はじめに:なぜServerless MLなのか?
レコメンデーションシステムと聞いて、多くのエンジニアが思い浮かべるのは、大規模な機械学習インフラストラクチャでしょう。GPUクラスター、分散学習システム、リアルタイム推論サーバー...これらは確かに強力ですが、レコメンデーションを始める場合、これらは過剰になる場合が多いです。
私が個人開発しているCookLabでは、「料理を通して喜びを得てほしい」というテーマで、レシピレコメンデーションアプリを開発しています。このレコメンデーションシステムには以下の3つの重要な特徴があります:
- ユーザーの目的に寄り添う: 「簡単に作れるパスタが知りたい」「子供が喜ぶおやつは?」など、ユーザーの多様な要望に合わせたレシピを提案
- お気に入りのクリエイターを重視: ユーザーが過去に閲覧・お気に入りしたYouTubeやInstagramのクリエイターの新しいレシピを優先的に紹介
- セール商品を活用した経済的な料理提案: ユーザーの近隣スーパーのセール情報を活用し、「今日買えるお得な食材で作れるレシピ」を提案
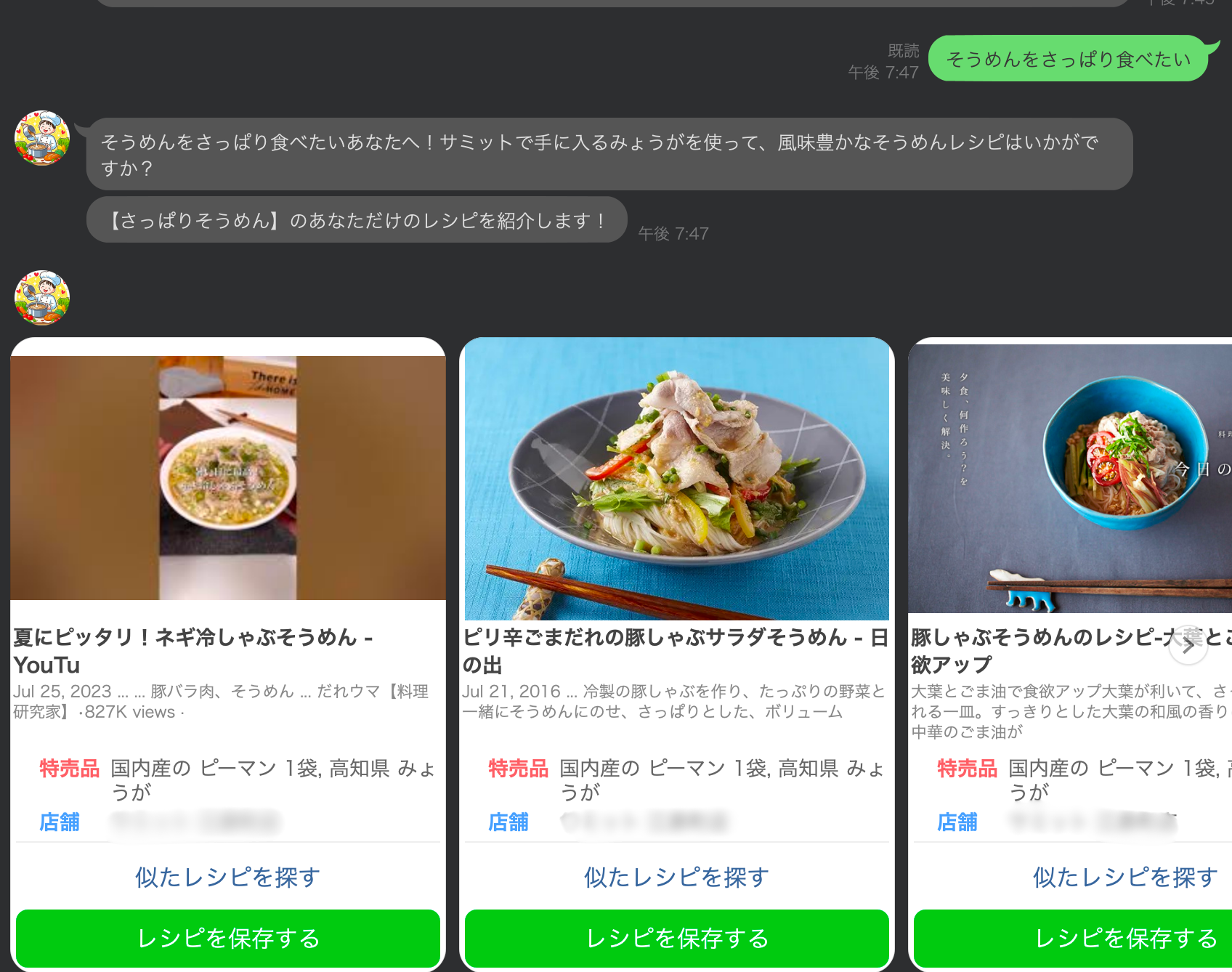
図1: Lineを通したrecipeのレコメンデーション。ユーザーの好みや意図を読み取り、スーパーで購入できる材料を加味したrecommendationができる。
今回は、自社でMLモデルをホスティングすることなく、LLMを活用したServerless MLアーキテクチャでこれらの機能を実現した事例をご紹介します。
従来のMLシステムが抱える3つの課題
1. 💰 運用コストの重さ
CookLabのバックエンドはGolangで構築されています。しかし、多くのMLライブラリはPython環境を前提としており、以下のような課題に直面しました:
【従来のMLインフラのコスト例】
- マシーンリソースを低く見積もっても月額4万円〜(4CPU, 12GB RAM)
- 常時起動が必要(利用頻度に関わらず)
- スケールアウト時はさらにコスト増
- GPUを使えば月額数十万円も
Cloud Runなどのサーバーレス環境も検討しましたが、Pythonランタイムでのコールドスタートは10秒以上かかり、UXの観点から採用できませんでした。
2. 🔄 コールドスタート問題
新しいサービスの宿命として、ほとんどのユーザーは行動履歴がない「コールドスタート」状態です。最近の研究によると、このような場合、従来の協調フィルタリングよりもLLMベースのアプローチが優れた結果を示すことが分かっています。
3. 🔧 運用・メンテナンスの複雑さ
レコメンデーションシステムには、学習後デプロイが済めば終わりというわけではなく、以下のような非常に重いメンテナンスが必要になります。
- モデルの定期的な再学習パイプライン
- A/Bテスト基盤の構築
- マシーンのスケーリング
- パフォーマンスモニタリング
これらの運用タスクには、MLOpsの専門エンジニアリングチームが必要となります。
CookLabのServerless MLアーキテクチャ
そこで私たちは、自身のマシーンにモデルを持たず、LLMのAPIを活用したServerless MLアプローチを採用しました。
🏗️ システム構成
図2: recommendation systemを簡略に示した図。理解の簡単さのために、実際の実装から多くの部分を省略してます。
📊 2段階のレコメンデーションフローとその設計思想
レコメンデーションシステムを2段階に分けることは業界では一般的ですが、私たちのServerless MLアプローチには特別な意味がありました。
従来のレコメンデーションシステムでは、「ユーザーAがこのレシピを見たなら、同じレシピを見た他のユーザーBが好んだ別のレシピも推薦する」という協調フィルタリングが一般的です。しかし、この手法では一般的に自社データベース内のitemの推薦しかできません。
CookLabでは「自社のレシピだけでなく、YouTube、Instagram、一般Webサイトなど外部のレシピも含めて、最適なものを推薦したい」です。つまり、レシピの内容や特徴を理解し、プラットフォームを横断して類似コンテンツを見つけ出せる仕組みが必要だったのです。
さらに、LLMに一度に大量のデータを処理させるとコストと時間がかかります。そこで処理を2段階に分け、最初のステージでは候補を絞り込み、次のステージでは精度の高いランキングに集中するという設計にしました。
1. Candidate生成 - RECFORMERにインスパイアされたアプローチ
RECFORMERは、ユーザーの履歴から次にクリックしそうな商品名を直接生成する手法です。私たちはこのコンセプトを拡張し、Web検索のための「クエリ」を生成するアプローチを採用しました。
コード上では以下のようにpromprを組み合わせて、検索クエリの予想をしてもらってます。
// LLMへの入力情報
prompt := fmt.Sprintf("%s\n%s\n%s\n%s\n%s",
basePrompt, // Main Taskの定義: 検索クエリを探してほしい旨
userIntentionPrompt, // ユーザーの検索意図(「簡単パスタレシピ」など)
userProfile, // 国、都道府県、食の好み、アレルギー情報
recipeInfo, // 閲覧履歴と「いいね」したレシピ(タイトル、ソース、閲覧時刻など)
saleItemInfo, // スーパーのセール商品(店名、商品名、特集フラグ)
seasonInfo // 天気、曜日、日付、時間帯
)
特筆すべきは、LLMが天気や日時なども考慮して、その日にユーザーが食べたいと思われるレシピのクエリを生成する点です。雨の日はあったかい鍋物、暑い日は冷たい麺類など、状況に応じた提案が可能になります。
生成されたクエリは、YouTube、Instagram、一般Webという3つの異なるプラットフォームで並列検索され、候補レシピを集めます。ここで重要なのは、各プラットフォーム専用にカスタマイズされたGoogle Custom Search Engine (CSE)を使用している点です。プラットフォームごとに最適化された検索エンジンIDを用意し、それぞれの特性に合わせた検索結果を取得しています:
// 各プラットフォーム用のカスタム検索エンジンID
const (
youtubeSearchEngineID = "xxx" // YouTube専用CSE
instagramSearchEngineID = "xxx" // Instagram専用CSE
webSearchEngineID = "xxx" // レシピサイト用CSE
)
// 各プラットフォームで並列検索(コードを簡略化)
for _, cond := range queryConditions {
wg.Add(1)
go func(cond recipe_search_type.RecipeSearchCondition) {
defer wg.Done()
switch cond.Source {
case recipe_search_type.Youtube:
results = youtubeSearch(cond.Query)
case recipe_search_type.Instagram:
results = instagramSearch(cond.Query)
case recipe_search_type.Web:
results = webSearch(cond.Query)
}
}(cond)
}
2. Listwise Reranking - セール商品を活用した優先順位付け
第2段階では、集められた候補レシピに対して優先順位付けを行います。従来の機械学習ベースのレコメンデーションシステムでは、各アイテムのクリック確率を数値(スコア)で予測し、それによってランキングを行うPointwiseやPairwiseなどの手法が選択肢として存在します。これらの方法は自社のデータで特定目的にトレーニングされたモデルを前提としています。
一方、汎用LLMはレコメンデーション専用にトレーニングされていないため、「このレシピがクリックされる確率は32.7%」といった数値を生成することは原理的に困難です。そこで私たちは、LLMが得意とする「言語的な理解と相対的な比較」を活かしたListwise手法(候補全体を一度に順位付け)を採用しました。
// リランキングのためのプロンプト生成(実際のコードから簡略化)
recipeInfo := "Please output title of top 10 recipes from the following contents. \n"
for i, content := range contentMap {
recipeInfo += fmt.Sprintf("id: %d, title: %s, source: %s, account_name: %s\n",
i, content.Title, content.Type, content.AccountName)
}
// システムプロンプトの一部(日本語に意訳)
/*
- ユーザーが何を探しているのかが最も重要です
- レシピは表示順にユーザーに提示されるので、好みそうなものから順に並べてください
- セール商品を使って作れるレシピを優先的に上位に配置してください
- 各レシピにどのセール商品が使えるかを具体的に指定してください
*/
ここで特に重要なのは、セール商品とレシピの関連付けです。LLMはレシピのタイトルから材料を推測し、その日のセール商品と照合します。そして「このレシピにはA店のトマトとB店の鶏肉が使える」といった情報を付加します。
この2段階アプローチにより、単なる「おすすめレシピ」ではなく、「今日のセール商品を使って作れるおすすめレシピ」という、より具体的で実用的な提案が可能になりました。ユーザーにとっては節約になり、スーパーマーケットにとってはセール商品の消化促進になるという、Win-Winの関係を構築できています。
その他の工夫
⚡ パフォーマンス最適化
LLMの時間以外にも検索にすごく時間がかかることが判明しました。現状CookLabでは検索は外部のsearch APIを呼ぶだけなので、並列処理可能です。この並列処理により、検索時間を大幅に短縮しました:
func (f *recipeSearch) searchInParallel(ctx context.Context, queries []string) []*Recipe {
var wg sync.WaitGroup
results := make(chan []*Recipe, 3)
// YouTube, Instagram, Web検索を並列実行
for _, platform := range []string{"youtube", "instagram", "web"} {
wg.Add(1)
go func(p string) {
defer wg.Done()
searchResults := f.searchPlatform(ctx, p, queries)
results <- searchResults
}(platform)
}
// 結果を集約
go func() {
wg.Wait()
close(results)
}()
// 全結果をマージして返す
var allResults []*Recipe
for r := range results {
allResults = append(allResults, r...)
}
return allResults
}
並列化により、10秒以上かかっていた検索時間が1秒以下に短縮されました。
🚀 Golang × Cloud Runの相性の良さ
Pythonレイヤーを排除し、GoからLLM APIを直接呼び出すことで:
- コールドスタート時間: 10秒以上 → 数十ms未満
- 最小インスタンス数: 1 → 0(完全従量課金)
- メモリ使用量: 1GB → 128MB
まで減らすことができ、マシーンにかかるコストを大幅に減らすことができます。
// Golangで直接Gemini APIを呼び出すcoden例
client, err := genai.NewClient(ctx, option.WithAPIKey(apiKey))
model := client.GenerativeModel("gemini-xxx")
response, err := model.GenerateContent(ctx, genai.Text(prompt))
📈 成果とメリット
パフォーマンス
処理ステップ別の所要時間:
- クエリ生成: 1秒
- 並列検索: 1秒
- リランキング: 3-4秒
━━━━━━━━━━━━━━━━━
合計: 5-6秒
コスト削減
【従来のML基盤】 【Serverless ML】
月額固定費: 4万円+ 月額固定費: 0円
従量課金: API利用料 従量課金: API利用料のみ
運用人件費: 高 運用人件費: 最小限
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
削減額: 月4万円以上 + 運用コスト
ビジネス価値
- 🛒 セール商品を活用したレシピ提案で、ユーザーの節約に貢献
- 🎯 新規ユーザーにも即座に的確なレコメンデーション
- 🌐 自社コンテンツに限定されない幅広いレシピ提案
🔮 今後の展望と課題
現在の最大の課題はリランキングのレイテンシです。全体の処理時間5-6秒のうち、リランキング処理が3-4秒を占めています。これはListwiseアプローチでLLMが文章を生成するのに時間がかかるためです。
この課題に対して、いくつかの改善策を検討しています:
LLMのファインチューニング
最新の研究によれば、LLMをレコメンデーションタスク用にファインチューニングすることで、精度とレイテンシの両方が大幅に改善されることが報告されています。特に注目しているのが以下のポイントです:
- ファインチューニングによりPairwiseアプローチが実現可能になる可能性
- Pairwiseアプローチでは複数のレシピを並列で評価できるため、全体のレイテンシを大幅に削減できる
TALLRecの研究によれば、実際のユーザークリックデータでLLMをファインチューニングすることで、「pointwise」(各アイテムの選好度を直接予測)や「pairwise」(2つのアイテムの相対的な選好を予測)のアプローチが可能になります。これにより、テキスト生成を伴わない高速な判断が実現でき、レスポンス時間を大幅に短縮できる可能性があります。
しかし、現在使用しているGemini Flashのファインチューニングが2025年5月に終了するため、代替モデルや他のアプローチを検討しています。
コールドスタートからウォームステートへの移行戦略
A-LLMRECなどの研究が示すように、サービスの成長に伴いユーザーデータが蓄積される「ウォームステート」に移行すると、ファインチューニングなしのZero/Few-shot LLMでは精度が従来の協調フィルタリングに追いつかなくなる傾向があります。
当初はコールドスタート問題に対処するためにLLMを採用しましたが、サービスの成長とともに:
- 実際のユーザー行動データを活用したLLMのファインチューニング
- 従来の協調フィルタリングとLLMのハイブリッドアプローチ
- ドメイン特化型の小規模モデルの開発
といった方向性も視野に入れています。
キャッシングと事前計算
- よく検索されるクエリのレコメンド結果をキャッシュ
- ユーザーのお気に入りレシピや閲覧履歴に基づいた事前計算
- セール商品とレシピの関連付けをバッチ処理で事前に計算
その他の検討事項
- ユーザーフィードバックの活用による精度向上
- マルチモーダル(画像+テキスト)レコメンデーションへの拡張
- より軽量なLLMモデルの探索
結局のところ、「完璧なレコメンデーション」と「高速なレスポンス」のバランスをどう取るかが永遠の課題です。現在は精度を優先していますが、ユーザー体験を考慮すると、将来的にはレイテンシをさらに改善することが必要だと考えています。
まとめ
Serverless MLアプローチは、以下のような場合に特に有効です:
✅ スタートアップや中規模サービス
✅ コールドスタートユーザーが多い
✅ 運用コストを最小限に抑えたい
✅ MLエンジニアリングチームがいない
✅ 外部コンテンツも含めてレコメンドしたい
CookLabの事例が、同じような課題を抱えるエンジニアやプロダクトマネージャーの参考になれば幸いです。
実際のアプリケーション例
本記事で解説したレコメンデーションを実装した実例として、私が開発しているCookLabをご紹介します。
CookLabは、料理好きの方々が簡単にレシピを共有し、お気に入りのレシピを保存できるLINE Bot + LIFFアプリです。
主な機能:
- レシピの検索、解析
- レシピの相談
- 盛り付け例の画像提案
- セール品で作れるレシピの提案
等、料理を楽しめる様々な機能があります。
以下のQRコードまたはリンクから、LINEの公式アカウントを友だち追加して、実際の認証フローと機能を体験してみてください!

ぜひ以下のLINE公式アカウントを友だち追加して、実際の認証フローを体験してみてください!
また、実装の相談、依頼についてはGithubに記載されている、emailまたはSNSから連絡ください。