はじめに
「自社サービスのデータを分析して、もっと良い価値を届けたい!」
と誰もが思っていると思いますが、
データ分析には色々なセンスが必要だなと最近感じています。
ビジネス面では、
「どんなデータを元に、どんなアウトプットを期待するか?」
「そのアウトプットからどういうビジネス施策を打ちたいか?」
という仮説を立てるのはもちろん、
「将来必要になりそうなデータだから今のうちから整理しておこう!」
という予測能力も必要です。
(ビジュアル的な見せるセンスも必要ですね)
そして技術面では、
自社のデータがどういう分析に向いていて、
今のデータ量で分析ができるのか?や
どの部分の分析に時間がかかりそうなのか?などです。
良い結果が出なそうな時は、すばやい方向転換が必要となってきます。
ということで、データサイエンティストとの二人三脚で最高の分析ができるように
機械学習の基礎をまとめました。ほぼ参考サイトの集めですが...
概要
- ①難しく考える前に、まずはKaggleのタイタニックをやってみます
- 検索すればいっぱい出てくるので詳細は割愛しますが、映画にもなった「タイタニック」の乗客リストから生存者を予測するコンペです。891人分の生存有無の入ったリストを機械学習して予測をたてて、順位を競います。結構奥深い
- PythonのScikit-learnでやります。jupyterという統合分析環境が便利
- ②機械学習の種類を理解します。
- 教師データ「あり」とか「なし」とか
たったこれだけです。
環境整備(Mac)
brew
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
pyenv
brew install pyenv
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile
echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile
echo 'eval "$(pyenv init -)"' >> ~/.bash_profile
source .bash_profile
jupyter / Anaconda
# pyenv install anaconda3-5.1.0
# pyenv global anaconda3-5.1.0
# pyenv version
# python --version
# pip install pydotplus
# brew install graphviz
# conda install graphviz
# jupyter notebook
→ブラウザが立ち上がればOK
Kaggleにユーザ登録し、必要なデータを取得
train.csv →学習するデータ(これを分析します)
test.csv →予測するデータ
分析の流れと結果スコアの理解
- データ分析で大事なのは2つ
- データクレンジング
- データの補完:データが欠損している部分をどう補完するか
- 分析に必要ないデータは削除(ノイズになるため)
- どのアルゴリズムを使うか
- アルゴリズムによって得意不得意があります
- データクレンジング
- 結果スコアの見方
- accuracy_score : 正解率
- auc : 信頼度(再現性)
- ROC曲線とは?:https://qiita.com/kenmatsu4/items/550b38f4fa31e9af6f4f
- auc > 0.7が一般的には最低ライン。正解率が高くても信頼度が低ければ意味がない
分析してみる①:簡易版
- まずは流れの把握なので、欠損しているデータは中央値で補完しただけです
- 王道のアルゴリズムである「決定木」と「ランダムフォレスト」を利用(理解はあとですれば良い)
分析してみる②:データ補完をしっかりやる
- 名前の敬称からデータを整えたり、チケット番号や客室番号を整えたりしてます
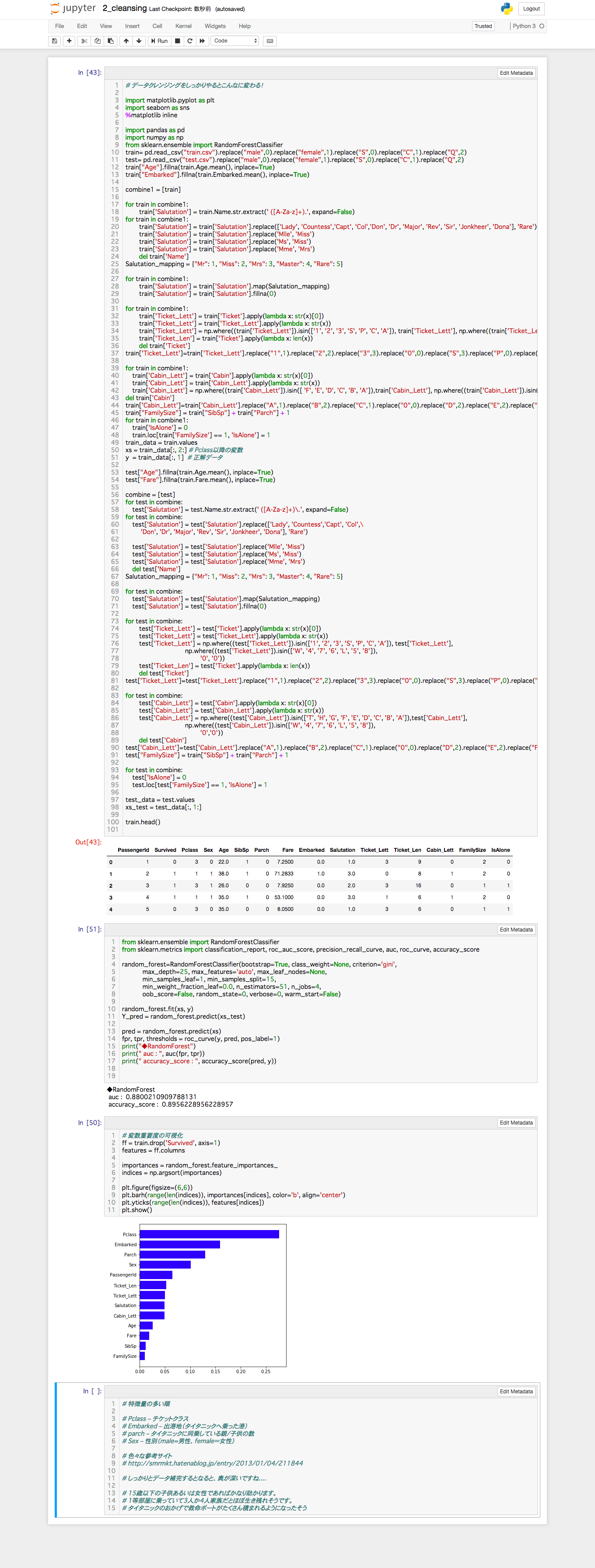
参考にさせていただいたサイト:https://lp-tech.net/articles/0QUUd?page=6
分析結果を比較
- スコア
- 分析してみる①:簡易版
- 決定木
- auc : 0.788859764089122
- accuracy_score : 0.7988826815642458
- ランダムフォレスト
- auc : 0.7995412844036697
- accuracy_score : 0.8212290502793296
- 決定木
- 分析してみる②:データクレンジングをしっかりやってみる
- ランダムフォレスト
- auc : 0.8800210909788131
- accuracy_score : 0.8956228956228957 (全然違う!)

- Kaggleにアップしてみたら341位でした
- ランダムフォレスト
- 分析してみる①:簡易版
- データクレンジングは奥が深い!!
- 色々な背景から予測するとおもしろいですねー
機械学習の種類を理解
機械学習には「教師あり学習」、「教師なし学習」、「強化学習」という3つの学習方法があり、その背後には「回帰」、「分類」、「クラスタリング」などの統計学あります。更にその解を求める方法として「決定木」、「ランダムフォレスト」など多くのアルゴリズムがあります。
- 教師あり学習
- 分類(Classification)
- 2項分類 … 2つに分類:例)明日は晴れるか? (今回のタイタニックですね、生存有無)
- 多項分類 … 3つ以上に分類:例)明日の天気は?(晴れ、曇、雨)
- 回帰(Regression)
- 連続性の予測 … 例)明日の気温は何度?
- 分類(Classification)
- 教師なし学習
- クラスタリング(Clustering)
- グループに分類する。例)カード会員を「高級志向」「流行思考」「無関心」などにグルーピング
- クラスタリング(Clustering)
- 強化学習(Reinforcement Learning)
- 囲碁で有名なGoogleの「AlphaGo」がそうですね。まずインターネット上の囲碁対局サイトにある3000万「手」に及ぶ膨大な棋譜データを読み込ませて学習させました。最初は人間が教える言わば「教師あり学習」です。しかし、それでは学習データが足りないということで、次にAlphaGo開発チームはコンピュータ同士で囲碁の対局を自動で行わせました。教師なし学習で経験値とも呼べるデータを新たに学習・蓄積させました。その対局数は3000万「局」とも言われています。これが「強化学習」
どのアルゴリズムを使うのが良いか?
- scikit-learnにはアルゴリズムチートシートがあるのでこれを利用するのが良いです
実際に利用したアルゴリズムの解説
- 決定木、ランダムフォレストとは?