はじめに
プロフィールにも書きましたが、私はエンジニアとして会社勤めをする傍ら音楽ライターとしても細々と活動しています。最近だとこんな記事を書きました。
パブロ・シーグレルって誰?と思う方も多いと思いますが、アルゼンチンタンゴの巨匠アストル・ピアソラの五重奏団のピアニストだった人で、ピアソラ亡き後は自身の「ジャズ・タンゴ」を追求しているミュージシャンです。今月 (2025年8月) 末に東京でのコンサートが予定されており…と、ここで長々書く話ではないですね。興味のある方はぜひご一読ください。
インタビュー記事を書くにあたってはAIのお世話になっています。本当はその際の手順を紹介する記事を書くつもりだったのですが、いろいろ確認したら自分のやり方は古かったことがわかり、ちょっとショックを受けた、という話です。
インタビューのスペック
アルゼンチン人のシーグレルさんのネイティブ言語はスペイン語ですが、ニューヨーク在住なので英語も堪能です。インタビューはZoomで行われ、私は日本語で質問、彼のパートナーの志和雅恵さんがそれをスペイン語に訳し、シーグレルさんはなぜか (多分私がわかるように) 英語で回答、という流れでした。一部雅恵さんに質問した個所もあります。英語の回答は翻訳されず、結果的に3か国語混在となりました。もちろん録音してあります。長さは1時間ちょっと。
記事執筆時の流れ
以下は記事を書いた際に採用した手順です。簡単に書きます。
文字起こし
今回はGoogleのGeminiを使いました。Google AI StudioのUIから使う分には無料で使えてお得です。
前回 (2025年2月ごろ) Geminiで文字起こしをした際にはAPI経由で2.0 Flashを使ったのですが、その際は長い音声ファイルの文字起こしがうまくできず、10分程度に区切ってAPIに投げていました。今回はバージョンも使い方も違いますが、前回の経験を踏襲して音声ファイルを分割してからUI経由でアップロードして文字起こしを行いました。結果はかなり良好で、特に英語部分は非常に高い精度で文字起こしできたと思います。
翻訳
上述のように、シーグレルさんの回答は英語のみなので、和訳する必要があります。こちらはChatGPTを使いました。Geminiじゃないのは気分です。というか、最近別の用途でChatGPTに翻訳をさせたらかなり高品質だった、という経験が背景にあります。5が出る直前のタイミングだったので4をやはりUI経由で。
文字起こしの結果から英語の部分のみを逐次コピペして、プロンプトでインタビューの回答である旨を伝えて訳させたら、フィラーや無駄な繰り返しが省かれてかなり高品質な結果となりました。
記事化
ここに関しては私はAIを信用しきれておらず、手作業で行いました。話題の取捨選択を行い、重複箇所をまとめたり、話の流れを考えて順序を入れ替えたり。最後に改めて文字起こし結果と照らし合わせ、誤訳や抜け、編集過程で生じたニュアンスのずれなどを修正し、最終的な記事となりました。
今回の手順で古かったこと
上記の手順で古かったのは以下のポイントです。
- 音声ファイルの分割
- 英語部分のみのコピペによる翻訳
- 手作業による記事化
それぞれ説明します。
音声ファイルの分割
文字起こし対象の長さに関する制約は、AIが扱えるトークンの数に関係します。トークンはAIが言語を扱う際の最小単位です。Geminiでは、文字情報の場合1トークンは英語なら0.6~0.8語、日本語なら1/3~1文字程度に相当します (→ トークンを理解してカウントする | Gemini API | Google AI for Developers、Geminiの日本語トークン数について | Genspark)。また音声データは1秒を32個のトークンとして表します (→ 音声の理解 | Gemini API | Google AI for Developers)。
まず入力トークン数。上記の数字から、音声1分間で1,920トークン、1時間で115,200トークンに相当しますが、入力トークン数の上限はGemini 2.0も3.0も約100万トークンなので、9時間半までは入力できることになります。1時間程度の音声なら問題ないですね。
ところが、出力トークン数の上限はこれよりだいぶ少ないのです。前回使ったGemini 2.0では出力トークン数の上限は8,192でした。前回は日本語メインだったので、ざっくり3千~8千文字程度が出力の上限ということになります。一般的な話速は1分あたり300文字程度だそうなので、Gemini 2.0では最悪10分程度の発話内容で出力トークンの上限に達してしまいます。これを回避するには音声ファイルを分割する必要があったわけです (まとめて入力して一部ずつ出力させる、ということも試しましたが、私のやり方が悪かったのか、うまく行きませんでした)。
一方今回のGemini 2.5は65,536トークンの出力が可能です。2.0の8倍ですね。ということは最悪でも日本語で80分以上の発話内容の出力が可能です。詳細は省きますが英語はもっと長時間に相当します。よってファイル分割は不要なのです。
英語部分のコピペによる翻訳
これは、元々の環境でもうまいやり方ではなかったと言えます。上で述べたように入力トークン数の上限はGeminiだと100万で、日本語で30万~100万文字、英語で60~80万語とめちゃめちゃ大きい。ChatGPTはこれよりだいぶ小さいですが、それでも数万文字、数万語は余裕です。そして、全文まとめて読ませた方が前後の文脈を把握できるので、翻訳も正確になることが期待できます。
記事執筆だけじゃないですね。何らかの文章の一部分だけ訳したいときでも、訳したいところだけでなく全文を訳させた上で必要なところだけピックアップする方が、より正確な訳が得られるということです。
手作業による記事化
これは今回やってみてわかったのですが、全文を把握した状態のAIは全体の話題の構造や重複箇所もわかっています。また外部の知識もある程度反映できるようです。どこまでやらせるかは別としても、この状態を利用しないのはもったいない気がします。
今どきのやり方
具体的には以下のような手順を踏めば、結構いい感じの記事が10分ぐらいでできてしまいます。ここではAIはGeminiを使います。
Google AI Studioへのアクセスと設定
Google AI Studioを初めて使う場合、最初の画面はこんな感じのはずです。
右上の「Get started」をクリックするとGoogleアカウントの認証に進み、それが通ると下図のような画面になります。
今回はUI経由で使うので、上の「Use Google AI Studio [Try Gemini]」をクリックするとGoogle AI StudioのUI画面に遷移。右上のGeminiのバージョンが書かれた部分をクリックすると使用するバージョンが選べます。
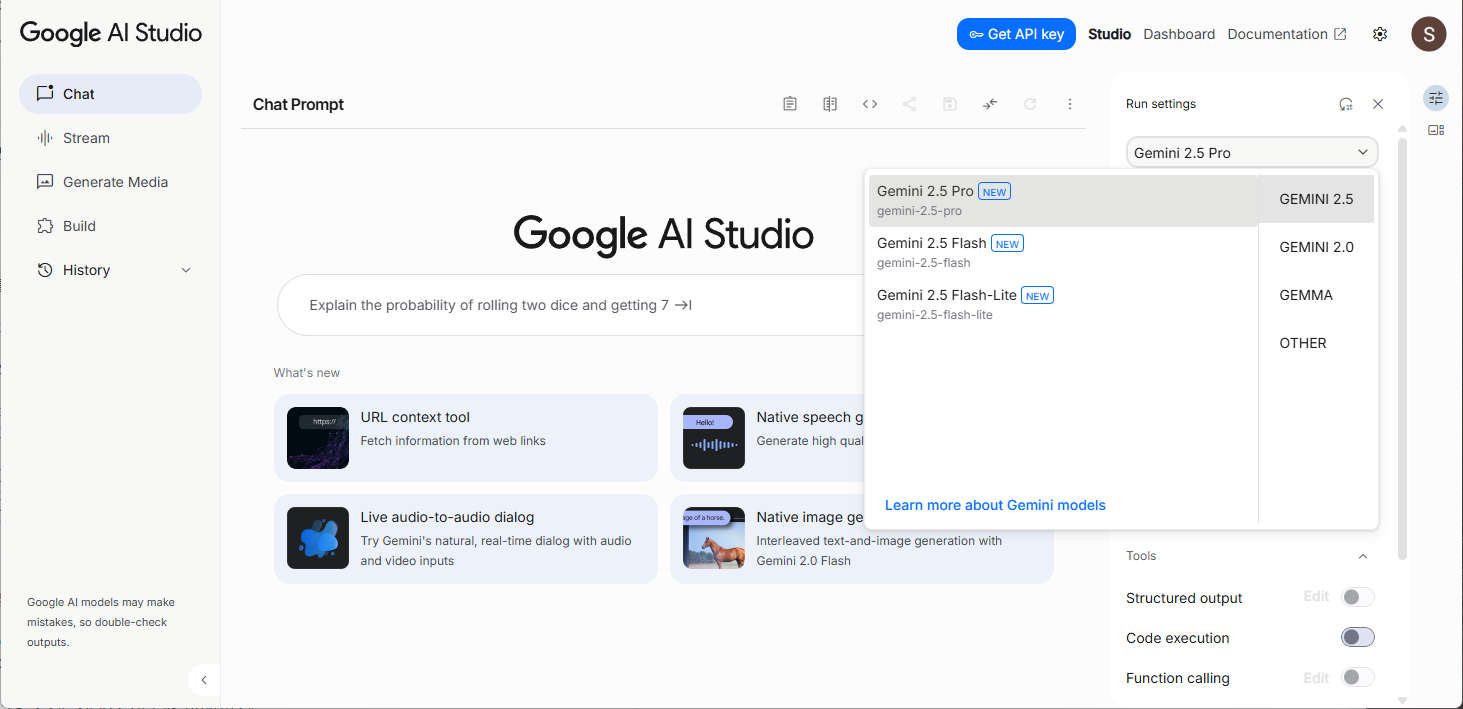
バージョン間の比較は下記ページを参照してください。
価格がどうのとか言ってますが、Google AI Studioで使う分には無料です。ただし、使用した内容が製品の性能向上に使われる、などの制約はありますので要注意です。詳しくは下記参照 (日本語版は一部翻訳がイマイチだったので英語で)。
今回は制約事項に関しては問題なし。とすれば無料なんだから一番強いやつ、ということで2.5 Proを選びました。
文字起こし
音声ファイルをアップロードします。一番簡単なのは画面上にドラッグアンドドロップ。他に、プロンプト入力欄の右にある〇の中に+が書かれたボタンをクリックして表示されたメニューから「Upload File」を選んでもOKです。既にGoogle Driveにファイルがある場合は同メニューのMy Driveから選ぶことも可能です。
ファイルがアップロードされたら (サイズが大きければそれなりに時間がかかります) 文字起こしを行わせるプロンプトを入力します。今回は「日本語、スペイン語、英語が混在したインタビューです。文字起こししてください。」としました。
少し間をおいて、結果が出力されます。
結果の上に何やら「Thoughts」というのがありますね。最近のAIは「思考プロセス」が組み込まれていて、求められた結果を出力する前に何らかの思考を行うステップが挿し挟まれます。ここにはその思考プロセスの要約が格納されています。開いてみましょう。
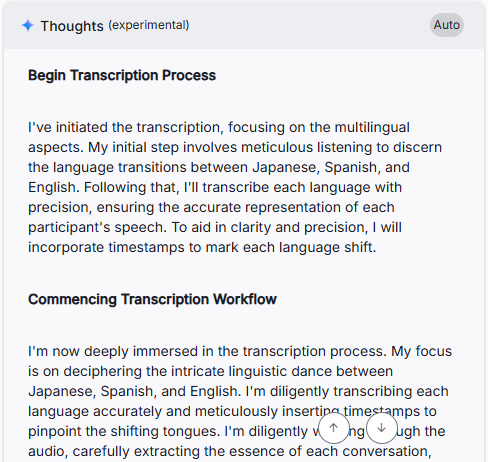
3か国語であることに注意を払っていることがわかります。さらに、上記スクリーンショットの外にはこんなことも書いてありました。
The main interviewee is Pablo Ziegler, but I'm being mindful to include Masayo's Japanese contributions, interpreting the conversation with the relevant speakers. I'm focusing on the technical terms and proper names to ensure that they are correctly transcribed.
プロンプトでは名前を出さなかったにもかかわらず、インタビュイーがパブロ・シーグレルだと認識していました。さらにMasayoさん (本当は雅恵さん) の貢献についても意識しています。さすがです。
今回の文字起こしの結果は満足の行くものでしたが、もし結果に問題があったら「Thoughts」を確認し、問題があれば適切なプロンプトで方向修正する、と言うようなことも可能かと思います。
翻訳と記事化
AIは文字起こしの結果の全体を覚えていますので、そのまま翻訳と記事化を一気にさせてみます。プロンプトは「文字起こしの結果について、スペイン語、英語はすべて日本語に訳してインタビュー記事形式にしてください。」としました。
出てきた結果は、一応他媒体に上がっている記事と同じ素材によるものなので公開は控えます。でも結構衝撃的。そのまま公開できそうなタイトルとリード文まで付いていて、記事としてコンパクトにまとまり、なおかつ読みやすい。日本語の固有名詞も正しく漢字で書かれています。いや、ギタリストの鬼怒無月 (きどなつき) さんの名前がちゃんと漢字で出るのは何気にすごいですよ。与えられた音声ファイルの範囲の情報だけでなく、パブロ・シーグレルさんと共演している日本人ギタリストのキドさんとは鬼怒無月さんである、というバックグラウンド知識を持ってるわけです。
ちなみに、最初にリンクを貼った私の記事は、多分インタビュー記事としては結構冗長な部類である、という自覚はあります (この文章も冗長だ)。自覚しつつ、掲載媒体の字数制約が緩いこともあり、面白そうなエピソードはなるべく捨てたくない、という気持ちで書いているわけですが、AIくんの簡潔にして要領を得た記事を見て軽いショックを受けたというのは正直なところです。加えて、専門分野での自分の知識のAIに対する優位性がさほどでもないという感覚、ですかね。
Thoughtsを見ると記事を書き上げる上での思考過程がちゃんと書かれていました。勉強になります(笑)
これからはAIに全部任せる…か?
とりあえずちゃちゃっといい感じの記事を書くまでのことは、AIに一任してもできてしまうことがわかりました。今回は文字起こしと記事化の2ステップを踏みましたが、音声からいきなり記事化させても案外行けちゃうのかもしれません。
ただ、今回出来上がった記事をよーく読んでみると、一部でちょっとした事実誤認があったり、私から見ると大事だと思われるエピソードが省かれてしまっていることがわかりました。従って、まだAIに全部任せるのは早いというのが私の認識です。多分次回こんな機会があったら、最終確認のためにも全体の文字起こしは確保し、記事化の際にはあらかじめアウトラインを指定した上で、結果を確認しながら何度かプロンプトで調整する、という工程を踏むことになるかと思います。
でもまあ、ほんの半年前と比べてもAIはずいぶん進歩していましたので、また半年ぐらい経つと状況は変わるかもしれません。その時はまた驚きつつ絶望しつつ、新しい方法を模索するのだと思います。