本稿では、生成AIのニーズのために新たに開発されたLangStreamプロジェクトを紹介します。
LangStreamにより、LLMアプリケーションの典型的な処理を、Apache Pulsarファンクションとして組み込むことが容易になり、LLMをリアルタイムイベント処理と組み合わせることが可能になります。また、後述のStarlight for Kafkaを用いることで、Kafkaクライアントとの組み合わせも可能です。
以下の記事は、LangStreamの公式ドキュメントの内容をソースとしています。
LangStreamとは何か?
LangStream は AI の導入を推進するオープンソース プロジェクトです。
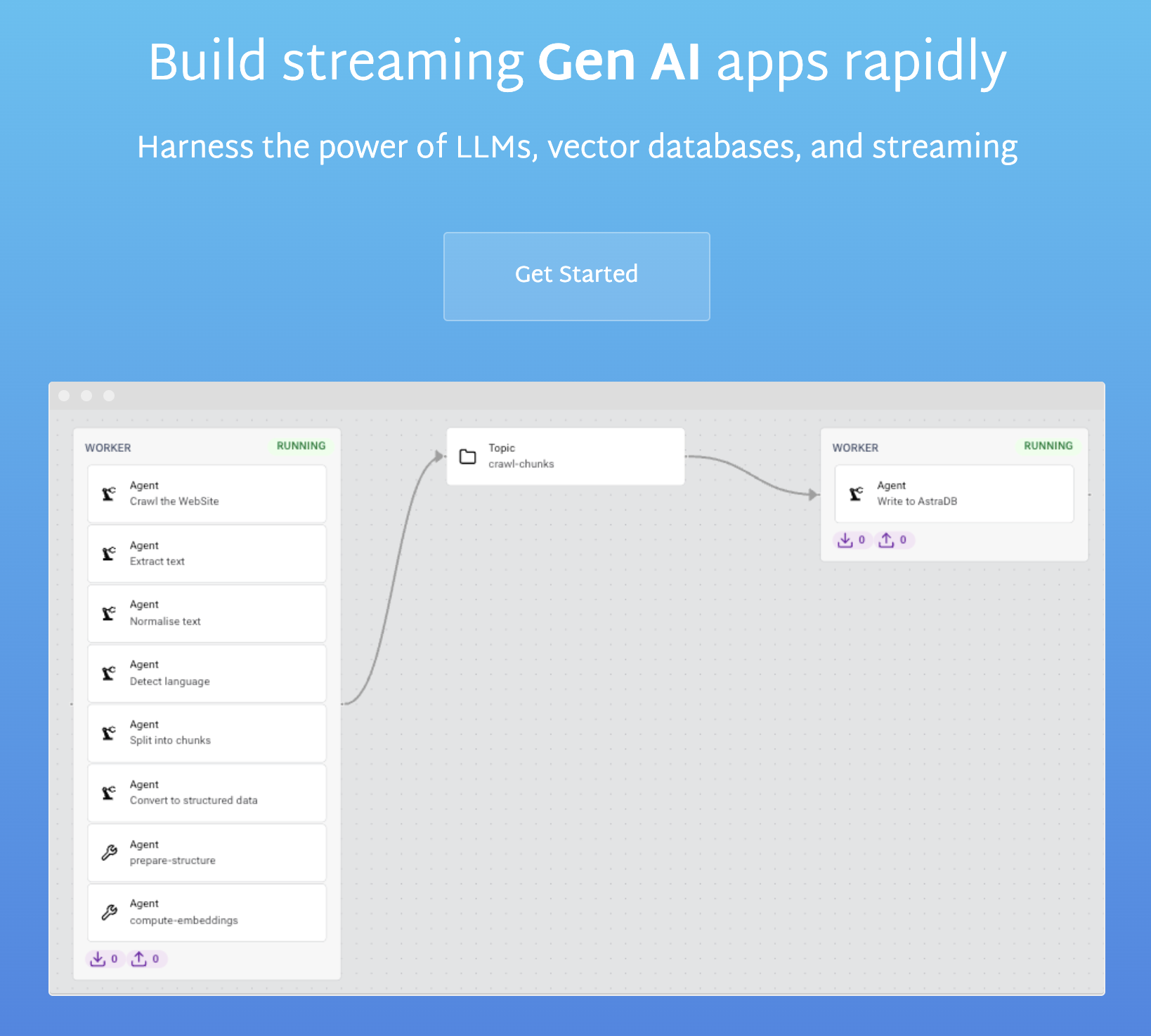
LangStream プロジェクトは、LLM(大規模言語モデル)のインテリジェンスとストリーミング処理の機敏性を組み合わせて、アプリケーションを作成します。
LangStream のアプリケーションは、メッセージ トピックを監視し、複数のステップを通じてデータを処理して、有用な生成 AI 結果を出力します。
LangStreamをつかうことで、チャットボットなどの生成 AI プロジェクトの開発に伴うオーバーヘッドを大幅に削減できます。例えば、開発者は、データの変更に応じてベクトル化するステップを持つ、パイプラインを宣言するアプリケーションを作成できます。また、ユーザーの質問を受け取り、それをベクトル化されたデータと比較し、コンテキスト化されたプロンプトを構築し、LLM に送信するアプリケーションを作成することもできます。
パイプラインの各ステップはエージェントに変換されます。エージェントは入力メッセージを受け取り、そのデータを処理し、結果を新しいメッセージとして出力します。処理は、データをすべて小文字に設定するという単純な場合もあれば、ラベル付きの値を削除する命令である場合もあります。あるいは、エンベディングモデルを使用してメッセージ データをエンベディングに変換する生成 AI用処理や、LLM にプロンプトを送信して完了を受け取るなどの、より強力な処理を行うこともできます。
すべてのパイプラインには開始点と終了点があります。ストリーミング データのコンテキストでは、これは通常、ソースとシンクと呼ばれます。ソースは、データベース、別のメッセージ トピック、または開始点トピックのメッセージ データを生成する方法を知っているアプリケーションです。パイプラインには 1 つのソースまたは複数のソースを含めることができます。
LangStream はトランスポートにメッセージ ブローカーのトピックを使用します。
パイプラインがデータを正常に処理したら、それに対して何らかの処理を行う必要があります。こちらはシンクが使われているところです。ソースと同様に、シンクにもさまざまな形状があります。通常、シンクは処理されたデータをデータベースに保存します。パイプラインには 1 つのシンクを接続することも、複数のシンクを接続することもできます。
技術的特徴
- KubernetesやApache Kafkaなどの実証済みのテクノロジーを基盤に構築
- ChatGPTなどの LLM 、 HuggingFaceなどの推論 API 、 AstraDBなどのベクトル データベース、LangChainなどのエージェントとのインテグレーション
- シンプルな宣言型 YAML ファイルを使用して独自のリアルタイム AI アプリケーション パイプラインを作成
- イベント データ、セマンティック検索、データベース クエリなどを組み合わせて、リッチ コンテキストを含むプロンプトを生成するプロンプト テンプレート
- 非構造化データ (PDF、Word、HTML など) および構造化データの処理
- Kafka Connect シンクとソースを実行して外部システムとリアルタイムに統合
- 可観測性のための Prometheus メトリクスと Kubernetes ログ