はじめに
Pythonデータサイエンスハンドブックの勉強中に思ったこと。
seabornでヒートマップ作って誤分類を可視化しているけど、これって全体の中で数字が大きい値に色がつくのでは?
(全分類でサンプル数が同じであればよいが、データ不均衡は往々にして発生するため)
行の合計(=各分類)に対する、各要素の割合が分かるヒートマップもあった方がよいのでは。
ということで作った。
データの読み込みと分類アルゴリズムの適用
load_and_modelfitting.py
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
# サンプルとして今回は手書き文字の画像を分類タスクとしてロード
digits = load_digits()
X = digits.data
y = digits.target
# 訓練用と評価用に分割
Xtrain, Xtest, ytrain, ytest = train_test_split(X, y, random_state=0)
# 分類アルゴリズムも適当にガウシアンナイーブベイズを適用
model = GaussianNB()
model.fit(Xtrain, ytrain)
y_model = model.predict(Xtest)
accuracy_score(ytest, y_model)
ここから本題
いつもの混同行列と、行に対する比率の配列をヒートマップにする
create_confmrx.py
# 普通のコンフュージョンマトリックスの2次元配列
mat = confusion_matrix(ytest, y_model)
# 各行合計に対する割合を計算し、小数点第3位を四捨五入した2次元配列
mat_dec = np.round(mat / np.sum(mat, axis=1), decimals=2)
fig, axes = plt.subplots(1, 2, figsize=(10, 10))
kwargs = dict(square=True, annot=True, cbar=False, cmap='RdPu')
# 2つのヒートマップを描画
for i, dat in enumerate([mat, mat_dec]):
sns.heatmap(dat, **kwargs, ax=axes[i])
# グラフタイトル、x軸とy軸のラベルを設定
for ax, t in zip(axes, ['Real number', 'Percentage(per row)']):
plt.axes(ax)
plt.title(t)
plt.xlabel('predicted value')
plt.ylabel('true value')
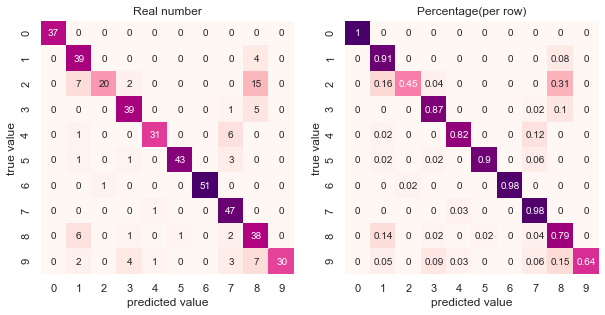
描画したヒートマップ情報の解釈案
- 全体を俯瞰する
- 左側(普通のヒートマップ)の対角線上で色が薄い要素に注目し、「全体の中でハズレが多かった行」を特定
- 分類2,9,4,0が該当
- 右側ヒートマップを見て「行単位の中でもハズレが多い要素」を確認する
- 分類2,9が該当しそうなので、サンプル数増やすとかチューニングを優先的に行う
- 逆に分類4,0は、左側だけを見ると色が薄いが、右側を見ると色が濃いのでチューニングの優先順位低
おわりに
コンフュージョンマトリックス、見方がムズい…。