プログラミング初心者がChatGPTを使って競馬予想AIを作ることで、生成AIとプログラミングについて学んでいく企画の第9回です。
このシリーズも連載二桁までもう少しですね。
前回の記事はこちら
前回の記事では正規表現や前処理について学びつつ、約8000頭の馬成績を1つのテーブルにまとめました。
今回はこれまでに用意したレース結果と馬成績を結び付け、特徴量を入力できるように1つのテーブルにしていきましょう。
入力データの考え方
シリーズ第9回までやっていながら、実はまだデータを集めただけです。
この回から見始めた人は、今まで何をやっていたんだと驚愕すると思います。
しばらくBeautifulSoupやPandasと格闘していたおかげで、当初どのようなデータを入力して何を予測しようとしていたか忘れてしまいました。
したがって一度集めたデータを整理し、機械学習モデルへの入出力変数をまとめましょう。
予測モデルについて
目指している競馬予想AIはその馬が一位になるかどうかを01で判別するものです。
予測には機械学習のコンペでも使用率が高いLightGBMを使っていきます。
LightGBMへのデータの入力方法については、この企画とは別に以下の記事でまとめました。
これまで用意したデータのテーブルを元に、LightGBMの実装を行いましょう。
まずはこれまで集めたデータのおさらいです。
集めた特徴量は1つのテーブルにして、pickleファイルに保存しています。
こちらを確認してみると
with open("C:\\Users\\name\\Desktop\\mykeibaAI_ver1p0\\data\\race_result_table.pkl", "rb") as f:
model = pickle.load(f)
print(model.columns)
print(f"Number of items: {len(model.columns)}")
Index(['date', 'race_id', 'is_win', 'rank', 'horse_id', 'weight_carried',
'jockey_id', 'popularity', 'odds', 'last3f', 'trainer_id',
'body_weight', 'sex', 'age', 'time_sec', 'body_diff'],
dtype='object')
Number of items: 16
計16個の特徴量が保存されています。
これらはnetkeiba.comのレース結果が保存されているページからスクレイピングした情報です。
またそれぞれの特徴量にどんな値が保存されているか、中身を確認しておきます。

この中で特徴量に使えそうなのは 'weight_carried', 'popularity', 'odds', 'body_weight', 'sex', 'age', 'body_diff' くらいでしょうか
情報にならないID系や入れるとリークになってしまうタイムを抜くと計7個しか残らず…
いつかhorse_idやjockey_idも紐づけ、特徴量をどんどん増やしていきます。
LightGBMへの実装
入力データを見繕ったところで、機械学習モデルに入力してモデルを作っていきます。
LightGBMはDataFrame型のデータに対して説明変数(特徴量)と目的変数を指定し、データセットを学習・評価に分割、そして学習時のハイパーパラメータを設定することで使用可能です。
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# modelにはDataFrame型のテーブルが格納されている
# 説明変数と目的変数の設定
feature = ['weight_carried', 'popularity', 'odds', 'body_weight', 'sex', 'age', 'body_diff']
X = model[feature]
y = model['is_win']
# データセットの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
# ハイパーパラメータの設定
params = {
'objective': 'binary', # 2クラス分類
'metric': 'binary_logloss', # ロス関数
'boosting_type': 'gbdt', # 勾配ブースティング
'learning_rate': 0.1, # 学習率(小さいほど慎重に学習、ただし学習時間は長くなる)
'num_leaves': 31, # 木の葉の数(複雑なモデルほど大きく)
'verbose': -1, # 全てのログの出力を非表示
'early_stopping_round': 30, # 30回連続で改善しなければ終了
'num_boost_round': 300 # 最大100本の木を作成
}
# モデルの学習と評価
ml_model = lgb.train(params, lgb_train, valid_sets=[lgb_train, lgb_eval], valid_names=['train', 'eval'])
y_pred_prob = ml_model.predict(X_test, num_iteration=ml_model.best_iteration)
y_pred = (y_pred_prob >= 0.5).astype(int)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy * 100:.2f}%")
results = X_test.copy()
results["actual"] = y_test
results["predicted"] = y_pred
results["predicted_prob"] = y_pred_prob
print(results.head(10))
こうしてできたモデルを見ると正答率(Accuacy)がなんと92.74%!
Accuracy: 92.74%
weight_carried popularity odds body_weight sex age body_diff \
21107 57.0 12.0 110.6 446.0 0 3.0 -2.0
17038 55.0 3.0 6.5 472.0 1 3.0 -8.0
2281 54.0 7.0 73.5 466.0 1 3.0 8.0
3378 58.0 1.0 3.0 496.0 2 5.0 2.0
19085 56.0 9.0 45.2 480.0 2 6.0 -6.0
13174 57.0 11.0 35.6 464.0 0 4.0 8.0
4404 56.0 2.0 3.6 462.0 0 2.0 -2.0
28181 51.0 11.0 42.0 412.0 1 3.0 -14.0
16441 57.0 2.0 3.1 444.0 0 3.0 4.0
14118 58.0 7.0 27.2 522.0 0 5.0 10.0
actual predicted predicted_prob
21107 0 0 0.007538
17038 0 0 0.125715
2281 0 0 0.011118
3378 0 0 0.287334
19085 0 0 0.023021
13174 0 0 0.015342
4404 0 0 0.277253
28181 0 0 0.138365
16441 0 0 0.268297
14118 0 0 0.031001
しかし喜ぶのも束の間、当然この少ない特徴量ではたいした予測はできていません。
評価用にimportしたscikit-learnのaccuracy_score関数では、予測した結果どれだけ01を当てることができたかを%で出力します。
このとき、0も当たれば正解としていることがネックで、こちらの1を当てたいという目的からはずれています。
したがって、よくよく評価用データの中身を確認してみると、419個ある単勝当たり馬券のうち、23個しか当てていないことがわかります。
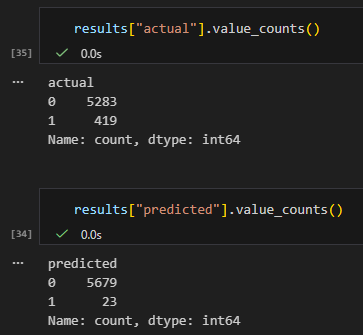
「当たり馬券を予測できた確率」でいうと23/419=0.055
つまりたったの 5.5% です。
値としてはがっかりですが、特徴量も少ないため予測できなくて当然です。
むしろモデル評価の際にはこういった評価方法が重要だ、ということを学べたことが大きいです。
特徴量の追加やそもそものデータ拡充、期待値ベースの回収率計算など、まだまだやることはたくさんあるため、引き続き連載を続けていきます。