1. はじめに
はいどうも、myjlab advent calender 2022 4日目を担当する3年の yoshiki495 です。
先日、HRIと京大が開発・公開しているHARK(Honda Research Institute Japan Audition for Robots with Kyoto University)というロボット聴覚のオープンソースソフトウェア(OSS)の講習会にお邪魔してきました。
このロボット聴覚という研究分野、日本発祥だとか。さすが京大と言わざるを得ません。
ちなみにタイトルで次世代と言っておりますが、バージョン1.0の公開は2008年だそうです。
次世代って使ってみたかっただけです、はい。
そんなことは置いておいてせっかくOSSを紹介するのでハンズオン形式の記事にしたかったのですが、
このHARKというOSSを使用するためにはマイクロホンアレイを搭載した特殊な機械が必要となるため今回は紹介だけに留めておこうと思います。
以下の記事で実際に使っている様子が見れるので気になれば是非。
そんなわけでこの記事ではHARKというものを軽く紹介していきます。
ではどうぞ。
2. ロボット聴覚とは
まずロボット聴覚とは何か。
それは「私たちが普段聞いている音環境をロボットがいかに理解できるようにするかという問題を扱う研究分野のこと」です。
音環境を理解させると簡単に言っていますが、実際はかなり挑戦的です。(どの分野にも言えますが、、、)
私たちの耳は様々な音源を聞く中で、特定の音源をどこから来た何の音源なのかを即座に言い当てることができます。
これをいわゆる「カクテルパーティー効果」と言いますが、
ロボット聴覚はこの「カクテルパーティー効果」を完全再現するのが目的というわけです。
3. HARK の紹介
では実際にHARKを紹介していきます。
まずは公式が出しているこの動画を見てみましょう。
ご覧の通り結構精度が高いです。
ちなみにOSSなのでロボットを作っているわけではないのでご注意を。
実際の主要機能と処理の流れはこんな感じです。
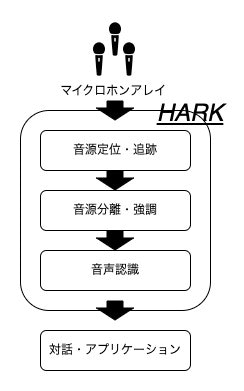
主要機能をそれぞれ補足していくと、
-
音源定位・追跡
- 実時間で音源の到来方向を推定、その音源を追跡する
-
音源分離・強調
- 特定の方向から到来する音源を分離抽出する
-
音声認識
- 分離した音源を認識する
の通りです。
あくまでHARKは音源定位・追跡、音源分離・強調、音声認識をパッケージ化したOSSなので、
マイクロホンアレイと対話・アプリケーションとしてのアウトプットは開発者が用意する必要があるというわけです。
4. HARKを使用した開発
では実際にはどのように開発できるOSSなのか見ていきましょう。
HARKを使って開発するにはGUIかPythonプログラムでHARKのネットワークを組む必要があります。
GUIによる開発
一つ目がGUIでのHARK開発。
hark_designerと呼ばれるHARK独自のGUIツールをインストールすることでローカル上で開発することができます。
見た目は以下のような感じです。
Pythonプログラムによる開発
二つ目がPythonプログラムでのHARK開発。
プログラムは参考程度にこの前使用したものを載っけておきます。
#!/usr/bin/env python
'''PyHARK(オフライン処理)で音源定位を行うプログラム。
引数としてTAMAGOで収録した8ch音響信号を受け取り、
音源定位を行い結果を表示する。
'''
import sys
# import threading
# import time
import numpy as np
import soundfile as sf
from numpy.lib.stride_tricks import sliding_window_view
import hark
import matplotlib.pyplot as plt
from collections import defaultdict
def psource(tsources):
# 音源が存在する時刻と方位角を格納するdictオブジェクト
# デフォルトの値(存在しないキーにアクセスしたときの)が空リストとなるように設定
sources_time = defaultdict(lambda: [])
sources_azimuth = defaultdict(lambda: [])
for i, frame_sources in enumerate(tsources):
for j, source in enumerate(frame_sources):
#print("frame {} , source {} , source-id {}:".format(i, j, source.id))
# フレーム番号を時刻(秒)に変換
sources_time[source.id].append(i/100)
# 音源の仰角を計算(2次元定位では使用しない)
# theta = np.arctan2(source.x[2], np.sqrt(sum(map(lambda x: x**2, [source.x[0], source.x[1]]))))
# 音源の方位角を計算
phi = np.arctan2(source.x[1], source.x[0])
# ラジアンを度に変換して sources_azimuth に格納
sources_azimuth[source.id].append(phi*180/np.pi)
# プロットに用いる fig オブジェクトと ax オブジェクトを作成
fig = plt.figure(facecolor="white")
ax = fig.add_subplot(111, xlabel="time [s]", ylabel='azimuth [deg]')
# 横軸が時刻、縦軸が方位角のグラフをプロットする
for mykey in sources_time.keys():
ax.plot(sources_time[mykey], sources_azimuth[mykey], marker="o")
ax.set_ylim([-180, 180])
# グラフをディスプレイに表示する
# ウインドウが表示されている間は後続の処理をブロックする
# ウインドウを閉じると後続の処理を再開する
plt.show()
def main():
# コマンドライン引数の処理
if len(sys.argv) < 2:
print("no input file")
return
wavfilename = sys.argv[1]
# WAVファイル読み込み
audio, rate = sf.read(wavfilename, dtype=np.float32)
audio *= 2**15
# print(audio.shape)
nch = audio.shape[1]
frame_size = 512
advance = 160
frames = sliding_window_view(audio, frame_size, axis=0)[::advance, :, :]
# print(type(frames), frames.shape)
# multi_gain = hark.node.MultiGain()
# frames = multi_gain(INPUT=frames, GAIN=2**15).OUTPUT
# print(type(frames), frames.shape)
multi_fft = hark.node.MultiFFT()
spec = multi_fft(INPUT=frames)
# print(spec.OUTPUT.shape)
########################################
# 音源定位処理
########################################
# MUSIC法で用いる雑音相関行列を作成する。
# 雑音に関する事前情報は与えられていないので単位行列で代用する。
# 単位行列は本来は チャネル数xチャネル数 の大きさをもつ行列(二次元配列)だが、
# 現在のHARKの実装では一次元配列として与える必要がある。
# さらに 各時間フレーム x 各周波数ビン ごとに配列を与える必要があるため
# Numpyのブロードキャスト機能で配列のインデックスを拡張する。
noise_cm = np.broadcast_to(
np.eye(nch, dtype=np.complex64).flatten(),
(frames.shape[0], frame_size//2+1, nch*nch))
# MUSIC法による音源定位(MUSICスペクトルの計算)を行う
localize_music = hark.node.LocalizeMUSIC()
music_spec = localize_music(
INPUT=spec.OUTPUT,
A_MATRIX='tf.zip',
MUSIC_ALGORITHM='SEVD',
NOISECM=noise_cm,
LOWER_BOUND_FREQUENCY=3000,
UPPER_BOUND_FREQUENCY=6000,
WINDOW=50,
PERIOD=1,
WINDOW_TYPE='PAST',
NUM_SOURCE=2)
print("LocalizeMUSIC processing ...")
# MUSICスペクトルに対して音源追跡処理を行い音源を検出する
source_tracker = hark.node.SourceTracker()
src_info = source_tracker(
INPUT=music_spec.OUTPUT,
THRESH=27.0,
PAUSE_LENGTH=1500.0,
MIN_SRC_INTERVAL=20.0)
# 音源定位結果を図示する
psource(src_info.OUTPUT)
########################################
# 音源分離処理
########################################
# GHDSSによる音源分離処理を行う
ghdss = hark.node.GHDSS()
ghdss_output = ghdss(
INPUT_FRAMES=spec.OUTPUT,
INPUT_SOURCES=src_info.OUTPUT,
TF_CONJ_FILENAME='tf.zip')
print("GHDSS processing ...")
# 必要に応じて分離音をWAVファイルとして保存する
synthesize = hark.node.Synthesize()
synthesize_output = synthesize(INPUT=ghdss_output.OUTPUT, OUTPUT_GAIN=16.0)
save_wave_pcm = hark.node.SaveWavePCM()
save_wave_pcm_output = save_wave_pcm(INPUT=synthesize_output.OUTPUT)
# print("SAVE_WAVE_PCM")
# sys.exit()
########################################
# 音声認識処理
########################################
# 認識性能を安定させるためホワイトノイズを加算する
white_noise_adder = hark.node.WhiteNoiseAdder()
noisy_spectrum = white_noise_adder(INPUT=ghdss_output.OUTPUT, WN_LEVEL=15)
print("Feature extraction processing ...")
# 高周波数帯域を強調する
pre_emphasis = hark.node.PreEmphasis()
pre_emphasized_spectrum = pre_emphasis(INPUT=noisy_spectrum.OUTPUT, INPUT_TYPE="SPECTRUM")
# メルスペクトルを求める
mel_filter_bank = hark.node.MelFilterBank()
mel_spectrum = mel_filter_bank(INPUT=pre_emphasized_spectrum.OUTPUT, FBANK_COUNT=40)
# MSLS特徴量を求める
msls_extraction = hark.node.MSLSExtraction()
msls = msls_extraction(FBANK=mel_spectrum.OUTPUT, SPECTRUM=pre_emphasized_spectrum.OUTPUT,
FBANK_COUNT=40, NORMALIZATION_MODE="SPECTRAL", USE_POWER=True)
# 時間方向の差分をとる
delta = hark.node.Delta()
msls_delta = delta(INPUT=msls.OUTPUT)
# デルタパワーを除いた時間方向の差分を取り除く
feature_remover = hark.node.FeatureRemover()
asr_features = feature_remover(INPUT=msls_delta.OUTPUT,
SELECTOR=" ".join([str(c) for c in range(40, 81+1)]))
# スペクトルの平均値を正規化する
spectral_mean_normalization = hark.node.SpectralMeanNormalizationIncremental()
normalized_features = spectral_mean_normalization(
INPUT=asr_features.OUTPUT,
NOT_EOF=True,
SM_HISTORY=False,
PERIOD=1)
# Kaldidecoderに特徴量を送信する
speech_recognition_client = hark.node.SpeechRecognitionClient()
asr_result = speech_recognition_client(
FEATURES=normalized_features.OUTPUT,
MASKS=normalized_features.OUTPUT,
SOURCES=src_info.OUTPUT,
MFM_ENABLED=False,
HOST="localhost", PORT=5530,
SOCKET_ENABLED=True)
print("Speech recognition processing ...")
if __name__ == '__main__':
main()
こんな感じです。
5. おわりに
以上でHARKの紹介は一旦終わりです。
卒研でこのOSSを使った内容なども面白いなあと思ったりしたのですが、宮治研究室に合っていないような気もしていて迷う日々です。
最後までありがとうございました。
ではこれにて。