やりたい事
この記事の続きを書いている途中でtipsができた。
XMLのツリー構造を理解する際の階層構造をpython内で表現する方法について備忘録を作っておきたい。
環境
- Windows10 pro
- anaconda navigator 1.6.2
- Jupyter Notebook 5.0.0
- python 3.6.1
- Intel Core i7 4770 16GB
経緯
1.OpenWeatherMapから取得したXMLの構造が最大4階構想になっており温度・湿度データを取り出す際のElementTreeに対する指示を明確にしたい。
2.そのためにXMLを木構造で表示する方法を知っておきたい。
3.再帰をかけたらうまくいったっぽいので備忘録。
最初書いていたコード
# ライブラリのインポート
import urllib.request
import urllib.parse
import xml.etree.ElementTree as et
import xml.dom.minidom as md
url='http://api.openweathermap.org/data/2.5/forecast?' #基底URLの設定
query = {
'id' : '1850144' ,
'APPID' : 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX', #あなたが取得したappid *1
'units' : 'metric',
'mode' : 'xml'}#クエリに設定する値群
url = url + urllib.parse.urlencode(query) #リクエストURLの生成
response = urllib.request.urlopen(url) #httpリクエスト
root = et.fromstring(response.read()) #取得したコンテンツをXML Elementに格納
for sub1 in root.iter('weatherdata'):
print("->",sub1.tag, sub1.attrib)
for sub2 in sub1:
print(" ->",sub2.tag, sub2.attrib)
for sub3 in sub2:
print(" ->",sub3.tag, sub3.attrib)
for sub4 in sub3:
print(" ->",sub4.tag, sub4.attrib)
最初書いていたコードの結果
-> weatherdata {}
-> location {}
-> name {}
-> type {}
-> country {}
-> timezone {}
-> location {'altitude': '0', 'latitude': '35.6895', 'longitude': '139.6917', 'geobase': 'geonames', 'geobaseid': '1850144'}
-> credit {}
-> meta {}
-> lastupdate {}
-> calctime {}
-> nextupdate {}
-> sun {'rise': '2017-07-08T19:33:18', 'set': '2017-07-09T09:59:30'}
-> forecast {}
-> time {'from': '2017-07-09T12:00:00', 'to': '2017-07-09T15:00:00'}
-> symbol {'number': '800', 'name': 'clear sky', 'var': '02n'}
-> precipitation {}
-> windDirection {'deg': '197.01', 'code': 'SSW', 'name': 'South-southwest'}
-> windSpeed {'mps': '4.32', 'name': 'Gentle Breeze'}
-> temperature {'unit': 'celsius', 'value': '23.07', 'min': '23.07', 'max': '23.44'}
-> pressure {'unit': 'hPa', 'value': '1019.84'}
-> humidity {'value': '97', 'unit': '%'}
-> clouds {'value': 'clear sky', 'all': '8', 'unit': '%'}
-> time {'from': '2017-07-09T15:00:00', 'to': '2017-07-09T18:00:00'}
(省略)
-> time {'from': '2017-07-14T09:00:00', 'to': '2017-07-14T12:00:00'}
-> symbol {'number': '500', 'name': 'light rain', 'var': '10n'}
-> precipitation {'unit': '3h', 'value': '0.67', 'type': 'rain'}
-> windDirection {'deg': '347.003', 'code': 'NNW', 'name': 'North-northeast'}
-> windSpeed {'mps': '6.57', 'name': 'Moderate breeze'}
-> temperature {'unit': 'celsius', 'value': '24.1', 'min': '24.1', 'max': '24.1'}
-> pressure {'unit': 'hPa', 'value': '1012.9'}
-> humidity {'value': '98', 'unit': '%'}
-> clouds {'value': 'broken clouds', 'all': '76', 'unit': '%'}
コード
でも なーんかエレガントじゃないんだよなぁ と思っていたところ再帰させることを思いつき再帰関数を作ってみた。
表示方法もディレクトリ方式に変えてみようと考えた。
この方法だと深さとfullpathを追跡できる。
さらにルート要素の名前もroot.tagで抽象表現できたのでいろんなXML文書で使えるはず・・。
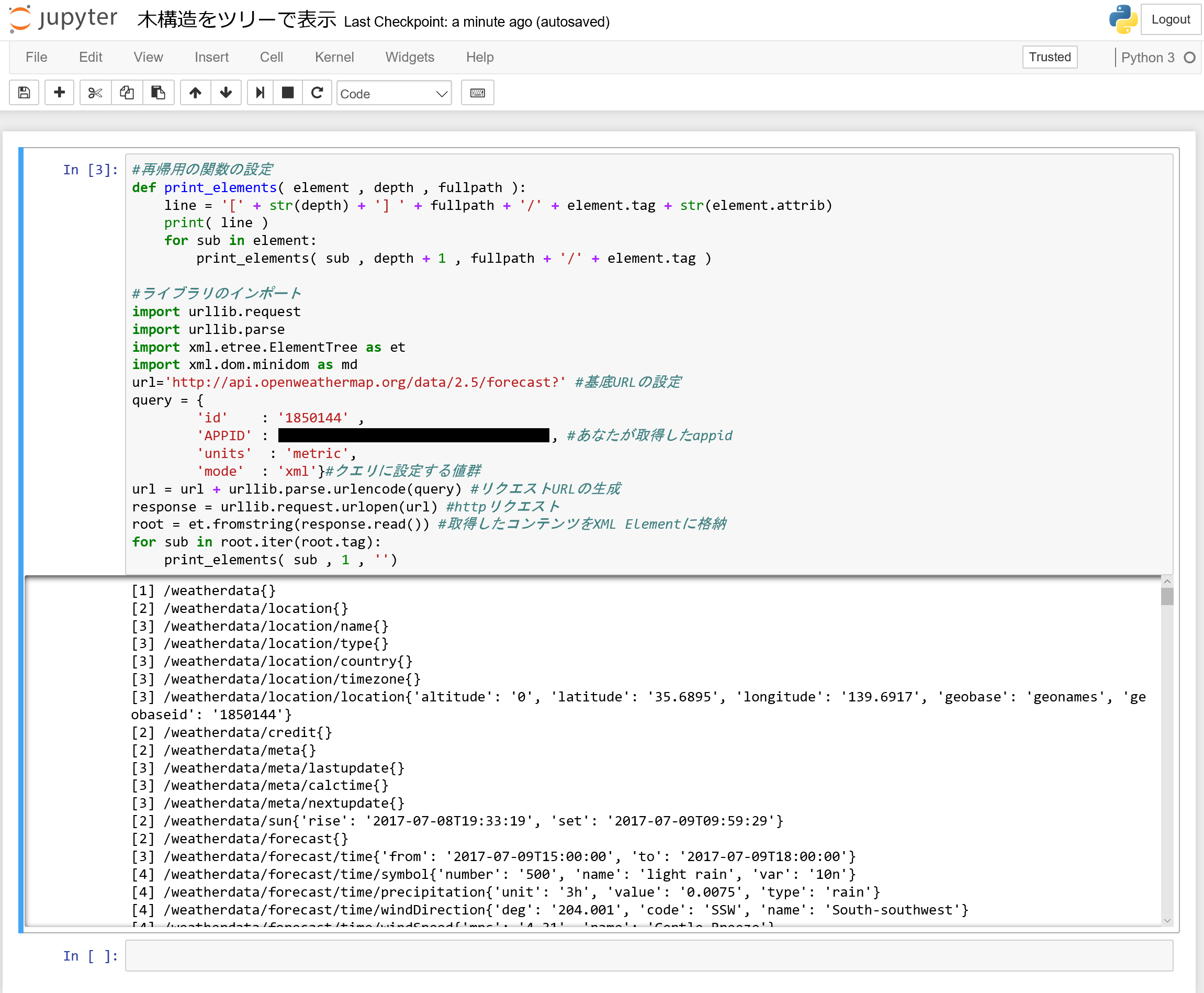
# 再帰用の関数の設定
def print_elements( element , depth , fullpath ):
line = '[' + str(depth) + '] ' + fullpath + '/' + element.tag + str(element.attrib)
print( line )
for sub in element:
print_elements( sub , depth + 1 , fullpath + '/' + element.tag )
# ライブラリのインポート
import urllib.request
import urllib.parse
import xml.etree.ElementTree as et
import xml.dom.minidom as md
url='http://api.openweathermap.org/data/2.5/forecast?' #基底URLの設定
query = {
'id' : '1850144' ,
'APPID' : 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX', #あなたが取得したappid *1
'units' : 'metric',
'mode' : 'xml'}#クエリに設定する値群
url = url + urllib.parse.urlencode(query) #リクエストURLの生成
response = urllib.request.urlopen(url) #httpリクエスト
root = et.fromstring(response.read()) #取得したコンテンツをXML Elementに格納
for sub in root.iter(root.tag):
print_elements( sub , 1 , '')
*1 appidはこちらからユーザー登録後、こちらで取得出来ます。
結果
[1] /weatherdata{}
[2] /weatherdata/location{}
[3] /weatherdata/location/name{}
[3] /weatherdata/location/type{}
[3] /weatherdata/location/country{}
[3] /weatherdata/location/timezone{}
[3] /weatherdata/location/location{'altitude': '0', 'latitude': '35.6895', 'longitude': '139.6917', 'geobase': 'geonames', 'geobaseid': '1850144'}
[2] /weatherdata/credit{}
[2] /weatherdata/meta{}
[3] /weatherdata/meta/lastupdate{}
[3] /weatherdata/meta/calctime{}
[3] /weatherdata/meta/nextupdate{}
[2] /weatherdata/sun{'rise': '2017-07-08T19:33:19', 'set': '2017-07-09T09:59:29'}
[2] /weatherdata/forecast{}
[3] /weatherdata/forecast/time{'from': '2017-07-09T15:00:00', 'to': '2017-07-09T18:00:00'}
[4] /weatherdata/forecast/time/symbol{'number': '500', 'name': 'light rain', 'var': '10n'}
[4] /weatherdata/forecast/time/precipitation{'unit': '3h', 'value': '0.0075', 'type': 'rain'}
[4] /weatherdata/forecast/time/windDirection{'deg': '204.001', 'code': 'SSW', 'name': 'South-southwest'}
[4] /weatherdata/forecast/time/windSpeed{'mps': '4.31', 'name': 'Gentle Breeze'}
[4] /weatherdata/forecast/time/temperature{'unit': 'celsius', 'value': '23.34', 'min': '22.9', 'max': '23.34'}
[4] /weatherdata/forecast/time/pressure{'unit': 'hPa', 'value': '1019.56'}
[4] /weatherdata/forecast/time/humidity{'value': '100', 'unit': '%'}
[4] /weatherdata/forecast/time/clouds{'value': 'scattered clouds', 'all': '32', 'unit': '%'}
[3] /weatherdata/forecast/time{'from': '2017-07-09T18:00:00', 'to': '2017-07-09T21:00:00'}
(省略)
[3] /weatherdata/forecast/time{'from': '2017-07-14T12:00:00', 'to': '2017-07-14T15:00:00'}
[4] /weatherdata/forecast/time/symbol{'number': '500', 'name': 'light rain', 'var': '10n'}
[4] /weatherdata/forecast/time/precipitation{'unit': '3h', 'value': '0.27', 'type': 'rain'}
[4] /weatherdata/forecast/time/windDirection{'deg': '320.001', 'code': 'NW', 'name': 'Northwest'}
[4] /weatherdata/forecast/time/windSpeed{'mps': '5.11', 'name': 'Gentle Breeze'}
[4] /weatherdata/forecast/time/temperature{'unit': 'celsius', 'value': '24.35', 'min': '24.35', 'max': '24.35'}
[4] /weatherdata/forecast/time/pressure{'unit': 'hPa', 'value': '1013.6'}
[4] /weatherdata/forecast/time/humidity{'value': '96', 'unit': '%'}
[4] /weatherdata/forecast/time/clouds{'value': 'few clouds', 'all': '20', 'unit': '%'}
とまぁ こんな感じでうまくいったっぽい。
全体感を迷いなく把握できた感じが良い。
まとめ
木構造がことのほか深くなっていた。
全体感を把握するにはこの表記がよいかもしれない。
あくまで構造を把握するための中間表現。
どの要素とどの属性がほしいのか整理するのに役に立つ。
この再帰関数はほかのXML文書でも使える(はず)。
参考にさせていただいたサイト
jupyter notebookの結果画面