はじめに
re:Invent 2025 で発表された Amazon Nova Forge は、RAG や既存モデルへのファインチューニングよりも「深い層」で、モデルを自社仕様に寄せるためのサービスです。
現地で新規ローンチされたセッション(AIM3325)を聴講した内容をもとに、要点を整理します。
AWS re:Invent 2025 - Amazon Nova Forge: Build your own frontier models using Amazon Nova (AIM3325)
「Forge」は「鍛造する/作り上げる」等の意味を持ちます。本記事では、Nova を素材として 自社データで鍛え上げるというニュアンスで捉えています(筆者解釈)。
NNova Forge を一言で言えば、Amazon Nova の複数の学習段階チェックポイントを起点に、AWS 側のキュレーションデータと自社データをブレンドしながら独自モデルを育て、完成後は Amazon Bedrock 上でホストして推論利用できるようにする仕組みです。
基盤モデルは高機能ですが、企業固有の知識や文脈まで学習しているわけではありません。そのまま導入しても、企業価値につながる差別化が難しい場面があります。
RAG は「必要な情報を引く」用途で有効ですが、企業知識をモデル自身の知識・理解として定着させるには限界があります。 また、自前で大規模モデルをゼロから構築するのは、データ収集・コスト・期間の面でハードルが高いのが現実です。
そのギャップを埋める選択肢として、Nova Forge が位置づけられています。
企業が直面する LLM カスタマイズの「壁」
もう少し具体的に、課題を掘り下げます。
典型的な2手法
-
RAG(Retrieval-Augmented Generation)
検索(ベクタ検索等)で関連文書を引き当て、プロンプトに添えてモデルへ渡す方式。モデル本体は変えず、知識を外付けする方式。 -
SFT(Supervised Fine-Tuning)
教師ありファインチューニング。入出力ペア(例:問い合わせ→正解応答)でモデルを後段調整する方式。「振る舞い(文体・フォーマット・タスク手順)」の最適化に有効。
セッションでは「RAGは検索と取得の体験に過ぎず、企業の知的財産(IP)の理解がモデル自体に組み込まれていない」という課題が明確に語られていました。
一般的に RAG を採用しているケースが多いと思いますが、次のような要件では、典型手法だけだとコスト・品質面で頭打ちになりやすいです。
壁になりやすい要件
-
業種知識が「考え方/手順」まで必要なケース
ただ文書を渡すだけでは足りず、「どの順で何を確認し、どう判断するか」という 推論手順そのものに専門性が必要。単純なRAGだけでは精度が上がりにくい。 -
レイテンシ要件が厳しいケース
RAGは検索+長文コンテキストが前提になりやすく、リアルタイム性が損なわれます。即応が求められる業務では難しくなります。 -
監査や説明責任を伴うケース
「なぜその答えになったか」だけでなく、「どんなデータで学習したのか」「学習の手順は妥当か」といった透明性が求められます。RAG/SFTだけで“説明可能性”を満たす設計は難易度が上がります。
Nova Forgeの3つのキー要素
ここから Nova Forge の中身について見ていきましょう。
チェックポイント(事前学習/中間学習/事後学習)
ゼロからの学習ではなく、AWSが事前に学習したモデル(Nova)の途中から学習を着手可能。データ量や形式に応じた柔軟性を持つことができます。
セッションでも、foundation model が「事前学習 → 中間学習 → 事後学習(SFTや強化学習)」の段階で作られること、その各段階を起点にできることが説明されています。

データミキシング
自社データと Amazon Nova の高品質なキュレーションデータを、最適な比率で混合します。
既存の知識を残しつつ領域特化を進めることで、一般能力の低下(破滅的忘却 / catastrophic forgetting)を抑える狙いです。

RFT & Responsible AI
Nova Forge は、教師ありの CPT(Continued Pre-Training)だけでなく、強化学習(Reinforcement Fine-Tuning)向けの機能も統合しています。
- 自社のシステムやシミュレーション環境を「報酬関数の計算先」として組み込み
- 複数ターン対話や長時間処理を伴う評価も実行可能
- 学習基盤として SageMaker AI HyperPod を用いた大規模分散トレーニングを想定
また、Responsible AI toolkit も含まれます。
- 安全性・コンプライアンスを考慮した学習用データテンプレート
- 推論時のコンテンツ制御・モデレーション設定
- 不適切な出力を抑制する学習レシピ
などが提供され、トレーニング時・推論時の両方で安全性ガードレールを組み込みやすくなっています。
参照アーキテクチャ
Nova Forge は「学習」だけでなく、データ準備 → 学習 → 評価 → 推論運用 → 改善が一連で回る前提のサービスです。推論側は、SageMaker AIでカスタマイズした Nova を Amazon Bedrock のカスタムモデルとして取り込んで推論することができます。

評価運用設計
モデルは「作って終わり」ではなく、品質を測る → 更新しても壊れていないか確認する → 事故を防ぐを繰り返します。そのために押さえるべきポイントは、大きく次の3つです。
- 評価設計(成功指標と合格ラインを決める)
精度だけではなく、業務が改善したかを測定します。務成果(時間・コスト・リスク)に接続する指標を入れておきます。- 正答率/再現率:回答が正しいか、必要情報を落としていないか
- 作業時間削減:調査・対応がどれだけ短縮されたか
- 監査指摘件数:規程違反や危険回答が減ったか
一次回答での自己解決率:再問い合わせが減ったか
- データ準備(混ぜて良いデータを守り、評価の正しさを守る)
- 機密・PII(個人情報)・著作権の分類と除外/匿名化方針
- 学習/評価のデータリーク対策
- どのデータが有効か(高品質な手順書、レビュー済み設計書など)
- 運用設計(更新しても戻せる・説明できる仕組みにする)
- モデルのバージョン戦略:いつ更新するか、誰が承認するか
- ロールバック手順:問題発生時もとに戻せるか
- 監査証跡:学習データの出所、学習レシピ、評価結果を記録
How to use
SageMaker AI のメニューから Nova Forgeを選択します。

2025/12時点では US East (N. Virginia) で提供開始。今後拡大予定。
コストについて
Nova Forge は年額のサブスクリプションモデルで、$100,000/年/payer accountとなり、これに加えてトレーニング用の計算リソースコストや推論時のBedrockやNovaの利用料金、その他のインフラコストが必要になります。
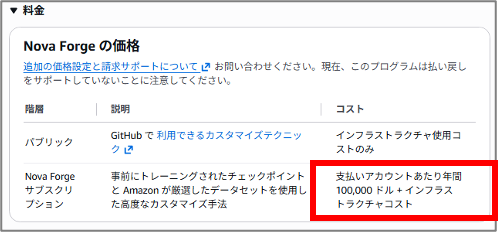
フルスクラッチでの研究開発コスト(数百万〜数千万ドル規模)と比較すれば、現実的なレンジに下りてきた、という見方はできます。
どんな企業が導入に向いているか
Nova Forge の導入が適しているのは、次の条件が揃う企業ではないでしょうか。
- 競争力や価値の源泉である独自データがある
- RAG/SFTだけでは満たせない要求がある
- 推論手順までドメイン化したい
- レイテンシが厳しい
- 監査・説明責任が強い
- 評価 → 改善 → 再学習を回すための運用体制がある
逆に、社内FAQやナレッジ検索中心なら、RAG最適化(検索品質・要約・プロンプト・評価)で十分なことが多く、Forgeはオーバースペックになると思います。
まとめ
「基盤モデルの良さを保ったまま、自社ドメインの知識をモデル側に取り込む」という選択肢として登場したのが Nova Forge です。
Nova Forge の価値は、基盤モデルが持つ推論力・汎用知識の土台を活かしつつ、自社ドメインに特化した知識を埋め込める点にあります。さらに、AWS エコシステムと統合しやすい形で運用設計できることも、現場にとっては実務上のメリットになり得ます。
もちろん、フルスクラッチでモデルを一から作る世界と比べれば、Nova Forge は現実的なコストレンジに降りてきています。とはいえ、ここが重要で、「圧倒的に安い」=「誰にでもお得でメリットがある」ではありません。
Nova Forge の導入で効果を得やすいのは、メガバンクなどの金融機関、グローバル製造業、専門データが豊富で研究開発を行う化学産業のように、専門知識そのものが競争力になっていて、しかも扱うデータの量と質が揃っているドメインです。こうした企業・プロダクトでは、モデルにドメイン知識を取り込むことが、他社との差別化に直結しやすく、投資として成立しやすいといえるでしょう。
一方、社内ナレッジ検索や FAQ、限定された業務システムの問い合わせ対応のような用途では、Nova Forgeの適用はオーバースペックになりがちです。
Nova Forge の導入を検討するなら、少なくともビジネスインパクト、データの量や質、データガバナンスやコンプライアンスの観点で冷静に検討すべきです。
くれぐれも、個人で 10 万ドルをポチッとしないように気をつけましょう(笑)