はじめに
Cassandra Day Tokyo
今年、2023年6月1日に、Cassandra Dayが日本でも開催されます。
Cassandra Dayは、昨年、ベルリン、ロンドン、アムステルダム、ハノイ、ジャカルタ、ヒューストン、サンタクララ、シアトル、シンガポールでも開催されました。
今回の東京での開催に向けて、Apache Cassandraに関する記事を発表していきます。

Apache Cassandraについて
Apache Cassandraとは、一言でいうなら、オープンソースの分散データベース管理システムです。
他の分散データベース管理システム同様、複数の汎用サーバーを用いて、ひとつのデータベースを構築します(開発などの目的のため、一つのサーバーのみで構成することも可能です)。
ここでは、詳しい説明は割愛し、興味のある方へのご紹介の役割は、公式サイトやWikipediaに譲ります。
CassandraをリアルタイムAIに活用するには〜CassandraによるKappaアーキテクチャ
この記事のソース
本稿は、元Google Quantum AIのAlan Ho氏の下記の記事「Cassandra をリアルタイムフィーチャー(特徴量)ストアとして使用するための実践者向けガイド(Practitioner’s guide for using Cassandra as a real-time feature store)」に基づいています。
この記事自体は、「リアルタイムフィーチャー(特徴量)ストアとして使用するためのベストプラクティスについて説明」しています。ここでは、その中からCassandraによるKappaアーキテクチャについての情報をお伝えしたいと思います。
関連して、以下のような記事を過去に発表しています。適宜ご参考ください。
CassandraとのリアルタイムAIとの親和性
Cassandra は、数十万TPSをサポートでき、リアルタイム トレーニングのユースケースに十分なスループットを提供できます。
一方、ユーザーがオブジェクト ストアからのトレーニングを維持したい場合、Cassandra は CDC を介してオブジェクト ストレージにデータを書き込むことで、これを実現します。このニーズを理解するには、Tensorflowや PyTorch などの機械学習フレームワークでは、オブジェクト ストレージからの ML モデルの並列トレーニング用に特に最適化されている、ということを思い出す必要があります。
Kappa アーキテクチャのサポート
オンライン/オフラインのスキューによるコストとデータ品質の問題により、Kappa アーキテクチャが Lambda アーキテクチャに徐々に置き換えられています。
この動向は、Lambdaアーキテクチャーの持つバッチ レイヤーとリアルタイム コンピューティング レイヤーを単一のリアルタイム レイヤーに移行するものと言えます。
その利点についての説明がさまざまに行われる一方(上記リンク参考)、サービス レイヤーの設計方法についてはあまり説明されていません。
Kappa アーキテクチャを使用して特徴量を生成する場合、いくつかの新しい考慮事項が生じます。
- データベースへの大量の書き込みが発生する可能性があります。例えば、元データからの変更を伴う特徴量の生成が一括処理として行われる場合が考えられます。このような大規模な更新中にクエリの遅延が発生しないようにすることが重要です。
- サービス層は、推論のための低レイテンシ クエリや、モデルのバッチ トレーニングのための高 TPS クエリなど、さまざまな種類のクエリをサポートする必要があります。
Cassandra は、次の方法で Kappa アーキテクチャをサポートします。
- Cassandra は大量データの書き込み時の性能保証を考慮した設計がなされています。書き込みの流入が増加しても、性能が大幅に損なわれることはありません。例えば、その一要因として、Cassandra は、強整合性ではなく結果整合性を使用して書き込みを処理することを選択することで分散環境における書き込み性能を担保しています。また、物理データの管理についても、書き込み時の性能に配慮した設計が行われています。適切に設計されたアプリケーションでは、書き込み時の結果整合性の選択は、読み込み時の一貫性考慮により、他のデータベースと遜色のない、一貫性を提供します。
- CDC を使用すると、データをトレーニング用にオブジェクト ストレージに複製し、推論用にメモリ内ストレージに複製できます。CDC は Cassandra へのクエリのレイテンシーにほとんど影響を与えません。
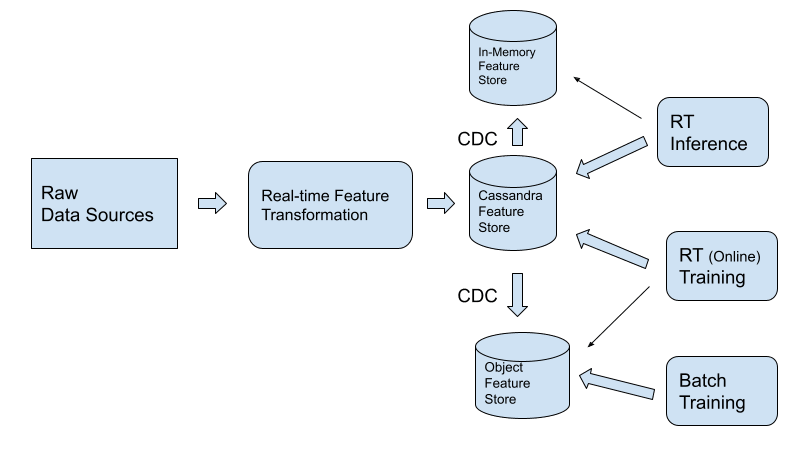
Lambda アーキテクチャのサポート
現在でも多くの企業では、リアルタイム パイプラインとは別のバッチ層パイプラインを備えた Lambda アーキテクチャが採用されています。 Lambda アーキテクチャには、以下のような側面があります。
- リアルタイムでのみ計算され、トレーニングのためにバッチ特徴量ストアに複製される特徴量
- バッチでのみ計算され、リアルタイム特徴ストアに複製される特徴量
- 特徴量は最初にリアルタイムで計算され、次にバッチで再計算されます。その後、不一致はリアルタイム ストアとオブジェクト ストアの両方で更新されます。
このシナリオでは、Cassandraを用いるには、次の図で説明されているアーキテクチャが推奨されます。
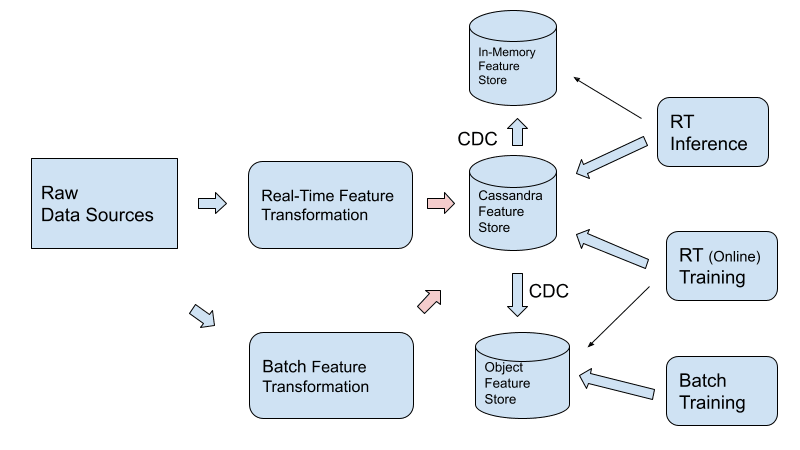
その理由は次のとおりです。
- Cassandra は、読み取りレイテンシーにほとんど影響を与えずにデータをバッチアップロードできるように設計されています。
- 単一の記録システムを持つことにより、データがフィーチャー ストアとオブジェクト ストアに分割されている場合に比べて、データ管理が大幅に容易になります。これは、特徴量が二度、最初にリアルタイムで計算、次にバッチで再計算される場合と比べて、特に重要です。
- CDC 経由で Cassandra からオブジェクト フィーチャー ストアにデータをエクスポートする場合、データ エクスポートをバッチ トレーニング ( Facebook などの企業で使用される一般的なパターン)用に最適化できるため、トレーニング インフラストラクチャのコストが大幅に削減されます。
既存のパイプラインを更新できない場合、または特徴量を最初にオブジェクト ストアに置く必要がある特定の理由がある場合は、以下に示すように、Cassandraによる特徴量ストアとオブジェクト ストアの間の双方向 CDC パスを使用することをお勧めします。
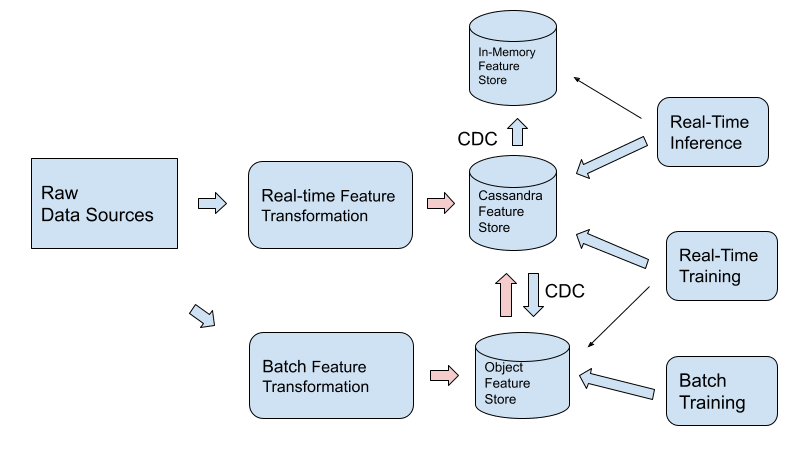
既存の ML ソフトウェア エコシステムとの互換性を確保する
Cassandra を特徴量ストアとして使用するには、エコシステムの 2 つの部分、つまり推論とトレーニングを実行する機械学習ライブラリと、特徴変換を実行するデータ処理ライブラリとを統合することになります。
機械学習で最も人気のある 2 つのフレームワークは、TensorFlow と PyTorch です。Cassandra には、Cassandra データベースから機能を簡単に取得できる Python ドライバーがあります。
また、複数の特徴量を並行してフェッチすることができます (以下のコード例を参照)。
特徴量の変換を実行するための 2 つの最も一般的なフレームワークは、Flink とSpark Structured Streamingです。
FlinkとSparkの両方のコネクタがCassandra で使用できます。
こちらについては、Flink、Spark Structured Streaming、および Cassandraのチュートリアルを参照できます。
FEAST などのオープンソースのフィーチャー(特徴量)ストアにも、Cassandra 用のコネクタとチュートリアルが準備されています。
最後に
この記事では、Alan Hoによる「Cassandra をリアルタイムフィーチャー(特徴量)ストアとして使用するための実践者向けガイド(Practitioner’s guide for using Cassandra as a real-time feature store)」から、CassandraによるKappaアーキテクチャについての記載された箇所の情報をお伝えしました。