。 (#108129, @ahg-g) [SIG Apps and Testing]
 FEATURE(機能追加)
FEATURE(機能追加)
- v1.22 から GA になっている
NamespaceDefaultLabelNameの feature gate が削除されました。 (#106838, @mengjiao-liu) [SIG Apps and Node]
 Documentation(ドキュメント改善)
Documentation(ドキュメント改善)
特になし
 ENHANCEMENT(機能改善)
ENHANCEMENT(機能改善)
特になし
 BUGFIX(バグ修正)
BUGFIX(バグ修正)
-
未解決の bug のため、JobTrackingWithFinalizers は beta ですが default で disabled となります。 (#109487, @alculquicondor) [SIG Apps and Testing]
-
本来、job を実行中の Pod にのみ付与されるはずの finalizer が backoff limit に達して、失敗し Pod にも付与されるままになっているバグが未修正のため、JobTrackingWithFinalizers がデフォルトで無効化されました。
-
こちらの PR でバグについては修正予定になります。こちらの修正は kubernetes v1.25 から反映される予定です。
-
v1.23 についてはこちらの PR で default で disabled になることが検討されています。
-
JobTrackingWithFinalizers は v1.23 から Beta となりデフォルトで有効化されているので、k8s v1.23 を利用される方は、無効化することを検討して下さい。
issue では以下のような再現の例が書かれてますが、backoffLimit に達しやすい job (backoffLimit で指定している値が小さいなど)のケースで再現しやすい事象かと思います。spec: backoffLimit: 0 completionMode: Indexed completions: 5000 parallelism: 5000 status: completedIndexes: 0-4003,4005 conditions: - lastProbeTime: "2022-04-14T14:09:23Z" lastTransitionTime: "2022-04-14T14:09:23Z" message: Job has reached the specified backoff limit reason: BackoffLimitExceeded status: "True" type: Failed failed: 1 startTime: "2022-04-14T13:57:54Z" succeeded: 4005 uncountedTerminatedPods: {}
-
-
jobが削除される時に job controller が Pod から job tracking finalizer を削除せずに、 pod が孤立する問題を解消。 (#108752, @alculquicondor) [SIG Apps and Testing]
-
こちらもこの PR で v1.23 に Cherry pick 予定です。
-
上記の issue もあるので v1.23 を利用する際は JobTrackingWithFinalizers を無効化を検討してください。
-
-
attachdetach controller が kube-apiserver のエラーを適切に処理しなかったため、attachments/detachments のスタックにつながるバグを修正しました。 (#108167, @jfremy) [SIG Apps]
-
API で他の Pod が complete と報告を受けた後に、すぐにスケジュールされると OutOfCpu errors として正しくない理由で拒否されるバグが修正されました Kubelet は全ての実行中の Pod が停止され、新しい Pod が起動できなくなるまで pod の phase を報告するのを待ちます。この変更により、短命の Pods の場合は Succeeded か Failed の報告が少し(~1s)遅れるようになります。 (#108366, @smarterclayton) [SIG Apps, Node and Testing]
-
以前、クラスタのリソースで一度に処理しきれない大量の Job を実行した際に、Pending になっていたいくつかの Pod が OutOfCpu で失敗になったのはこのバグが原因だったんだなと思いました。
-
-
CronJob Controller V2 で job template の labels 変更されると追跡できなくなるバグが変更されました。 (#107997, @d-honeybadger) [SIG Apps]
-
この bug 修正は v1.21,v1.22,v1.23にもバックポートされる予定です。
-
-
basic-auth と ssh secret validations 時のエラーメッセージの修正 (#106179, @vivek-koppuru) [SIG Apps and Auth]
 Other (その他の修正)
Other (その他の修正)
所感
今回の大きな変更は以前より、ずっと要望が上がっていた CronJob の TimeZone 対応がついにコミュニティとして対応されて、 Alpha で導入されたことかなと思います。これで CronJob Controller の v2 対応に伴う一連の Job に関する機能追加については一段楽したので、今後は暫く sig-apps での大きな機能追加はなく、成熟度をあげるフェイズになるかと思います。