OthloTech Advent Calendar 2018
オスロテック アドヴェント・カレンダー2018企画
自己紹介(About me)
Name: Yosiyoshi
(Twitter: https://twitter.com/yosiyos38795255, GitHub: https://github.com/yosiyoshi)
はじめまして、Yosiyoshiと申します。
最近GitHubを始めました。Pythonコーダーです。
さて、作品はGitHubアカウントにいくつかのレポジトリがあります。深層学習の他、自然言語処理やドローンプログラミング、そしてWeb開発など、Pythonの機能はあらかた試しているところです。
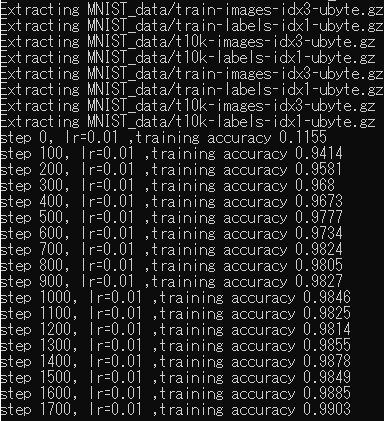
一つはTensorFlowとPyTorchの、それぞれ、MNISTとDDQNの実装です。
スコアはMNISTが精度0.9903(step 17)、DDQNがCartPoleで1エポックの自己最高記録1000秒超えました。中関村の友人との交流には感謝しています。
そこで、今回は「YoshiNet」という作品集の一部として、GitHub上で公開しているDDQNによるCartPoleの実装についての記事です:
DQNとDDQNについて
(English, Chinese versions are available on my YoshiNet page on github.com)
Deep Q-networkは強化学習の一種。任意回数の試行錯誤を経て学習データを更新し、スコア最大化の目的で自らを最適化するアルゴリズム、または深層学習の手法で実装したニューラルネットワークの名称。Double DQNは、以前の学習データをディープコピーし、それを定期的に学習データへフィードバックする手法。
元となったコード
"PyTorch Intermediate Tutorials"のDQN実装をベースとしています:
http://pytorch.org/tutorials/intermediate/reinforcement_q_learning.html
実験内容
元となるDeep Q-networkの実装は、PyTorchのドキュメンテーションにあるコードをベースとします。
PyTorchはDefine-by-runを特徴としており、ちょうどChainerと同様の感覚でコーディングできます。そして、Double DQN(DDQN)への書き換えは、コード量としては僅かで済むのですが、その効果として、後半になればなるほど、AIはゲームの特徴を学習し、高いスコアを挙げることが期待されます。これが深層学習と強化学習の手法を組み合わせる意義ではないでしょうか。
ニューラルネットワークの記述は以下の通りです。
class DQN(nn.Module):
def __init__(self):
super(DQN, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=5, stride=2)
self.bn1 = nn.BatchNorm2d(16)
self.conv2 = nn.Conv2d(16, 32, kernel_size=5, stride=2)
self.bn2 = nn.BatchNorm2d(32)
self.conv3 = nn.Conv2d(32, 64, kernel_size=5, stride=2)
self.bn3 = nn.BatchNorm2d(64)
self.head = nn.Linear(896, 2)
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
return self.head(x.view(x.size(0), -1))
PyTorchのサンプルからの変更箇所は
・deepcopy()の追加
・定期的に学習データのフィードバックを促す条件分岐
・学習データ更新に関するコード
の追加、以上三点です。
model = DQN()
q_ast = deepcopy(model)
先に定義したDQN()をmodelとして定義し、deepcopy()関数に複製されたmodelをq_astに代入します。
def optimize_model():
global last_sync
q_ast = model
モデルの最適化に、前出のq_astを用います。
そして、次の状態(next_state_values)を、次のように定義します:
next_state_values[non_final_mask] = q_ast(non_final_next_states).max(1)[0]
この部分はもともと、
next_state_values[non_final_mask] = model(non_final_next_states).max(1)[0]
という記述でした。ここでは、model()によって次の状態を予測しています。
つまりこの書き換えにより、次の状態の予測にq_astが利用されるようになったのです。
そして、q_astの更新頻度を定義する変数は
UPDATE_TARGET_Q_FREQ = 3
であり、
if num_episodes % UPDATE_TARGET_Q_FREQ == 0:
q_ast = deepcopy(model)
のように、全体のエピソード数がUPDATE_TARGET_Q_FREQで割り切れるとき(つまり倍数であるとき、あるいはUPDATE_TARGET_Q_FREQ回ごとに)、q_astの更新が行われます。
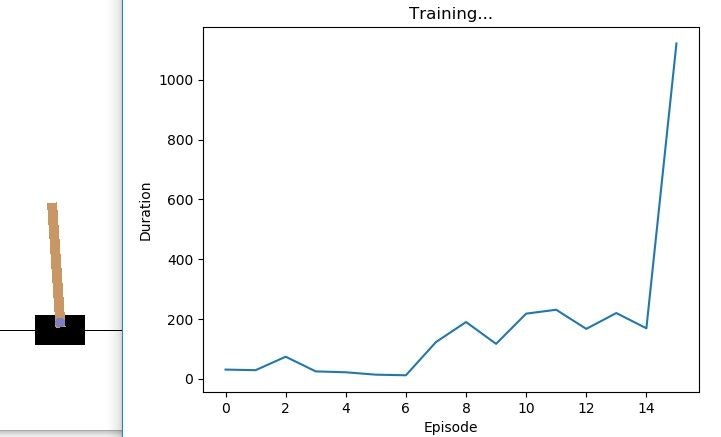
・・・で、結果を見ていただければご実感頂けると思いますが、第5-15エポックで結果が飛躍的に上昇します。なぜかは分かりません、無意識です。なので、東方キャラになぞらえて「こいし」とでも名付けましょう。
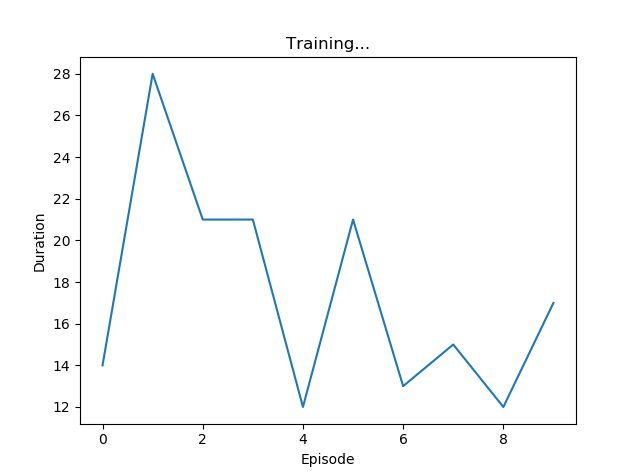
実験結果
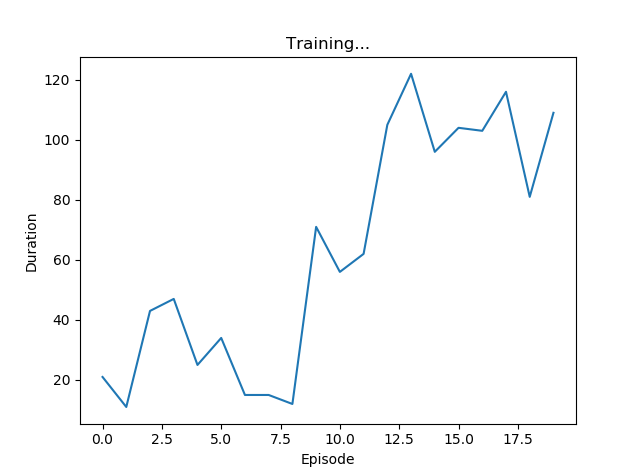
PyTorch サンプルのDQN
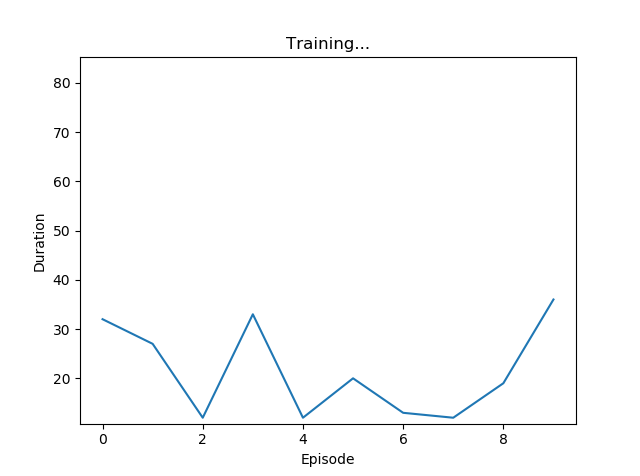
"Koishi" DDQN
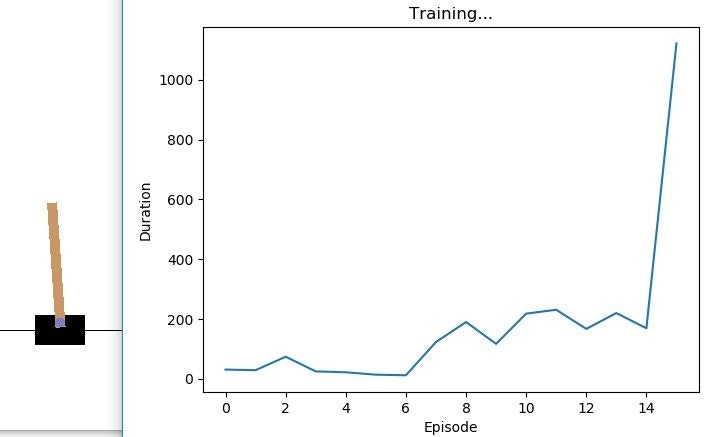
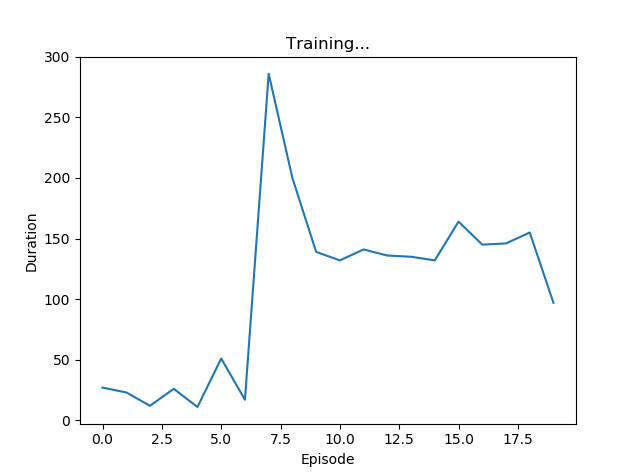
はい。桁違いですね。
さらなる改良:とりあえず倍プッシュ
しかし、妹分がいるからには姉分も欲しい。そこでさっきのKoishiを改良してみましょう。
https://github.com/yosiyoshi/YoshiNet/blob/master/ddqn.py
class DQN(nn.Module):
def __init__(self):
super(DQN, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=5, stride=2)
self.bn1 = nn.BatchNorm2d(16)
self.conv2 = nn.Conv2d(16, 32, kernel_size=5, stride=2)
self.bn2 = nn.BatchNorm2d(32)
self.conv3 = nn.Conv2d(32, 64, kernel_size=5, stride=2)
self.bn3 = nn.BatchNorm2d(64)
self.head = nn.Linear(896, 2)
ではノード数を二倍にします。
https://github.com/yosiyoshi/YoshiNet/blob/master/ddqn2.py
class DQN(nn.Module):
def __init__(self):
super(DQN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=5, stride=2)
self.bn1 = nn.BatchNorm2d(32)
self.conv2 = nn.Conv2d(32, 64, kernel_size=5, stride=2)
self.bn2 = nn.BatchNorm2d(64)
self.conv3 = nn.Conv2d(64, 128, kernel_size=5, stride=2)
self.bn3 = nn.BatchNorm2d(128)
self.head = nn.Linear(1792, 2)
こんだけです。後は様子を見ましょう。
比較
では妹分"Koishi"と姉分"Satori"の対決。
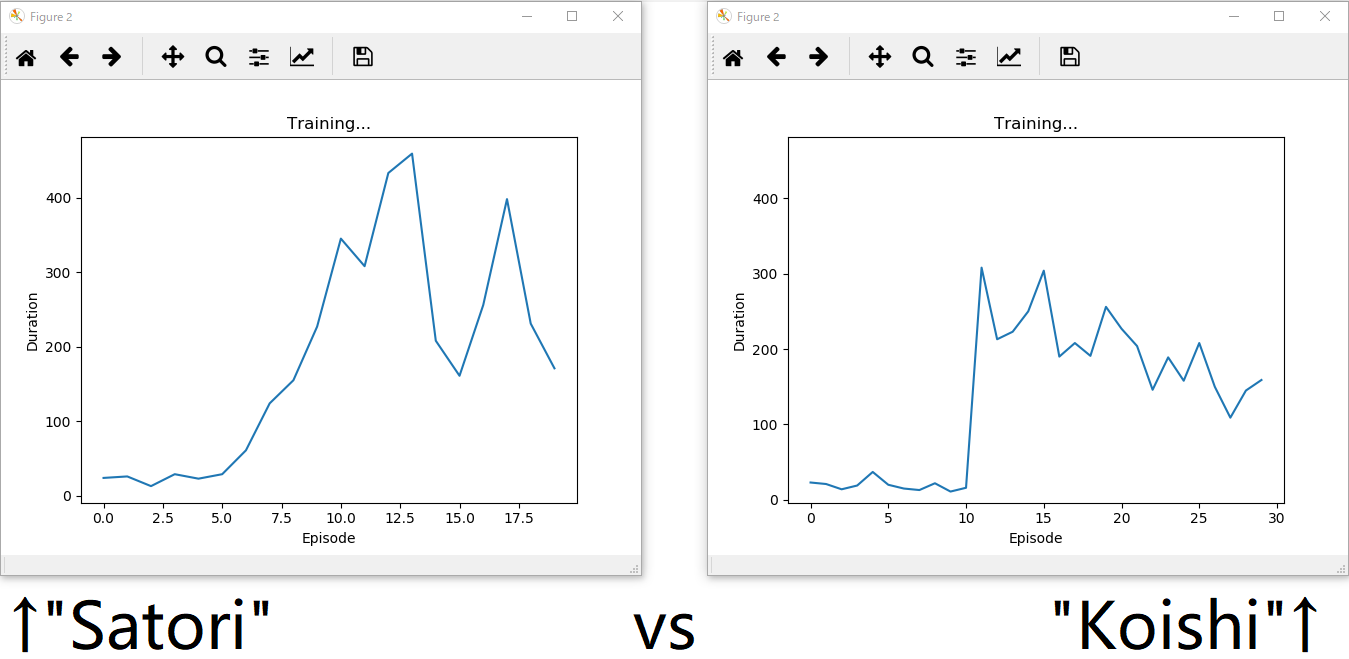
"Satori"が勝ちました。
あとがき
この記事の筆者は文系学生であり、強化学習を専攻しているわけではありません。従って、各位ご専門の観点から本記事に対するご批判やご指摘を頂いたとして、その全てにお応えできるとは限りません。しかし、このように簡単な工夫が性能を大きく左右するのが、深層学習系のコーディングで最も醍醐味といえる部分ではないでしょうか。