こんにちは クイックイタレート株式会社の加藤 義也と申します。
この度掲題通り python3 で特定チャンネル内のファイルを一括削除する方法について困った末に実現出来たのとそのものズバリ(python3 & チャンネルリスト & 削除)がなかったので記事にしました。
何はともあれ、まずはslackのtoken取得
ワークスペースのtokenをファイル削除権限付きで取得しましょう。
https://api.slack.com/methods/files.list/test
チャンネルを指定してファイルを一括削除するコード
import requests
import json
from datetime import datetime
from time import sleep
token_id = "xoxp-XXXXXXXXXXXX-XXXXXXXXXXXX-XXXXXXXXXXXX-XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
# ↑ここにtoken_ID
channel_id = "XXXXXXXXX" #<==ここにチャンネルID
url = "https://slack.com/api/files.list?token=" + token_id + "&channel=" + channel_id
headers = {"content-type": "application/json"}
r = requests.get(url ,headers=headers)
json_data = r.json()
entries = json_data['files']
entries = sorted( entries , key=lambda x:x['created'] )
for attr in entries:
print(attr['id'])
url2 = "https://slack.com/api/files.delete?token=" + token_id + "&file=" + attr['id']
headers2 = {"content-type": "application/json"}
r2 = requests.get(url2 ,headers=headers2)
json_data2 = r2.json()
print(json_data2)
sleep(0.1)
経緯
つい先日SLACKを活用して複数拠点の写真による連携をしておりましたらいつしかファイルをアップロードするたびに 下記のメッセージが出るようになってしまいまして頭を悩ませておりました。

普段からお世話になっているSLACKなので費用を支払いたいのはやまやまなのですが、どうしても費用コースがフィットせずで、どうにかしてやりくりする方法が無いかと考えて色々調べたところファイルを削除を試みたのですが、一向にアナリティクスの画面の容量が減ってくれません。
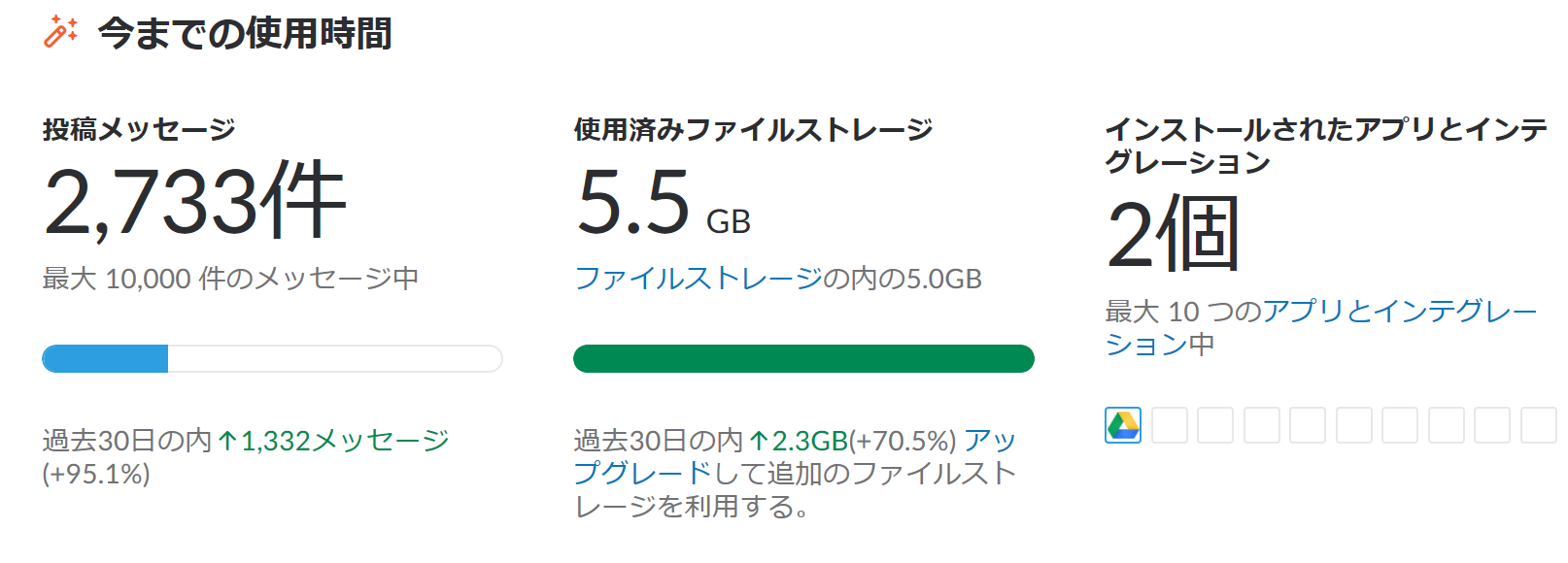
ファイル削除の制約
1.どうやらツールからの削除ではファイル本体が消えないので使用済みファイルストレージが減らない。
2.どうやらファイルの削除は一つ一つクリックして削除しないと消えない。
削除がとにかくめんどい!
特に2番目が本当にめんどい! 何百というファイルを削除しているだけでホントに1日かかる!!
ところがそこはSlack 充実したAPIを公開している様でコンピュータにファイルを
削除してもらいたい と言う事になりまして 最近色々な局面で活躍してくれてる
大好きな python3 を利用した SLACKの特定のチャンネルのファイルの削除をしていきたいと思います。
狙っていきたい感じ
1.チャンネルのリスト取得
2.チャンネル内のファイルリスト取得
3.チャンネル内のファイルを一括削除
下記色々調べた結果のリスト。
-tokenという固定長IDでワークスペース-権限-認証が紐付いたアクセスが可能。
-ファイル・チャンネルには一意の固定長IDが振られる。
-slack apiは https 経由で準備されてる。
中間成果物として
・チャンネルをリストするコード
・チャンネルを表示してから中身のファイルを表示するコード
も貼っておきます。
チャンネルをリストするコード
import requests
import json
from datetime import datetime
token_id = "xoxp-XXXXXXXXXXXX-XXXXXXXXXXXX-XXXXXXXXXXXX-XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
url = "https://slack.com/api/channels.list?token=" + token_id
headers = {"content-type": "application/json"}
r = requests.get(url ,headers=headers)
data = r.json()
entries = data['channels']
entries = sorted( entries , key=lambda x:x['created'] )
print(" DATE of CREATED CHANNELID NAME")
print("---------------------------------------------------")
for attr in entries:
print(str(datetime.fromtimestamp(attr['created'])) + " " + attr['id'] + " " + attr['name'])
こちらのコードはこんな感じに出力されます。
DATE of CREATED CHANNELID NAME
---------------------------------------------------
2017-04-21 16:21:37 C539XXXXX XXXXXXl
2017-04-21 16:21:37 C52GXXXXX XXXXXX
2017-12-19 17:31:02 C8GMXXXXX XXXXXXs
2017-12-20 11:11:00 C8GGXXXXX XXXXXX
2018-01-16 06:15:39 C8T9XXXXX XXXXXX
2018-03-22 14:35:10 C9V5XXXXX XXXXXXast
2018-04-10 17:29:05 CA46XXXXX XXXXXX検
2018-04-21 09:50:22 CAATXXXXX XXXXXX検用資料
2018-05-09 21:39:28 CAMNXXXXX XXXXXXservice
2018-05-12 09:48:25 CAPLXXXXX XXXXXXa関連
2018-05-14 15:25:20 CAP0XXXXX XXXXXX029
2018-05-14 15:25:58 CAQ0XXXXX XXXXXX030
2018-05-14 20:59:51 CAP8XXXXX XXXXXX
2018-05-15 08:54:43 CAP1XXXXX XXXXXX023
2018-05-15 08:54:51 CAQPXXXXX XXXXXX024
2018-05-15 08:55:00 CAQJXXXXX XXXXXX025
2018-05-15 08:57:56 CAQJXXXXX XXXXXX
2018-05-15 08:58:05 CAP5XXXXX XXXXXX
2018-05-15 09:15:33 CAPMXXXXX XXXXXX
チャンネルを表示してから中身のファイルのtitleとIDを表示するコード
import requests
import json
from datetime import datetime
token_id = "xoxp-XXXXXXXXXXXX-XXXXXXXXXXXX-XXXXXXXXXXXX-XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
# ↑ここにtoken_ID
url = "https://slack.com/api/channels.list?token=" + token_id
headers = {"content-type": "application/json"}
r = requests.get(url,headers=headers)
data = r.json()
entries = data['channels']
entries = sorted( entries , key=lambda x:x['created'] )
print(" DATE of CREATED CHANNELID NAME")
print("---------------------------------------------------")
for attr in entries:
print(str(datetime.fromtimestamp(attr['created'])) + " " + attr['id'] + " " + attr['name'])
url2 = "https://slack.com/api/files.list?token=" + token_id + "&channel=" + attr['id']
headers2 = {"content-type": "application/json"}
r2 = requests.get(url2 ,headers=headers2)
json_data2 = r2.json()
entries2 = json_data2['files']
entries2 = sorted( entries2 , key=lambda x:x['created'] )
for attr2 in entries2:
print( " " + str(datetime.fromtimestamp(attr2['created'])) + " " + attr2['id'] + " " + attr2['title'])
こちらのコードはこんな感じに出力されます。
DATE of CREATED CHANNELID NAME
---------------------------------------------------
2017-04-21 16:21:37 C539XXXXX XXXXXXl <==チャンネルIDと名称
2017-04-21 16:21:37 C52GXXXXX XXXXXX <==ファイルIDと名称
2017-12-19 17:31:02 C8GMXXXXX XXXXXXs
2017-04-21 16:21:37 C539XXXXX XXXXXXl <==チャンネルIDと名称
2017-04-21 16:21:37 C52GXXXXX XXXXXX <==ファイルIDと名称
2017-12-19 17:31:02 C8GMXXXXX XXXXXXs
参考にさせていただきましたサイト
https://api.slack.com/methods
https://qiita.com/unbabel/items/cb811f512162e61f56f4
http://lyncs.hateblo.jp/entry/2017/06/04/191421
https://qiita.com/ono0708/items/b517cc83ec84bb787456