目次 (リンクがうまく機能していません)
1.はじめに
こんにちは。AI関係の記事も書いておきたいと思ったので投稿します。
まず、AI関連で何かをしようと考えると一番大変なのはデータセットの用意だと思います。私が現時点で手っ取り早くデータを用意する方法はたまたま手元にあった芸人さんのネタ動画のみだったので、それを利用してAIを作ろうと考えました。
この記事は芸人さんのネタや写真をデータに使っているので、使用データの詳細については一切お見せできませんのでご了承ください。
また、ルール上問題があった場合は直ちにこの記事を削除・修正します。
データの用意とそれに基づいたAIについては今回の動画以外にもいろいろ考えていたのですが、データの作成と収集に手間がかかりすぎてしまい、ここ数か月未だに完成の見込みがないので、一旦こちらを優先しました。現在制作中のデータを用いたAIについては、いずれ投稿しようと思います。
今回も細かいところで結構雑な方法を使っている個所もあるので、そこは大目に見てください。
また、記事について間違っている個所や改善できる個所があればぜひ教えていただきたいです。よろしくお願いします。
2.芸人さんについて
今回データとして使用させていただく芸人さんをご紹介します。と言っても、M-1グランプリで決勝戦の出場経験があるコンビのみを選んだので、ご存知の方も多いかと思います。今回は以下の5組のみの分類をします。
( )内は2023年5月時点での所属事務所です
1. ダイヤモンド(吉本興業東京)

https://thetv.jp/person/2000030722/ より引用
独特の世界観を持ったネタをするコンビです。M-1グランプリ2022ではこのコンビも決勝戦に進出しています。ネタの中で小野さん(右)にいじめられる野澤さん(左)の様子が本当に面白いです。
2. 見取り図(吉本興業東京)

https://natalie.mu/owarai/artist/8370 より引用
今やテレビの売れっ子ですね。M-1グランプリでは2018~2020で3年連続決勝進出しています。売れっ子になった今でも劇場でのステージ数が多いことから"大阪の劇場番長"なんて呼ばれることも多いです。
3. さや香(吉本興業大阪)

https://profile.yoshimoto.co.jp/talent/detail?id=6046 より引用
M-1グランプリ2017と2022で決勝に進出していて、2022では準優勝を収めた実力派コンビです。正統派で漫才一筋かと思えば, 歌ネタ王決定戦2020でも優勝している多彩なコンビです。
4. 真空ジェシカ(プロダクション人力舎)

https://www.p-jinriki.com/sp/talent/shinkujesica/ より引用
こちらもM-1グランプリ2021, 2022で決勝戦に進出している実力派です。コアなネタや尖ったボケでお笑いファンを魅了してきました。かくいう私のプロフィール画像も真空ジェシカのお二人です。
5. ゆにばーす(吉本興業東京)

https://profile.yoshimoto.co.jp/talent/detail?id=3532 より引用
M-1グランプリに文字通り人生のすべてをかけているコンビです。2017, 2018, 2021で決勝戦に進出していて, 下ネタも織り込めるのに安定した正統派といえるネタで, 精密性にはほれぼれさせられます。
※各コンビに対するコメントはただのお笑いファンである筆者が主観だけで書いているので, その芸人さんのことを正確に表現できていない場合があります。ぜひ、テレビや劇場で芸人さんを知っていくことをおすすめします!
みんな、お笑い、楽しいよ!
3.使用した環境
- OS: Windows11
- メモリ: 48GB
- GPU: NVIDIA GeForce RTX 3070 Ti
- Anaconda(Spyder, JupiterNotebook) or VSCode
- python 3.8
- tensorflow-gpu 2.9.0
4.データの用意
画像認識での深層学習を行うので, 芸人さんの画像を用意します。今回は, 先ほども述べた通り権利などの都合により添付することはできませんが, それぞれの芸人さんたちのネタ動画から画像を切り出します。
画像の切り出し
動画はたくさんの画像を順番に表示しているだけなので, 一枚一枚の画像を得ることができれば, それを学習データにできます。Python, OpenCVで動画ファイルからフレームを切り出して保存にて紹介されている切り出し関数をそのまま使用しています。
import cv2
import os
def save_all_frames(video_path, dir_path, basename, ext='jpg'):
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
print("can't open")
return
os.makedirs(dir_path, exist_ok=True)
base_path = os.path.join(dir_path, basename)
digit = len(str(int(cap.get(cv2.CAP_PROP_FRAME_COUNT))))
n = 0
while True:
ret, frame = cap.read()
if ret:
cv2.imwrite('{}_{}.{}'.format(base_path, str(n).zfill(digit), ext), frame)
n += 1
else:
return
関数の引数について, video_pathは切り出したい動画のパス, dir_pathは切り出し後の動画の保存先フォルダ(実行時に存在しない場合は新しく作ってくれます), basenameは保存される画像達の名前の文字列です。この文字列の後ろに数字が振られて保存されます。extは保存される画像の保存形式を確定させる拡張子なので, 大抵の場合.pngか.jpgになると思います。
この関数によって出力された画像の一部が以下のものです(画像部分にはモザイクをかけています)。大量の画像が1分程度で生成できました。

ディレクトリについて
私の場合、ディレクトリは以下のようになります。保存先を芸人さんの名前に設定していて、ファイルをもとにクラス分類していきます。
comedy_movieAI
|
-comedy_train
|-diamond
|-mitorizu
|-sayaka
|-shinku-jeshika
|-yuniba-su
不要画像の削除
動画フレームの中には芸人さんが映っていないものなどもあるので, それを削除する必要があります。今回は手作業で行いましたが(所要時間5分程度), もし自動で行うなら切り出しの際に省くのが効率がよさそうです。具体的には以下の方法があるかと思います。
- 先頭と終わりの数秒を最初から無視する
芸人さん入場と最後の「もうええわ」のあとのお辞儀以降はいらないので、前後数秒間を固定で削除しておく。 - 先ほどの画像切り出しのサイトにもある「時間・範囲を指定して切り出し」や「自分で確認しながらキーボード押下でフレーム切り出し(半自動)」を使う。
- 動体検知など
通常の劇場であれば背景はまず動かないので, 「芸人さんが動き始めたらフレームを保存する」といった処理を行う。
保存された画像と使用した画像について
それぞれの芸人さんについて保存されている画像数を確認すると、以下の表のようになりました。それぞれ4分の漫才ネタで30FPSの動画3個から画像を切り出したので, 単純計算1組当たり22,400枚前後の画像数となるはずですが実際そうなっていることがわかります。
ここで、画像処理等の深層学習に明るい人はお気づきかと思われますが、私のPCのスペック的にこの枚数は無理です、処理できません!頑張ろうとしましたが案の定Memory ErrorやInternal Errorが出てしまいました。今回は元データが動画ということもあり、似たような画像(芸人さんの姿勢や表情など)が多かったため、シンプルに間引いてやることにしました。30フレームに1枚画像を使うようにすれば、全体としてデータ数が1/30になりますよね。実際のコードは5.データの読み込みにて説明しますが、実際に使用したデータの数は以下のようになります。
| 名前 | 元々の画像数(枚) | 使用した画像数(枚) |
|---|---|---|
| ダイヤモンド | 23,309 | 777 |
| 見取り図 | 24,410 | 814 |
| さや香 | 23,592 | 787 |
| 真空ジェシカ | 25,659 | 855 |
| ゆにばーす | 23,197 | 773 |
| 合計 | 120,167 | 4,006 |
5.データの読み込み
画像データセットを作れたら次は画像の読み込みです。skimageを使って画像を読み込んでいきます。まず、以下に読込に必要なパスを読み込むためのコードを添付しています。先ほどの通り、30枚に1枚読み込むという処理はcntで愚直に数えて行っています。フォルダ内のすべての画像を読み込みたい場合は、cntに関する記述をすべて消せばいいです。
import os
c_classes = ['sayaka', 'shinku-jeshika', 'daiamond', 'mitorizu', 'yuniba-su']
data_path = '.../comedy_movieAI/comedy_train/'
all_filepaths = [] #ファイルパス
y_class = [] #クラスラベル
cnt = 0
# 画像パスの一覧を取得
for i, cclass in enumerate(c_classes):
tgt_folder = os.path.join(data_path, cclass)
files = os.listdir(tgt_folder)
filepaths = []
for file in files:
if file.endswith('.jpg') and cnt%30==0:
filepaths.append(os.path.join(tgt_folder, file))
y_class.append(i)
cnt += 1
print(tgt_folder, len(filepaths))
all_filepaths.extend(filepaths) # クラス別ファイルパス一覧リストを結合
これによって、tgt_folderにクラスのパスが、filepathsにクラスごとのすべての画像のパスが保存されます。all_filepathsにクラス関係なく全ての画像のパスが保存されているので、これを sklearn.model_selectionのtrain_test_splitなどでx_train_path,x_test_path,y_train_path,y_test_pathに分けます。私はテストデータのパスの割合を0.3に設定して学習させました。
6.モデルの作成
画像を読み込めるようになるといよいよモデルを作ります。コードの詳しい解説は他の記事などでされているので省略しますが、今回は3層CNNモデルを使うことにします。
from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Dropout, Flatten, Input
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import Adam
# CNNモデルの構築(3層CNN)
def build_CNN3(imgshape, n_classes, dr=0.0, lr=1e-4):
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(imgshape[0], imgshape[1], 3)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(dr))
model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(dr))
optimizer = Adam(learning_rate=lr)
model.add(Dense(n_classes, activation='softmax'))
model.compile(loss='sparse_categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
return model
drやlrを指定してモデルの学習を簡単に変更できるようにしてあります。
cnn0 = build_CNN3(x_train[0].shape, n_classes=len(c_classes))
7.学習
作成したモデルに読み込んだ画像を学習させます。50エポックで学習させる。
history0 = cnn0.fit(x_train, y_train,
batch_size = 64,
epochs = 50,
shuffle = False,
validation_data = (x_test, y_test),
)
8.モデルの評価
学習の様子を示すグラフを表示する関数です。
#学習曲線を表示する関数
def show_history(hists, labels):
plt.figure(figsize=(10,4))
plt.subplot(121)
for fit, label in zip(hists, labels):
plt.plot(fit.history['loss'], label='train loss %s'%label)
plt.plot(fit.history['val_loss'], label='val loss %s'%label)
plt.title("Loss")
plt.xlabel("epocs")
plt.ylabel("loss")
plt.legend()
plt.subplot(122)
for fit, label in zip(hists, labels):
plt.plot(fit.history['accuracy'], label='train acc %s'%label)
plt.plot(fit.history['val_accuracy'], label='val acc %s'%label)
plt.title("Accuracy")
plt.xlabel("epocs")
plt.ylabel("accuracy")
plt.legend()
plt.show()
show_history([history0], [''])
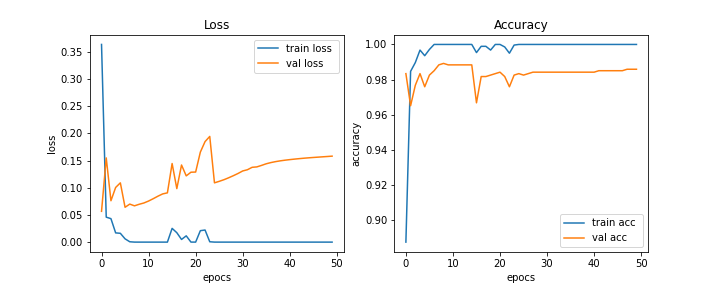
以上のコードから以下のようなグラフが得られます。学習が進むにつれてval lossが増加してしまっています。
以下が混同行列や正解率を求めることができる関数です。正解率以外の評価指標(再現値など)は一旦今回は省略します。
from sklearn.metrics import confusion_matrix, accuracy_score, recall_score, precision_score, f1_score
# 認識結果,混同行列を表示する関数
def show_results(model, x_test, y_test):
n_classes = y_test.max()+1
y_prob = model.predict(x_test) #学習済みモデルを使って予測
if n_classes==2:
y_pred = (y_prob>0.5).astype(int).reshape(-1)
else:
y_pred = np.argmax(y_prob, axis=1) #確率最大のインデックスを取得
print(confusion_matrix(y_test, y_pred))
print('正解率 = %.2f%%'%(accuracy_score(y_test, y_pred)*100))
# 混同行列をヒートマップで表示
sns.heatmap(confusion_matrix(y_test, y_pred),
cmap='PuBu', annot=True, cbar=False, square=True)
plt.xlabel('pred')
plt.ylabel('label')
plt.show()
return y_prob, y_pred
y_prob, y_pred = show_results(cnn0, x_test, y_test)
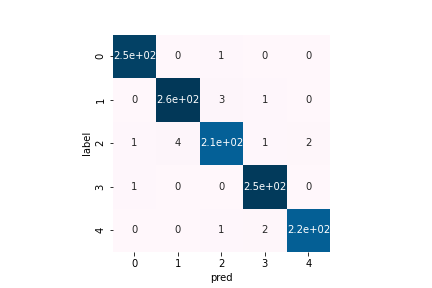
このコードより以下の混同行列が得られます。さや香(2)に関する誤分類が多いことがわかります。
0: ダイヤモンド
1: 見取り図
2: さや香
3: 真空ジェシカ
4: ゆにばーす
正答率は98.59%と、かなりいい精度が出せています。
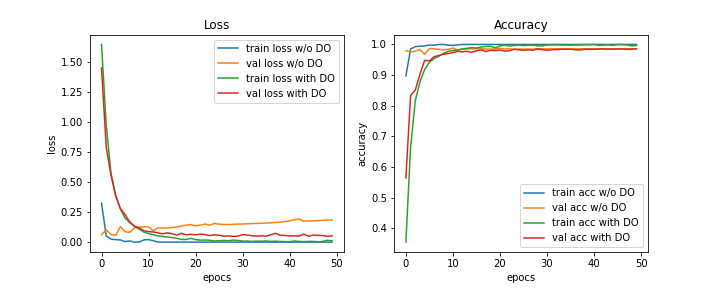
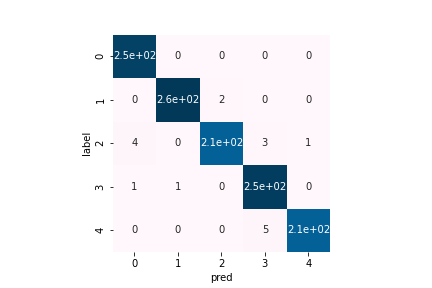
ここで、dr=0.5としたモデルを定義し、再び学習させると、以下のような学習曲線となり、その下の混同行列のようになりました。学習曲線については、学習が進む度にval lossの値が上昇してしまっていた元々のモデルに対して、ドロップアウトしたモデルはval lossの値が小さい値で収束していることがわかります。混同行列については分かりにくいですが、間違えた箇所が少しずつ変わっていることがわかります。相変わらず、さや香に関する誤分類が一番多いです。また、正答率は98.59%でドロップアウトする前と変わらない結果となりました。
9. まとめ
このように動画から画像を切り出し、その画像を用いてCNNモデルを学習させ、その結果を評価することができました。
PCのスペックに悩まされたり、精度が良すぎたりして戸惑ったこともありましたが、意外と早く結構良さげに記事を書ききることができて満足しています。ちなみに、最初動画1つで学習させたモデルの評価をしたら脅威の精度100%を達成してしまい大変困りました(笑) これは類似画像が多すぎたことが原因で、その動画以外の写真には全く反応できないモデルになってしまっていたことになると思われます。さらに、分類モデルの評価について、間違えた画像についての考察も行ったのですが、例のごとく権利などの都合でやむを得ず省略しています… 結構面白い結果が出てて、どう見ても真空ジェシカのふたりなのにさや香に分類されてたりしました。
今後は、学習画像の種類を増やす(ネタ動画の種類を増やす)などすると、より汎用性の高いモデルができると考えられます。また、芸人さんはたくさんいます!もっと別の芸人さんに関する分類モデルも作っていきたいと考えています。
最後となりますが、ここまで読んでいただいてありがとうございました。
AIの勉強をしている皆さん、息抜きにお笑いを楽しんではいかがでしょうか。劇場に足を運ぶだけでも楽しさが段違いですよ!