はじめに
本稿は、次の3部構成からなります。
- Apache Pulsarを扱う前に、メッセージング及びストリーミングテクノロジーの概観からはじめます。
- 次に、Apache Pulsarの解説に進みます。まずPulsarの歴史や現状の概観について触れた後、アーキテクチャーと機能の説明を行います。
ここでは、Apache Pulsarの特徴をより理解しやすいように、先行して登場した技術である、Apache Kafkaとの比較を用いて説明します。 - 最後に、本稿でPulsarに興味を保たれた方が、実際にPulsarを利用するための情報を提供します。
なお、本稿は、DB Tech Showcase 2022の発表内容を元にしています。そちらをご覧になられた方にとっては、基本的には特に新しいところのないものとなっていますが、最後にApache Pulsarのプログラミングの雰囲気を伝えるために、サンプルプログラムコードを掲載しています。この部分だけは、上記イベントでの発表には含まれなかったものとなります。
メッセージングおよびストリーミングテクノロジー概観
メッセージング
メッセージングおよびストリーミングテクノロジーの概観からはじめますが、まずはメッセージング技術の歴史について見ていきます。
ETL, MQ
ここでは、十分な歴史を持ちよく知られている、ETL、について振り返るところから始めたいと思います。
ETLとは、Extract、Transform、Loadの頭文字から取られており、それぞれ、(データの)抽出、変換、登録を意味します。ETLとは何かを事細かに説明することはしませんが、名称自体が十分な説明になっていると考えます。
ETLもメッセージングもシステム間でデータ連携を行うという共通の目的をもつといえます。
ETLは、バッチ処理、つまりマニュアルまたはスケジューリングされたジョブとして実行されるため、リアルタイム性は低く、扱うデータ量は大きいものである傾向があります。
このように、利用者が主体的に実行するプログラムとして、ETLは、しばしばETLツールとも呼ばれます。これに対して、メッセージングを実現するシステムは、他のシステムと協調して動作する、ミドルウェア、であるといえます。
このようなメッセージングミドルウェアについて、初めに、MQ、つまりメッセージキューについて触れます。
MQでは、ソースからターゲットにデータを直接的に渡すのではなく、キューを介してデータをやりとりします。
送信と受信のタイミングが分離している非同期型の通信を実現するものといえます。
メッセージキュー、そしてメッセージングミドルウェアの仕様の詳細は、製品やオープンソースを含む実装において、さまざまに異なりますが、ここでは、メッセージングミドルウェアの本質について目をむけてみたいと思います。
メッセージングミドルウェアを利用する意味
システム間のデータのやりとりに、ミドルウェアを利用しない場合と利用する場合の違いについて、考えてみたいと思います。
- メッセージミドルウェアにより、システム間連携のリアルタイム性を高めることができることは、大きな利点ですが、その他にもさまざまな利点があります。
- まず、ミドルウェアを企業内のシステムで共有することによって、企業全体として、コストが抑えられます。
また、メッセージングミドルウェアを利用することによって、データ連携において、システム間を疎結合に保つことができます。 - ミドルウェアを用いる場合、上流システムのデータソースを、複数の下流システムで共有および再利用できる可能性があります。その場合、ソースシステムに対して、新たな開発の負荷が生じないのみではなく、リリースタイミングなどの影響を抑えることができます。
- また、データのやりとりが、ミドルウェアを介して行われる利点として、上流システムのデータが、突発的に増加した場合にも、ミドルウェアがキューの役割を果たすため、下流システムへの影響を抑えることができる可能性があります。
MQTT, Kafka
次に紹介するのは、MQTT・メッセージング・キューイング・テレメトリー・トランスポートです。
MQTTは、パブサブ型のデータ配信モデルのプロトコルです。
パブサブ型のメッセージングモデルにおいては、メッセージブローカー、つまり仲買人の役割を果たすコンポーネントが存在します。
ブロカーは、メッセージのトピックに基づいて、クライアントにメッセージを配信します。
Apache Kafkaは、MQTTと同じくPub/Sub型のモデルからなります。
Kafkaには、(ここまで説明してきたテクノロジーには見られなかった)分散アーキテクチャーをもつという特徴があります。Kafkaは、オープンソースでもある事から、現在広く使われています。
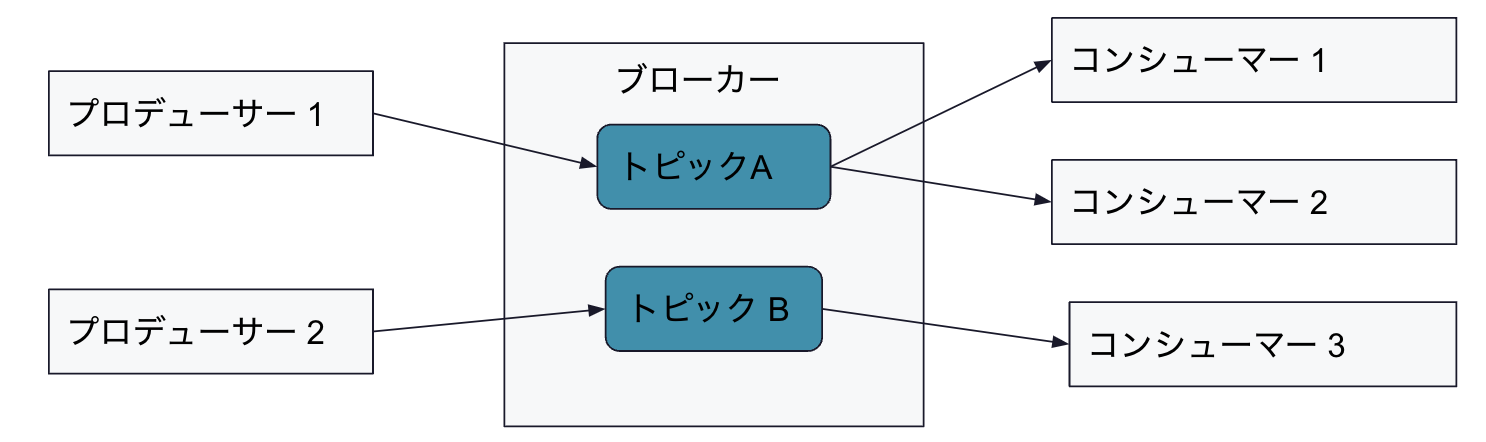
Pub/Subモデル
ここで、Pub/Subモデルについて、整理します。
Pub/Subモデルの特徴は、まず、メッセージ送受信のためのトピックという概念です。
このトピックを介して、メッセージがプロデューサーからコンシューマーへ伝わります。
- プロデューサー、つまりメッセージの生産者は、トピックに対してメッセージをパブリッシュします。
- メッセージの消費者であるコンシューマーは、トピックを指定して、メッセージをサブスクライブします。
プロデューサーとコンシューマーは、メッセージングミドルウェアのクライアントの位置付けになります。
そして、ミドルウェアは、プロデューサーとコンシューマーの間を仲介する役割として、ブローカーの役割を果たします。ブローカーが仲買人としての役割を果たすことにより、プロデューサーとコンシューマーは互いを認識する必要がありません。
ストリーミング
マイクロサービス アーキテクチャ
現在、システムのマイクロサービス化というトピックは、珍しいものではなくなっています。
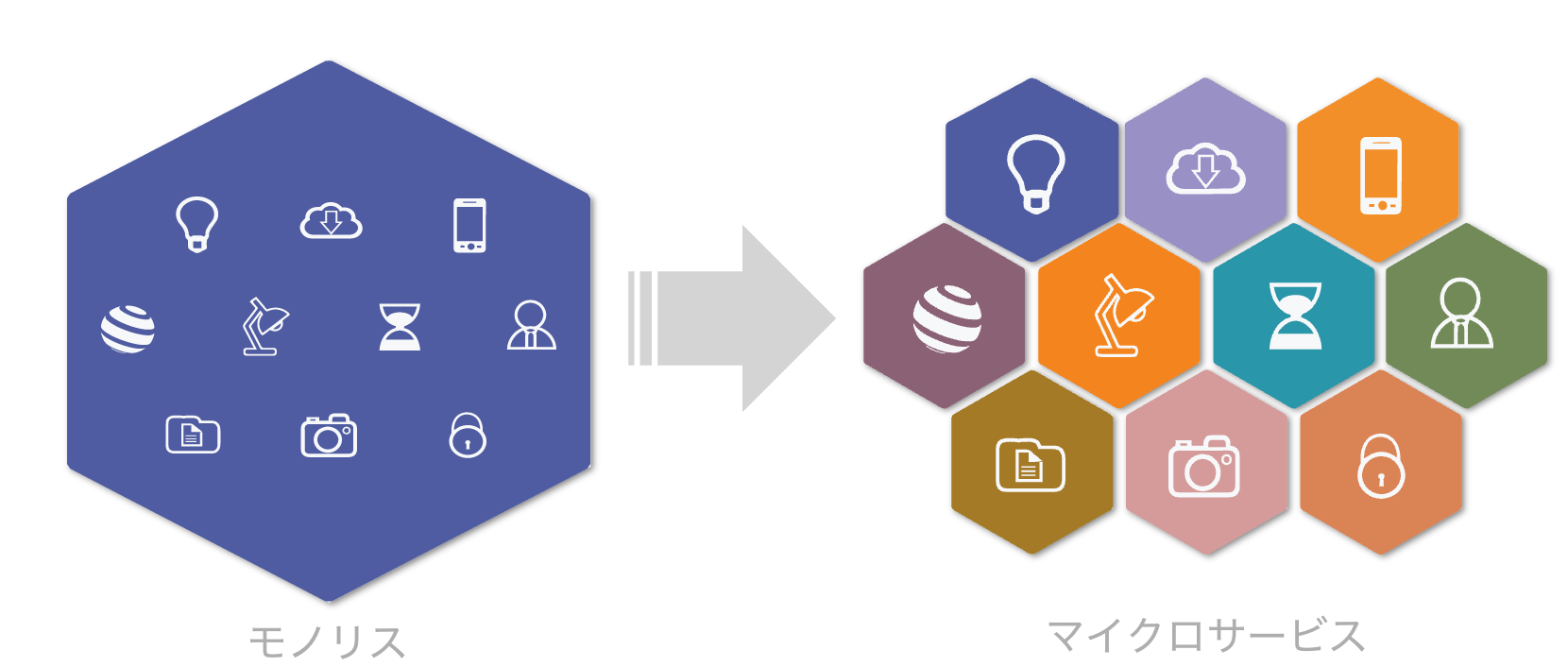
メッセージングに関するテクノロジーは、マイクロサービスを実現するために登場したわけではありませんが、メッセージングによってシステムを疎結合に保つことができるため、システムの粒度が細かくなるに連れて、ミドルウェアの重要性はさらに高まっています。
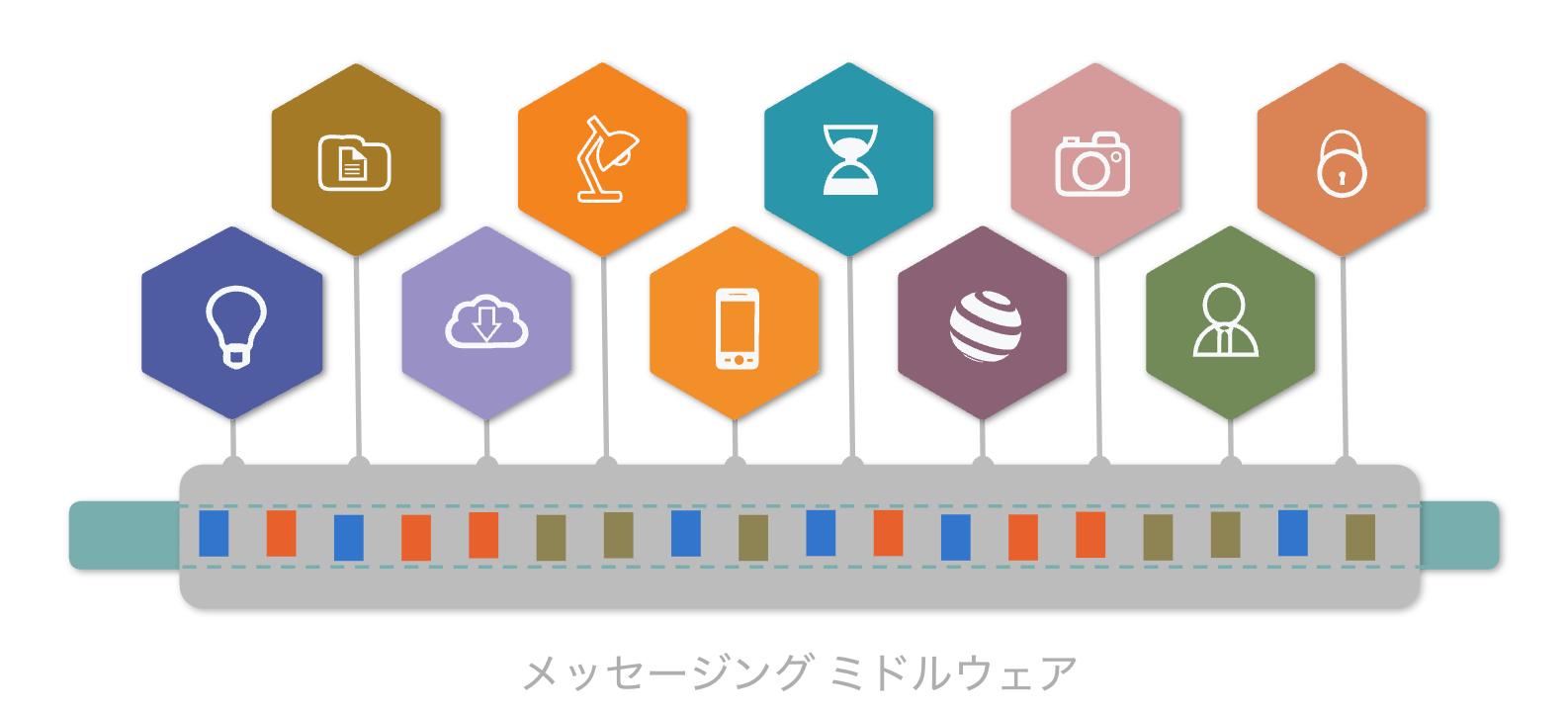
そして、次に説明するストリーミングは、サービスを結びつけるのみではなく、それ自体マイクロサービスを実現する環境であると捉えることもできます。
ストリーミングとは
Apache Pulsarなどのテクノロジーについて、(イベント)ストリーミングプラットフォーム、あるいは単にストリーミング、という言葉が用いられます。
単に「ストリーミング」という単語を用いた場合、現代では、「メディア」の「ストリーミング」という用法が一般的です。つまりデータ一般というよりも、音声や映像など、従来はデータ全体(のダウンロード)で利用されていたものを、継続的に、配信・消費するテクノロジーです。そして、それを可能にするためには、配信データを「処理」するプレイヤープログラムが欠かせません。また、上記の利用形態では、データの順序が保証されていることが重要な意味を持ちます。
ここでは、「ストリーミング」について、より個別・具体的に指示するために、ストリーム処理(Stream Processing)との言い換えが成立するものとして進めます。
ストリーム処理とは、言葉の通り、ストリームに対する処理、ということになります。処理の対象は「データストリーム」あるいは「イベントストリーム」と呼ばれる場合があります。
ETLでは、永続化されたデータに対するデータの変換が行われます。
あるいはデータベースをバックエンドで利用するアプリケーションは、永続化されたデータを利用して、データの表示や変換、あるいはデータに基づく判断を行います。
ストリーム処理では、データが永続化される前に、システム間を流れているデータを用いてリアルタイムでこれらの処理が行われます。
ストリーミングはビジネスをどのように変えるか?
このようにストリーミングと従来の永続化データを用いたアプリケーションとの違いは、リアルタイム性にあります。
データによる判断・意思決定、あるいはデータによる見える化、データの変換、集計などは、従来のアプリケーションでも用いられている操作ですが、ストリーム処理では、これらがリアルタイムで実行されることが特徴になります。
従来のシステムでは、ユーザーとシステムとのインタラクティブなコミュニケーションは同期モデルで行われているのが一般的でした。
同期モデルにおいては、永続化されたデータを前提とすることは自然です。
しかし、永続化されたデータを前提とした場合、例えば、在庫数に応じて注文を受けることができるかどうか、といった判断には、在庫数の増減に対して、全ての処理が同期される必要があります。
システム化の対象、システム利用者、あるいはエッジデバイスなど、相互接続されたシステムが増え続ける状況においては、このようなモデルはどこかで破綻することになります。実際に、同期モデルから非同期モデルへの移行はさまざまな場所で始まっているといえます。
つまり、ストリーミングを採用するかどうかは、単純に永続化の後に処理をするのか、永続化の前に処理をするのかといった違いではなくなっています。
ストリーミングにより、イベントドリブンに、非同期的に、インタラクティブなサービスを実現することができます。
このように、今後ますますストリーミングの重要性は増していくものと考えられます。
Apache Pulsar
概要
来歴
Pulsarは、Yahooによって開発され、2016年に、Apache Software Foundationに寄贈されました。
ちなみに、Apache Kafkaは2011年にオープンソース化しているので、5年遅れで登場していることになります。
Kafkaは、メッセージングのためのプラットフォームとして設計されていますが、
Pulsarは、メッセージングとストリーミングの両方の機能のために設計されています。

開発者の注目度
Githubにおけるストリーミングカテゴリーにおける注目度の指標となるStarのランキングでは、Pulsarは、2022年11月時点にて、9位となっていました。
ちなみに、1位はSpark Streaming,2位が、Kafka Streams、10位以内には、Flink,Akka, Stormという名前が登場していました。
最新の情報については、以下をご覧ください。
開発の活況状況
一方、開発状況について見てみると、コミット数においてはApache Software Foundationプロジェクトのトップ5にランクしており、アクティブコントリビューター数の推移ではApache Kafkaを上回るようになってきています。
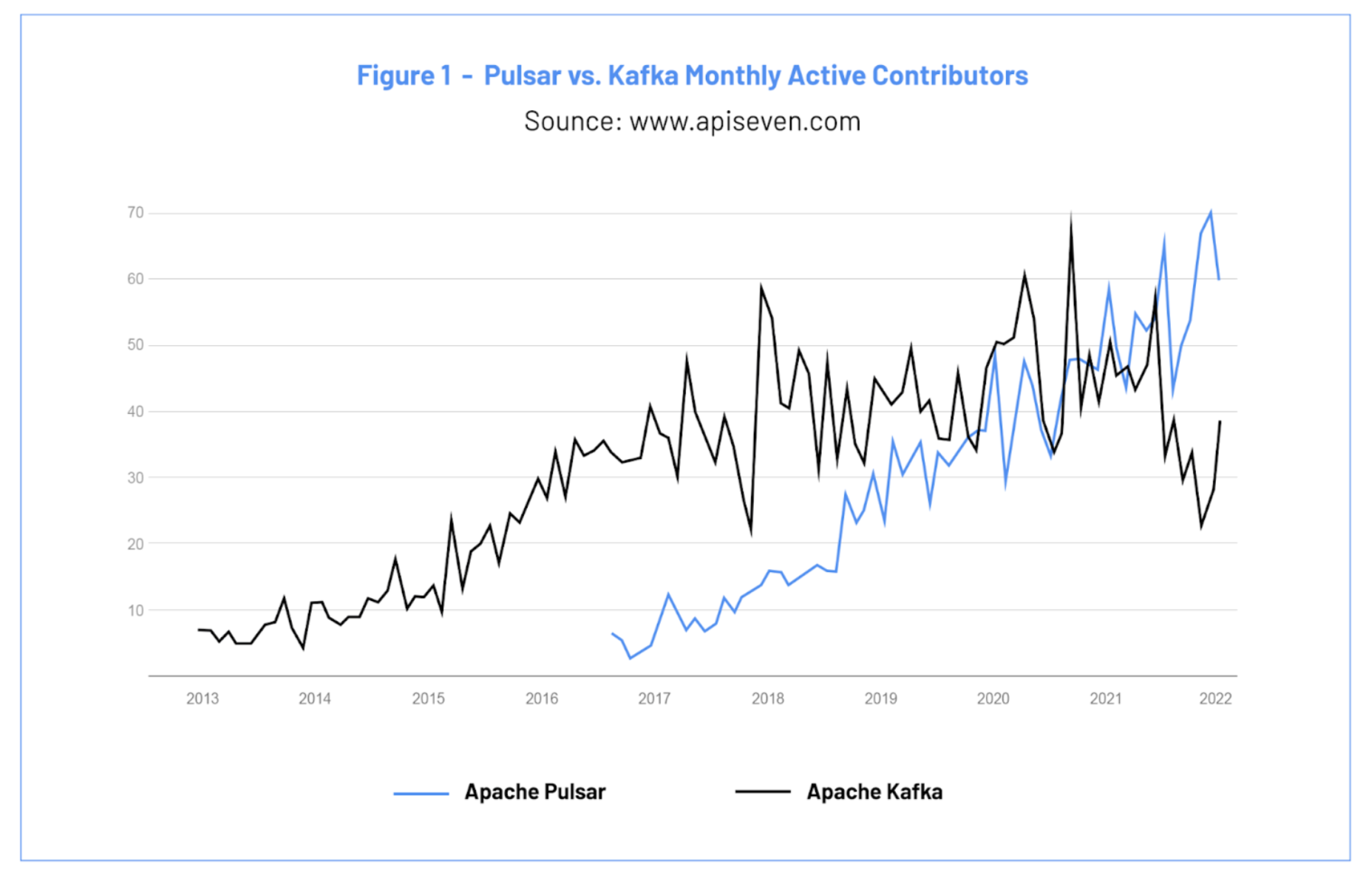
なお、コミット数のランキングは、ストリーミング技術に限ったものではありませんが、トップ4にFlinkがランクしているのも興味深いところです。
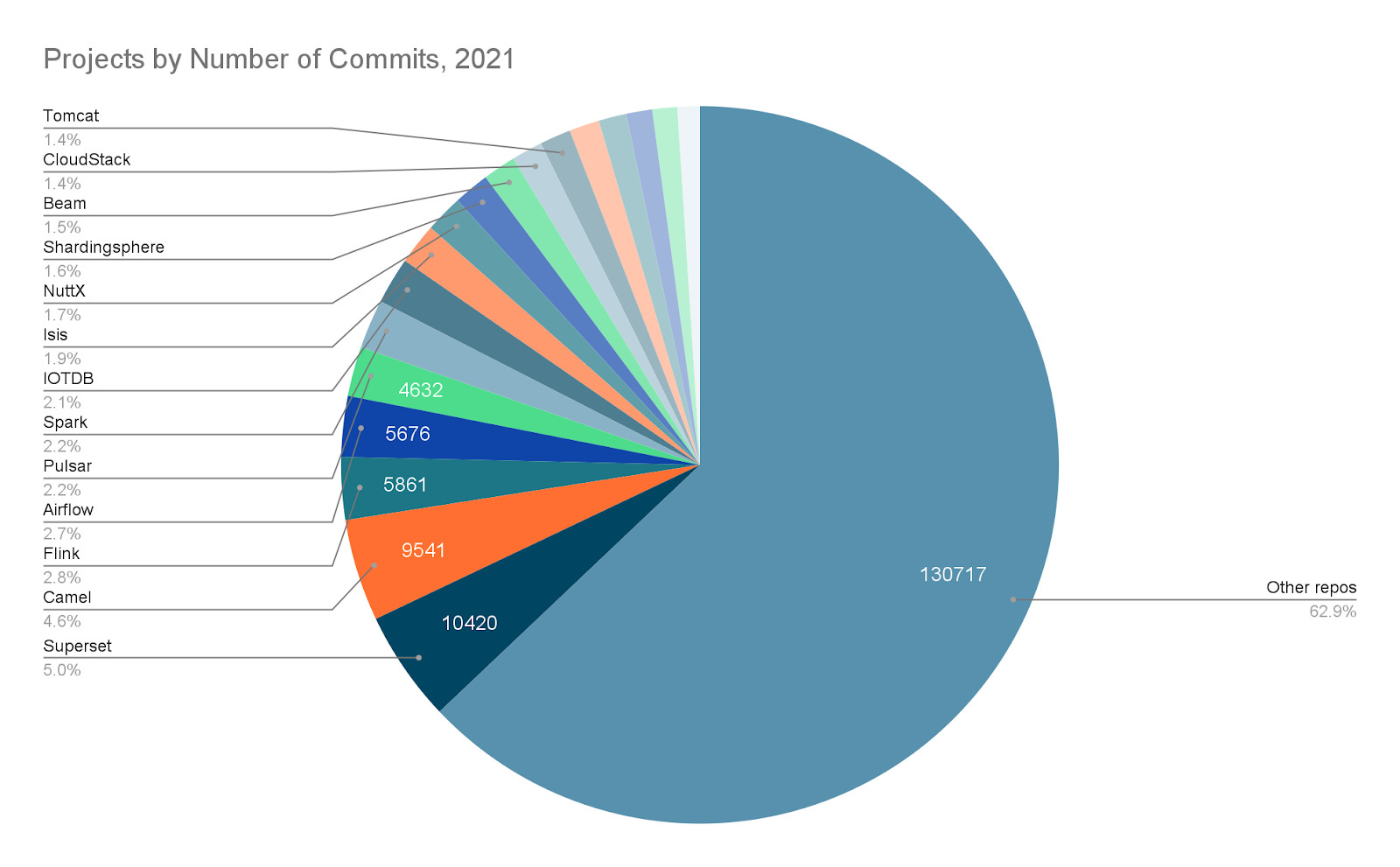
情報源として、以下のURLを示します。適宜ご参照ください。
Splunk
このように、Pulsarは、頭角を著してきている段階といえそうですが、やはりまだ十分に知られているとはいえないかもしれません。
そんな中、Pulsarの名前を聞いたことがなくても、Splunkという名前を聞いたことがある人は多いのではないでしょうか。
Splunkは、データストリームプロセッシングのフラッグシップ製品です。
実は、このSplunkの内部では、Pulsarが利用されています。
また、Splunk社のブログでも、多くのPulsarの記事が公表されています。
それによると、Pulsar はKafka よりも 5 倍から 50 倍優れたレイテンシを実現し、運用上の負担を軽減するとのことです。
KafkaとPulsar: 性能比較
なお、性能については、KafkaとPulsarのそれぞれのコミュニティから、別々にレポートが発表されており、内容はそれぞれ自陣のテクノロジーをサポートするものとなっています。
以下に、それぞれの立場からの記事を紹介します。
Confluent (Kafka)
Benchmarking Apache Kafka, Apache Pulsar, and RabbitMQ: Which is the Fastest?
StreamNative (Pulsar)
Benchmarking Pulsar and Kafka - A More Accurate Perspective on Pulsar’s Performance
中立的立場からの見解
比較においては、当然ハードウェアスペックなどを揃えて行うことになりますが、そもそもどのようなパターンで性能評価をするかについて、網羅的な実行は難しく、結局のところ、ユースケースや目的の影響を色濃く受けたものになると思います。
参考まで、中立的な記事から引用すると、「経験則的に、Kafka は高スループットを、Pulsarは低レイテンシーを指向している」(Ivan Despot: “Apache Pulsar vs Apache Kafka - How to choose a data streaming platform” ) という見解があります。
Pulsarのアーキテクチャーの背後にある目的
ここからは、Pulsarのアーキテクチャーについての解説に移ります。
まず、具体的なアーキテクチャーの説明にはいる前に、Pulsarのアーキテクチャーの背後にある目的を確認します。
それは、メッセージデータの確実かつ効率的な永続化です。
メッセージ順序を維持しながら、必要な未確認メッセージを永続的に保存することを前提にアーキテクチャ設計が行われています。
信頼性とコスト効率、そしてスケーリング柔軟性
ここで、「確実な」だけでなく、「効率的な」という点が重要です。
つまり、メッセージ保存の信頼性だけでなく、インフラのコスト効率、そして、分散アーキテクチャであるからには、スケーリングの柔軟性も非常に重要な要素となります。
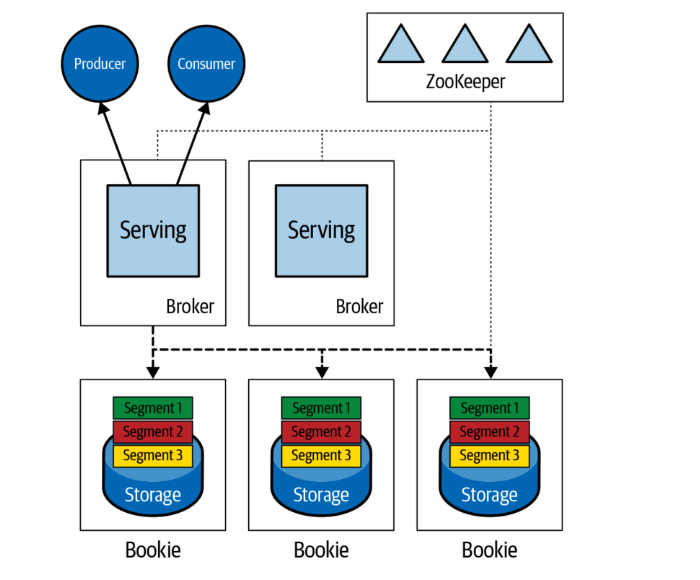
まず、メッセージングプラットフォームの特徴として、ブローカーの存在があります。
メッセージの永続化機能をもつためには、ブローカーは、プロデューサーやコンシューマーに対してサービスを提供する、コンピューティングレイヤーだけでなく、メッセージ永続化を司るストレージ機能を持つ必要があります。
Pulsarのアーキテクチャーの特徴として、プロデューサーやコンシューマーのようなクライアントのアクセスポイントとなるサービスレイヤーと、ストレージレイヤーとが、分離していることがあります。
なおPulsarのストレージレイヤーは、Apache Book KeeperというOSSが用いられており、ブッキーとも呼ばれます。
これに対して、Kafkaでは、ブローカーが内部にストレージ機能を持っています。
ここで、付け加えると、Pulsarの特徴の一つとして、コンテナテクノロジーを想定したクラウドネイティブな設計があります。ここで見たような、Pulsarのコンポーネント化の粒度は、このような背景と考え合わせると、よりよく理解することができます。
なお、Kafkaでは分散環境におけるブローカー間の関係はリーダーとフォロワーからなります。
Pulsarでは、ブローカーはステートレスであるという特徴があります。
つまり、分散環境におけるデータレプリケーションのコントロールは、ブッキーのレベルで発生することになります。
Pulsar:ステートレスブローカー
Kafka:リーダー・フォロワーモデルによるメッセージレプリケーション
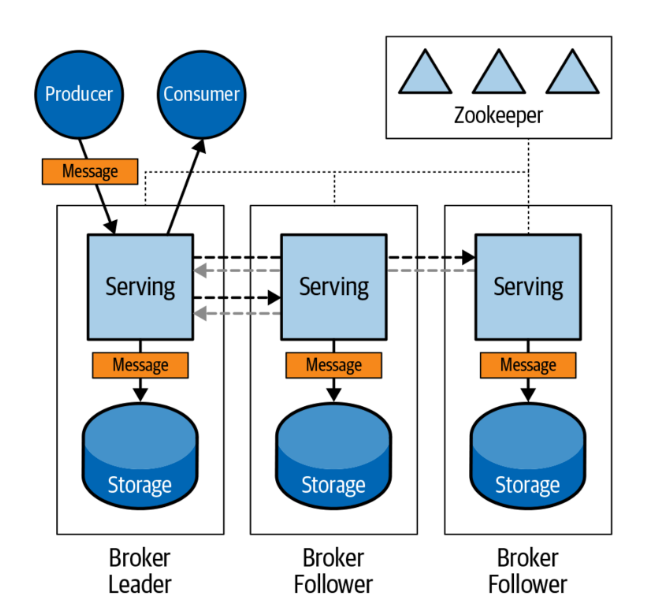
画像は、「Apache Pulsar Versus Apache Kafka」 (Chris Bartholomew著 O'Reilly Media, Inc.刊)より
セグメント指向
分散アーキテクチャーをもつメッセージングプラットフォームの特徴として、トピックの処理を複数のノードで分散して処理を実行することがあります。
そこでトピック内のメッセージの分割・複製の単位としての、「パーティション」という概念が用いられます。
Pulsarのアーキテクチャーの特徴として、このパーティションという論理的概念を支える物理的な要素としてセグメントが導入されていることがあります。
Kafkaでは論理的なパーティションと分散環境におけるファイル配置は一致しており、セグメントという概念は存在していませんでした。
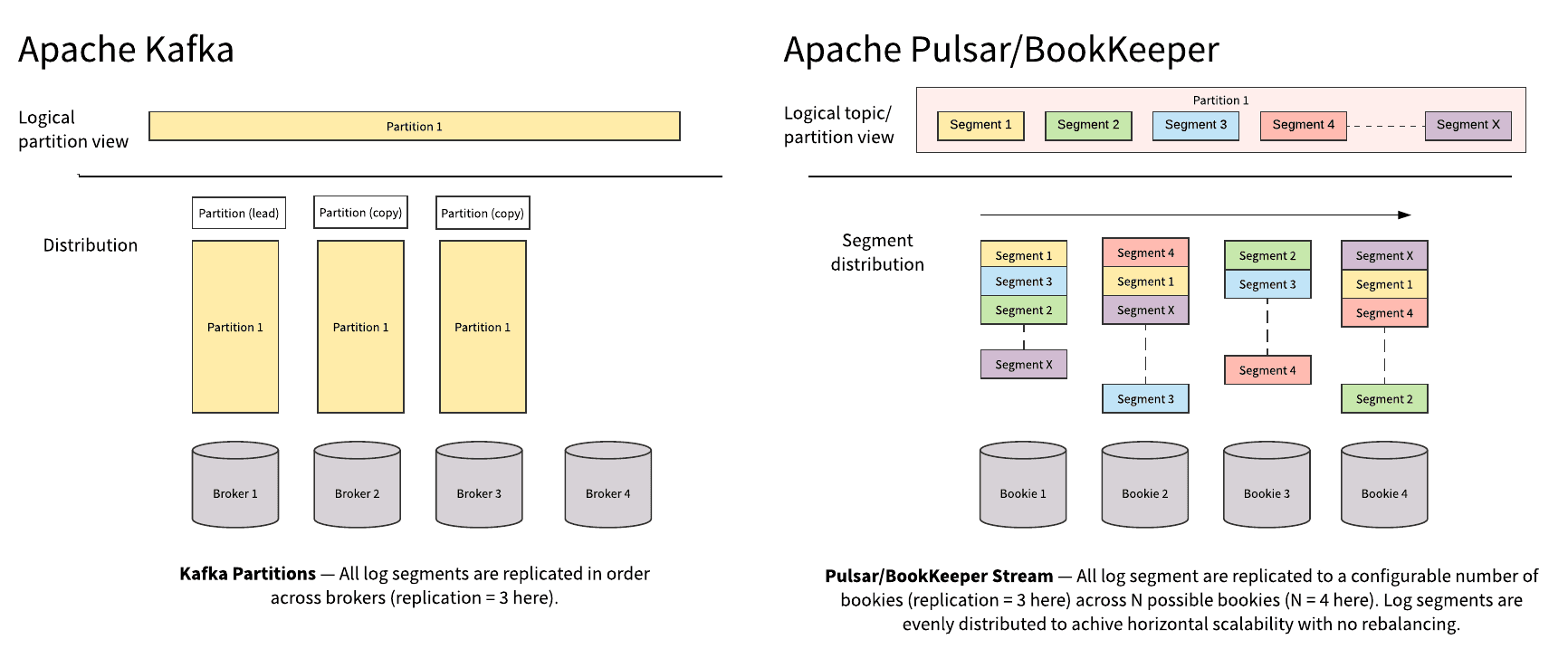
画像は、Splunkブログ”Partition-Centric vs.Segment-Centric”より
(https://www.splunk.com/en_us/blog/it/comparing-pulsar-and-kafka-how-a-segment-based-architecture-delivers-better-performance-scalability-and-resilience.html)
階層型ストレージ
ここで、さらに永続化層の効率を高めるPulsarの特徴として、階層型ストレージについて紹介します。
Pulsar はコンピューティングとストレージで階層化されているだけでなく、永続化層についても、いわばホットデータとコールドデータとの間を階層化することが可能です。
つまり、頻繁に使われないデータを、より安価なストレージ環境にオフロードすることができます。
これは、自動または手動で実行するように構成可能であり、クライアントに対しては透過的です。クライアントは、データがどこに保存されているかを意識する必要がありません。
トピックコンパクション
階層型ストレージは、データの保存場所を変更することによって、コストを最適化する機能でしたが、そもそも不要なメッセージを保存しない、という設計は自然なことです。
旧来のメッセージングプラットフォームでは、このような目的のために、メッセージに有効期限を設ける、という考え方が一般的でした。
Pulsarは、この目的のために、トピックコンパクションという機能を提供します。
トピックコンパクションは、メッセージの有効期限とは異なり、メッセージの保持(Retention)を尊重した概念だといえます。
つまり、古いメッセージは、新しいメッセージの発生によって、不要になった場合にのみ削除されます。
どのような条件で、古いメッセージが不要になるかは、アプリケーションの要件・設計次第ですが、Pulsarでは、メッセージにキーを設定することによって、トピックコンパクションが実現されます。
トピックコンパクションは、バックログが特定のサイズに達したときに自動的にトリガーされるか、コマンド ラインから手動でトリガーすることができます。
例えば、株式市場のティッカー情報は、わかりやすいユースケースの一つです。
株価は常に変化しますが、リアルタイム性が薄れた情報については、イベントレベルの推移は不要であり、チャートを描くための、分単位などの情報が受け取れれば十分と考えることができます。あくまで一つの例としてですが、このような場合、ティカーと分単位までの時刻情報をキーとして扱い、最新データのみを残して、定期的に古いデータを削除することは合理的と言えるかもしれません。
Kafkaのアーキテクチャー上の問題点
メッセージデータの確実かつ効率的な永続化を目的としたアーキテクチャー上の特徴の説明については以上となります。
ここで、Kafkaのアーキテクチャー上の問題点について、インフラ管理の観点から具体的に整理してみます。
- まず、ブローカー構成変更に伴い、トピックのパーティションとレプリカを複製する必要があります。これには、相応の時間を要することになり、分散システム運用上のリスクとなります。
- また、データを長期間保存するために、ストレージコストが高価になる可能性があります。
- そして、リソース設計のために、ブローカー、トピック、パーティション、レプリカの数、といったさまざまな要素の複雑な組み合わせを用いて計算する必要があります。
これらは、Pulsarを利用することによって、一定の合理化・最適化が期待できる要素であると言えます。
災害耐性
次に災害耐性を高めるためのアーキテクチャーについて紹介します。
GEOレプリケーション
Pulsarには、プラットフォームネイティブ機能として、GEOレプリケーション、つまりクラスターの地理的分散のための機能が備わっています。
これは、Kafkaの場合は、ネイティブ機能ではなく、Mirror Makerという別のコンポーネントによって実現されています。
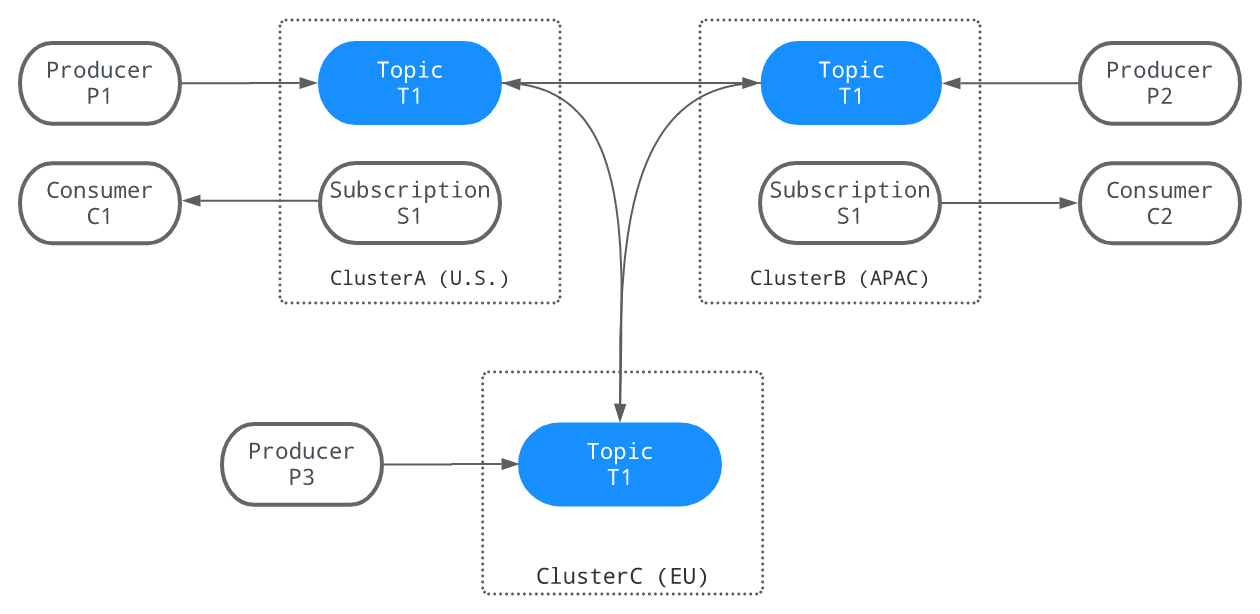
画像は、Apache Pulsarドキュメントより(https://pulsar.apache.org/docs/2.10.x/concepts-replication/ )
以下、PulsarのGEOレプリケーション機能の概略について説明します。
同期と非同期
まず、Geoレプリケーションは、同期と非同期の両方に対応しています。
同期GEOレプリケーションは、複数のリージョンにまたがる単一のクラスターとして実現されます。
そして、非同期GEOレプリケーションは、複数の地理的に異なる場所にあるクラスター間のレプリケーションとして実現されます。
GEOレプリケーションの種類
PulsarのGEOレプリケーションは、アクティブ・アクティブおよびアクティブスタンバイの両方をサポートするだけでなく、エッジコンピューティングにおけるように、複数のエッジデータセンターにあるクラスターのデータを中央データセンターにおいて集約するというツリー上のネットワークモデルにも対応しています。
プラットフォーム共有
次に、アーキテクチャーに関する最後の特徴として、一つのプラットフォームを共同利用する機能について解説します。
マルチテナント
一つのプラットフォームを共同利用する機能は、一般にマルチテナントと呼ばれます。
マルチテナントを実現するには、各テナント、例えば営業部とマーケティングのそれぞれは、自分の管轄内にあるデータにのみアクセスできることが保証されている必要があります。
これは一般にデータベースにとっては基本機能でしたが、メッセージングプラットフォームにおいては、必ずしもそうではありませんでした。
ここで重要なことは、データベースの例で言えば、個々のテーブルレベルの権限管理では、実質的に不十分であるということです。
このような状態を実現するには、特定のグループに属するデータが論理的にグループ化された上で、適切に権限を管理される必要があります。
また、一部のテナントが利用可能なすべてのリソースを使い果たし、他のテナントのためのリソースが枯渇するようなことがあってはなりません。
階層化されたトピック管理
メッセージングプラットフォームについて説明した際に、トピックという概念を提示しました。
Pulsar以前のKafkaのようなプラットフォームでは、トピックの上位概念は存在していませんでした。
Pulsarは、マルチテナントを実現するために、トピックの上位概念としてネームスペースとテナントという階層が提供されています。
例えば、マーケティングやセールスなどの部門毎にテナントを割り当て、それぞれの配下のシステム単位でネームスペースを使い分けるということが考えられます。
さらに、ネームスペースレベルで、データ保持ポリシーやストレージ クォータ のポリシーを使用可能です。

アプリケーション開発
ここからは、Pulsarを用いたアプリケーション開発の観点から、Pulsarの機能について紹介します。
ストリーム処理
まず、ストリーム処理機能について紹介します。
Kafka Streams
初めに、Kafkaにおけるストリーミング処理機能として、Kafka Streamsの紹介から始めます。
Kafka Streams は、ライブラリであり、実装においては、通常のアプリケーションからこのライブラリを使うことになります。
このアプリケーションの実行環境としては、特に規定されるものはありません。
好きなように実行できる、とも言えますが、開発者がKafkaとは別に、アプリケーション実行プラットフォームについて責任を持つ必要があります。
Kafka Streams実装イメージ

画像はApache Kafkaチュートリアルより(https://kafka.apache.org/33/documentation/streams/tutorial)
Pulsarファンクション
Pulsarにおけるストリーミング機能はPulsarファンクションと呼ばれます。
Pulsarファンクションは、Pulsar上で実行されるサーバーレスコンピューティングフレームワークです。
開発者は、特定のインターフェイスを実装する関数クラスを開発することになります。
開発したプログラムはパッケージ化した上で、Pulsarクラスターにデプロイします。
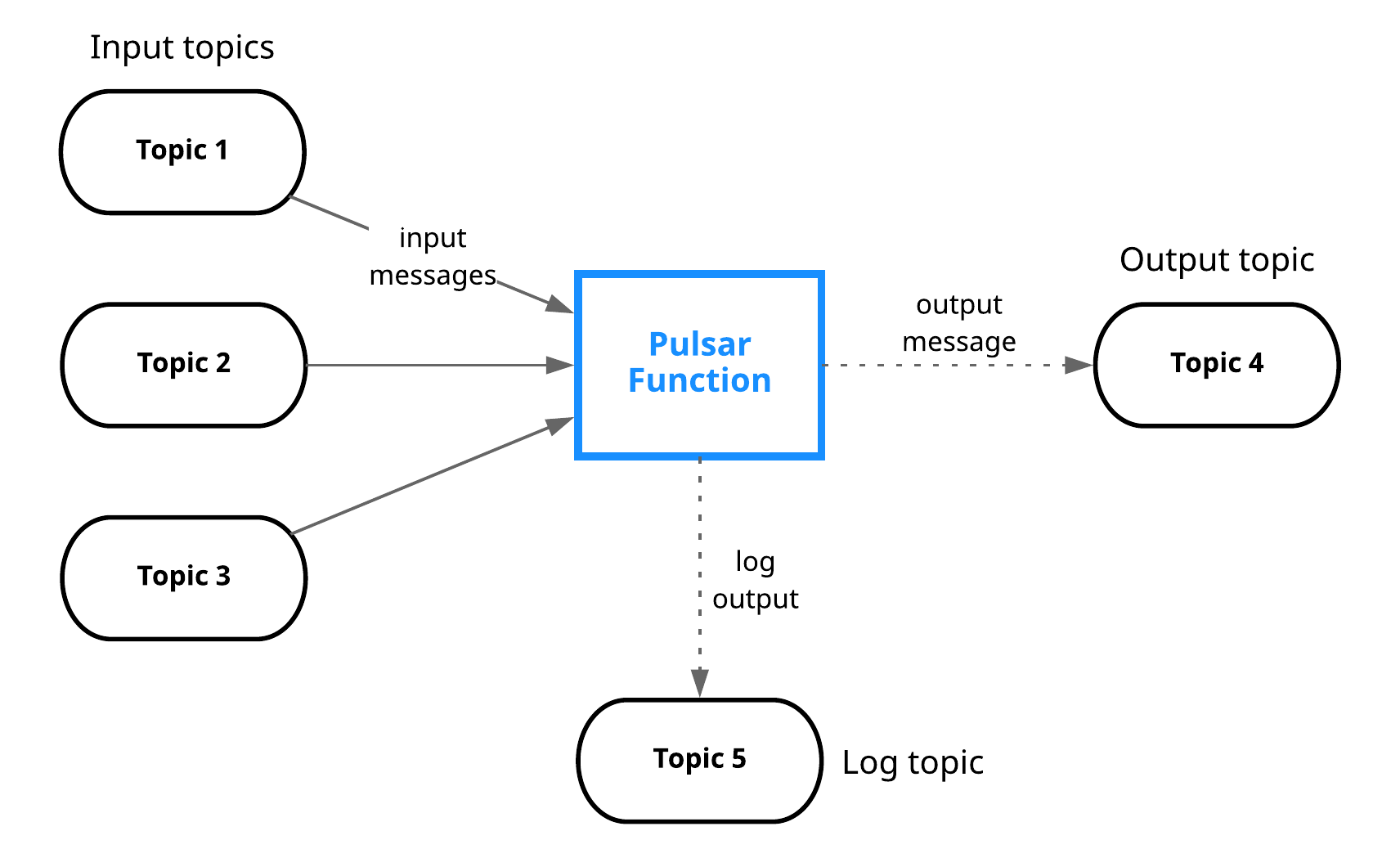
画像はApache Pulsarドキュメントより(https://pulsar.apache.org/docs/functions-overview)
「メッセージ パッシング」 マイクロサービス アプリケーション
Pulsarファンクションは、並列実行できるデータフロープログラミングに適した分散処理フレームワークであると言えます。
入力/出力トピックを使用して、関数として実現された処理を並列あるいは多段実行するだけでなく、条件分岐や実行結果の集約を実現することができます。
言い換えると、アプリケーションを、複数の関数が処理を実行し、入力/出力トピックを使用して、データを送信するデータ パイプラインとしてモデル化するものであると言えます。
(このデータパイプライン、一般にDAGとして知られる有向非巡回グラフであると言えます)
これによって、Pulsarは、メッセージパッシング型のマイクロサービス・アプリケーションのためのプラットフォームとして利用することができるものとなっています。
以上、見てきたように、KafkaとPulsarとではストリーム処理に関するアプローチは全く異なっています。
これについては、優劣というよりも、比較自体が成り立たないというのが公平な言い方だと考えます。
なお、Pulsarファンクションを用いたアプリケーション実装について、「Pulsar in Action」という書籍では、さまざまなデザインパターンが紹介されていますので、興味のある方はぜひご参照ください。
コンシューマー開発
次に、Pub/Subモデルにおける、Subscriberである、コンシューマー開発に関係する機能を紹介します。
Pulsar の利点として、メッセージング 消費モデルの柔軟さがあります。
Pulsarは、複数のサブスクリプションタイプを提供しています。
-
Exclusive: 1つのコンシューマー -
Failover: 一方で受け取れなかった場合のみ他方に配信 -
Shared:複数のコンシューマーで処理分担 -
Key_Shared:複数のコンシューマーで処理分担(メッセージキー単位)
これらのタイプによって、コンシューマーアプリでは、エラー処理の簡素化・柔軟なスケーリングが可能になります。
Kafkaにおいては、これらサブスクリプションタイプの一つであるSharedに相当するコンシューマーグループという機能が提供されています。
ここまでの整理と補足
ここまで紹介した機能以外にも、Pulsarにはさまざまな機能がありますが、ここまでの内容の整理を補足を行いことによって、締めくくりとしたいと思います。
Pulsarの機能として階層化ステレージ機能について、紹介しました。公平を期して言えば、 Confluent社が提供するKafkaプラットフォームでは、階層化ストレージ機能が提供されます。
また、GEOレプリケーションの比較の際に名前をあげたMirrorMakerのようにKafkaにはさまざまなエコシステムが備わっています。
そうしたスキーマレジストリーや、I/Oコネクターのような周辺機能がプラットフォームにビルトインされた機能として提供されていることもPulsarの特徴と言えるでしょう。
Apache Pulsarを体験する
最後に、今回Apache Pulsarについて興味を持たれた方が、実際に体験するための方法を紹介します。
Astra Streaming
「体験」という意味で、特に開発者にとしてPulsarを利用したい方のために、初めに、マネージドサービスを利用する方法を紹介します。
DataStaxから提供されているAstra Streamingを利用することで、簡単にPulsarを体験していただくことが可能です。
なお、DataStaxのAstraは、Apache CassandraとApache Pulsarをマネージメントサービスとして提供します。CassandraのDBaaSであるAstra DBが先行してサービス開始され、Astra Streamingは後に追加されたという経緯があります。Astraへのサインアップにより、どちらも使えるようになっています。
Apache Pulsar
Pulsarを使った開発というよりも、むしろ、Pulsar自体への興味から、ご自身で環境を構築することを考えられている場合には、まずApache Pulsarのドキュメントを参照されることになるかと思います。
バイナリファイルを用いたインストールだけでなく、KubernetesやDockerを使ったインストールについても解説されています。
スタンドアローンインストール:
https://pulsar.apache.org/docs/getting-started-standalone
Dockerインストール:
https://pulsar.apache.org/docs/getting-started-docker
Kubernetesインストール:
https://pulsar.apache.org/docs/getting-started-helm
Luna Streaming
オンプレやプライベートクラウドのセルフマネージド環境における本番運用のために、サポートを受けられるソフトウェアを利用したい場合には、DataStaxから提供されているLuna Streamingが選択肢となります。
Luna Streamingには、DataStaxからのサポートだけではなく、管理コンソールや、システム監視機能などが付随しています。
Apache Pulsar 2.10ディストリビューションに加えて、DataStax Luna Streaming は以下を提供します。
- Cassandra、Elastic、Kinesis、Kafka、JDBCコネクタ
- Pulsar環境の管理を簡素化するPulsar Admin Console
- Pulsarインスタンスを監視および監視するPulsar Heartbeat
- 上記追加機能を含むKubernetesデプロイ用のHelmチャート
Kubernetesインストール
https://docs.datastax.com/en/luna-streaming/docs/index.html
ベアメタル・VMインストール
https://docs.datastax.com/en/luna-streaming/docs/quickstart-server-installs.html
サンプルプログラム
最後に、Apache Pulsarを用いた開発の雰囲気を掴んでいただくために、プロデューサーのサンプルコードを掲載します。
このプログラムは、DataStax Astra Streamingを利用することを想定していますが、(特にAstra用のライブラリを利用しているわけでもなく)他の環境でも、同様に考えることができます。
また、同様にコンシューマーをコーディングすることもできるでしょう。
なお、このプログラムについては、リアルタイムデータ生成をシミュレートし、作成したデータをAstra Streamingから、Astra DBに投入し、Astra DBをバックエンドに使ったリアルタイムダッシュボードWEBアプリケーションをデモするために作成しました。
import pulsar
from pulsar.schema import *
from pulsar.schema import AvroSchema
import random
import time
print("start")
class DataUsage(Record):
accountno = Integer()
year = Integer()
month = Integer()
date = Integer()
serial = Integer()
datausage = Integer()
day = String()
service_url = '<Astraから提供されるあなたの環境のURLを入力してください>'
token = '<Astraから提供されるあなたの環境のトークンを入力してください>'
client = pulsar.Client(service_url,
authentication=pulsar.AuthenticationToken(token))
producer = client.create_producer('<Astraであなたが定義したトピックの情報を入力してください>',schema=JsonSchema(DataUsage))
usage = DataUsage()
usage.accountno = 100001
usage.year = 2022
usage.month = 12
usage.date = 24
usage.datausage = 100
usage.day = 'S'
i = 1
while True:
print("---------------------------------------")
time.sleep(5)
usage.serial = i
usage.datausage = random.randint(50, 100)
producer.send(usage)
i = i + 1
client.close()
最後に
本稿では、 Apache Pulsarの紹介として、メッセージング/ストリーミング自体の存在意義から初め、Apache Pulsarについては、特にKafkaとの比較という観点から整理しました。
※ 本稿に利用している画像のうち引用元の記述がないものについては、個人的に作成したもの、およびDataStax社の資料からの流用となっています。
今後の学習のために
Apache Pulsar と Kafka のマルチテナンシー機能の比較
10 分でわかる Pulsar : Kafka ユーザーのためのガイド